この記事は「Google Cloud Platform Advent Calendar 2019」4日目の記事です。
GKEのベータ機能でノードプールにsurgeが設定できるようになって便利だよ、という趣旨の内容を書こうとしたのですが、
Google Cloud Japan Customer Enginner Advent Calendar 2019に1日先を越されてしまったため、surgeを設定した時とそうでない時に、ノードプールのアップグレードにどのような違いがあるのか、surgeを設定しないノードプールの場合にPodDisruptionBudgetが特定の条件下でどのような振る舞いをするのかを解説します。
現行のノードプールのアップグレードの挙動
まず、公式ドキュメントには次のように記載があります。
- ノードは閉鎖され、ドレインされます。この時点で、新しいポッドの実行がスケジュールできなくなります。
- PodDisruptionBudget は、1 時間使用可能です。
- GracefulTerminationPeriod は、1 時間に制限されます。
この「1時間使用可能です」の意味を理解し、現行のsurgeを設定しないノードプールのアップグレードの挙動を理解するのがこの節のゴールです。
まずはクラスタとノードプールを作成します。
$ gcloud beta container clusters create upgrade \
--disk-size=20 \
--num-nodes=1 --region=asia-northeast1 --node-locations=asia-northeast1-a \
--enable-stackdriver-kubernetes \
--cluster-version=latest
$ gcloud container node-pools create upgraded-pool --region=asia-northeast1 \
--cluster=upgrade \
--node-version=1.13.12-gke.13 \
--num-nodes=1
そして、次が今回の検証に使うマニフェストファイルです。
kind: Deployment
apiVersion: apps/v1
metadata:
name: nginx
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
name: nginx
labels:
app: nginx
spec:
affinity:
nodeAffinity: # upgraded-poolにスケジュールされるようにする
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: cloud.google.com/gke-nodepool
operator: In
values:
- upgraded-pool
containers:
- name: nginx
image: nginx:stable-alpine
resources:
requests:
cpu: 300m # ノード1つに2つのPodが載るように調整する
memory: 1Gi # てきとう
---
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: nginx
spec:
maxUnavailable: 1 # 同時に使えなくなってもよいPodが1つまで
selector:
matchLabels:
app: nginx
このマニフェストファイルをデプロイすると、Podは次のようなステータスになります。
$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx-6cc68796fc-bxncg 1/1 Running 0 16s 10.4.2.6 gke-upgrade-upgraded-pool-c8c5f2d7-p90l
nginx-6cc68796fc-zlvgr 1/1 Running 0 17s 10.4.2.5 gke-upgrade-upgraded-pool-c8c5f2d7-p90l
ここで、同じノードに2つのPodが載っている事実が重要です。
この状態でupgraded-poolのバージョンを上げようとした時の挙動を頭の中で思い描いてみてください。
まず、ノードをアップグレードするためにPodの再スケジュールが実行されます。
このとき、PodDisruptionBudget(PDB)の影響で、同時に使用不可能になってもよいnginxのPodは1つまでに制限されます。
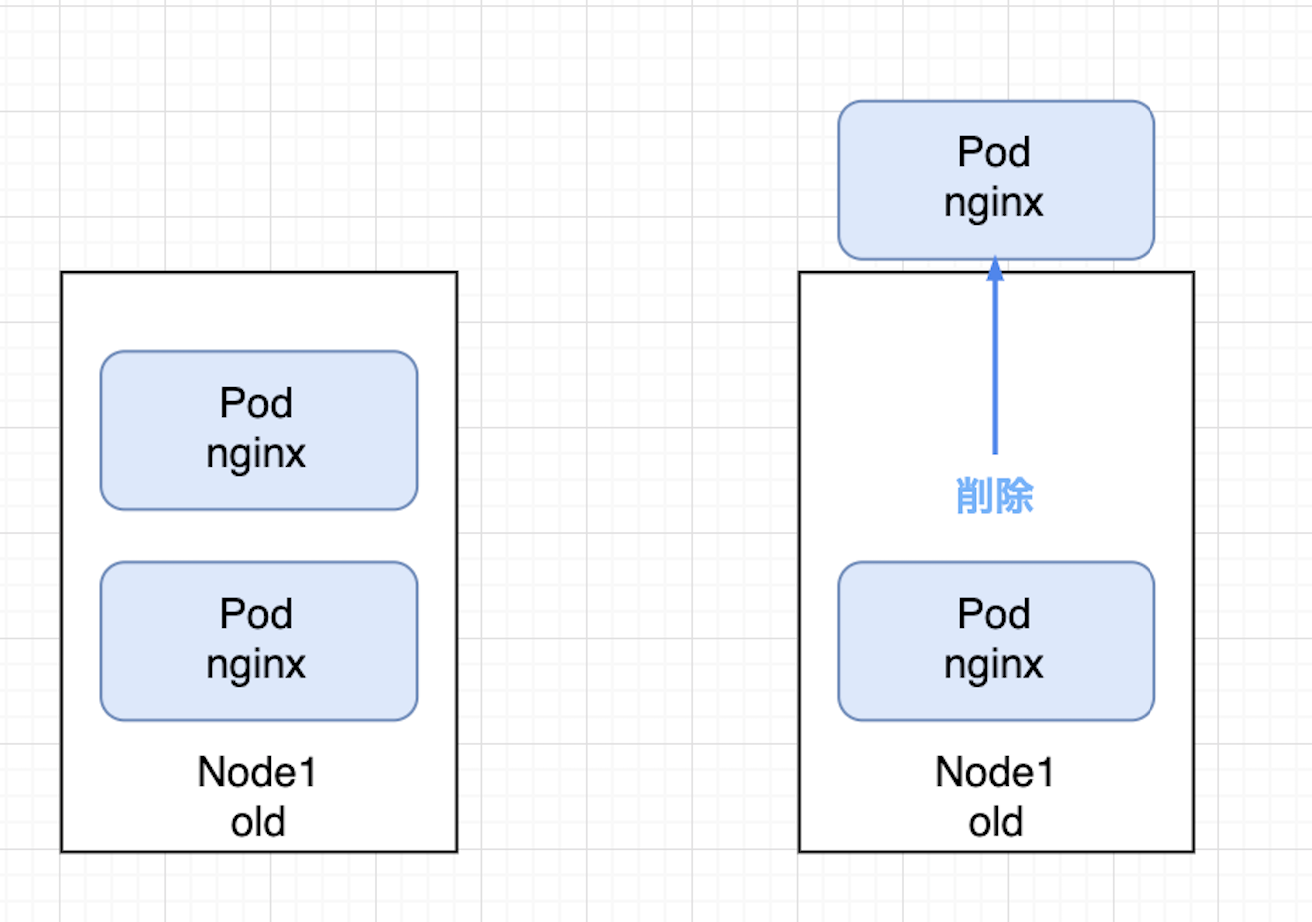
新しく起動しようとしているPodは他にスケジュール可能なノードが存在していれば、そのノードに再スケジュールされますが、今回はノードが1つしかないことに加え、そのノードはcordon状態なので再スケジュールができません。
PDBの制約により起動中のPodは再スケジュールできなくなり、ノードのアップグレードが実行できなくなってしまいました。
これを避けるために、「PodDisruptionBudget は、1 時間使用可能です。」という例外があります。
次の出力は、実際に1時間Podの状態を観測したものです。
※異なるタイミングで検証した結果を貼るので、Pod名などが異なります。
$ kubectl get po -w
NAME READY STATUS RESTARTS AGE
nginx-6cc68796fc-d548h 1/1 Running 0 9m41s
nginx-6cc68796fc-ppn4r 1/1 Running 0 9m41s
# まず1つのPodが削除される
nginx-6cc68796fc-d548h 1/1 Terminating 0 10m
# minReplica: 2を維持するために新しいPodを起動しようとするも、他にノードが無いのでPending状態となる
nginx-6cc68796fc-6bpbd 0/1 Pending 0 0s
nginx-6cc68796fc-6bpbd 0/1 Pending 0 0s
...(1時間後)
# 最初のPodを消して以降、1時間もの間新しく起動しようとしているPod
nginx-6cc68796fc-6bpbd 0/1 Pending 0 58m
# 古いNodeで起動し続けているPod
nginx-6cc68796fc-ppn4r 1/1 Running 0 59m
# 我慢の限界に達し、古いノードのPodを消そうとする。この時点で正常なPodが無くなる
## PDBのルールを無視していることに注目
nginx-6cc68796fc-ppn4r 1/1 Terminating 0 61m
# 新しいPodを作成しようとする
nginx-6cc68796fc-62hcn 0/1 Pending 0 0s
nginx-6cc68796fc-62hcn 0/1 Pending 0 0s
nginx-6cc68796fc-ppn4r 0/1 Terminating 0 61m
nginx-6cc68796fc-ppn4r 0/1 Terminating 0 61m
nginx-6cc68796fc-ppn4r 0/1 Terminating 0 61m
nginx-6cc68796fc-62hcn 0/1 Pending 0 72s
nginx-6cc68796fc-62hcn 0/1 Pending 0 72s
# きっとノードのアップグレードが終わったので起動できるようになった
nginx-6cc68796fc-62hcn 0/1 ContainerCreating 0 72s
nginx-6cc68796fc-6bpbd 0/1 Pending 0 61m
nginx-6cc68796fc-6bpbd 0/1 ContainerCreating 0 61m
nginx-6cc68796fc-6bpbd 1/1 Running 0 61m
nginx-6cc68796fc-62hcn 1/1 Running 0 94s
この時のノードの様子がこちら
※異なるタイミングで検証した結果を貼るため、ノードの名前が異なります
# cordonされ
gke-auto-upgrade-upgraded-pool-e6ee1938-350n Ready,SchedulingDisabled <none> 62m v1.13.12-gke.13
gke-auto-upgrade-upgraded-pool-e6ee1938-350n NotReady,SchedulingDisabled <none> 63m v1.13.12-gke.13
# upgradeされ
gke-auto-upgrade-upgraded-pool-e6ee1938-350n Ready,SchedulingDisabled <none> 63m v1.14.8-gke.17
# Ready状態
gke-auto-upgrade-upgraded-pool-e6ee1938-350n Ready <none> 63m v1.14.8-gke.17
ここまでの動きを図示するとこうなります。
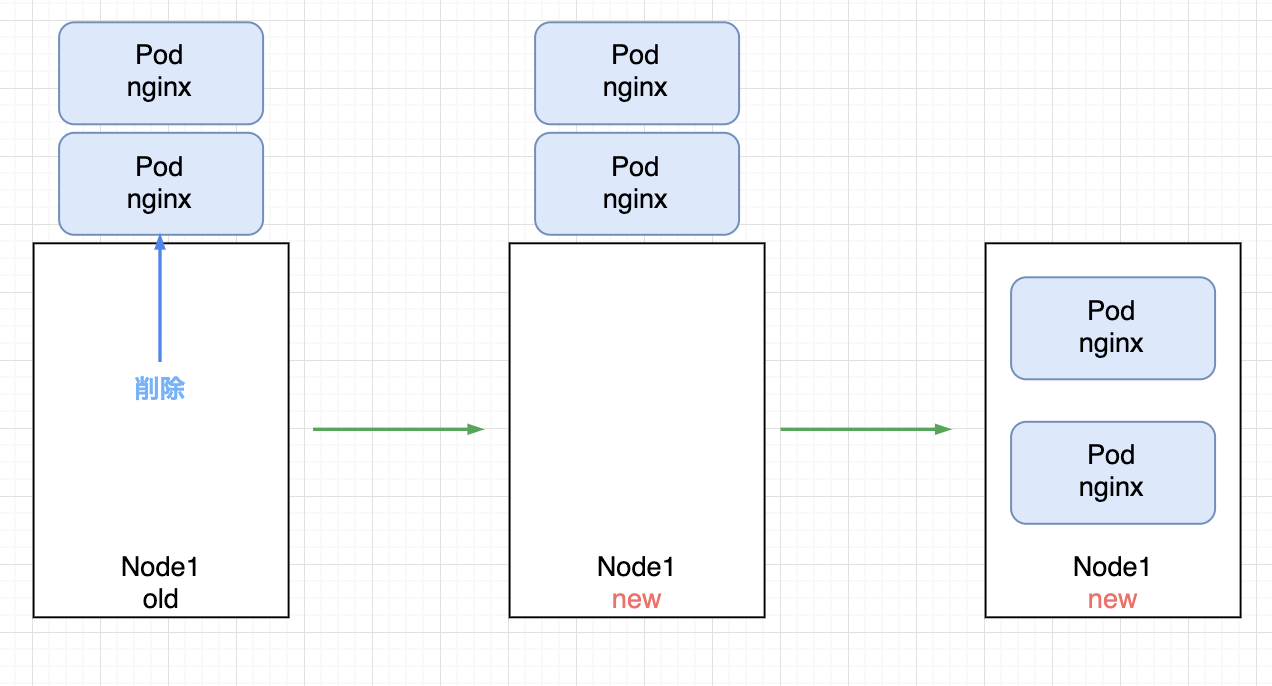
例えPDBが設定されていたとしても、新たなPodを正常に再スケジュールできなかった場合、サービスが瞬断してしまう可能性を紹介しました。
これが現行のノードプールにおけるアップグレードの挙動です。
GracefulTerminationPeriodについてはPDBの挙動が確認できれば大体想像がつくので省略します。
これを理解したうえでベータ機能であるsurgeを理解しましょう。
ノードプールのsurge
現行のノードプールのアップグレードの挙動を理解したうえで、surgeが設定されたノードプールとの違いを理解するのがこの節のゴールです。
Google Cloud Japan Customer Enginner Advent Calendar 2019 でも紹介されていたように、ノードプール内のノードを1度に複数個アップグレードすることができるようになります。
これに加えてsurgeを設定することはもう1つ大きな影響をノードのアップグレードにもたらします。
まずは下準備をします。
Deployment nginx, ノードプール upgraded-poolを削除して、surgeを設定した新たなupgraded-poolを用意しましょう。
# Deploymentを削除
$ kubectl delete deploy nginx
deployment.extensions "nginx" deleted
# 既存のノードプールを削除
$ gcloud container node-pools delete upgraded-pool --cluster=upgrade --region=asia-northeast1
The following node pool will be deleted.
[upgraded-pool] in cluster [upgrade] in [asia-northeast1]
Do you want to continue (Y/n)? y
Deleting node pool upgraded-pool...done.
Deleted [https://container.googleapis.com/v1/projects/ca-tominaga-test/zones/asia-northeast1/clusters/upgrade/nodePools/upgraded-pool].
# betaで新しいノードプールを同じ名前で作成
$ gcloud beta container node-pools create upgraded-pool --region=asia-northeast1 \
--cluster=upgrade \
--node-version=1.13.12-gke.13 \
--num-nodes=1
ベータのAPIを使えば--max-surge-upgradeがデフォルトの1に設定されます。
この状態でマニフェストファイルをデプロイして、ノードプールのアップグレードを実行してみましょう。
Podとノード2つの状態を観測します。
# Podの初期状態
$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx-6cc68796fc-6wjs8 1/1 Running 0 15s 10.4.3.3 gke-upgrade-upgraded-pool-c8c5f2d7-1h4p
nginx-6cc68796fc-72ng4 1/1 Running 0 15s 10.4.3.2 gke-upgrade-upgraded-pool-c8c5f2d7-1h4p
# ノードの初期状態
$ kubectl get nodes -l cloud.google.com/gke-nodepool=upgraded-pool -w
NAME STATUS ROLES AGE VERSION
gke-upgrade-upgraded-pool-c8c5f2d7-1h4p Ready <none> 10m v1.13.12-gke.13
アップグレード中のそれぞれの様子
# Podの様子
$ kubectl get po -o wide -w
NAME READY STATUS RESTARTS AGE IP NODE
nginx-6cc68796fc-6wjs8 1/1 Running 0 4m54s 10.4.3.3 gke-upgrade-upgraded-pool-c8c5f2d7-1h4p
nginx-6cc68796fc-72ng4 1/1 Running 0 4m54s 10.4.3.2 gke-upgrade-upgraded-pool-c8c5f2d7-1h4p
# 1つのPodを削除する
nginx-6cc68796fc-6wjs8 1/1 Terminating 0 5m56s 10.4.3.3 gke-upgrade-upgraded-pool-c8c5f2d7-1h4p
# 新しいPodが起動しようとする
nginx-6cc68796fc-ttgv5 0/1 Pending 0 0s <none> <none>
nginx-6cc68796fc-6wjs8 0/1 Terminating 0 5m57s 10.4.3.3 gke-upgrade-upgraded-pool-c8c5f2d7-1h4p
nginx-6cc68796fc-ttgv5 0/1 Pending 0 2s <none> gke-upgrade-upgraded-pool-c8c5f2d7-y68t
# 新しいPodが新しいノードで起動しようとする
nginx-6cc68796fc-ttgv5 0/1 ContainerCreating 0 3s <none> gke-upgrade-upgraded-pool-c8c5f2d7-y68t
nginx-6cc68796fc-6wjs8 0/1 Terminating 0 6m3s 10.4.3.3 gke-upgrade-upgraded-pool-c8c5f2d7-1h4p
# 新しいPodがRunningになったので、もう1つの古いPodを削除できるようになる
nginx-6cc68796fc-ttgv5 1/1 Running 0 18s 10.4.4.2 gke-upgrade-upgraded-pool-c8c5f2d7-y68t
nginx-6cc68796fc-72ng4 1/1 Terminating 0 6m15s 10.4.3.2 gke-upgrade-upgraded-pool-c8c5f2d7-1h4p
# 更に2つめの新しいPodが起動してくる
nginx-6cc68796fc-pjfgj 0/1 Pending 0 0s <none> <none>
nginx-6cc68796fc-pjfgj 0/1 Pending 0 0s <none> gke-upgrade-upgraded-pool-c8c5f2d7-y68t
nginx-6cc68796fc-pjfgj 0/1 ContainerCreating 0 1s <none> gke-upgrade-upgraded-pool-c8c5f2d7-y68t
nginx-6cc68796fc-72ng4 0/1 Terminating 0 6m16s 10.4.3.2 gke-upgrade-upgraded-pool-c8c5f2d7-1h4p
nginx-6cc68796fc-pjfgj 1/1 Running 0 2s 10.4.4.3 gke-upgrade-upgraded-pool-c8c5f2d7-y68t
nginx-6cc68796fc-72ng4 0/1 Terminating 0 6m17s 10.4.3.2 gke-upgrade-upgraded-pool-c8c5f2d7-1h4p
nginx-6cc68796fc-72ng4 0/1 Terminating 0 6m17s 10.4.3.2 gke-upgrade-upgraded-pool-c8c5f2d7-1h4p
# ノードの様子
$ kubectl get nodes -l cloud.google.com/gke-nodepool=upgraded-pool -w
NAME STATUS ROLES AGE VERSION
gke-upgrade-upgraded-pool-c8c5f2d7-1h4p Ready <none> 10m v1.13.12-gke.13
# まず新しいバージョンのノードが起動してくる
gke-upgrade-upgraded-pool-c8c5f2d7-y68t NotReady <none> 1s v1.14.8-gke.17
gke-upgrade-upgraded-pool-c8c5f2d7-y68t Ready <none> 1s v1.14.8-gke.17
gke-upgrade-upgraded-pool-c8c5f2d7-1h4p Ready <none> 13m v1.13.12-gke.13
# 新しいノードが使用可能になったので古いノードが消される
gke-upgrade-upgraded-pool-c8c5f2d7-1h4p Ready,SchedulingDisabled <none> 13m v1.13.12-gke.13
gke-upgrade-upgraded-pool-c8c5f2d7-1h4p Ready,SchedulingDisabled <none> 13m v1.13.12-gke.13
ここまでの流れを図示します。
まず、新しいノードが起動し、1つのPodが削除される。同時にminReplicaを満たすために新たなPodが新しいノードにスケジュールされる
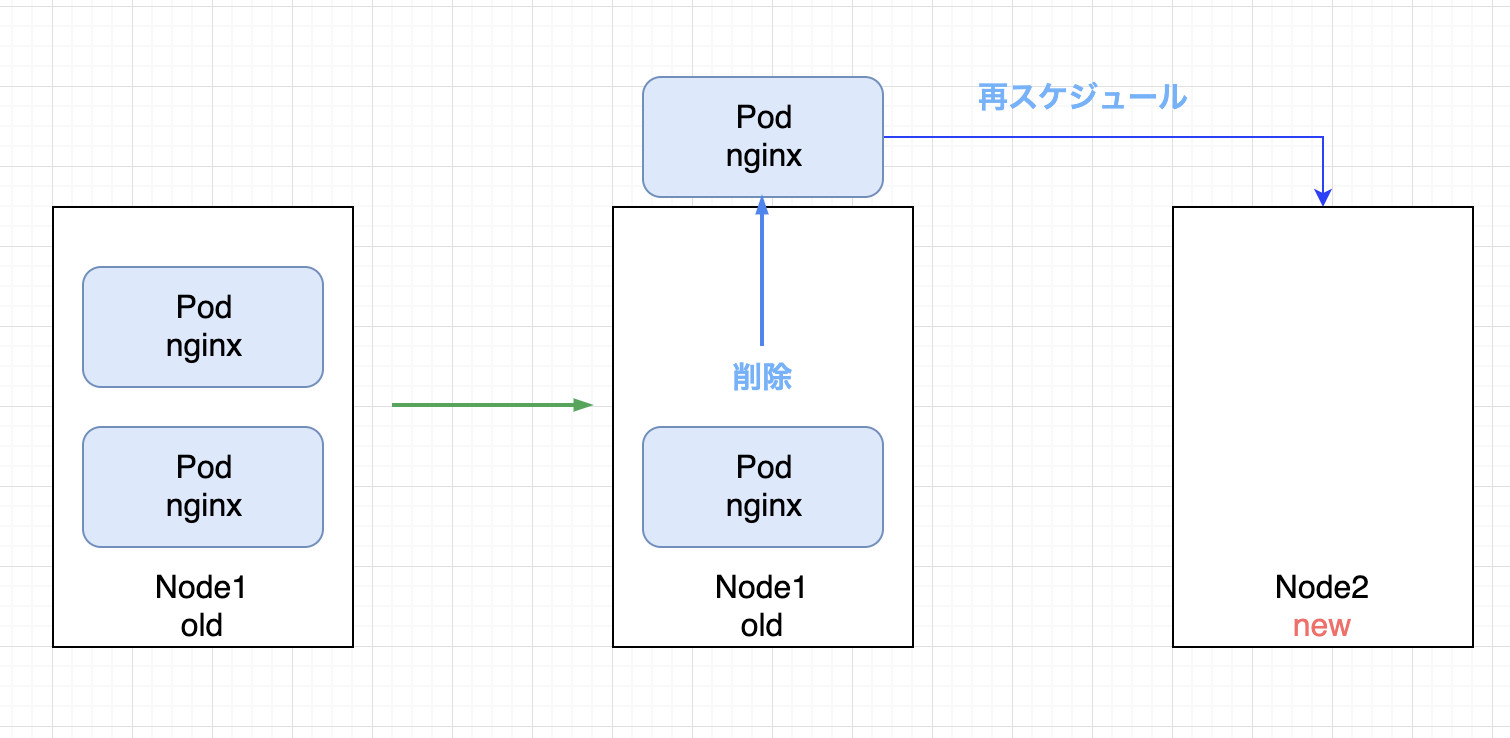
PDBの制約を満たすことができるようになったため、続いて2つめのPodが新しいノードに再スケジュールされる
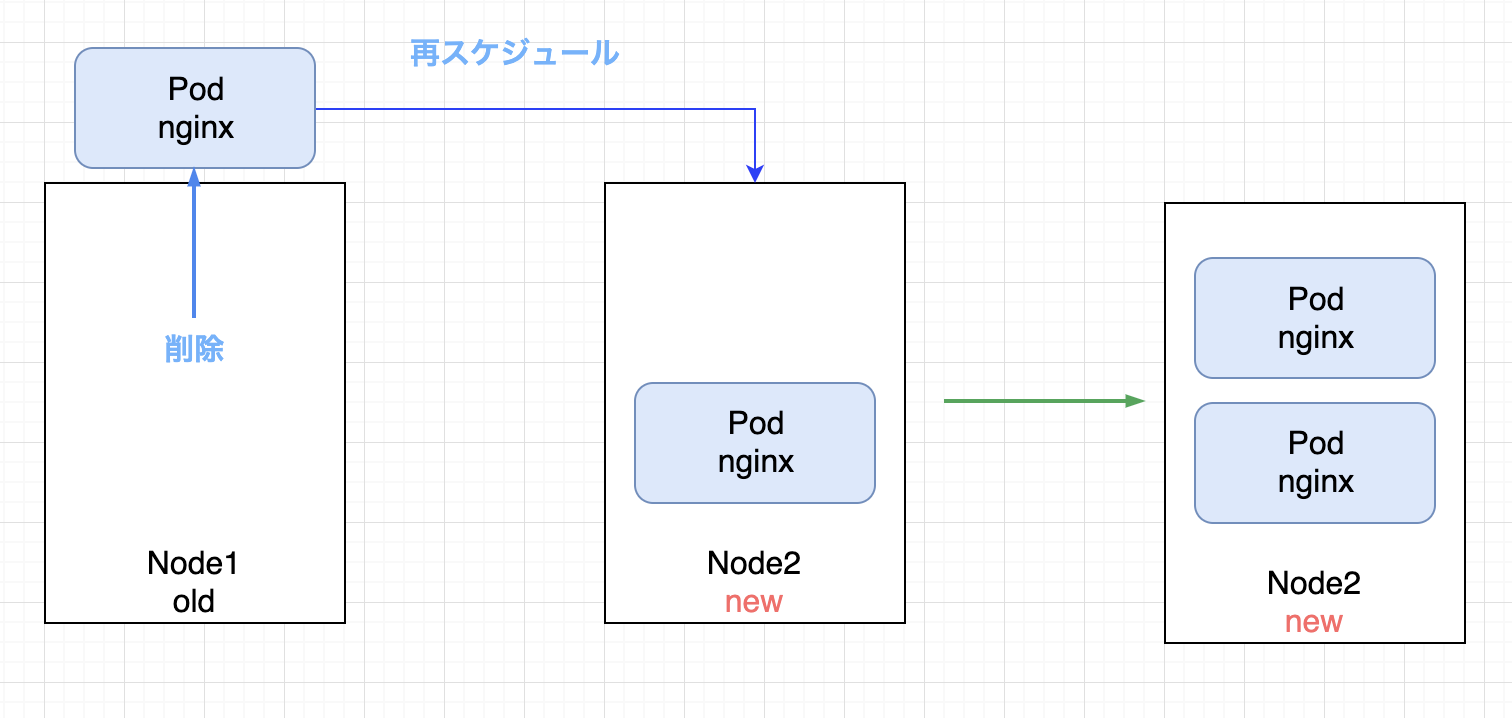
このように、surgeが設定されている場合は、既存のノードをアップグレードするのではなく、全く新しいノードを新しいバージョンで起動します。
一時的にワーカーノードのサイズが増えますが、surgeが設定されていない時のようなサービスの瞬断は発生しませんでした。
この動きがメリットしかないわけではありませんが、現行のノードプールとsurgeが設定されたノードプールではアップグレードの挙動にこのような違いが生じることを意識して、ノードプールのアップグレード計画を立てましょう。