論文概要
タイトル:CLASSIFIER-FREE DIFFUSION GUIDANCE
著者:Jonathan Ho & Tim Salimans, Google Research, Brain team
学会:NeurIPS 2021
URL:https://arxiv.org/abs/2207.12598
内容:Diffusionベースの画像生成モデルに対し、分類器を用いない条件付き生成を可能にした。条件付き拡散モデルと無条件拡散モデルを共同で学習し、結果として得られる条件付きスコア推定値と無条件スコア推定値を組み合わせて、分類器を用いたモデルと同様の品質と多様性を達成した。
はじめに
近年画像生成のタスクにおいて、拡散(Diffusion)モデルが高い性能を誇っている。そして、Diffusionモデルを用いて条件付き画像生成をする手法として、Classifier Guidance(分類器による誘導)が挙げられる。Diffusionモデルのスコア推定値に分類器の勾配を混ぜ合わせることで、より安定した画像生成を可能とする。しかし、この手法には欠点がある。誘導をする分類器は汎用の分類器を使えず、入力がノイズ交じりの画像と拡散過程のtimestep。出力がclassとなる特殊なモデルを学習する必要がある。この問題を解決するために、著者らは分類器を全く使わない誘導方法である分類器なし誘導を提案した。分類器なし誘導は、画像分類器の勾配方向にサンプリングするのではなく、条件付き拡散モデルと共同で学習した無条件拡散モデルのスコア推定値を混合する。混合重みを用いることで、分類器による誘導と同様のFID/ISトレードオフを達成することができる。この結果は、純粋な生成拡散モデルが、他のタイプの生成モデルで可能な極めて忠実度の高いサンプルを合成できることを示している。
関連研究
分類器による誘導(論文)
まず、Diffusionモデルにおける分類器による誘導を解説する。
第一に、画像のクラスも入力としてDiffusionモデルを学習させる。
通常のDiffusionモデルの推定スコアを以下の式のように表す。
$$ \varepsilon_\theta(z_{\lambda}, c) = -\sigma_\lambda \nabla_{z_\lambda} \log p(z_\lambda | c) $$
そして、分類器あり誘導では、分類器の勾配を加え、以下のようなスコアを考える。ただし、$\omega$はガイダンススケールと呼ばれ、分類器による誘導の強さを表す。
$$ \tilde \varepsilon _ \theta (z_ {\lambda}, c) = \varepsilon_\theta(z_{\lambda}, c) - \omega \sigma_\lambda \nabla_{z_\lambda} \log p_\theta (c|z_\lambda)
= -\sigma_\lambda \nabla_{z_\lambda} [\log p(z_\lambda | c) + \omega \log p_\theta (c|z_\lambda)]
$$
つまり、生成される分布は次のような条件部(尤度)$p(c|z_{\lambda})$に指数がついた分布となる。
$$\tilde p_{\omega,\theta}(z_\lambda | c) \propto p_{\theta}(z_\lambda | c) p_\theta (c|z_\lambda)^\omega $$
この効果は分類器が正解のクラスに高い尤度を割り当てた際のそのデータの確率を強く重み付けすることを意味する。うまく分類できたデータはInception Scoreの面で高く評価され、生成モデルも高く評価される。
以下の図は分類器による誘導の効果を示している。最も左がまったく誘導がない分布を表す。左に進むに連れガイダンススケールが上がっていく。それぞれの条件は確率分布の塊(3つそれぞれ)を他のクラスから遠ざけ、信頼度の高い方向へ配置し、塊はより小さな領域に集中するようになる。

スケール$\omega+1$の分類器による誘導を無条件モデルに適用すると、理論的には重み$\omega$の分類器による誘導を条件付きモデルに適用したものと同じ結果になる(証明は以下の式)。
$$\varepsilon_\theta(z_λ) − (\omega + 1)\sigma_\lambda \nabla_{z_\lambda} \log p_{\theta}(c|z_\lambda) ≈ −\sigma_\lambda \nabla_{z_\lambda} [\log p(z_\lambda) + (\omega + 1) \log p_\theta(c|z_\lambda)] = −\sigma_\lambda \nabla_{z_\lambda} [\log p(z_\lambda|c) + \omega \log p_\theta(c|z_\lambda)]$$
しかし、興味深いこととして、Dhariwal & Nicholは、無条件のモデルに誘導を適用するのと比較して、すでにクラス条件付きのモデルに分類器による誘導を適用した場合に、最良の結果を得ている。このため、この論文でも、すでに条件付きのモデルに誘導を適用することを考える。
提案手法:分類器なし誘導
提案手法では分類器なしで、上記の手法と同じ誘導の効果を得る方法を提案している。下記のアルゴリズム1と2は、分類器なしガイダンスを用いた訓練とサンプリングを示す。


別の分類器モデルを訓練する代わりに、スコア推定量$\varepsilon_\theta(z_\lambda)$をパラメータとする無条件ノイズ除去拡散モデル$p_\theta(z)$を、$\varepsilon_\theta(z_\lambda,c)$をパラメータとする条件付きモデル$p_\theta(z|c)$とともに訓練する。無条件モデルでは、スコアを予測する際にクラス$c$にヌルトークン$\phi$を入力するだけで、$\theta(z_\lambda) = \theta(z_\lambda,c = \phi )$となり、両方のモデルのパラメータ化に単一のニューラルネットワークを使用する。このとき、ハイパーパラメータとして設定された確率$p_{\text{uncond}}$で$c$を無条件クラス識別子$\phi$にランダムに設定することで、無条件モデルと条件付きモデルを合同で学習させる。(共同訓練ではなく、別々のモデルを訓練することも可能であるが、実装が非常に簡単で、訓練パイプラインを複雑にせず、パラメータの総数を増やさないため、共同訓練を選択した)次に、条件付きスコア推定値と無条件スコア推定値の次の線形結合を用いてサンプリングを行う:
$$ \tilde \varepsilon_\theta (z_\lambda, c) = (1+\omega) \varepsilon_\theta (z_\lambda, c) - \omega \varepsilon_\theta (z_\lambda)$$
上式には分類器の勾配が存在しないため、$\tilde\varepsilon_\theta $方向にステップを踏むことは、画像分類器に対する勾配に基づく敵対的攻撃と解釈することはできない。さらに、$\tilde\varepsilon_\theta $は、無制約ニューラルネットワークの使用により非保存的なベクトル場であるスコア推定値から構成されるため、一般に、 $\tilde\varepsilon_\theta $ が分類器による誘導スコアである場合の分類器対数尤度 のようなスカラーポテンシャルは存在し得ない。
一般に、上の式が分類器のガイドスコアとなる分類器は存在しないかもしれないにもかかわらず、実際には暗黙の分類器の勾配に触発されている。
もし、正確なスコア$\varepsilon^ * (z_\lambda, c)$と$\varepsilon^ * (z_\lambda)$(それぞれ$p(z_\lambda|c)$と$p(z_\lambda)$のスコア)を入手できたなら、この暗黙の分類器の勾配は$\nabla_{z_\lambda} \log p^i (c|z_\lambda) = - \frac{1}{\sigma_\lambda}[\tilde\varepsilon_\theta (z_\lambda,c) - \tilde\varepsilon_\theta (z_\lambda)]$となり、この暗黙の分類器による分類器誘導はスコア推定値を$\tilde \varepsilon^ * (z_\lambda,c) = (1+\omega) \varepsilon^ * (z_\lambda,c) - \omega \varepsilon^ * (z_\lambda) $に修正するだろう。
上の式と似ているが、$\tilde\varepsilon * (z_\lambda,c)$は$\tilde\varepsilon_\theta (z_\lambda,c)$とは根本的に異なることに注意されたい。前者はスケールされた分類器の勾配$\varepsilon^ * (z_\lambda,c) - \varepsilon^ * (z_\lambda)$から構成され、後者は推定値$\varepsilon_\theta (z_\lambda,c) - \varepsilon_\theta (z_\lambda) $から構成され、この式は一般的にはどの分類器の(スケールされた)勾配でもない、またスコア推定値は無制約ニューラルネットワークの出力であるからである。
ベイズの法則を用いて生成モデルを反転させると、有用な誘導信号を提供する優れた分類器が得られるということは、先験的に明らかではありません。例えば、Grandvalet & Bengio (2004)は、生成モデルの仕様がデータ分布と完全に一致する人工的なケースであっても、識別モデルが生成モデルから得られる暗黙の分類器よりも一般的に優れていることを発見した。
我々のようにモデルの仕様が誤っていることが予想される場合、ベイズの法則から導かれる分類器は矛盾を起こし(Grunwald & Langford, 2007)、その性能は保証されなくなる。
とはいえ、セクション4では、分類器なしの誘導が、分類器による誘導と同じようにFIDとISをトレードオフできることを経験的に示す。セクション5では、分類器ガイダンスとの関連で、分類器なし誘導の意味について議論する。
実験
FIDとInception Scoreのトレードオフを研究するためにクラス条件付きImageNetで分類器なし拡散モデルの学習を行った。分類器つき拡散モデルと同じハイパーパラメータを用いて比較した結果が以下の表である。
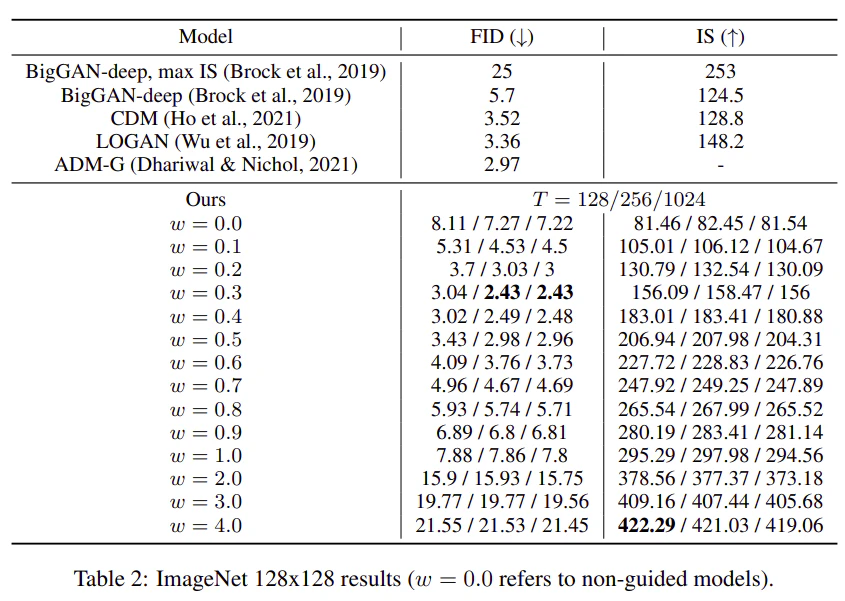
データセットによって異なるが、$\omega = 0.1$または$\omega = 0.3$という少量のガイダンスでFIDが最も良く、$\omega ≥ 4$という強いガイダンスでISが最も良い結果を得た。この2つの極端な間で、知覚品質の2つのメトリクス間の明確なトレードオフが見られ、FIDは$\omega$とともに単調に減少し、ISは単調に増加する。我々の結果はDhariwal & Nichol (2021) やHo et al. (2021) と好対照で、実際、128×128の結果はSOTAである。$\omega=0.3$では、128×128 ImageNetにおける我々のモデルのFIDスコアは、分類器による誘導のADM-Gを上回り、$\omega=4.0$では、BigGAN-deepがそのベストIS切り捨てレベルを評価した場合、我々のモデルはFIDとISの両方でBigGAN-deepを上回るとした。
下図は異なるガイダンスレベルのモデルからランダムに生成されたサンプルを示している。ここでは、分類器なしのガイダンススケールを上げると、サンプルの種類が減り、個々のサンプルの忠実度が上がるという期待通りの効果があることが明確に示されている。

無条件のトレーニング確率を変更
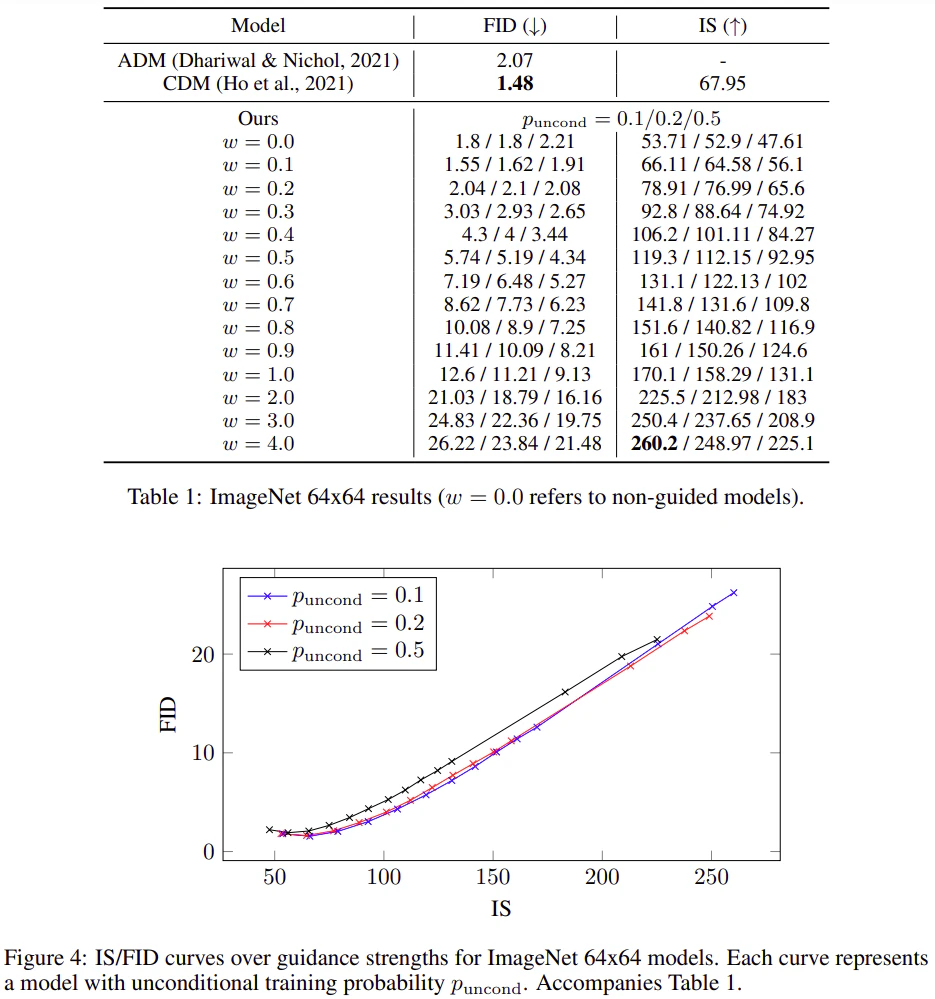
訓練時の分類器なし誘導の主要なハイパーパラメータは$p_{\text{uncond}}$である。条件付き拡散モデルと無条件拡散モデルの合同訓練時に無条件生成で訓練する確率である。ここでは、$p_{\text{uncond}}$を変化させた場合のモデルの学習効果を、64×64の ImageNetを用いて示す。
表1と図4は、$p_{\text{uncond}}$がサンプル品質に与える影響を示している。我々は、$p_ {\text{uncond}} \in [0.1, 0.2]$を変化させたモデルを学習させた。{0.1、0.2、0.5}のモデルを40万ステップで学習させ、様々なガイダンス強度でサンプルの品質を評価した。ガイダンスの強さを評価した。その結果、$p_ {\text{uncond}} = 0.5 $は$p_ {\text{uncond}} \in [0.1, 0.2 ] $よりも一貫して性能が低いことがわかる。また、$p_ {\text{uncond}} \in [0.1, 0.2]$はほぼ同等であることがわかる。
これらの結果から、サンプルの品質に有効な分類器なし誘導のスコアを生成するためには、拡散モデルのモデル容量の比較的小さな部分のみを無条件生成タスクに充てる必要があると結論付けた。興味深いことに、分類器による誘導については、Dhariwal & Nicholは、分類器による誘導付きサンプリングを効果的に行うためには、容量の少ない比較的小さな分類器で十分であると報告しており、我々が分類器なし誘導付きモデルで発見したこの現象を反映している。
生成のタイムステップ数を変更
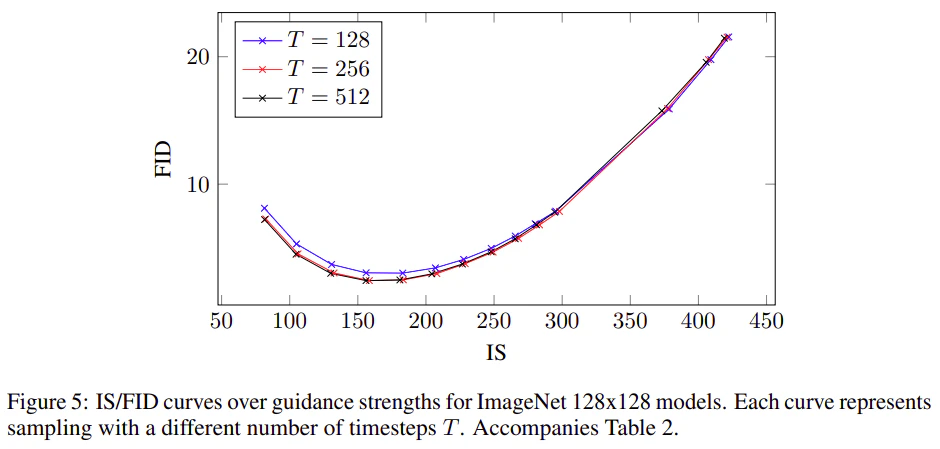
サンプリングステップ数Tは拡散モデルのサンプル品質に大きな影響を与えることが知られているため、ここでは128×128のImageNetモデルでTを変化させた場合の影響を調査することにした。表2と図5(上部に記載)は、$T \in [128, 256, 1024]$を変化させた場合の効果を、誘導強度の範囲にわたって示しています。予想通り、Tを大きくするとサンプルの品質が向上し、このモデルではT = 256がサンプルの品質とサンプリング速度の良いバランスを保っています。
T = 256は、ADM-G (Dhariwal & Nichol, 2021)が使用するサンプリングステップ数とほぼ同じであり、我々のモデルより優れていることに注意が必要である。しかし、我々の方法の各サンプリングステップでは、条件付き$\varepsilon _ \theta(z_ \lambda,c)$と無条件$\varepsilon _ \theta(z_ \lambda)$に対して1回ずつ、ノイズ除去モデルを計2回評価する必要があることに注意することが重要である。ADM-Gと同じモデルアーキテクチャを使用しているため、サンプリング速度の点で公平な比較は、FIDスコアの点でADM-Gより劣るT = 128の設定となる。
議論
分類器を用いない誘導手法の最も実用的な利点は、極めてシンプルであることである。トレーニング中に条件付けをランダムに削除し、サンプリング中に条件付きと無条件のスコア推定値を混合するために、コードを1行変更するだけでいい。一方、分類器による誘導は、分類器を追加で学習させる必要があるため、学習パイプラインが複雑になる。この分類器はノイズの多い$z_\lambda$に対して学習させる必要があり、標準的な学習済みの分類器を差し込むことはできない。
分類器なし誘導は、分類器による誘導のようにISとFIDをトレードオフすることができ、余分に訓練された分類器を必要としないため、純粋な生成モデルでガイダンスを実行できることが実証された。さらに、我々の拡散モデルは制約のないニューラルネットワークによってパラメータ化されているため、そのスコア推定値は分類器の勾配とは異なり、必ずしも保守的なベクトル場を形成しない(Salimans & Ho, 2021)。したがって、我々の分類器なしの誘導付き生成器は、分類器の勾配に全く似ていないステップ方向に従うため、分類器に対する勾配ベースの敵対的攻撃と解釈することはできない。したがって、この結果は、分類器ベースのISとFIDの向上は、分類器の勾配を使用する画像分類器に対して敵対的ではないサンプリング手順を用いた純粋生成モデルで達成できることを示す。
まとめと感想
提案手法は、Diffusionベースの条件付き生成モデルにおいて、新たに分類器を学習させることなく分類器の勾配にあたるものを用いることができる。