scikit-learnとは
Pythonの代表的な機械学習ライブラリで、複雑な機械学習の数式を使うことなく、誰でも簡単に高度なデータ分析を行うことができます。オープンソースでBSDライセンスであるため商用利用可能です。
機械学習といえば、ディープラーニングですが、ディープラーニングの学習には膨大なデータが必要で、データ数が少ないときには精度が上がりにくいです。一方、scikit-learnは、機械学習全般のアルゴリズム(統計学、パターン認識、データ解析の技法など)を簡単に実装でき、特にデータ数が少ない場合は、sciki-learnでデータ分析するメリットは大きいです。
scikit-learnの実装のイメージ
まずは、簡単にscikit-learnを使ってみます。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# データを読み込む
iris = load_iris()
X = iris.data[:, :2]
y = iris.target
# 訓練用, テスト用のデータに分ける
X_train, X_test, y_train, y_test =\
train_test_split(X, y, test_size=0.25, random_state=1)
# 訓練用データでモデルに学習させる
clf = SVC(kernel='linear', random_state=1)
clf.fit(X_train, y_train)
# テスト用データで学習済モデルを評価する
y_pred = clf.predict(X_test)
score = accuracy_score(y_test, y_pred)
print(score)
# 出力: 0.7631578947368421
たったこれだけのコードで、機械学習ができます。やったことは、基本的に下記の4つです。
- データの読み込み (Irisという花の特徴量と種類を読み込みます)
- 訓練用のデータとテスト用のデータに分ける
- モデルを訓練
- モデルで予測 (特徴量から、花の種類を予測します)
学習済モデルを評価した結果 0.763... と表示されます。これは、76.3%の正解率で予測できるモデルということです。
さらに必要に応じて、データの前処理を行なったり、モデルのハイパーパラメータを調整したりして、機械学習の精度を高めていきます。
scikit-learnに含まれる主な機能
scikit-learnのライブラリは、大きく分けて6つの機能に分類できます。
機械学習の機能が4つ
- クラス分類 (教師あり学習)
- 回帰 (教師あり学習)
- クラスタリング (教師なし学習)
- 次元削減 (教師なし学習)
学習精度を高めるための機能が2つ
- モデル選択
- 前処理
これらの機能の概要について、以下の公式ドキュメントを読み進めながらまとめていきます。
クラス分類 (教師あり学習)
クラス分類とは、ラベル付きのデータを学習して、分類する機能です。例えば、スパムメールの識別や、画像認識に応用できます。
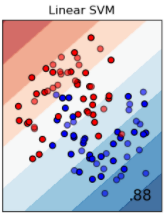
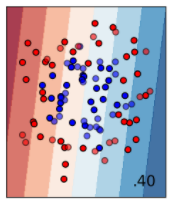
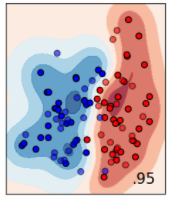
公式ドキュメントでは、input data (一番左の画像) の青と赤の点を分けるために、様々なモデルで評価した結果が並べられています。
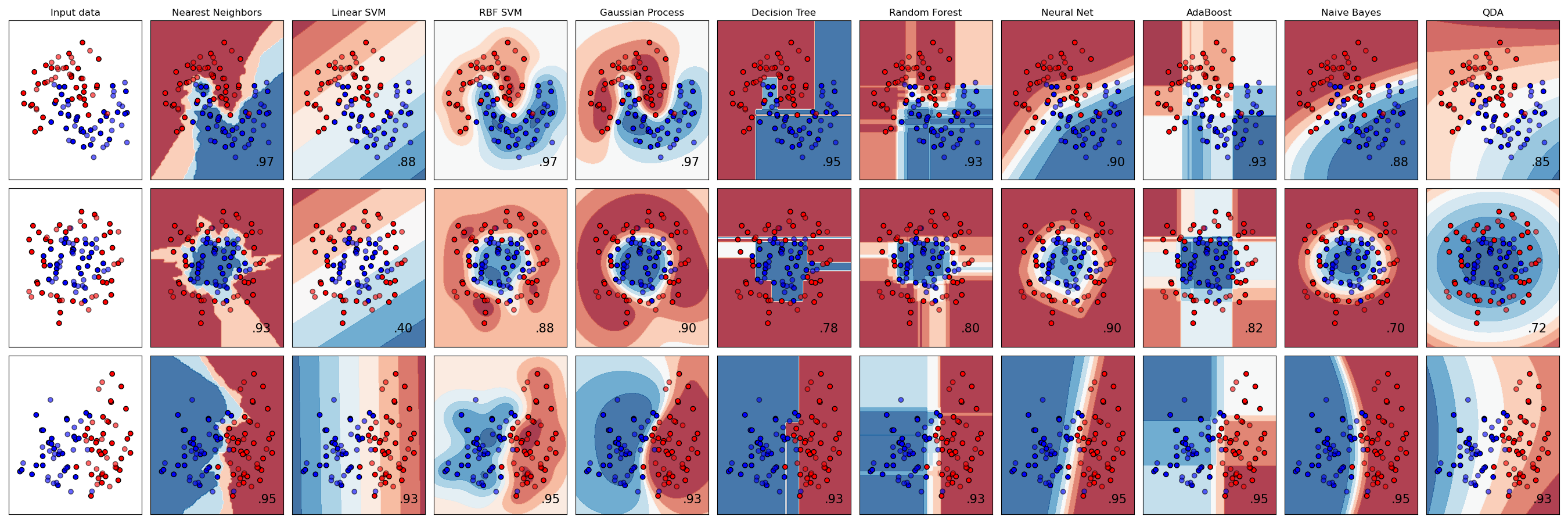
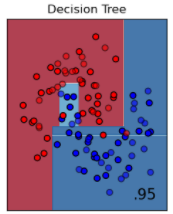
簡単なものをいくつか説明していきます。まずは決定木 (Decision Tree) です。これは、条件ごとに場合分けをしていく分類方法です。人の考え方に近いので、一番理解しやすく簡単ですが、分類の精度はあまり良くないです。
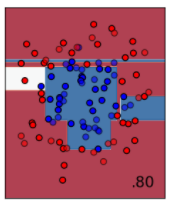
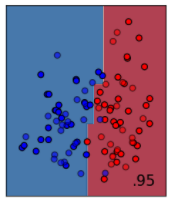
決定木を少し発展させた方法が、ランダムフォレストです。木がだめなら、森でどうだというイメージの分類方法です。ランダムに抽出したサンプルに対して決定木で分類し、その結果を多数決などのルールに従って統合するイメージです。単純な方法ですが、決定木よりは分類精度が良くなります。
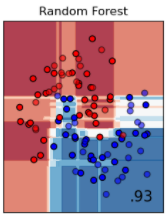
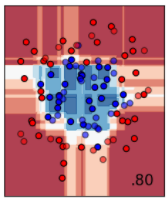
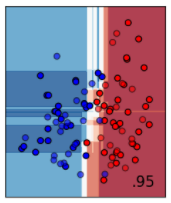
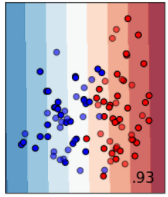
次にサポートベクターマシーンによる分類です。マージン最大化を行うことによって、データを線形で分類できます。線形という制約があるため、2番目のデータセットのように、青の点が赤の点に囲まれるようなデータはうまく分離できません。
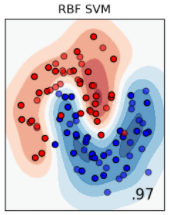
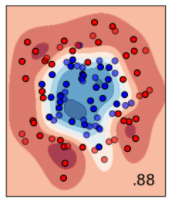
しかし、サポートベクターマシーンは、カーネル関数を設定することで、平面では分離できなかった非線形な分離を行うことができます。
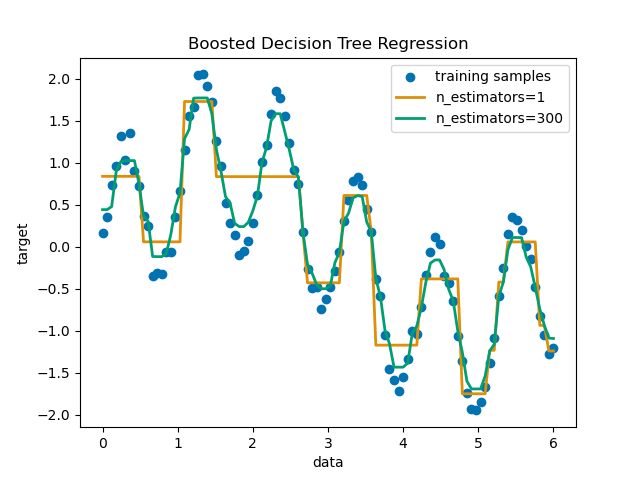
回帰 (教師あり学習)
回帰は、連続する数値についてのデータ分析に向いています。株価の分析や、薬の反応を分析することに応用できます。
簡単な回帰分析であれば、Excelなどで十分ですが、変数が多くなったり、外れ値が多いと分析は複雑になります。scimitar-learnは、そのようなデータの取り扱いも容易で、さらに回帰モデルも、リッジ回帰やラッソ回帰など豊富です。
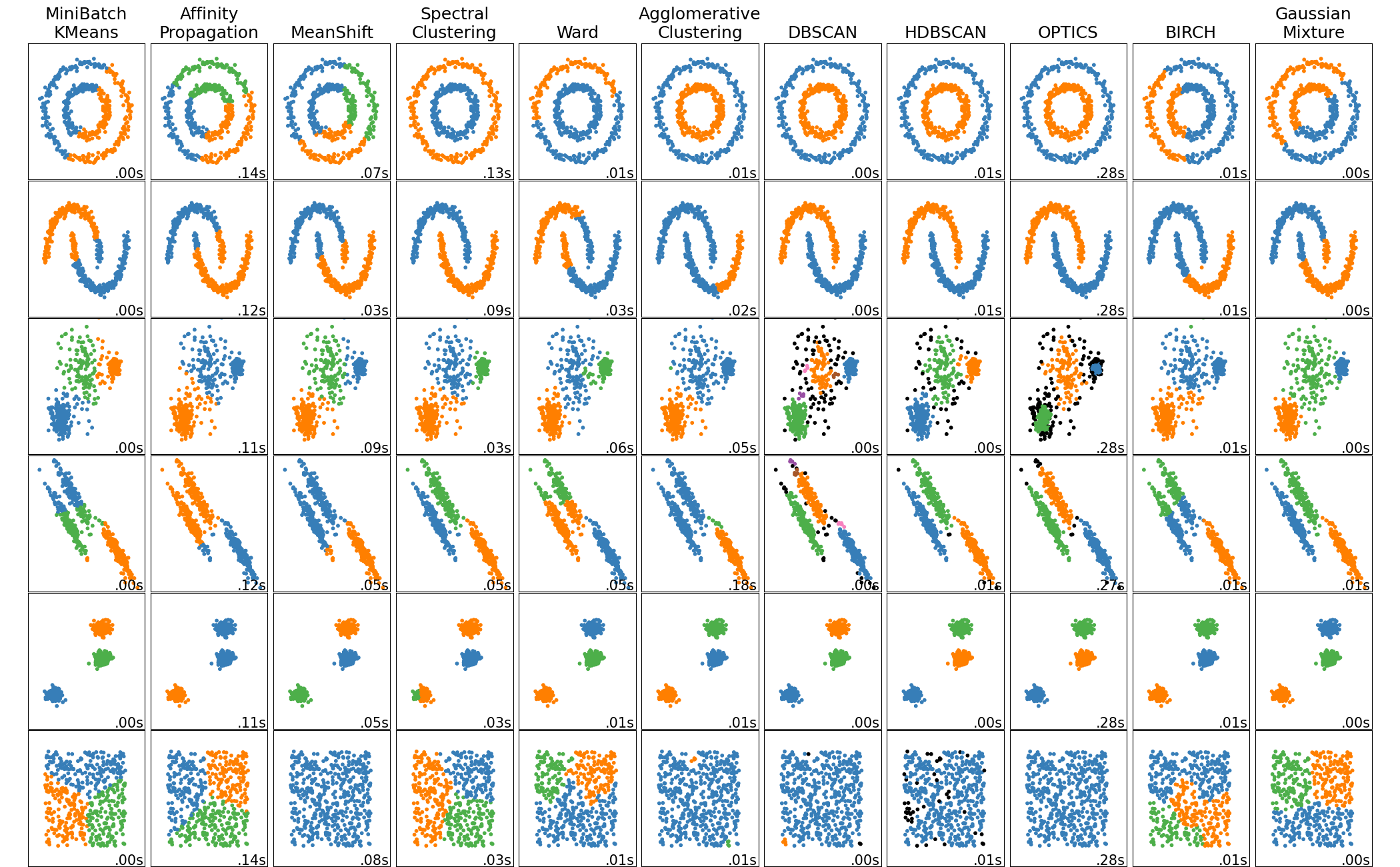
クラスタリング (教師なし学習)
似た特徴を持つデータごとのグループに、自動で分類する機能です。例えば、購買行動から顧客セグメントを分類することなどに応用できます。
クラス分類と同様に、モデルによって結果が異なることがわかります。
次元削減 (教師なし学習)
データ分析を行うときに、特徴量が多いと、重要度が低いデータが多く含まれることがあります。これらの重要度が低い特徴量が含まれることで、機械学習の処理量が多くなったり、予測精度が悪くなったりします。そこで、多くの特徴量からなる情報を、その意味を保ったまま、それより少ない情報に落とし込むために、次元削減モジュールが使われます。
次元削減は、他の3つの機械学習モデルのように何かを予測するのでなく、次元削減された主成分を返します。この主成分を使って、重要でないデータを多く含んだデータを変換することによって、データ量を圧縮することができます。
モデル選択
機械学習には、さまざまなモデルがあり、さらにそれぞれのモデルにはその予測性能を大きく左右するハイパーパラメータというものがあります。どのモデルを使って、どのようにハイパーパラメータを設定すれば良いかを判断することは難しいです。そこで、scikit-learnのmodel_selectionモジュールでは、モデルの選択や評価、ハイパーパラメータの決定に役立つさまざまな機能が提供されます。また、そのために、学習済モデルを評価する機能も含まれています。
前処理
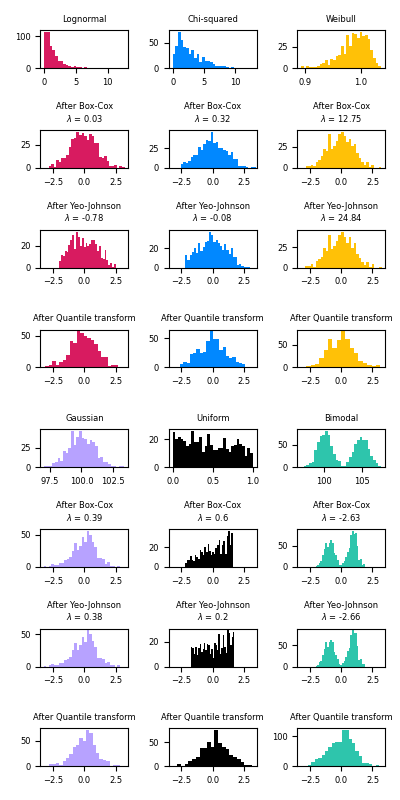
機械学習では、学習を行う前に正規化や標準化などの前処理を行います。これらの前処理を行うことで、一部のデータの影響だけが増幅されてしまい、偏った学習結果を得ることを避けるためです。scikit-learnのライブラリを使えば、元データが様々な分布を持っていたとしても、機械学習に適した正規化または標準化されたデータに容易に変換することができます。
チートシート
数多くの機械学習モデルがあるので、どのモデルを使うか迷います。
そんなときは、チートシートが役立ちます。
1. カテゴリー予測のとき:
- ラベルありのデータ(教師あり) → クラス分類: 確率的勾配降下法, 線形サポートベクター, k-近傍法, 単純ベイズ etc.
- ラベルなしのデータ(教師なし) → クラスタリング: k-平均法, MiniBatch k-平均法, MeanShift etc.
2. カテゴリー予測でないとき:
- 数値を予測するとき → 回帰分析: 確率的勾配降下法, ラッソ回帰, リッジ回帰 etc.
- ただの分析の場合 → 次元削減: 主成分分析, カーネル近似, 次元圧縮 etc.
![ml_map[1].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F80231%2Fbb55c5e9-c2aa-5cb5-adb6-a3b462231c5a.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=7d7c08befdc9e998cd36b3ceeab03d6b)
参考