「loc」は、DataFrameの内で条件を満たした行、列を抽出することができます。pandasを利用していると頻繁に出てくる「loc」ですが、データの指定方法にバリエーションがあるので、その辺をまとめていきたいと思います。
データ指定について
locは、大きく分けると以下のデータ指定が可能です。
- 単一ラベル
- ラベルリスト
- ラベルのスライスオブジェクト
- 真偽値リスト
- 条件式の指定
色々な使い方がありますね・・・ (゜_゜)
プログラムを書くときも注意が必要ですが、読むときにどのパターンで実装されているか冷静に見分けないと、「????」ってなりそうです。それぞれのサンプルコードを書いてみて動作を確認してみようと思います。
実際に使ってみた
今回動作確認で利用するデータは自分で作ったものです。
import pandas as pd
loc_sample_data = pd.read_csv("loc_sample_data.csv",index_col="item_name")
loc_sample_data.head()
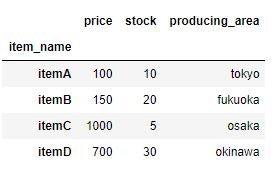
行インデックスはitem_name、列はprice、stock、producing_areaで構成されています。
単一インデックスラベルの指定
抽出したい行のインデックスラベル(単一)を指定してデータを抽出します。
今回はitemCの抽出をしていきます。
loc_sample_data.loc["itemC"]

抽出できました。抽出されたデータはSeries型です。
インデックスラベルリストの指定
上の例は単一行のみの抽出ですが、複数行を指定/抽出することが可能です。複数指定する場合はリストで指定します。
今度はitemA、itemDの抽出をしていきます。
loc_sample_data.loc[["itemA", "itemD"]]
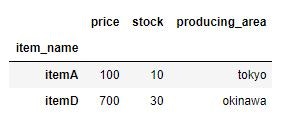
抽出できました。抽出されたデータはDataFrame型でした。
単一の行ラベル、列ラベルの指定
行と列のそれぞれのラベルを指定してデータを抽出することも可能です。今回は行→itemB、列→producing_areaを指定してデータ抽出します。
loc_sample_data.loc["itemB", "producing_area"]
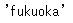
抽出できました。抽出されたデータstr型です。今回の例では抽出されたデータstr型ですが、これはDataFrame内に格納されているデータの内容で変わります。
スライスを利用した行ラベル、列ラベルの指定
スライスを利用して行、列を複数指定することができます。これを利用してitemA、itemBのpriceを抽出します。
loc_sample_data.loc["itemA":"itemB","price"]
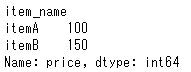
抽出できました。これ使うかな・・・?
真偽値リストを使ったデータ指定
抽出元のデータフレームと同じ長さ(行数)の真偽値リストを指定することで、Trueの行のみを抽出することができます。今回はitemBとitemDを抽出してみる。
loc_sample_data.loc[[False, True, False, True]]
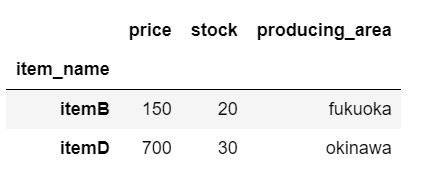
抽出できました。これ単発だと使う機会なさそうですが、事前に各行ごとに抽出条件を満たすかどうかを判定し、リストを作成したら使い道がありそうですね。
条件式を利用したデータ指定
一番使いそうなやつですね。今回はpriceが500より大きいデータ(itemC、itemD)を抽出してみます。
loc_sample_data.loc[loc_sample_data["price"] > 500]
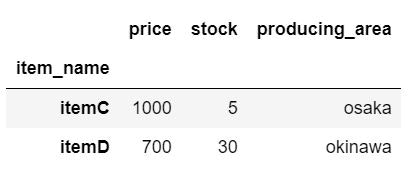
抽出できました。やっぱこれ単体だったら一番使いそう。
条件式を利用して特定列だけ抽出
さっきの条件式に加えて、特定の列を指定して抽出します。条件は先ほど同様ですが、今回はproducing_area列のみを抽出します。
loc_sample_data.loc[loc_sample_data["price"] > 500, ["producing_area"]]
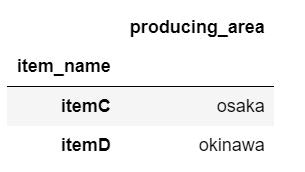
最後に
色々使い方ありますが、必ず身に付けた方が良いのは条件式を利用したデータ抽出ですかね。今回ちょっと長くて疲れたので終わりにします。それではまた次回の投稿でー!