Pandasでデータを2つ読み込んで結合したときに、こんなことないですか?
- データの読み込み
import pandas as pd
sample001 = pd.read_excel("sample_excel_001.xlsx")
sample001.head()
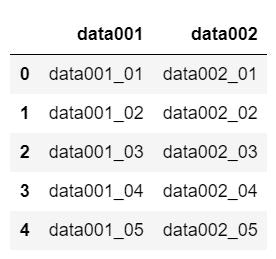
sample002 = pd.read_excel("sample_excel_002.xlsx")
sample002.head()
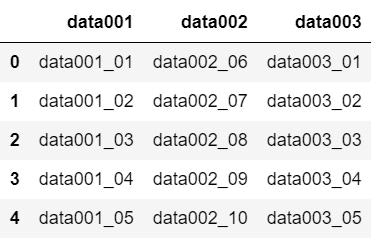
2つのデータをデータフレーム(sample001, sample002)に読み込みました。
"data001"列で2つのデータを結合できそうです。
- データの結合(join)
merge_data = pd.merge(sample001, sample002, on="data001", how="left")
merge_data.head()
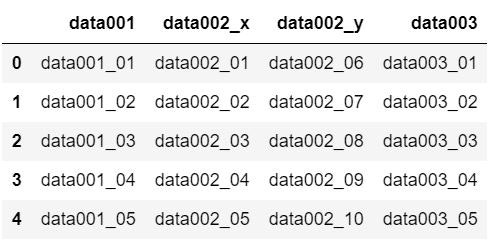 "data001"は結合のキーワード列、"data003"はsample002のデータであることはすぐ分かります。"data002_x"、"data002_y"ってなんやねんって話ですよ。「どこ出身のデータですか?」ってなっちゃいますよね?(いや本当はわかりますよ?mergeの第一引数で指定したデータフレームがx付き)見てくれが嫌なので、せめてどこ出身のデータなのかはパッと分かるようにしたいですね。
"data001"は結合のキーワード列、"data003"はsample002のデータであることはすぐ分かります。"data002_x"、"data002_y"ってなんやねんって話ですよ。「どこ出身のデータですか?」ってなっちゃいますよね?(いや本当はわかりますよ?mergeの第一引数で指定したデータフレームがx付き)見てくれが嫌なので、せめてどこ出身のデータなのかはパッと分かるようにしたいですね。
出身の名乗らせ方
suffixesオプションを使えば、結合キー以外でカラム名が重複したときに、新しいカラム名の末尾に加える文字列を指定することができます。
merge_data_new = pd.merge(sample001, sample002, on="data001", how="left", suffixes=[".sample001", ".sample002"])
merge_data_new.head()
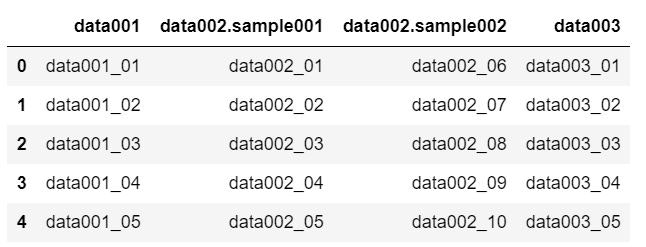
おー、これでどこ出身のデータかパッと判別できるようになりましたね!
最後に
できたらなんですが、末尾じゃなくて先頭に文字列を付けれたらいいですね。(SQLっぽくできるので)