Qiita初投稿です。
何とか投げ出さず投稿できて良かった・・・
はじめに
趣味でLINEスタンプを作っているのですが、特定個人としか使わないニッチなスタンプを作ろうとしたときに、「じゃあ、この人とのトークでよく使う言葉のランキングを出せたらスタンプ作成に活かせるのでは?」と思い立ちやってみました。
ちなみにPythonを選んだのは、今更ですが人気のPythonとやらに触れてみたいという安直な理由です・・・
環境
- OS
- Windows10
-
Ubuntu 20 04.1 LTS
※デュアルブートではなくWSL(Windows Subsystem for Linux)という方法を利用しました。
※後述の「mecab-ipadic-neologd」をインストールするにあたり、Windows環境ではどうしてもうまくインストールできなかったのでいれました。 - プログラミング言語
- Python 3.9.0
- エディタ
-
ATOM
※IDE(統合開発環境)ではなく単にエディタですが、手軽に使えそうでパッケージをインストールすれば便利な機能が色々使えそうだったのでこれにしました。 -
sakuraエディタ
※LINEから抽出したトークのデータ加工(不要な単語、空白の削除とか)に利用 -
ライブラリ
※PythonやMecabを利用するにあたって他にもインストールしていますが、主要なものは以下のものです。 -
Mecab
※Mecabはオープンソースの形態素解析ソフトで、これをインストールすれば簡単に品詞ごとに区切ってくれます。 -
seaborn
※seabornはPythonのデータ可視化ライブラリで、ランキングを出しすときの見た目が綺麗だったので使用しました。 -
mecab-ipadic-neologd
※「mecab-ipadic-neologd」は新語や固有表現に強い辞書で、LINEからの単語抽出ということもありインストールしました。
※そのままWindows上でインストールしようとするとうまくいかなかったので、ubuntuに一度ダウンロードして、Windows側にコピーする方法にしました。ここらへんの話については、以下のサイトを参考にしました。
MecabをインストールしてPythonで使う【Windows】
分析データ作成
1.LINEトークからトーク内容を抽出
LINEトークの右上「≡」マークから[その他]⇒[トーク履歴を送信]で、トーク内容をテキストファイルとして出力できます。
2.トーク履歴をデータとして使えるようにする。
トーク内容をテキストファイルに落としただけでは、以下のような形式になっています。
[LINE] 〇〇とのトーク履歴
保存日時:2020/10/19 22:31
2015/10/10(土)
1:04 〇〇 おやすみ!
6:03 △△ おはよ!
6:33 〇〇 おはよ(*´-`)
・・・
・・
・
※〇〇:自分のLINE名
※△△:相手のLINE名
日付や時間、LINE名、絵文字、空白などデータとして不要なものが多いので、これらを削除します。
ちなみに、LINE名はそのまま置換機能で指定して消せばいいのですが、日付や時間は様々なパターンがあるため、正規表現を使って削除します。
※絵文字は自分の知識不足で、まとめて削除する方法がわからなかったのでトーク内の絵文字「(*´-`)」等をコピーして置換機能で消していくという作業をひたすら行いまた・・・
上記のようにがんばって削除していき、最終的に以下のように文字列のみにしていきます。
おやすみ!おはよ!おはよ・・・・・・・・・
これで、プログラムで読み込むためのデータは完成です。
コード
全体は以下の通り
import MeCab as mc
from collections import Counter
import sys
from sys import argv
import matplotlib.pyplot as plt
import seaborn as sb
# 引数の取得
input_file_name= sys.argv[1]
# mecabを用いて単語(文節)に分ける
def mecab_analysis(text):
m = mc.Tagger('')
m_result = m.parse(text).splitlines()
m_result = m_result[:-1]
break_pos = ['名詞','動詞','接頭詞','副詞','感動詞','形容詞','形容動詞','連体詞']
wakachi = ['']
afterPrepos = False
afterSahenNoun = False
for v in m_result:
if '\t' not in v: continue
surface = v.split('\t')[0]
pos = v.split('\t')[1].split(',')
pos_detail = ','.join(pos[1:4])
noBreak = pos[0] not in break_pos
noBreak = noBreak or '接尾' in pos_detail
noBreak = noBreak or (pos[0]=='動詞' and 'サ変接続' in pos_detail)
noBreak = noBreak or '非自立' in pos_detail
noBreak = noBreak or afterPrepos
noBreak = noBreak or (afterSahenNoun and pos[0]=='動詞' and pos[4]=='サ変・スル')
if noBreak == False:
wakachi.append("")
wakachi[-1] += surface
afterPrepos = pos[0]=='接頭詞'
afterSahenNoun = 'サ変接続' in pos_detail
if wakachi[0] == '': wakachi = wakachi[1:]
return wakachi
# 取得した単語を図に表示する
def show_data():
sb.set(context="talk")
sb.set(font='Yu Gothic')
fig = plt.subplots(figsize=(8, 8))
text = str(open(input_file_name,"r",encoding="utf-8").read())
words = mecab_analysis(text)
counter = Counter(words)
#とりあえず、上位10個を取得
sb.countplot(y=words,order=[i[0] for i in counter.most_common(10)])
plt.show()
def main():
show_data()
if __name__ == '__main__':
main()
def mecab_analysis(text)部分の単語に分ける処理については、以下の記事を参考にしました。
日本語を文節単位で分かち書きする【Python】【MeCab】
※最初、品詞ごとに分けた際、文章が分解されすぎて、ランキングを出しても1位が「た」とかになってしまいました・・・。
それではあまり意味がなかったので、品詞ごとではなくもっと文節で区切って意味のある単語でランキングを出したいと思い、色々調べていると、上記の記事を見つけ参考にさせていただきました。
ではランキングの出力ですが、以下のようにランキングを出力したいデータを用意します。
おはよう。こんにちは。さようなら。おはよう。こんにちは。さようなら。おはよう。こんにちは。さようなら。おはよう。こんにちは。さようなら。おはよう。こんにちは。さようなら。おはよう。こんにちは。さようなら。おはよう。こんにちは。さようなら。おはよう。こんにちは。さようなら。今日はいい天気ですね。今日はよく眠れました。今日は悪い天気ですね。
あとは、コマンドで、python [プログラムのパス] [データファイルのパス]と指定して、実行すると以下のように出力されます。
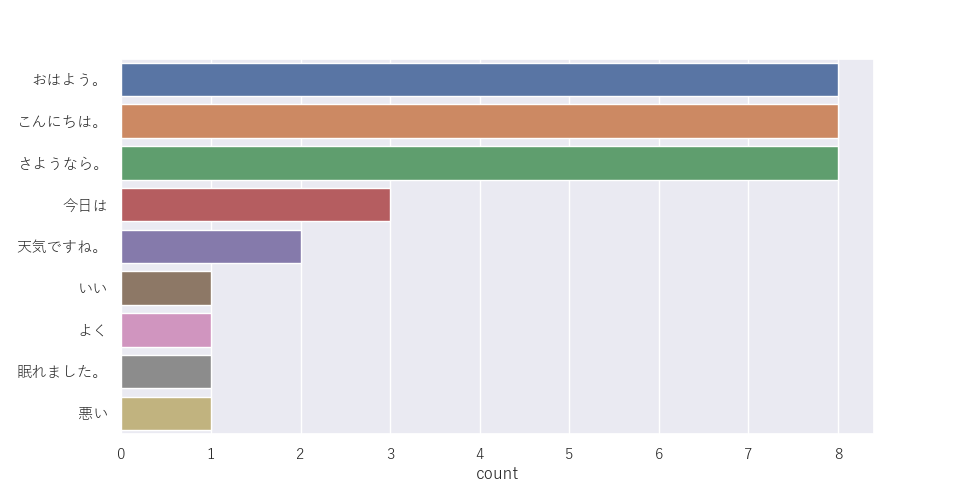
このように、ランキング上位から順番に出力できました。
最後に
今回は、とりあえず頻出単語のランキングを見たいなという思いで、パパっとできればと思ったのですが、知識不足なのと初めてのPythonでなかなか苦戦しました。しかし、前から気になっていたPythonにようやく触れることができました。
そして、しばらく仕事でプログラムに触れていなかったので、とても勉強になりました。
ただ、今回頻出単語抽出で用いた「mecab」に使われている「自然言語処理」については、ほとんど理解できず、とりあえず「利用した」というだけになってしまいました。
せっかくなので、これを機会に「自然言語処理」について勉強していこうかなと思います。