kaggleで使われている機械学習モデルのLightGBMの理論を論文からしっかりと理解する
1. 導入
機械学習案件を獲得に向けてkaggleのメダルを獲ることを目標として機械学習チームを発足し、kaggleに挑戦しています。その中で、kaggleでよく使われる機械学習関連の理論について理解し、それをアウトプットしようということになったので、理論についてしっかりと理解した記事内容を残すことにします。
![]() 注意
注意 ![]()
本記事は独学での理解をアウトプットしたもので理論の理解が正しいことは保証できません。もし誤りがあればコメントや訂正PRを投げていただけると幸いです。
LightGBMの論文:
対象読者
- kaggleでLightGBMを使っているが理論を理解したい人
- lightGBMが誕生した背景を知りたい人
- lightGBMの周辺知識を知りたい人
2. lightGBMの周辺知識
![]() lightGBMの理論を調べたところ他にも深く理解できていないものが多数あったので、ここで紹介させていただきます。正直理論を理解するところまではいけるが、数式まで完全に説明できるかは疑問・・・。
lightGBMの理論を調べたところ他にも深く理解できていないものが多数あったので、ここで紹介させていただきます。正直理論を理解するところまではいけるが、数式まで完全に説明できるかは疑問・・・。
lightGBMが生まれた背景:
決定木やGradient Boost Tree (GBDT)アルゴリズムで良い精度は出ているものの、全ての特徴量やデータから、全ての分岐点などを探索する必要があり、データ量や特徴量が多くなった時に学習効率が悪くなる。そこで、学習効率を上げるためにXGBoostやLightGBMなどのデータ量や特徴量を削減して学習するアルゴリズムが開発された。
→ 通常、ビンはデータよりもはるかに小さいため、ヒストグラムの構築が大半の計算量を占めます。そのため、データインスタンスと特徴量を減らすことがGBDTの学習を大幅に高速化することにつながります。
LightGBMでは、勾配の大きさや、特徴量のデータ種別などから学習時に削減しても精度に大きな影響がでないデータを選択し、削減するという手法をとっている。
↓ 論文の記載によるとGBDTと同じ精度を保ちながら20倍早く学習プロセスを完了させられるらしい。

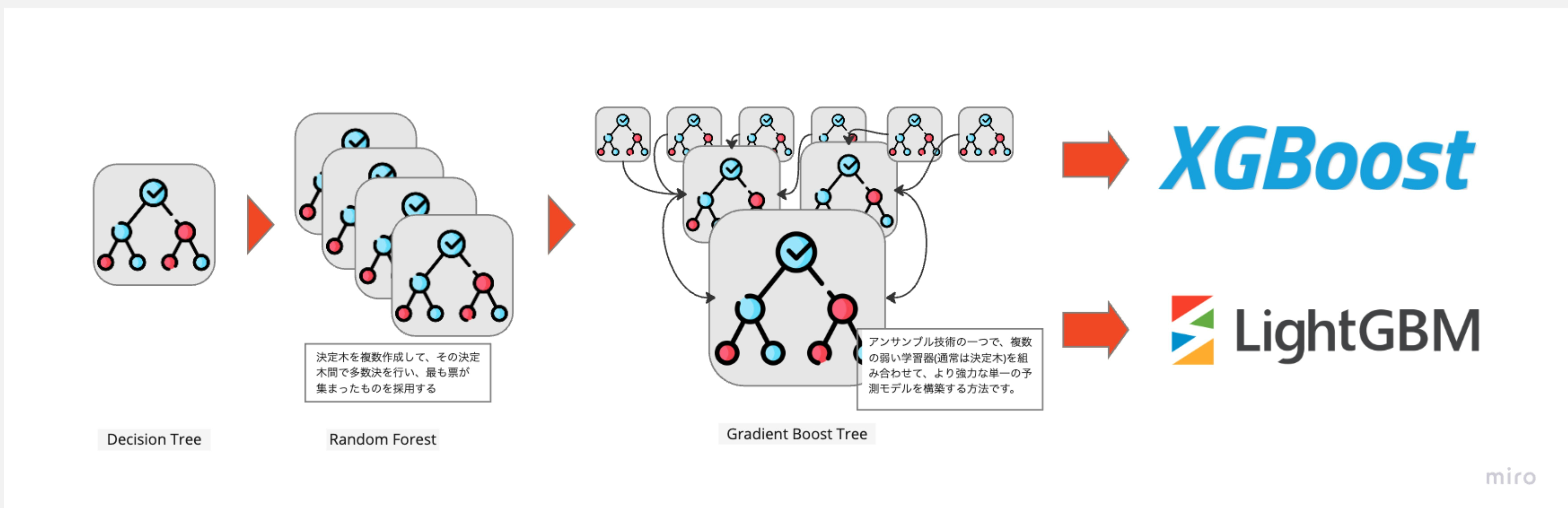
lightGBMを理解するのに理解する必要がある知識
- 決定木
- lightGBMは決定木を利用した機械学習モデルのため、大元の決定木を理解する必要があります
- 決定木を利用したモデルには以下のようなものがあります
- lightGBM
- XGBoost
- Random Forest
- アンサンブル学習
- 複数のモデルを組み合わせて学習器を生成する機械学習の手法です
- 各学習器の予測結果から多数決を取ることで制度の高い予測結果を出力します
- 勾配ブースティング
- アンサンブル学習にはスタッキング、バギング、ブースティングという手法があります
- ブースティングは1つ前の弱学習器の誤差を次の学習器にも伝搬させて、複数の学習器をアンサンブルさせて誤差を小さくしていく学習の方法です
- 勾配ブースティングの説明についてはこちらの記事がわかりやすかったです
- XGBoost
- 決定木を利用した機械学習モデルの一種で、lightGBMは決定木の成長の仕方にLeaf-wiseを採用しており、XGBoostはLevel-wiseを採用しています(後述)
- lightGBM論文内
-
 GOSS(Gradient-based One-Side Sampling)
GOSS(Gradient-based One-Side Sampling) -
EFB(Exclusive Feature Bundling)
-
![]() 特にGOSSとEFBがlightGBMの論文にも出てくる重要な概念のようです。
特にGOSSとEFBがlightGBMの論文にも出てくる重要な概念のようです。
決定木の理論を理解する
アンサンブル学習と勾配ブースティング
lightGBMとXGBoost
lightGBMとXGBoostの違い
こちらの記事でまとめられていますが、主な違いとしては「XGBoostではLevel-wiseを採用しており、LightGBMではLeaf-wiseです。」ということです。
<!--
以下にlevel-wise, leaf-wiseの理論の意味と、違いを説明する
-->
3. 論文:LightGBM: A Highly Efficient Gradient Boosting Decision Tree
論文内で記述されているLightGBMの数式:
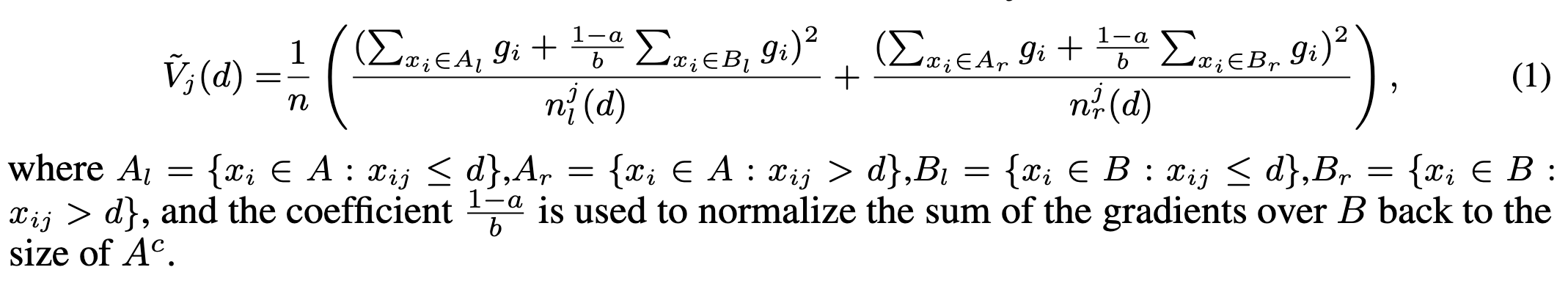
まずはAbstractをみてみる
 Abstract(英語本文)
Abstract(英語本文)
Gradient Boosting Decision Tree (GBDT) is a popular machine learning algo- rithm, and has quite a few effective implementations such as XGBoost and pGBRT. Although many engineering optimizations have been adopted in these implemen- tations, the efficiency and scalability are still unsatisfactory when the feature dimension is high and data size is large. A major reason is that for each feature, they need to scan all the data instances to estimate the information gain of all possible split points, which is very time consuming. To tackle this problem, we propose two novel techniques: Gradient-based One-Side Sampling (GOSS) and Exclusive Feature Bundling (EFB). With GOSS, we exclude a significant propor- tion of data instances with small gradients, and only use the rest to estimate the information gain. We prove that, since the data instances with larger gradients play a more important role in the computation of information gain, GOSS can obtain quite accurate estimation of the information gain with a much smaller data size. With EFB, we bundle mutually exclusive features (i.e., they rarely take nonzero values simultaneously), to reduce the number of features. We prove that finding the optimal bundling of exclusive features is NP-hard, but a greedy algorithm can achieve quite good approximation ratio (and thus can effectively reduce the number of features without hurting the accuracy of split point determination by much). We call our new GBDT implementation with GOSS and EFB LightGBM. Our experiments on multiple public datasets show that, LightGBM speeds up the training process of conventional GBDT by up to over 20 times while achieving almost the same accuracy.
![]() Abstract(DeepL日本語訳)
Abstract(DeepL日本語訳)
勾配ブースティング決定木(GBDT)は一般的な機械学習アルゴリズムであり、XGBoostやpGBRTなど多くの効果的な実装がある。これらの実装では多くの工学的最適化が採用されているが、特徴量の次元が高く、データサイズが大きい場合、効率とスケーラビリティはまだ満足できるものではない。その主な理由は、各特徴について、可能性のある全ての分割点の情報利得を推定するために、全てのデータインスタンスをスキャンする必要があり、非常に時間がかかるからである。この問題に対処するために、我々は2つの新しい手法を提案する: 勾配に基づく片側サンプリング(GOSS)と排他的特徴バンドル(EFB)である。GOSSでは、勾配が小さいデータインスタンスのかなりの部分を除外し、残りの部分のみを情報利得の推定に用いる。より大きな勾配を持つデータインスタンスは情報利得の計算においてより重要な役割を果たすので、GOSSはより少ないデータサイズでかなり正確な情報利得の推定が可能であることを証明する。EFBでは、特徴数を減らすために、互いに排他的な特徴(すなわち、同時に非ゼロ値をとることが少ない)を束ねる。我々は、排他的特徴量の最適な束ね方を見つけることはNP困難であるが、貪欲なアルゴリズムがかなり良い近似比を達成できることを証明する(したがって、分割点決定の精度をそれほど損なうことなく、特徴量の数を効果的に減らすことができる)。我々はGOSSとEFBを用いた新しいGBDT実装をLightGBMと呼ぶ。複数の公開データセットを用いた実験により、LightGBMは従来のGBDTの学習プロセスを最大20倍以上高速化し、ほぼ同じ精度を達成することが示された。
![]() histogram-baseアルゴリズムのヒストグラムの構築には
histogram-baseアルゴリズムのヒストグラムの構築にはdata×featureだけのコストがかかり、分岐点の探索にはbin×featureだけのコストがかかります。なのでデータの数・特徴量の数が増えればそれに比例して学習時間がかかる。
- bin = 全データの中から設定したbinの数だけデータを取得してきてその中で学習する時の単位数
- feature = 特徴量
(lightGBMの説明範囲だが間に合っていない)
以下は論文の文章を抜き出したものなのだが、histogram-based algorithmでは計算量として、「ヒストグラムの構築」に"データ量✖️特徴量数"の計算量、ノードの分割ポイントを見つけるのに"bin数✖️特徴量数"の計算量が必要なので、データ量と特徴量数を減少させることができれば、計算速度をUPすることができる。
As shown in Alg. 1, the histogram-based algorithm finds the best split points based on the feature histograms. It costs O(#data × #feature) for histogram building and O(#bin × #feature) for split point finding. Since #bin is usually much smaller than #data, histogram building will dominate the computational complexity. If we can reduce #data or #feature, we will be able to substantially speed up the training of GBDT.
そのため、GOSSでデータ量の削減、EFBで特徴量の削減を行っている。
GOSS(Gradient-based One-Side Sampling)
GOSSでは、勾配が小さいデータインスタンスのかなりの部分を除外し、残りの部分のみを情報利得の推定に用いる。より大きな勾配を持つデータインスタンスは情報利得の計算においてより重要な役割を果たすので、GOSSはより少ないデータサイズでかなり正確な情報利得の推定が可能であることを証明する。
除外してしまっても構わない分のデータを処理しないことで高速化を実現してる。かつ、精度は落とさず少ないデータ量での学習を可能にしている。
EFB(Exclusive Feature Bundling)
EFBでは、特徴数を減らすために、互いに排他的な特徴(すなわち、同時に非ゼロ値をとることが少ない)を束ねる。我々は、排他的特徴量の最適な束ね方を見つけることはNP困難であるが、貪欲なアルゴリズムがかなり良い近似比を達成できることを証明する(したがって、分割点決定の精度をそれほど損なうことなく、特徴量の数を効果的に減らすことができる)。
NP困難、排他的な特徴がよくわからない。
EFBでは、特徴量を減らすために排他的な特徴を束ねて使っている。その束ね方についてはNP困難らしいが、貪欲法を利用することで精度を損なうことなく特徴量の削減に成功している。
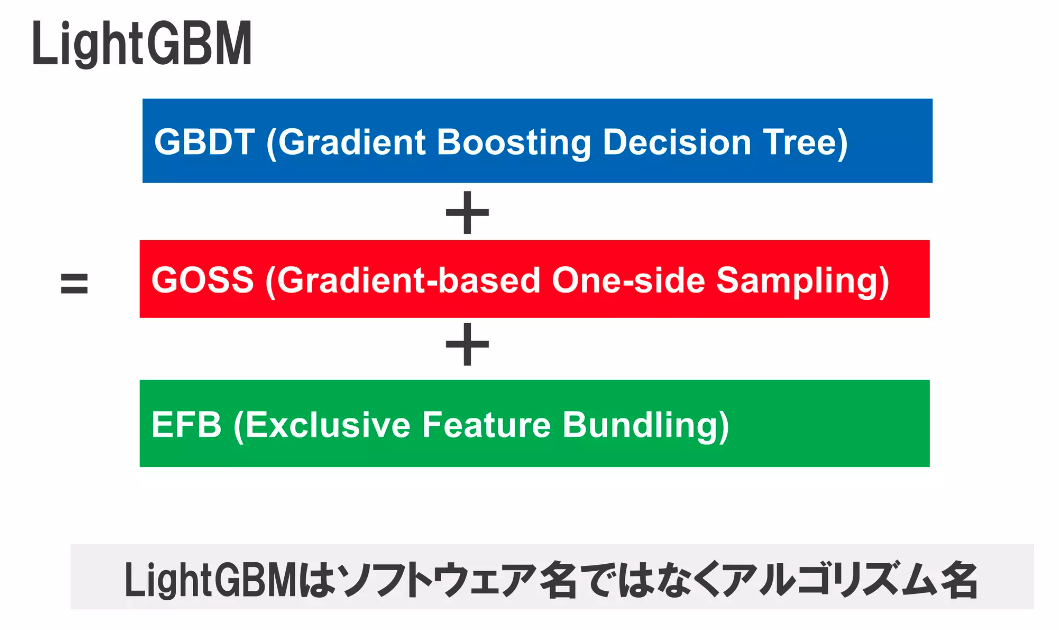
上記のサイトを参考にさせていただいたのですが、LightGBMのアルゴリズムはGBDT + GOSS + EFBとなっています。
![]() ということは前章で勾配ブースティングを紹介しているので、GOSSとEFBを理解すればLightGBMがなんたるかを理解できるはず!
ということは前章で勾配ブースティングを紹介しているので、GOSSとEFBを理解すればLightGBMがなんたるかを理解できるはず!
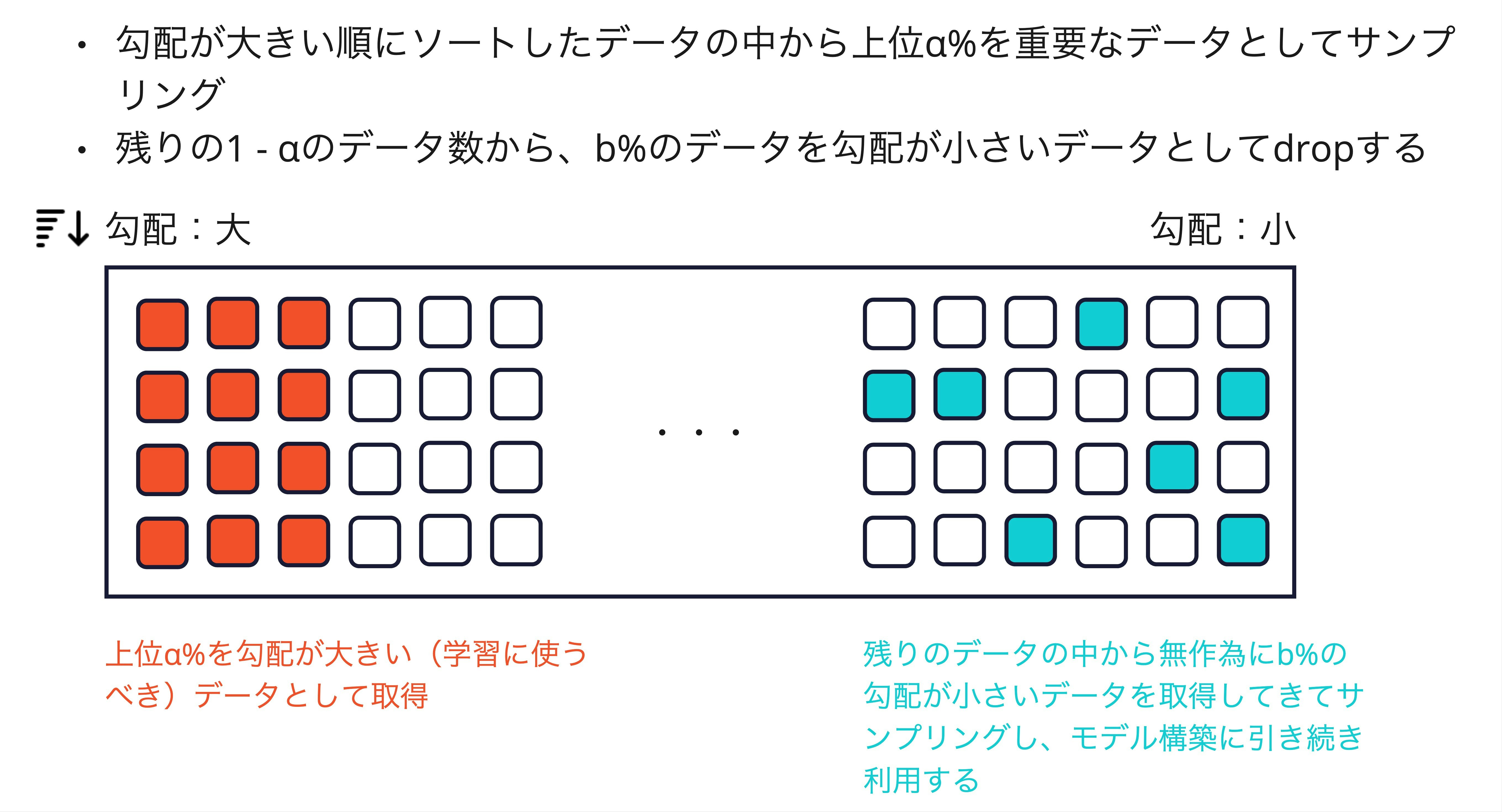
Gradient-based One-Side Sampling (GOSS)
LightGBMのGradient-based One-Side Sampling (GOSS)は、データセットのサブセットを選択するための効率的な手法です。これは特に勾配ブースティングにおいて用いられます。GOSSでは、以下の手順に従ってデータをサンプリングします。
-
勾配の大きさに基づくサンプリング: GOSSでは、全データポイントの勾配の絶対値に基づいて、上位$\alpha$% のデータを選択します。これらは「大きな勾配を持つデータ点」と見なされ、モデルが学習する際に最も重要とされます。
-
ランダムサンプリング: 残りの$100− \alpha$%のデータポイントの中から無作為に$b$%を選びます。これらは「小さな勾配を持つデータ点」と見なされます。
-
損失関数の調整: GOSSでは、小さな勾配を持つデータ点に対して大きな重みを与えることで、ランダムサンプリングによる情報の損失を補います。具体的には、小さな勾配を持つデータ点の損失関数に$\frac{1−a}{b}$の係数を乗じます。
数式の理解
GOSSではinformation gainというものがどれくらいモデルの改善に寄与できるかの指標として利用されているようです。information gainを計算するために決定木の各ノードの最適な分割店$d$を見つける必要があります。この分割点$d$を見つける際には、勾配が大きいデータと小さいデータに分け、それぞれのデータのモデルの出力の予測値と実際の値の誤差を計算して、その誤差のvariance(分散)をとります。
このvarianceが大きいほど予測値が誤っている割合が大きいので、varianceが減少するように重みを調整して、varianceの減少を目指します。
実際に論文に記載されていた数式部分のそれぞれの値の意味を理解しようとしたメモがこちらです。

Exclusive Feature Bundling (EFB)
Exclusive Feature Bundling (EFB) は、LightGBM において特徴量を効率的に処理するための技術です。特徴量の数が多い場合、モデルの訓練には多大な計算コストがかかります。EFB はこの問題に対処するため、互いに排他的(exclusiveな: 同時にゼロではない値を取らないような)な特徴量を束ねます(bundle)。bundleを一つの特徴量として処理し、より少ない数の複合特徴量を生成します。これにより、計算コストを削減しながら、情報の損失を最小限に抑えることで処理の高速化を実現しています。
EFB のプロセスは以下のように概説されます:
-
特徴量の分散の分析: まず、各特徴量の分布を分析します。特徴量がスパース(つまり、ほとんどの値がゼロ)である場合、これらは他の特徴量と結合される可能性があります。
-
互いに排他的な特徴量の同定: 次に、互いに排他的、またはほぼ排他的な特徴量を同一のものとみなします。これは、2つの特徴量が同時にゼロ値を取る、またはNONEゼロ値を同時に取る場合が非常に稀なときに特徴量を同一のものとして合成して特徴量数を減らします。
GPT-4に書いてもらった排他的なデータを同定する処理。同時にゼロ値を取らないデータを同定する処理をしている。
列ごとに見た時、同じ列に非ゼロ値が存在している場合は排他的ではないものとみなす。よって同じ列にゼロ値以外を取る列以外は結合(bundle)して1つの特徴量とみなし、特徴量の数を削減している。
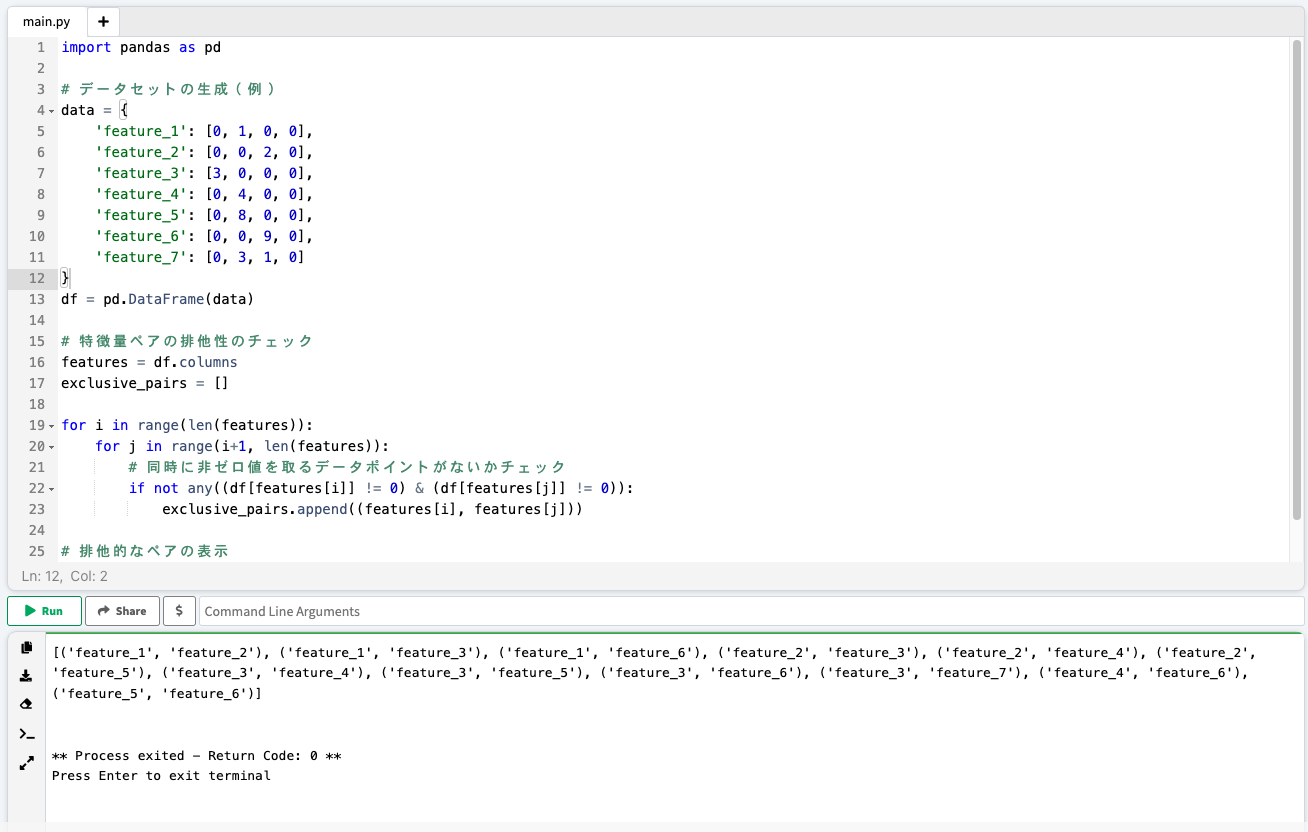
-
特徴量の結合: 排他的な特徴量は、一つの複合特徴量に「束ねられます」。これは、それぞれの個別の特徴量が取り得る値の範囲を考慮して行われます。結合された新しい特徴量は、元の特徴量よりも多くの値を取ることができますが、それでも元の特徴量の総数よりは少なくなります。
-
データの変換: 元のデータセットは、これらの新しい複合特徴量に基づいて変換されます。この変換により、モデルの訓練と予測における計算コストが削減されます。
結び
- lightGBMでは0値をそのまま学習できるという利点は聞いていたが、いまいちなぜなのかは分かってなかった。→学習率への寄与度が大きいデータや0値を取る特徴量の削減を行うので、0値を残しておいてもOKということがわかった。
- lightGBMは基本的には決定木で、決定木の最適な分割点を見つける際に不要なデータ削減を行い、処理を効率化して高速に処理できるようにするアルゴリズムだということがわかった
- EFBの箇所が完全には理解できていないが大枠の処理内容がわかった
- 決定木の最適な分割点を見つける方法がわかった(histogram-base algorythm)
主な参考資料