Cloud のデザインパターンで、Queue-Based Load Leveling pattern というのがある。Serverless をやっているとアーキテクチャをもっと勉強しとくほうがいいなと思って、少しづつパターンを検証してみようと思っている。ふと思い立って、このパターンを Azure Functions で本当にそうなのか試してみることにした。

このパターンは、高負荷の時にパフォーマンス問題を引き起こすケースに使える。例えば、アプリケーションがスケールして、それが一気にデータベースに書き込むようなケースはどう解決するか?という話だ。そこで、Queue を挟むといいですよ。という話になる。じゃあ、実際に、Azure Functions で試してみよう。
HttpTrigger -> AzureFunctions -> CosmosDB
という構成と、
HttpTrigger -> AzureFunctions -> StorageQueue -> QueueTriggger -> Azure Functions -> CosmosDB
つまりこんな感じのシンプルなテスト。
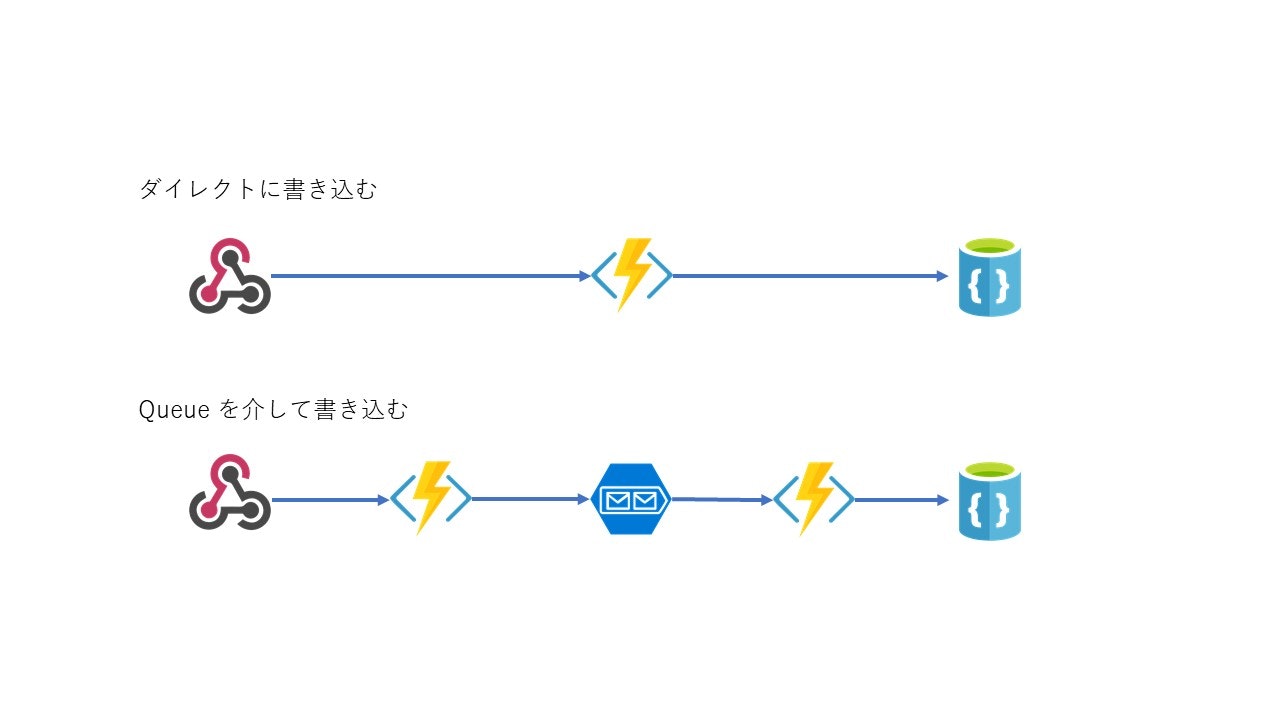
という構成で、どちらがパフォーマンスが良いかを検証してみよう。このぱたーんにしたがうと当然後者!になりそうである。最初は Consumption プランで試してみた。
前者のほうが何故かパフォーマンスが良いという初回の結果
とりあえず 2000 ユーザぐらいの負荷をかけてみる。
ダイレクト
using System.Net;
public static async Task<HttpResponseMessage> Run(HttpRequestMessage req, IAsyncCollector<object> outputDocument, TraceWriter log)
{
log.Info("DirectWrite Trigged!");
// Get request body
var body = await req.Content.ReadAsStringAsync();
await outputDocument.AddAsync(body);
return req.CreateResponse(HttpStatusCode.OK, "Thank your for the message");
}

Queue を介した結果

using System.Net;
public static async Task<HttpResponseMessage> Run(HttpRequestMessage req, IAsyncCollector<string> outputQueueItem, TraceWriter log)
{
log.Info("C# HTTP trigger function processed a request.");
var body = await req.Content.ReadAsStringAsync();
outputQueueItem.AddAsync(body);
return req.CreateResponse(HttpStatusCode.OK, "Thank you for sending messages");
}
using System;
public static async void Run(string myQueueItem,IAsyncCollector<object> outputDocument, TraceWriter log)
{
log.Info($"C# Queue trigger function processed: {myQueueItem}");
await outputDocument.AddAsync(myQueueItem);
}
な、なんでやねん
というわけで結果をみると、なんでやねんとしか言いようのない結果になった。想定と逆だ。ちなみに、何回か繰り返すと、これは、Queue がとか、ダイレクトがとかではなくて、ダイレクトでもエラー三昧になったり、出力が安定しない。一体何なんだろうと思ったのだが、原因は簡単だった。Consumptionプランは、マイクロビリングと言われるつかっただけの課金でオートスケールする。オートスケールはリクエストのカウントでスケールするようだ。
つまり、HttpTrigger が大量のデータをさばくためには、スケールアウトしていないといけないが、この負荷テストの設定だと、一気に2000ユーザのアクセスが来るようになっているので、スケールするまえに、リクエストが来すぎてやられている、もしくは、負荷をかけた後だと、スケールアウトがなされた状態だと、それでも負荷に耐えれている(たぶんデータベースのデータ量とかも関係している)という推測を立てた。
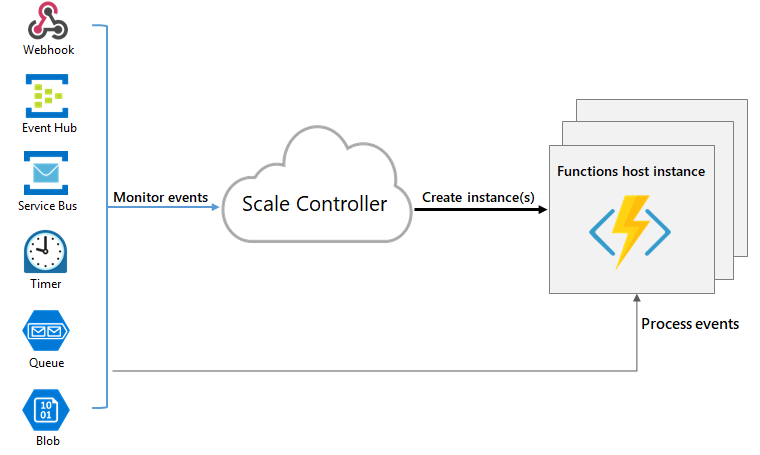
説明を読むと、スケールコントローラーがその役割を果たしている様子。
エラーを見てみるとこんな感じのだったりする。明らかに
Host Error: Microsoft.Azure.WebJobs.Script: Host thresholds exceeded: [Connections].
Session Id: 2ade43e7040548e49a6d620323e9a863
Timestamp: 2017-11-13T13:55:31.367Z
503 - Service Unavailable
だから、たまたまスケールした時にあたっているかということになる。元々、Httpで大量のデータを受け付けるというより、Event Hub や、IoTHub で受け付けるようにするといいのかもしれない。
上記の方法だとなんと100,000 Event / Sec でもさばけている様子だ。だからきっとHttpTrigger の制約で、それは、Web サイトのアクセスと同じような感じでかんがえるとよいかもしれない。
だから、負荷試験をするときに、この設定では、一気に2000ユーザ同時だが、段階を追ってあげていくと、よいのかもしれない。
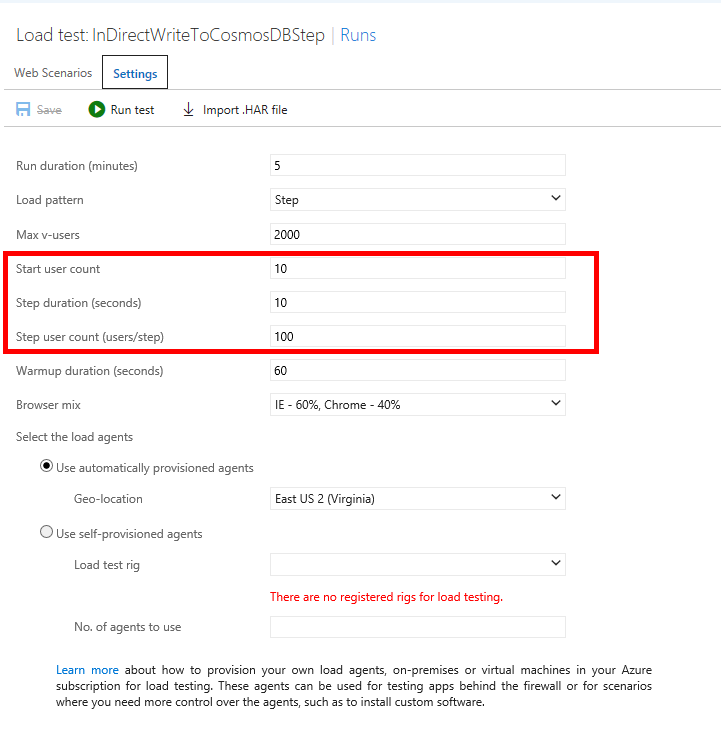
すると、少しエラーがでているが、Queue を介するほうではしっかりと、大体対応できているのがわかる。やっぱりスケールの原因っぽい。

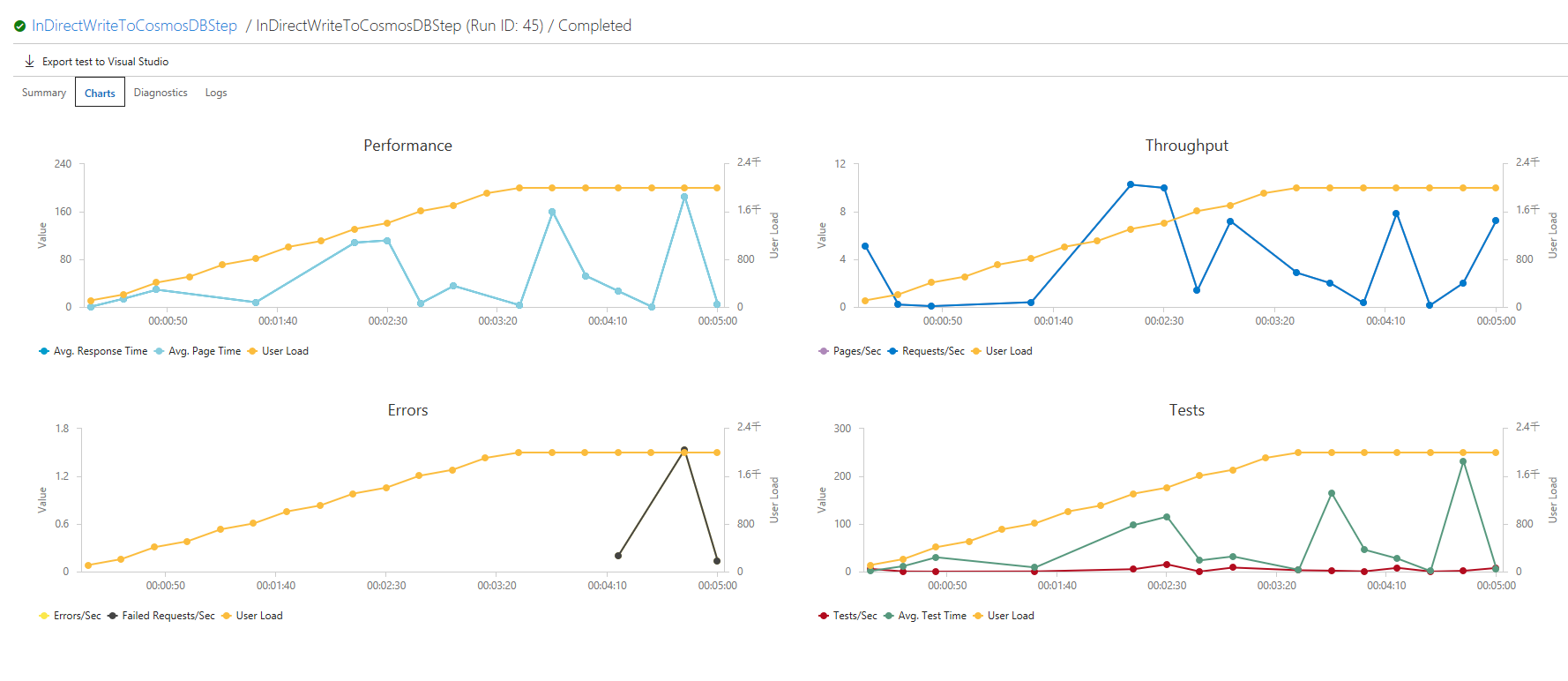
Consumption Plan では、オートスケールなので、大量のリクエストをさばきたいときは、EventHub 経由で非同期にするか、ある程度スケールするように温めるかということになる。ただ、このグラフを見ていると、ある程度のところで、サーバーがスケールしているっぽいのがわかる。今度は、8000 ユーザをステップ実行で流してみる。


途中でスケールしている感じがわかる。スケールが間に合っていない。ただ、耐えき照れていないところは、Consumption plan のサーバーの限界かもしれない。しかし、どんどんスケールしている雰囲気なのは興味深い。やっぱりHttpで高い負荷を受けるときは、AppService Plan を選択するか、もしくは、EventHub/IoTHub で受ける(可能なら)というのが良さげだ。おそらく、Azure Functions の限界ではなく、Consumption Plan の HttpTrigger の限界というべきかもしれない。
App Service Plan を試す
そうすると、このパターンを試すためには、App Service Plan で試すほうがいいかもしれない。そっちのほうが比較がちかくなるだろう。最初から10台のサーバーを並べることにしてみた。1 Core 1.75 GB RAM のプランなので一番しょぼい奴だ。
ダイレクト
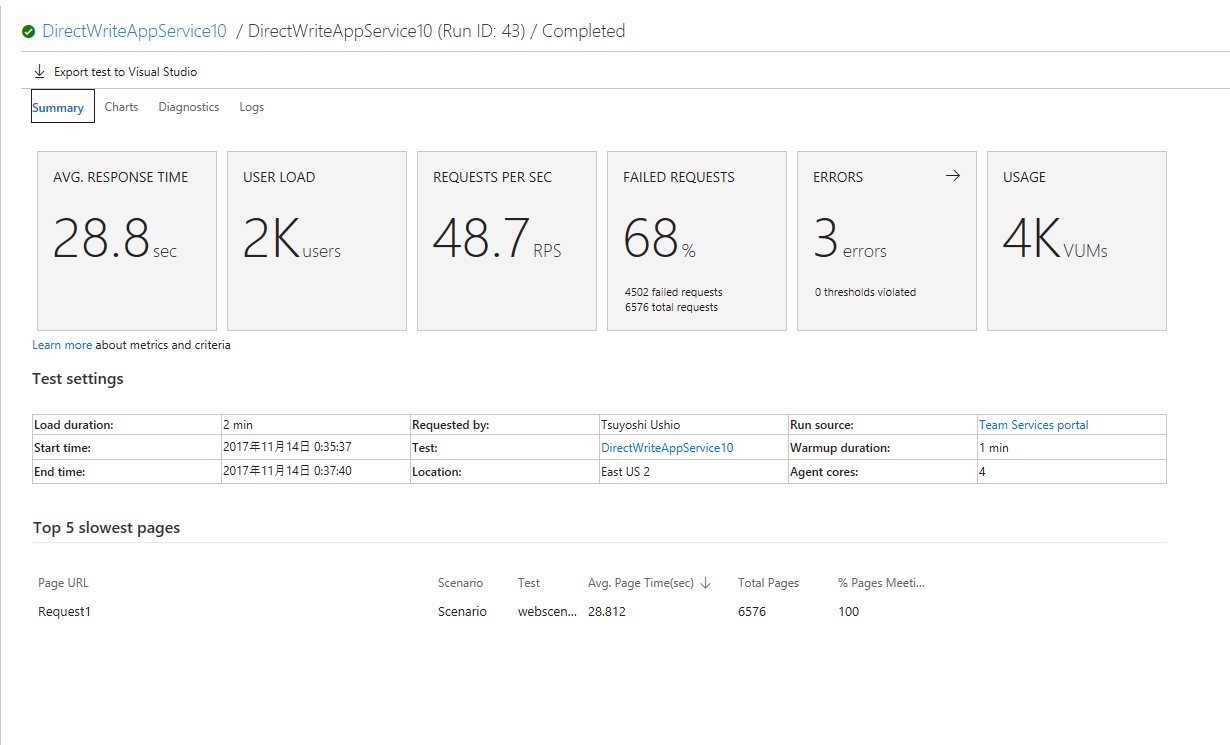
Internal Server Error 500 で落ちている。
Queue 経由
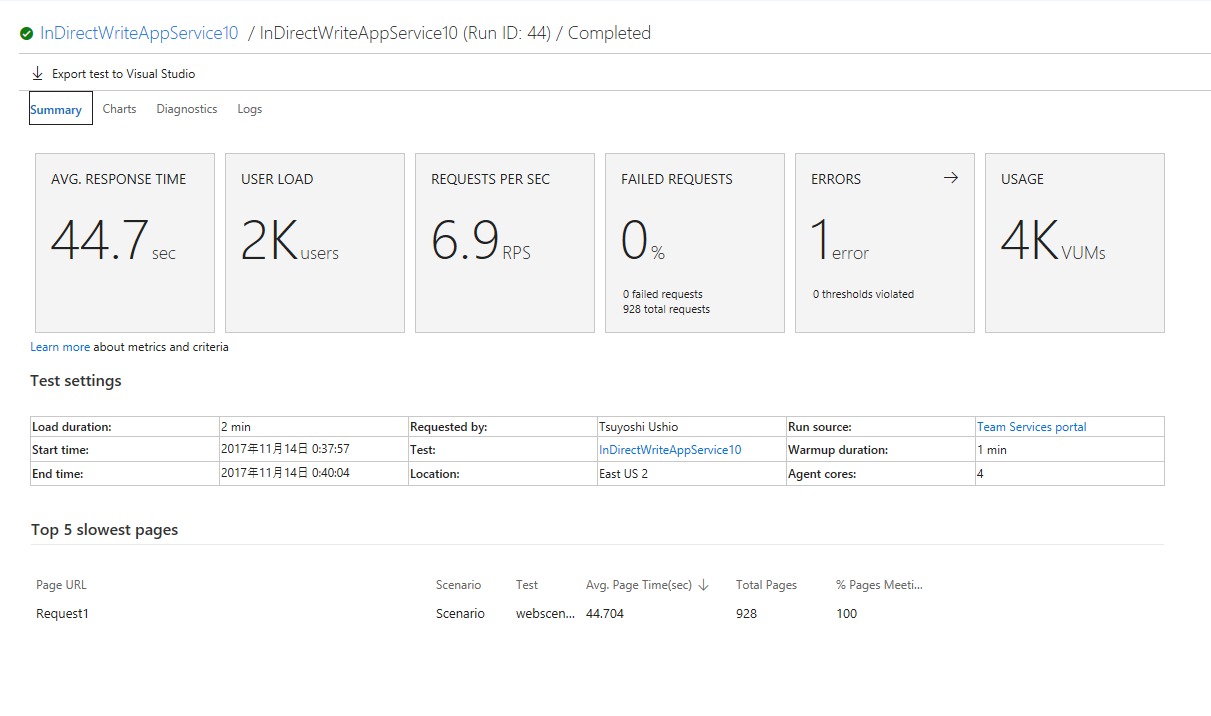
こちらは、1 は、Bad Gateway になっている。
Queue 経由だとほぼエラーが出なくなっている。ダイレクトだと、10並列で、Cosmosに叩き込むことになるので、エラーになっていると思われる。
ただ気になるのは、リクエスト数の違いだ。なぜ違うんだろう。私がうまく負荷テストをやれていない可能性がある。ただ、サーバーのログを見てもエラーにはなっていないので、Queue 経由のほうが高い負荷に耐えられそうだ。
基本的に高い負荷に耐えてもらおうと思うと、
- Consumption Plan で事前に負荷をかけて、温める
- App Service Plan で、スケールをすでにさせておく
後者が特に安定するだろう。App Service Plan はマイクロビリングの意味では意味をなさないかもしれないが、サーバーレスの生産性に注目して、マイクロビリングにこだわらないならいい感じかもしれない。
App Service Plan で高級サーバーでぶん殴ってみる
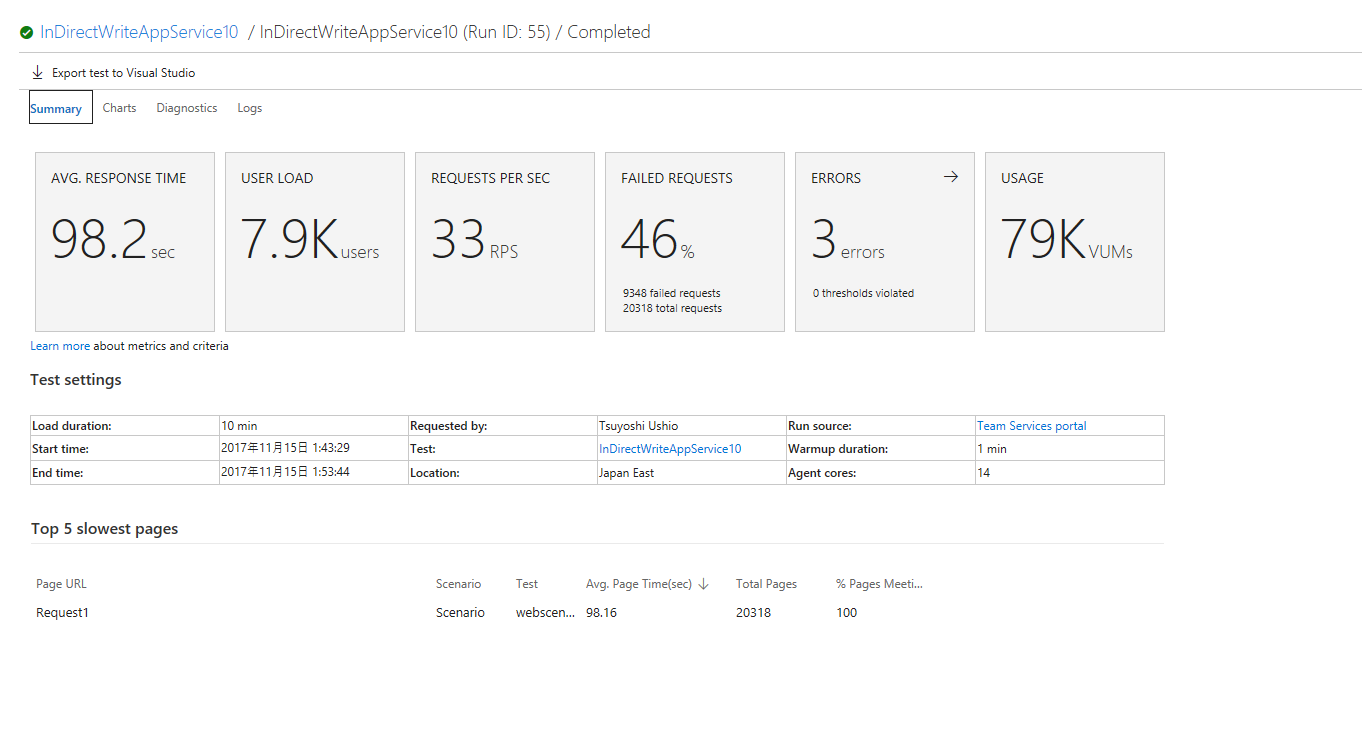
折角なのでためしに、高級サーバーで、14 サーバー並列にしてみよう。

だめだった
2000 user -> 8000 user まで、段階的に上げてみたがうまくいかず。ネックは違うところにあるかもしれない。


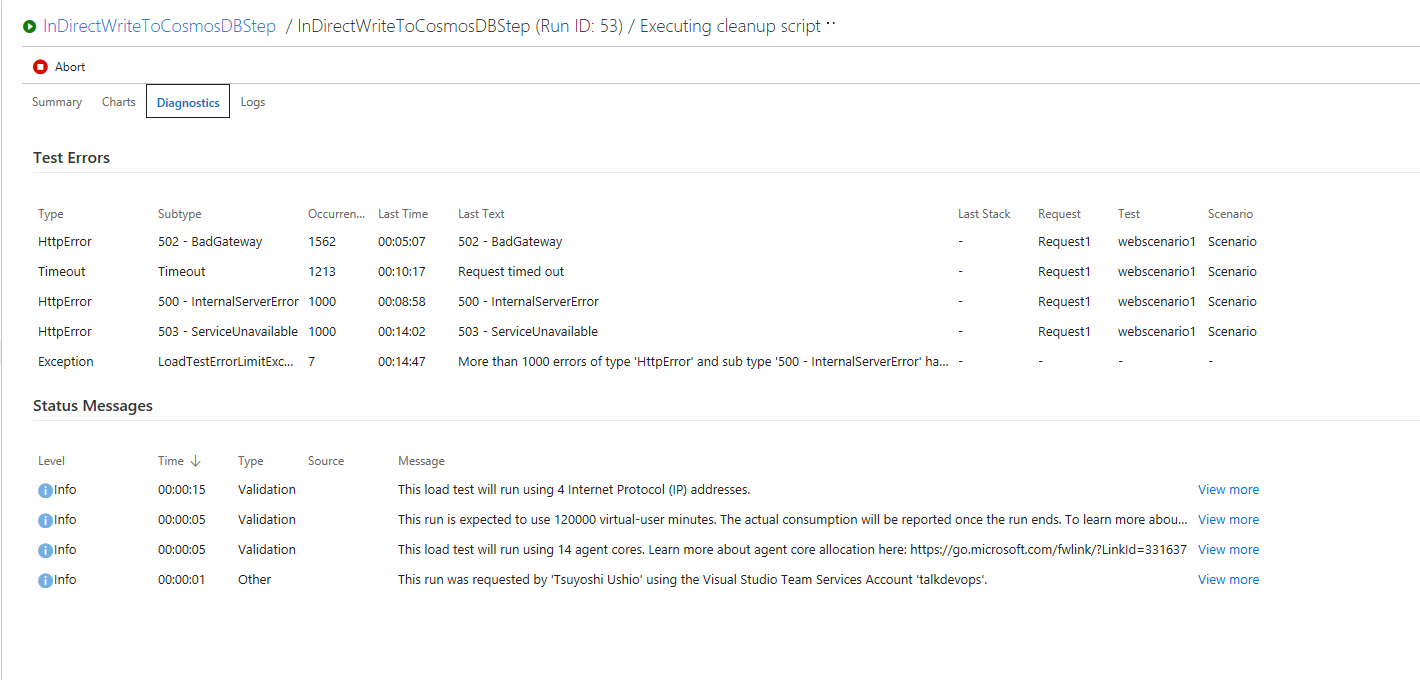
残念ながら、Application Insight をセットしていなかったので、Internal Error の内容はわからず。
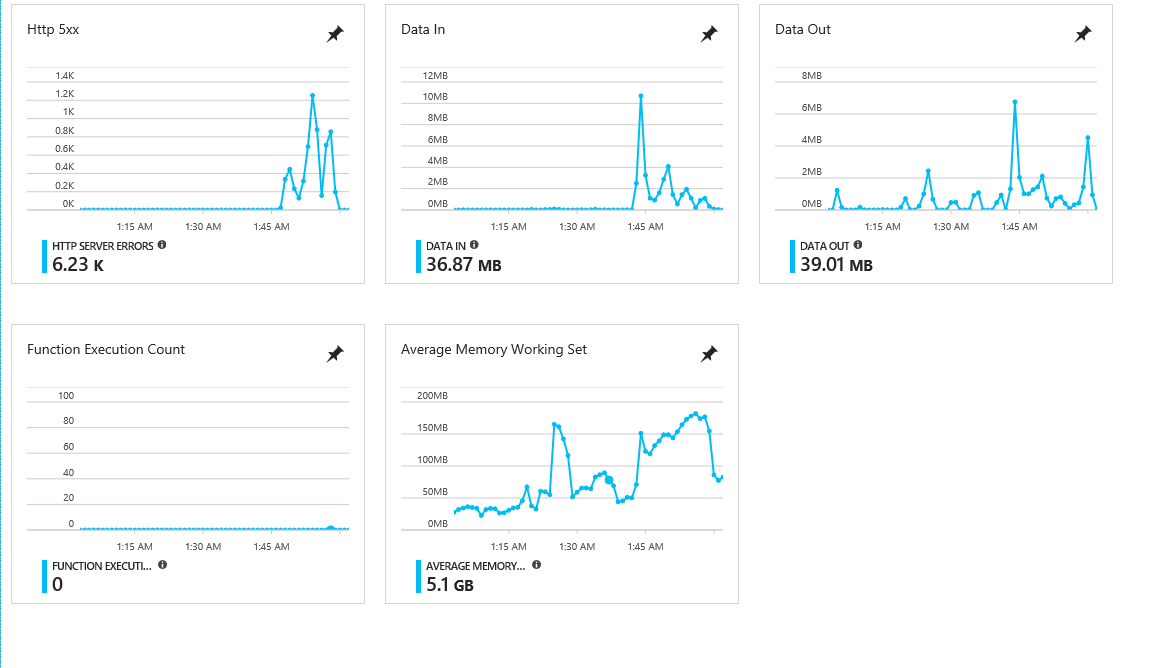
Azure Functions の件数を見ても、エラーはないので、何かサーバーレベルの問題と思われる(ちなみに、件数は、Queue トリガーのほうが少ないので Lost している)
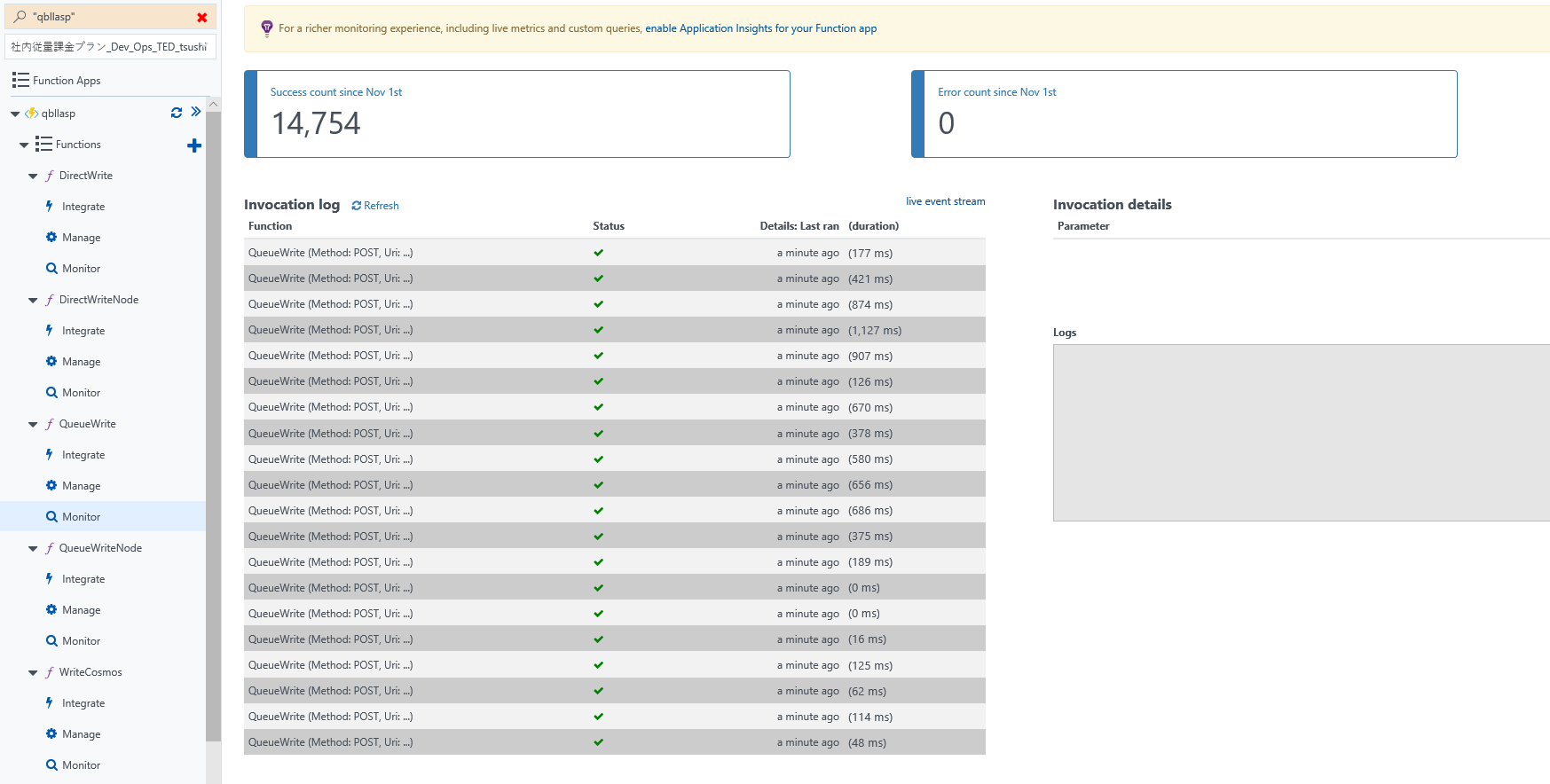
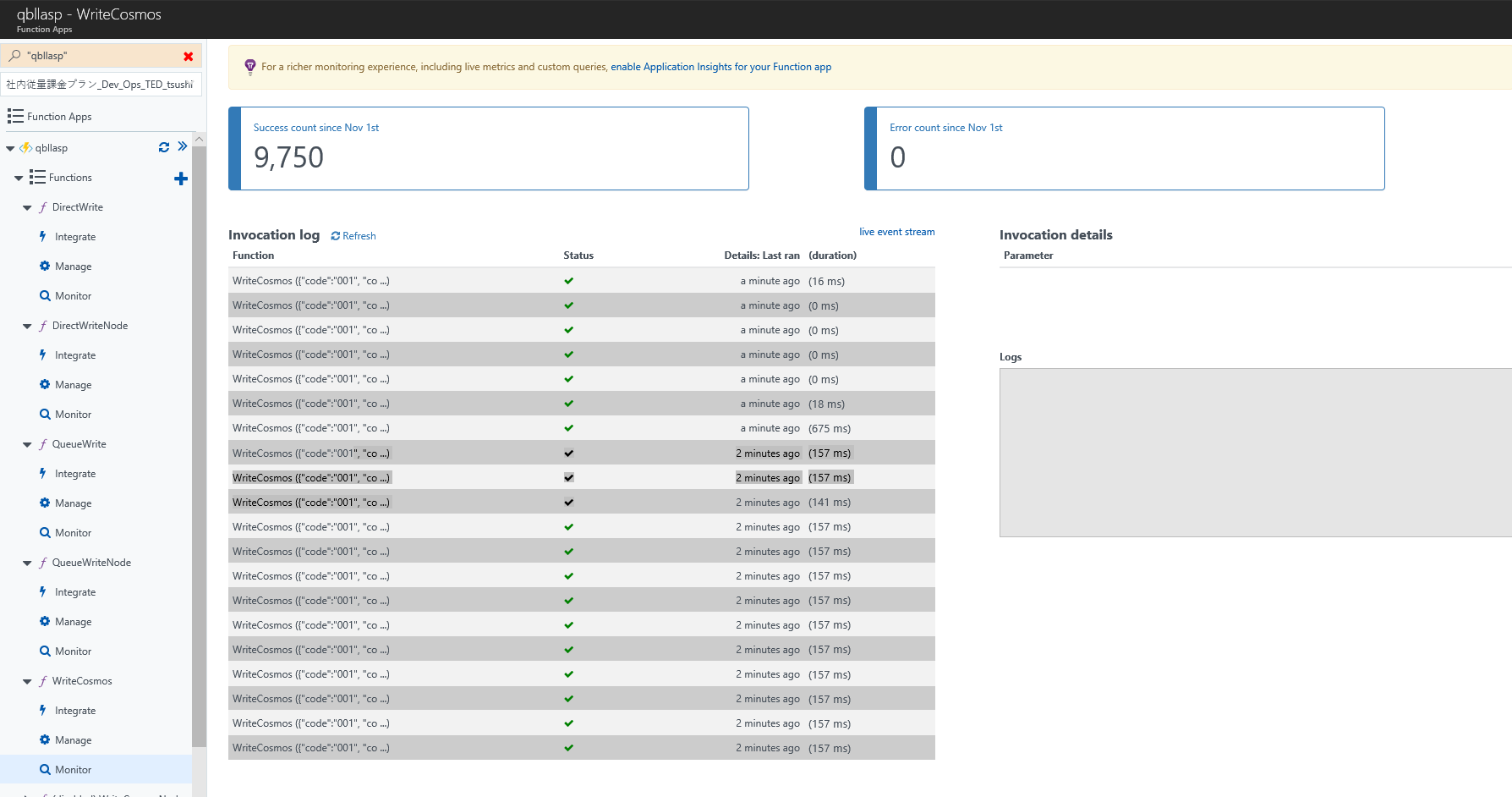
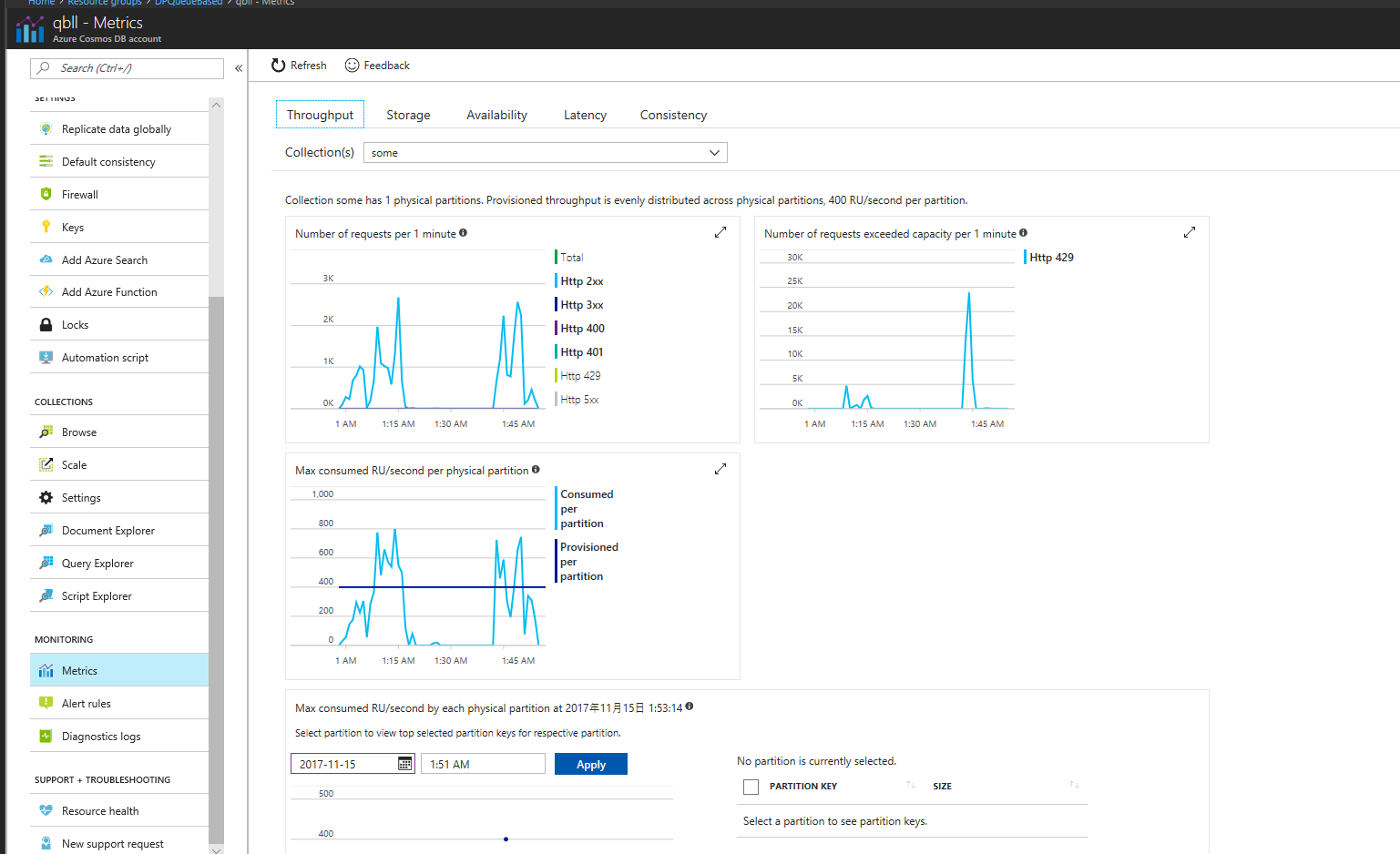
Cosmos 側がねっくなのでは?とも思ったがそうではないようす。400RU のチープなやつだが、一時的に超えても、問題ないようす。
次回
まずは、私の Azure Functions と、WebApps のチューニング、負荷試験の知識が足りないとおもわれるので、自分でうんうんうなってないで、人の助けを借りることにしよう。この結果は適切ではない可能性がある。まずは原因調査から。
次は、C#, Node, Durable Functions の比較、App Service Plan でもっといいサーバーを使ってみるとどうなるかとかを試してみよう。
負荷試験ツール(今回はVSTS) もちゃんと調べたほうがよさそう。あまり設定項目無いからこんなもんと思ってたけど一応目を通しておこう。