はじめに
お疲れさまです。
アドベントカレンダーに参加しましたので、5日目の担当記事を投稿しました。
この記事は自然言語処理初学者に向けた、深層学習の基礎になる前処理に重きをおいた記事です。
2013年に登場したword2vecまでしか触れませんので、現在主流のTransformerなどを触る前にさっと読んでいただければと思います。
自然言語処理における前処理とは
自然言語処理、つまり、我々の使う日本語や英語などをマシンに読み解かせ、必要な情報を取得する処理において、有名なタスクとしては、感情分析・固有表現抽出や質問応答・翻訳といった文生成などが挙げられます。
これらは、語の意味を文脈を加味して正確に捉えることで、高い正解率を出すことができると考えられています。
そのためには、入力の文章から語を切り出し、マシンが解析できる状態、つまり、語を数値化する必要があります。
それを本記事では、前処理と定義し、以下の項目にてご説明したいと思います。
形態素解析器を用いた分かち書き
例えば、以下の文から感情分析を行う場合のことを考えてみましょう。

この文を人間が見ると、あ、悲しいんだなと理解できますよね。
では、マシンにも同じように悲しいと当ててもらいましょう。
っと、ここで問題が生じます。
マシンくん「1語って、、、、どこからどこまでですか??」
おっとこれにはびっくり。
ですが、マシンに各語の切れ目がわからないのです。
英語であれば、"I am sad."と語の間にスペースがあるので、区切ることができますが、残念ながら日本語に区切れはありません。
なので、1語ごとに区切ってあげる必要があります。
これを分かち書きと言います。
日本語の分かち書きはスペースなどのルールが存在しないため、日本語の辞書を使って品詞解析・分かち書きを行います(ここではSentencepieceについては触れません。興味のある方は別途調べてみてください)。
この解析や分かち書きを行うツールを形態素解析器と呼びます。
では、実際に使ってみましょう!
形態素解析器はMeCabを始め、様々なものがあります。
MeCabやJanome,kuromojiなどはCベースのMeCabを各言語で再現したもので、sudachiはkuromojiをベースに辞書などを積極的に改良しています。
また、それとは別に京大からはjumanと呼ばれる形態素解析器がリリースされています。こちらはMeCabとは異なるアルゴリズム、異なる辞書を使用しており、所感としてはMeCabより細かく精緻に品詞分類してくれます。
またリクルートからはGiNZAと呼ばれる解析器が開発されています。これは多言語解析フレームワークのspaCyをベースに開発したもので、現在では内部処理にTransfoemerを導入し、高い精度と早い処理速度を両立させています。
今回はpythonで簡単に実行できるjanomeを使って見ましょう。
先に"pip install janome"とshellに打ち込みjanomeのパッケージをインストールします。
その後以下のコードをうちpythonを実行してみましょう。
from janome.tokenizer import Tokenizer
t = Tokenizer()
for token in t.tokenize("形態素解析に日和ってるやついる?いねぇよな!!?"):
print(token)
上記のコードからの出力は以下になります。
形態素 名詞,一般,*,*,*,*,形態素,ケイタイソ,ケイタイソ
解析 名詞,サ変接続,*,*,*,*,解析,カイセキ,カイセキ
に 助詞,格助詞,一般,*,*,*,に,ニ,ニ
日和 名詞,一般,*,*,*,*,日和,ヒヨリ,ヒヨリ
っ 動詞,非自立,*,*,五段・カ行促音便,連用タ接続,く,ッ,ッ
てる 動詞,非自立,*,*,一段,基本形,てる,テル,テル
やつ 名詞,代名詞,一般,*,*,*,やつ,ヤツ,ヤツ
いる 動詞,自立,*,*,一段,基本形,いる,イル,イル
? 記号,一般,*,*,*,*,?,?,?
い 動詞,自立,*,*,一段,未然形,いる,イ,イ
ねぇ 助動詞,*,*,*,特殊・ナイ,音便基本形,ない,ネェ,ネー
よ 助詞,終助詞,*,*,*,*,よ,ヨ,ヨ
な 助詞,終助詞,*,*,*,*,な,ナ,ナ
! 記号,一般,*,*,*,*,!,!,!
! 記号,一般,*,*,*,*,!,!,!
? 記号,一般,*,*,*,*,?,?,?
このように形態素解析により別れた語を、形態素と呼びその意味は「意味を持つ最小単位」となっています。ただし、近年では形態素解析に使用される辞書の拡充により、それら複数から意味を持つ統語の解析もできるようになっています(NEologdやSudachiDictなど)。
語のベクトル化
前節では、形態素解析について説明しました。
では、次に形態素として分割された語を数値化してマシンに読める状態にしなければいけません。
ですがその状態にするには、各語に数値を振る必要があります。その数値はどのようにして導き出すのでしょうか。

one-hotベクトル
深層学習が流行する以前、one-hotベクトルというベクトル表現に語を変換することで、マシンが解析できる形にしていました(*現在でも広く使われています)。
これを説明すると、下記の図のようになります。

これは、文章中に出現した語に対して、ランダムに数字を振っています。
ただし、one-hot、出現語彙分存在する0の中から1つだけが1になります。なので、図の形態素という語は2回出現していますが、はじめに出現している関係で1000...となっています。
また、このとき語彙数は次元数と言い換えることがあります。
それではこのone-hotベクトルを作成してみましょう。
from janome.tokenizer import Tokenizer
t = Tokenizer()
words = set(t.tokenize("人民の人民による人民のための政治", wakati=True))
print(words)
word_count = len(words)
for i,m in enumerate(words):
one_hot = ""
for j in range(word_count):
if i == j:
one_hot = one_hot + "1"
else:
one_hot = one_hot + "0"
print(m +":"+ one_hot)
これによって出力されるコードは以下です(ゴミコード恐れ入ります、、、)。
{'の', 'ため', '政治', '人民', 'による'}
の:10000
ため:01000
政治:00100
人民:00010
による:00001
人民が複数回出現していましたが、まとめられさっぱりしたことが分かると思います。
また、文章中の語の出現回数を数えたものはBag Of Wordsと呼ばれ、検索エンジンの基礎部分などに用いられることがあります。
word2vec
one-hotベクトルには問題があります。それは、出現した語に対し、0と1を使ってラベリングしているだけなので、どの単語が文章中に出現したかはわかりますが、どのタイミングで出てきたか、隣の単語は何だったのかなど語の並びについての情報はほぼ不明なことです。
しかし、2013年にTomas Mikolov氏により、語を出現した場所の周辺の語を用いてベクトル化するという手法が提案されました。
これが有名なWord2Vecです。この提案により自然言語処理においても高次元のベクトル空間を用いた研究が活発化しました。
Word2Vecには2種類のアルゴリズムがあり、周辺の語から中心の語を当てるCBoW(Continuous Bag-of-Words)と、中心の語から周辺の語を当てるSkip-gramです。
これらは教師なし学習によって語のベクトル化を行い、それによって生成された高次元のベクトル空間は以下の式を可能にしました。
それが、これです。

このように意味の計算を可能し、これは世界を驚かせるものでした。
では、例にももれず試して見ましょう。 、、、と言いたいところですが、この処理には大規模な学習データが必要になります(例:日本語Wikipedia全記事)。
なので、そのデータを持っている体で、コードの紹介をしたいと思います。
Word2Vecを使用する場合、有名はライブラリがgensimです。
なので、先に pip install gensim を行ってから下記のコードを実行します。
# Word2Vecモデルの学習
from gensim.models import word2vec
# sizeは特徴量の数、min_count以下の登場数の単語を無視、前後window幅の単語との関係を考慮、epochs回数分学習を繰り返す
input = word2vec.LineSentence("wikipedia.txt")
model = word2vec.Word2Vec(input,
vector_size=200,
min_count=0,
window=15,
epochs=100)
# モデルの保存
model.save("wikipedia_for_w2v.model")
これによりできたモデルを使い、次は語の類似度計算により、意味の足し引きを行います。
from gensim.models import word2vec
model = word2vec.Word2Vec.load("wikipedia_for_w2v.model")
results = model.wv.most_similar(positive=["王様","女"],negative=["男"],topn=10)
for result in results:
print(result[0], '\t', result[1])
このライブラリでは類似度の計算方法にcos類似度を使用しており、1に近くなるほど類似していることになります。
得られた結果は以下です。
[語] [cos類似度]
お姫様 0.5149936676025391
王女 0.5087050795555115
女王 0.4963114857673645
王妃 0.4953230619430542
貴婦人 0.4717015027999878
召使 0.46869608759880066
召使い 0.46412718296051025
王子 0.4609353244304657
プシシェ 0.45699068903923035
シンデレラ 0.45662805438041687
このように2番めには女王が出てきているのは驚きですよね。
この高次元空間ベクトルは我々が日常的に使用する日本語の語の意味を理解しているのではないでしょうか。
しかし、このベクトル空間はまだ完全ではありません。これはまだ文章の文脈を加味していないからです。ですが、これはまた長い話になりますので、また次回にでも。
おまけ
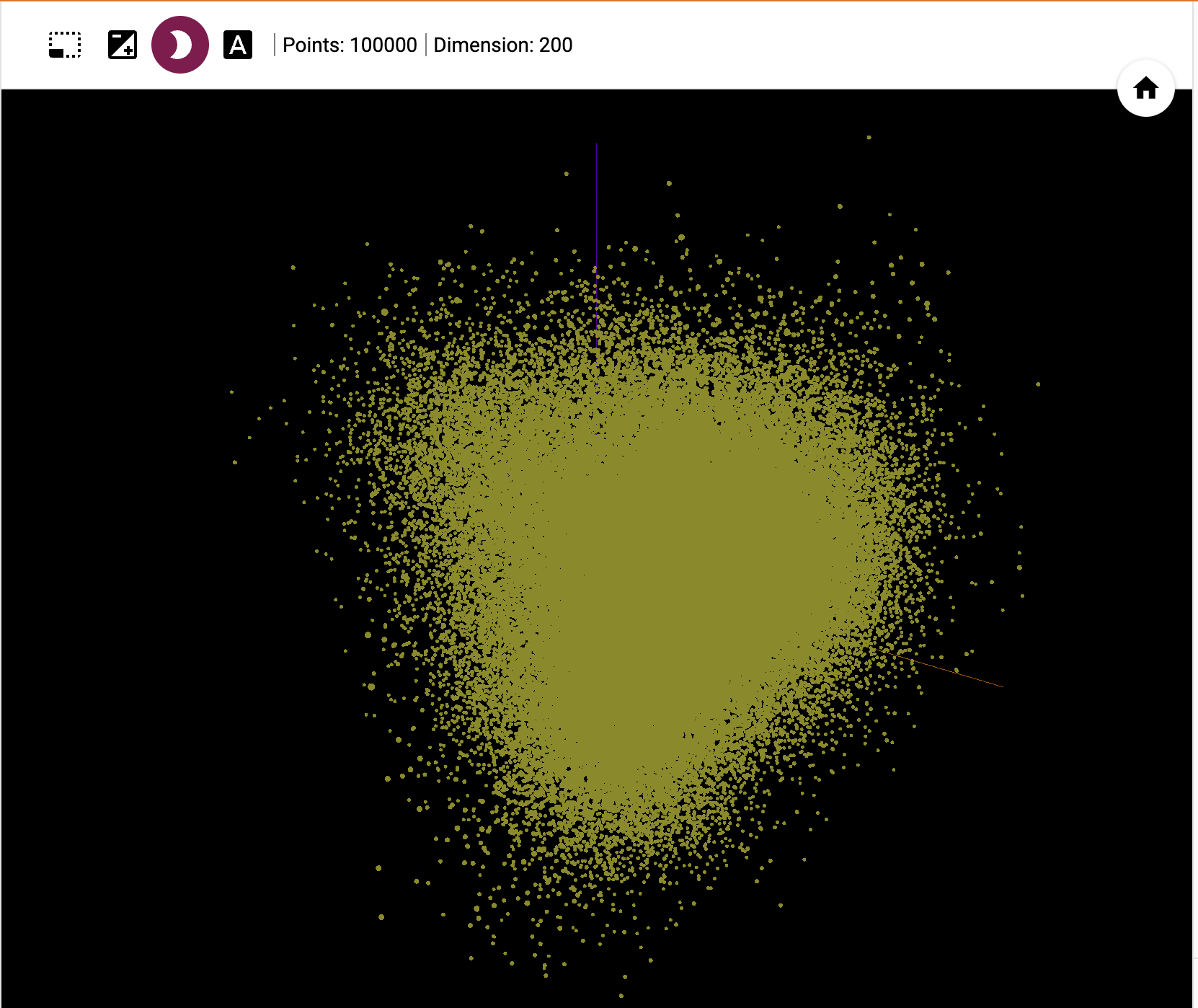
word2vecの学習モデルから10万語抜き出し、3次元にマッピングしてみました。
このすべての点が語となっています。
またその中から「ルパン」に類似する単語をピックアップしてみました。
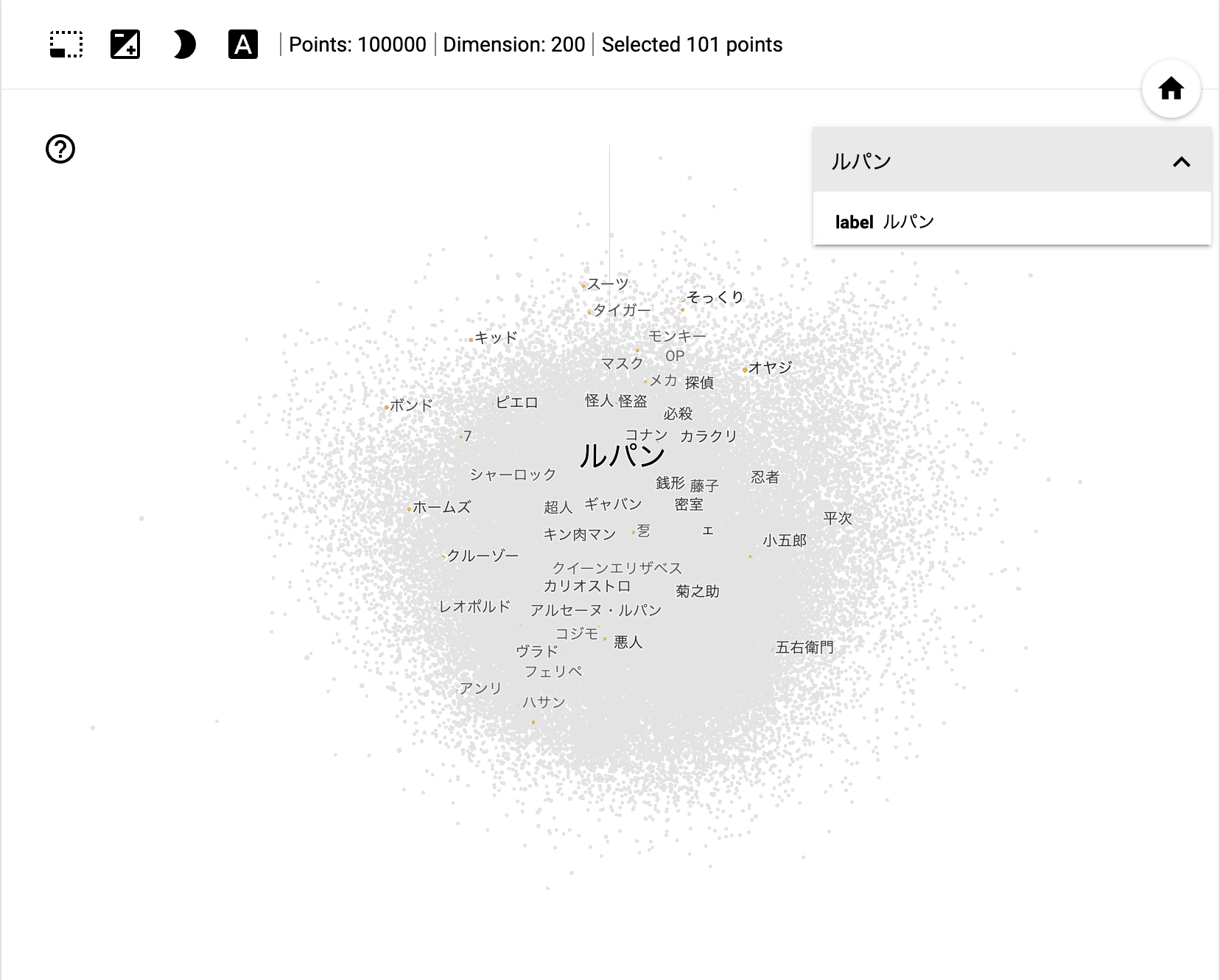
コナンくんや、銭形が近くに存在するのも面白いですよね。
では、今回はここまで。
記憶を頼りに書いた点も多々あります。ご指摘あれば修正しますので、よろしくお願いいたします。