目的
・顧客へのサービス提供
・何らかの理由で鯖落ちしてたときなどに、ユーザーからの問い合わせより前に
こちら側が先に気づける仕組みを作りたい。
手段
サーバーの死活監視
(GCPのUptime Checkを活用します。)
実現するための構想
Stackdriver(Monitoring)→Pub/Sub→Cloudfunctions→Chatwork
StackdriverでGCEの異常を検知し、Pub/Subを経由しCloudfunctionsからChatworkへ通知
という流れで構築していきます。
GCE(Google Compute Engine)のStackdriver-Monitoringの通知チャンネルを設定し
GCEに異常があればStackdriverからインシデントアラートをPub/Subに送り、
Pub/SubからCloudfunctionsで取得してチャットワークへ通知する。
(Chatworkトークンなどは準備済のため、今回は割愛する。)
あと、通知アラートを直接Pub/Subに送る機能(通知チャンネルにPub/Subを設定すること)は
まだベータ版のようで、導入するのにGcloudコマンドラインツールが必要になるため、
一旦アラート通知はEmailを設定して動作を確認し、後ほどPub/Subに載せ替える流れにしています。
日本語版にはドキュメントがなく英語版でしか確認できない機能だったので、
ちょっと苦労したんですが、無事に導入できたので、ご紹介します。
では実際にやってみる。
無事に顧客への導入も行いましたので、同様の業務が必要になったときは、参考になれば嬉しいです。
GCEインスタンスを立ち上げる。
GCPに登録
メールアドレスとかパスワードとか入力して登録。
クレジットカード番号も必要だけど無料で使えます。(約12ヶ月分の無料枠アリ)
プロジェクトを作る
プロジェクト名とか入れるぐらい。
左上ナビゲーションメニューからVMインスタンスのページへ飛ぶ
コンピューティング→Compute Engine→VM インスタンス
(それぞれ名前の横にピン留めできるボタンがあるので、よく使うものはピン留めすると良いと思います。)
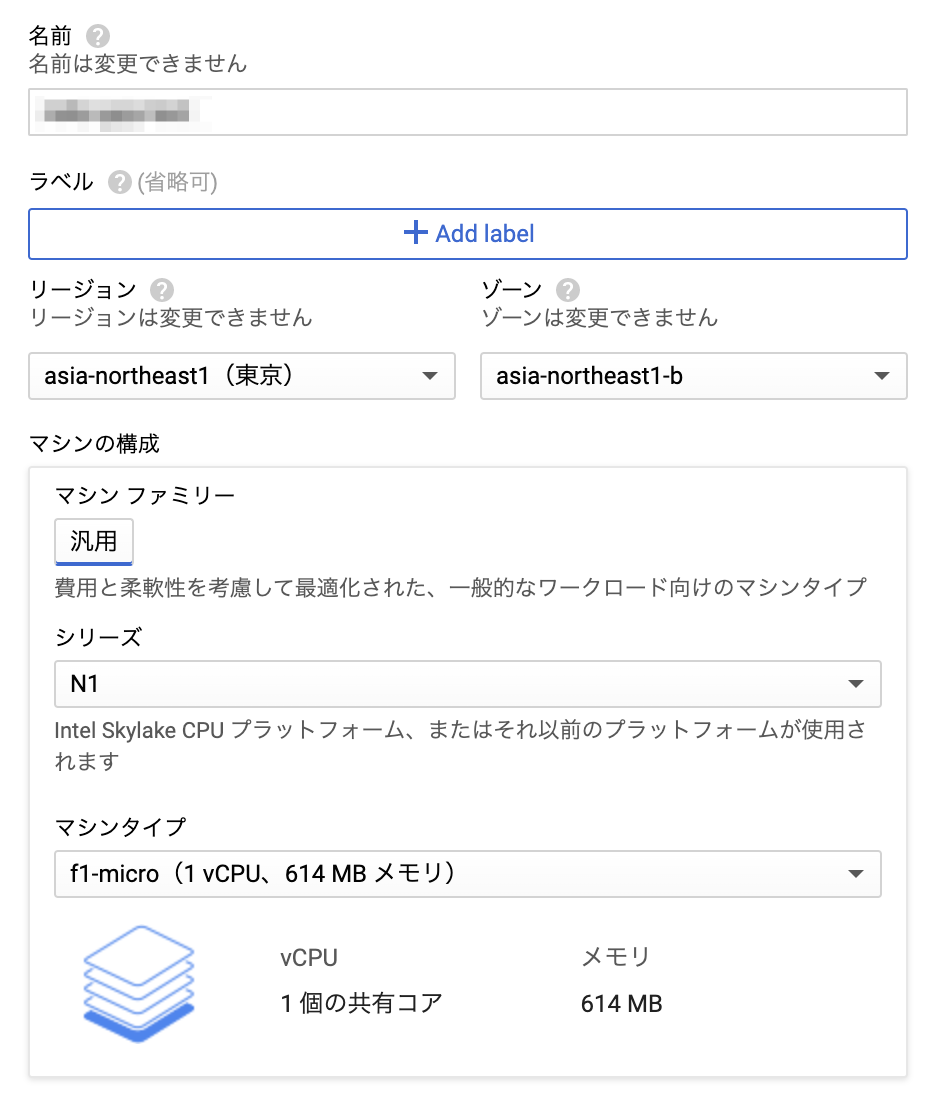
- インスタンスを作成
- インスタンス名
- リージョン(色々あるけどasia-northeast1で良いかと。)
- ゾーン
- マシンタイプ(今回はf1-microに設定。)
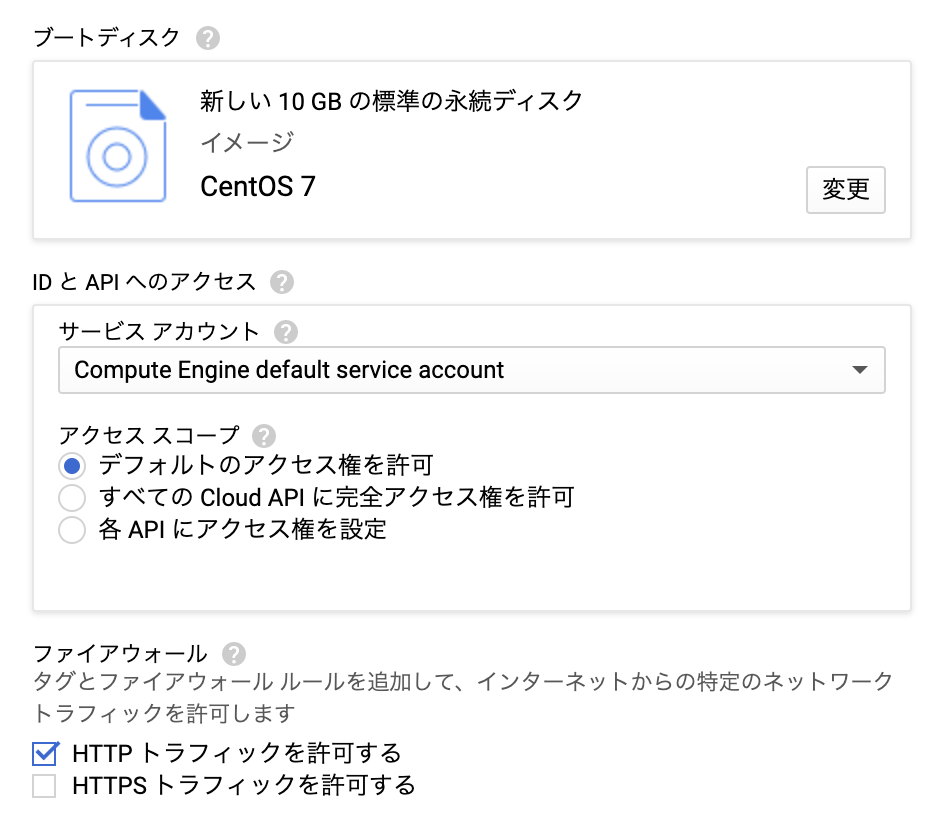
- ブートディスク(CentOS 7に設定。)
- HTTPトラフィックを許可する
ページ下部の「作成」を押下しちょっと待つとインスタンスが立ち上がる。
StackDriverでMonitoringする。
左メニューからStackdriver Monitoringのページへ飛ぶ
OPERATIONS→Monitoring→Overview
アラートポリシーを追加
Create Alert PoliciesのCREATE POLICYをクリックし、ポリシー追加ページへ

- アラートポリシーを設定
- 名前
- Condition
- Target(アラートを上げるトリガー・条件について設定)
- Aggregator
- Configuration(確認頻度などの設定)
- Notification(通知方法)
- Documentation(通知内容)
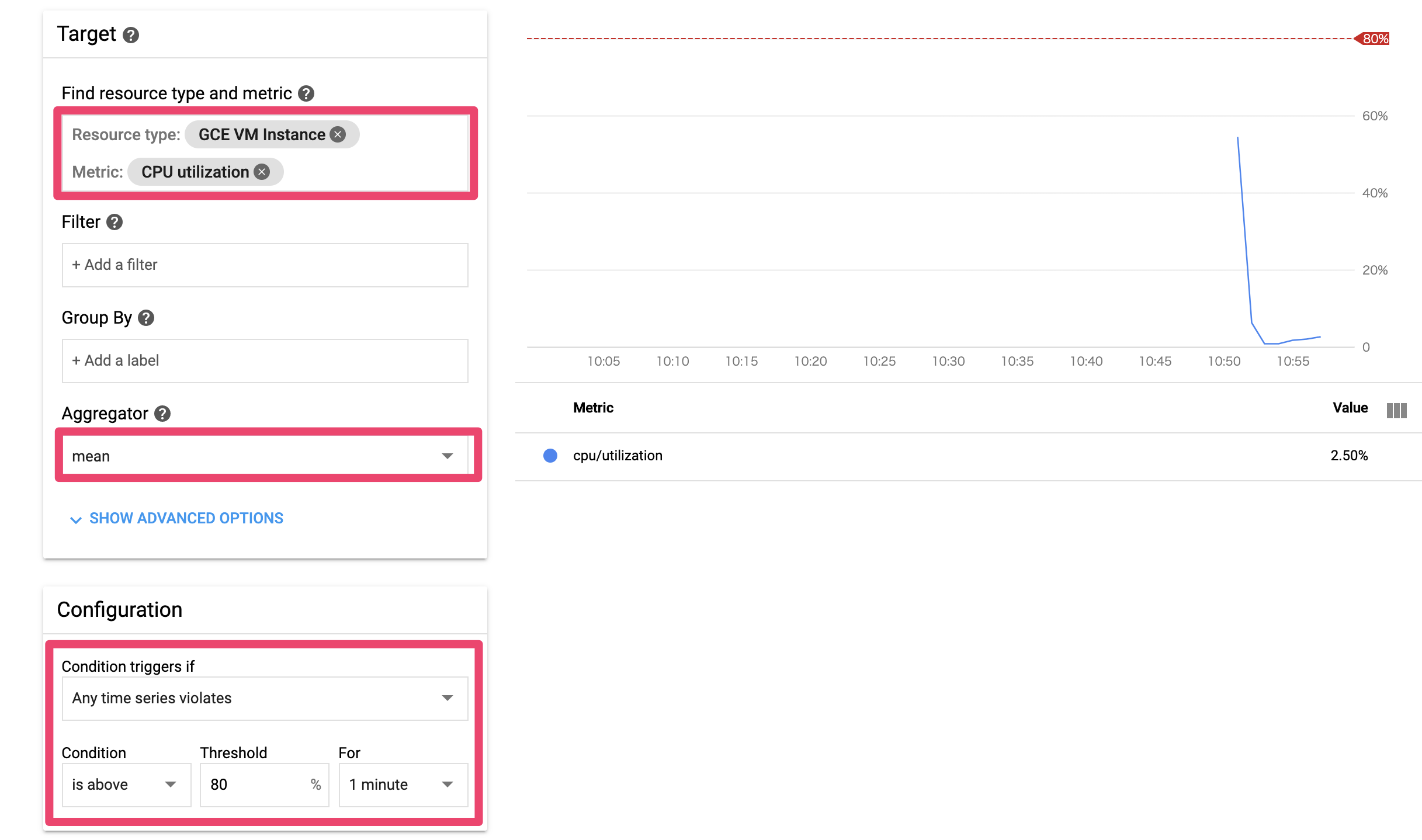
例えば…
自前で立ち上げたGCEインスタンスのCPU使用率が80%を閾値に監視したい、
かつ、アラート対象状態になった場合にメールで通知してほしい
- Condition
- Target:GCE VM Instance、CPU Utilization
- Aggregator:mean
- Configuration:Any Time、is above、80、1minute
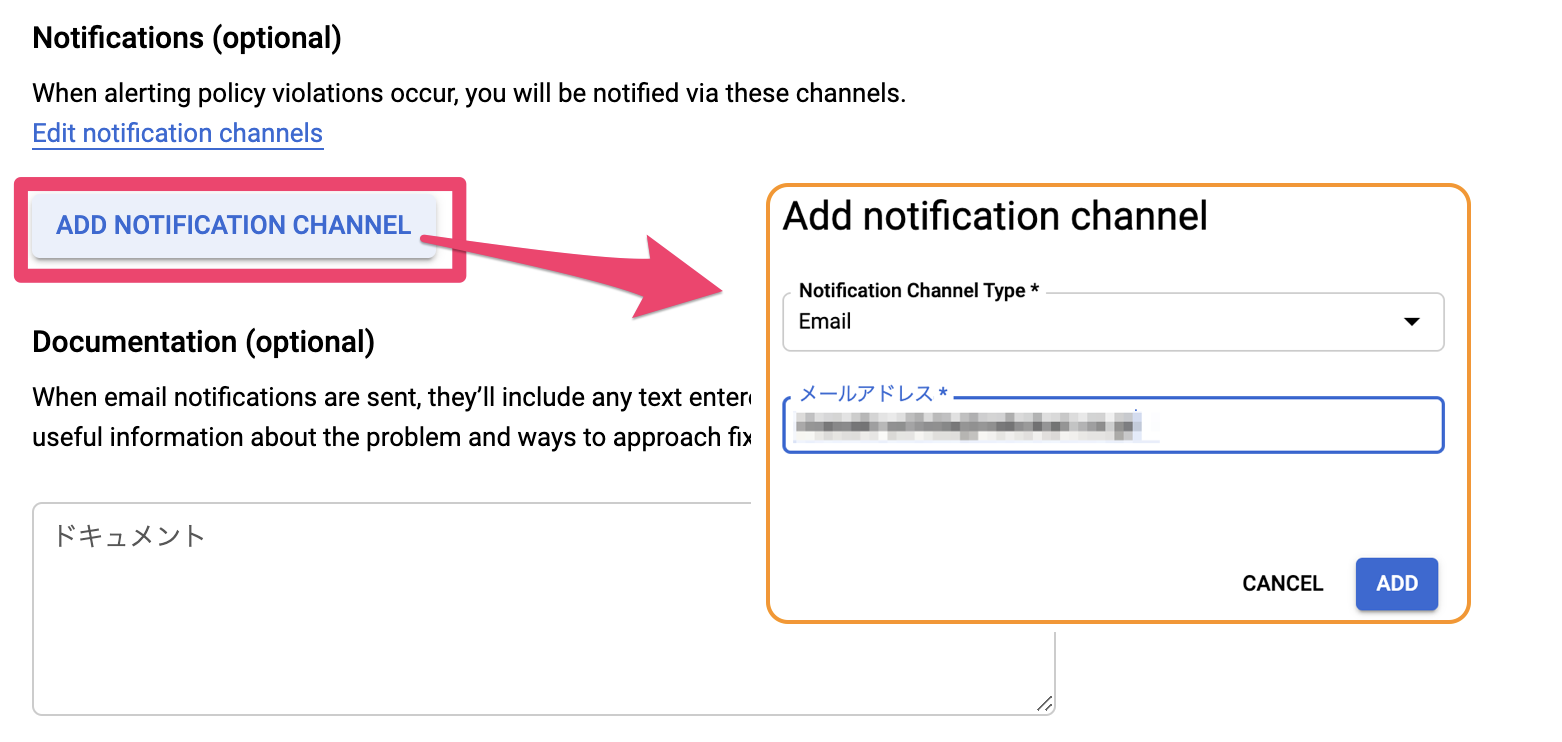
- Notification
- Email(自分のメールアドレスを指定)
GCEインスタンス内でWebサーバーを立ち上げる
アラートを設定し終わったら、VMインスタンスのダッシュボードページに戻る。
先ほど設定したインスタンスが表示されているはず。
画面右側のSSHをクリックすると、コンソールが立ち上がり、インスタンス内に接続した状態になっている。
$ sudo su
$ yum install httpd -y
$ systemctl start httpd.service
問題なくサーバーが立ち上がったようであれば
$ echo '<!doctype html><html><body><h1>Hello World!</h1></body></html>' | sudo tee /var/www/html/index.html
その後Chromeとかブラウザのアドレスバーに
http://外部IP
を入力して、ページにHello World!が表示されていればOK
負荷をかけてみる。
サーバーが立ち上がっている状態で、
$ yes > /dev/null &
このコマンドでCPU使用率はバチバチに跳ね上がっていきます。
インスタンスの設定でCPU増やしてたりする場合は、その分実行すればOK?
ちなみにCPU使用率を確認する際は、
$ top
topコマンドを実行すると立ち上がっているプロセスそれぞれのCPU使用率が一覧される。
しばらく放っておくと、アラートポリシーで登録したメールアドレス宛にAlertのメールが飛んでくる。
まずはこのメールが届けばOK。
Health Checkで死活管理してみる。
MonitoringのページからUptime Checksの設定を行う。

- 項目
- Title
- Check Type(HTTP、HTTPS、TCP)
- Resource Type(URL、App Engine、Elastic Load Balancer、Instance)
- Host Name
- Path
- Check Every
例えば。

ResourceTypeをURLに設定し、HostNameにgoogle.co.jpと入力し、
TESTをクリックすると、 Responded with 200 (OK) in 〜〜 となるはず。

- ということで
- ResourceTypeをInstance
- Instanceのフォームが出てくるので、上記で設定したインスタンスを選んでみる。
同じくTESTを押すとレスポンスが得られたことがわかるはず。
仮にここでエラーが出る場合は、インスタンスorWebサーバーが立ち上がっているか、今一度確認。
問題なくレスポンスが帰ってきていることがわかった場合は、そのままSAVE。
Uptime Check用のPolicies設定
先ほどSAVEを押下したところでPolicies設定する?みたいなモーダルが出てくるはず。
先ほどのアラートポリシー設定とは違い、大半の項目は入力済となっている。
モーダル下部にあるConfiguration -> Forの項目を編集するだけでOK。
※この項目は、何分間サーバーへの接続試行に失敗したらアラートを出す、という設定。
※※テスト段階は1(1分間)で良いかと。
Webサーバーを落としてEメールが来るかを確認
root権限
$ systemctl stop httpd.service
これでWebサーバーは落ちるので、そのうちメールが来ればOK。
来ないようであれば上の設定たちを今一度見返す。
メールが来たらサーバーを立ち上げておこう。
(不用意にメールが来ても鬱陶しいと思うので。w)
$ systemctl start httpd.service
CloudFunctionsを設定する
自分はこの辺が俄然詰まった箇所。という前置きは置いといて…。
Cloudfunctionsのページを開き、諸々設定していくが、
以下の「トリガー」を「Cloud Pub/Sub」に設定することを忘れないように。
トピックはまだ作ってないので、新しく作るみたいなのをチョイス。
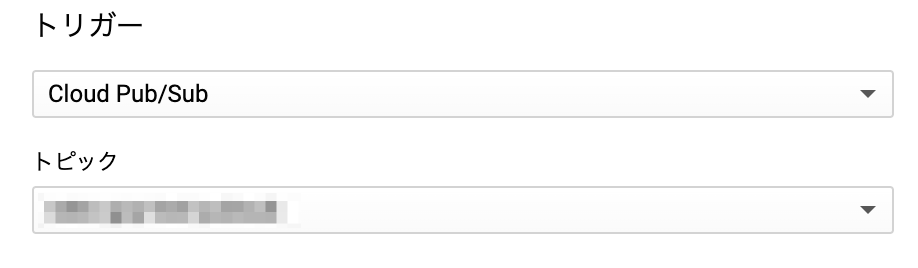
管理しやすいよう名前をつけて、トピック設定はOK。
ソースコードはインラインエディタのまま、ランタイム(使用言語)はお好きなものを。
(私はPython使いましたので、参考ソースもPythonで記載します。)
言語を切り替えると、画面下部のソースコードも切り替わるが、一旦そのままで。
その後、「環境変数、ネットワーキング、タイムアウト」などを押下しメニューを開くと、
リージョンの設定があるので、asia-northeast1に切り替えておく。
Pub/Sub通知チャンネルを作成する
ベータ版ということもあり、英語ドキュメントしかない。
(日本語にするとPub/Subの項目なくなるw)
https://cloud.google.com/monitoring/support/notification-options
英語に強いわけではないが、概ねこんな感じで理解してます。
- Pub/Subのトピック作る(今回は省略)
- 作ったPub/SubトピックをAlert-NotificationChannelに追加する
- 作ったPub/Subトピックにメンバー追加及び権限設定
という感じで進めていくが、1についてはさっきCloudFunctionsの設定の際に
トピックも作っているので、今回は省略してOK。
2.作ったPub/SubトピックをStackdriverの通知チャンネルに追加する
ローカルにpubsub-channel.jsonを作成し、
以下の内容を入力。(適宜置き換えて)
{
"type": "pubsub",
"displayName": "test notifications",
"description": "Pub/Sub channel for test notifications",
"labels": {
"topic": "projects/[PROJECT_ID]/topics/[PUBSUB-TOPIC-NAME]"
},
}
作成したJsonファイルをGcloudコマンドラインツールを導入したローカルのコンソール内で、
以下のコマンドを実行
$ gcloud beta monitoring channels create --channel-content-from-file="pubsub-channel.json"
Created notification channel ~~~~~~
となっていれば成功。
3.作ったPub/Subトピックにメンバー追加及び権限設定
[PROJECT_NUMBER]を2箇所置き換える必要がある。
これはGCPトップページに載っているのでそこからコピペでOK。
$ gcloud pubsub topics add-iam-policy-binding \
projects/[PROJECT_NUMBER]/topics/[PUB/SUB_TOPIC] --role=roles/pubsub.publisher \
--member=serviceAccount:service-[PROJECT_NUMBER]@gcp-sa-monitoring-notification.iam.gserviceaccount.com
以下のような返却があればOK。(XXXにも色々書いてある)
Updated IAM policy for topic [PUBSUB_NAME].
xxxxxxxxxxx
xxxxxxxxxxx
Stackdriver-Monitoringのアラート設定を確認する
Monitoring -> 設定 -> Edit Notification Channelから通知チャンネルの確認画面へいくと、
Cloud Pub/Sub[ベータ版]のところに先ほどjsonファイルにて追加した情報が載っているはず。
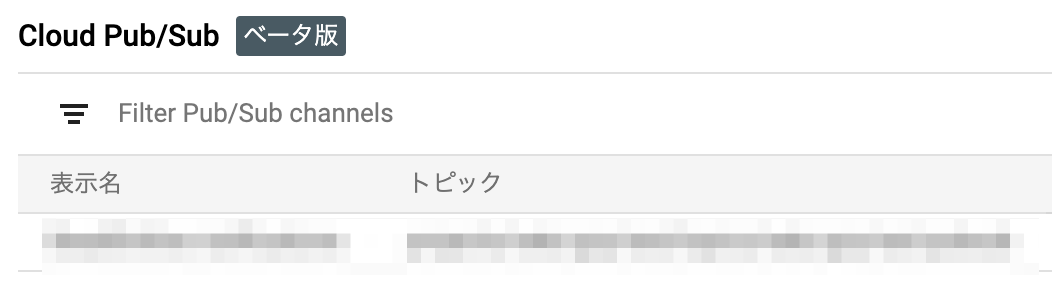
実際にアラートに設定する
Monitoring -> アラート -> Policiesと見ていくと、
先ほど設定したアラートポリシーが存在しているはず。
それを開いて、Notification Channelの編集をしていく。
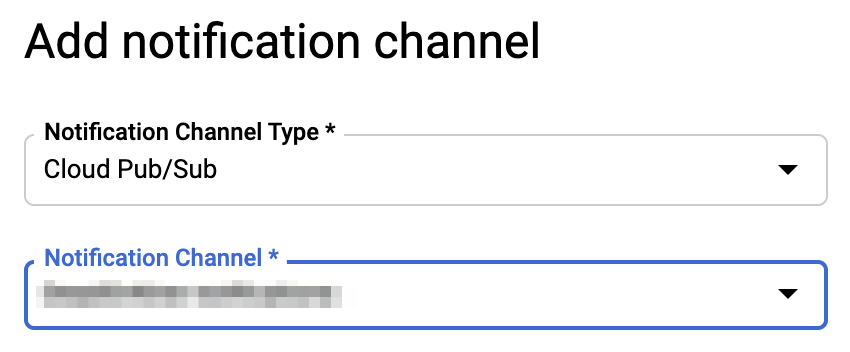
こんな感じで設定できればOK。
あとはもう一回サーバーを落として、アラートが上がるのを待とう。
ログを確認する
ログは【Logging】で確認できる。
設定が諸々できていれば、アラートが起きたタイミングで、
CloudFunctionsにログが飛んでくるはず。

インシデントログはJSONで飛んでくるようになっており、
どのインスタンスに問題が起きたか?
いつ問題が起きたか?
などなど様々しっかりと情報が載っている。
なのでこれらを取り分けて、それっぽく見えるようにする。
CloudFunctionsのソースを書き直そう。
今のままでは内容が読みづらいので、アウトプットをそれっぽく修正しよう。
実際に使ってるコードではなく、とりあえず動くよ!って段階のコードを転記してるため、
クオリティはお察し。。
とはいえ、ここはこうした方が見やすい!ってのがあったら教えてほしいです。
from datetime import datetime
from pytz import timezone
import base64
import json
import requests
import os
def hello_pubsub(event, context):
"""Triggered from a message on a Cloud Pub/Sub topic.
Args:
event (dict): Event payload.
context (google.cloud.functions.Context): Metadata for the event.
"""
pubsub_message = json.loads(base64.b64decode(event['data']).decode('utf-8'))
print(pubsub_message)
message = pubsub_message['incident']
incident_flag = message['state']
summary = message['summary']
# incident.summaryにはアラート内容の概要が飛んできているので、その内容で条件分岐。
if summary == 'An uptime check on [PROJECT_ID] [INSTANCE_NAME] is failing.':
summary = 'サーバーダウンを検知しました。'
elif summary == 'The uptime check for [PROJECT_ID] [INSTANCE_NAME] has returned to a normal state.':
summary = 'サーバー回復を確認しました。'
if incident_flag == 'open':
incident_flag = '障害発生'
start_date = datetime.fromtimestamp(message['started_at']) # UNIX時間→yyyy-MM-dd HH:mm:ss
jst = start_date.astimezone(timezone('Asia/Tokyo')) # UTC -> JST
elif incident_flag == 'closed':
incident_flag = '回復'
end_date = datetime.fromtimestamp(message['ended_at']) # UNIX時間→yyyy-MM-dd HH:mm:ss
jst = end_date.astimezone(timezone('Asia/Tokyo')) # UTC -> JST
mes = """
[info][title]検知: % s[/title]
発生時刻: % s
監視項目名: % s
対象リソース名: % s
エラー詳細URL: % s[/info]
""" % (
incident_flag,
jst,
summary,
message['resource_display_name'],
message['url']
)
# [info][title]はチャットワークへの通知で使うための記載
data = {
'body': mes
}
headers = {
'X-ChatWorkToken': TOKEN
}
requests.post(POST, headers=headers, data=data)
実際のログはこんな感じで変化する
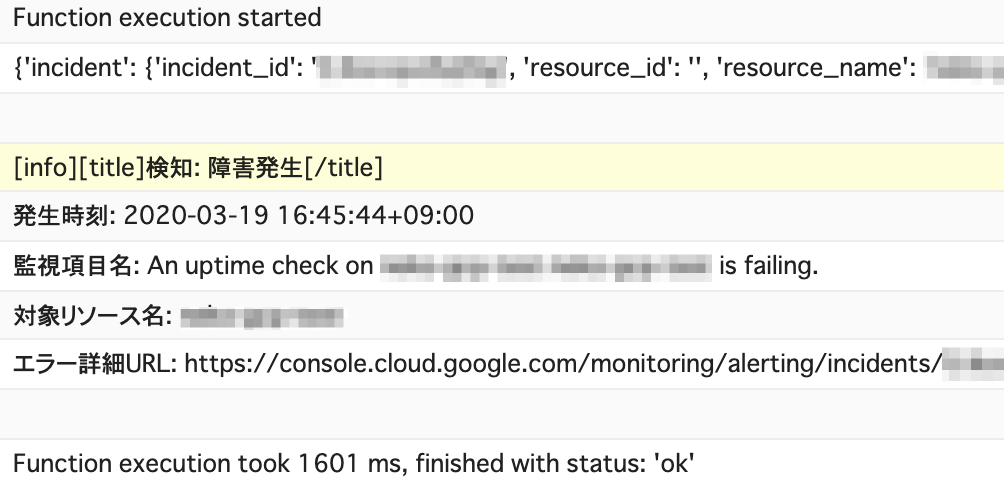
チャットワークへの通知を行おう。
チャットワークへの通知を行う場合、通知を行うROOMIDやTOKENが必要になるが、
これらはCloudFunctionsの環境変数に忍ばせよう。
(間違ってもソースに書いちゃダメだぞ☆)
CloudFunctionsの環境変数の設定
作成してあるFunctionsの設定を開き、画面下部にスクロールすると
[環境変数、ネットワーキング、タイムアウトなど]があるので、
そこから環境変数の設定ができる。

こんな感じで環境変数を設定したら、ソースの編集を行い、
環境変数を受け取るよう実装。
hello_pubsubの関数の前に記載しておけばOK。
TOKEN = os.environ.get('CW_TOKEN')
ROOMID = os.environ.get('CW_ROOMID')
URL = 'https://api.chatwork.com/v2/rooms'
POST = '{0}/{1}/messages'.format(URL, ROOMID)
これらを実装し終わったらデプロイを実行。
改めてアラートを出してみる。

チャットワークへ通知が飛びました。
まとめ
実際に自分でやりながら作っていったので、おそらくミスはないはず。。
今後この記事は自分にとっての手順書にします。笑
main.pyの実装については突っ込みどころが多いと思います。
そもそもの設定などこうしたほうがいいよ!ってのがあったら知りたいです。
最後に
株式会社ネコカリにて従事しています。
株式会社ネコカリでは猫の手も借りたい🔥炎上中🔥なお仕事を募集しています!
一緒に働くメンバーも募集していますので、よかったら是非!