Azure DataLake を触ってみたので、忘れないようにメモ。
Data Lake は、Data Lake Storeという非構造・半構造化データ構造化データをMax ペタバイト、数十億個まで格納できるデータレイクです。そして、、Data Lake Analytics はその分析基盤です。Data Lake Analytics を使わず、Hadoop や Spark と組み合わせることもできそうです。Data Lake Analytics では、U-SQL という言語を使います。これはほぼSQL なので、すぐにに理解できそうです。
使い道
大量の非構造・半構造データ (csv, tsv など)をがっつり、データレークにほりこんでおいて、超並列で処理させるとかが可能です。いくつかの言語は使えますが、王道は、Visual Studio を使って U-SQL を書くというのがよさげです。ちなみに、CSharpScript というコードビハインドが U-SQL についている様子なのでいろいろごにょごにょ出来そうです。
では、ざっくり触ってみた感じをシェアします。
サンプルデータのアップロード
サーバー側に、Data Lake Store と、 Data Lake Analytics を作ります。Data Lake Store にサンプルデータを入れておきます。Data Explorer というボタンがトップページにあるのでクリックすると、Blob Storage のようなイメージでデータが格納できるようになっています。
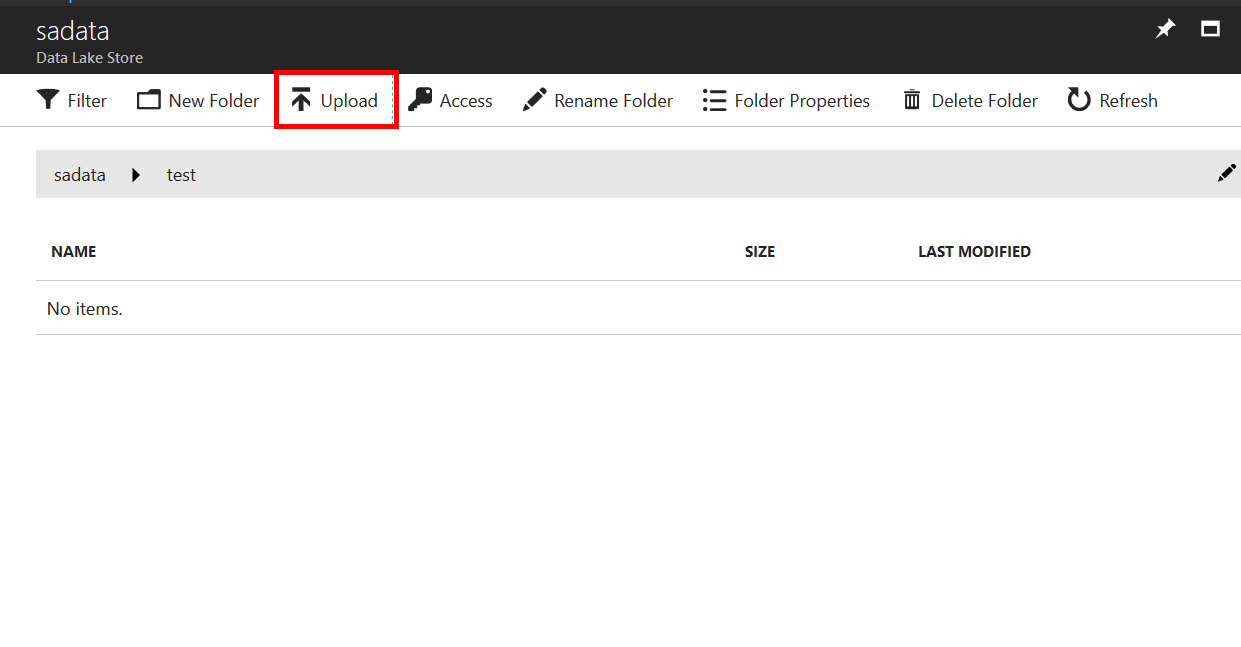
SearchLog.tsvに公式のサンプルデータがあるので、アップロードしてみましょう。簡単に終了

U-SQL を Visual Studio で作成する
Visual Studio 2017で、Data Lake のテンプレートがあるので、それを使ってプロジェクトを作ります。Azure の DataLake とも接続できます。Data Lake エクスプローラがあるので、そこで、データをロカールにダウンロードしておきましょう。
データのダウンロード
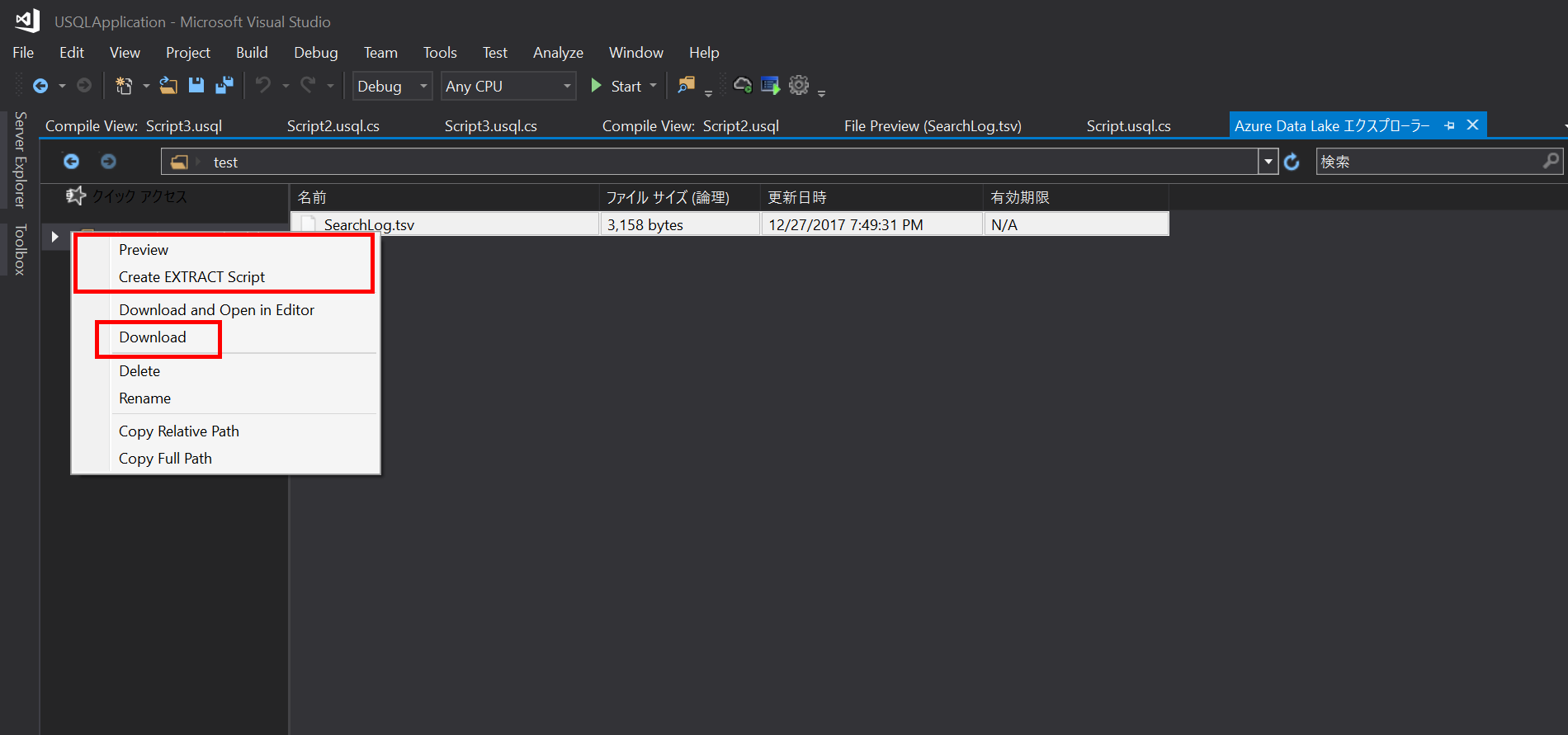
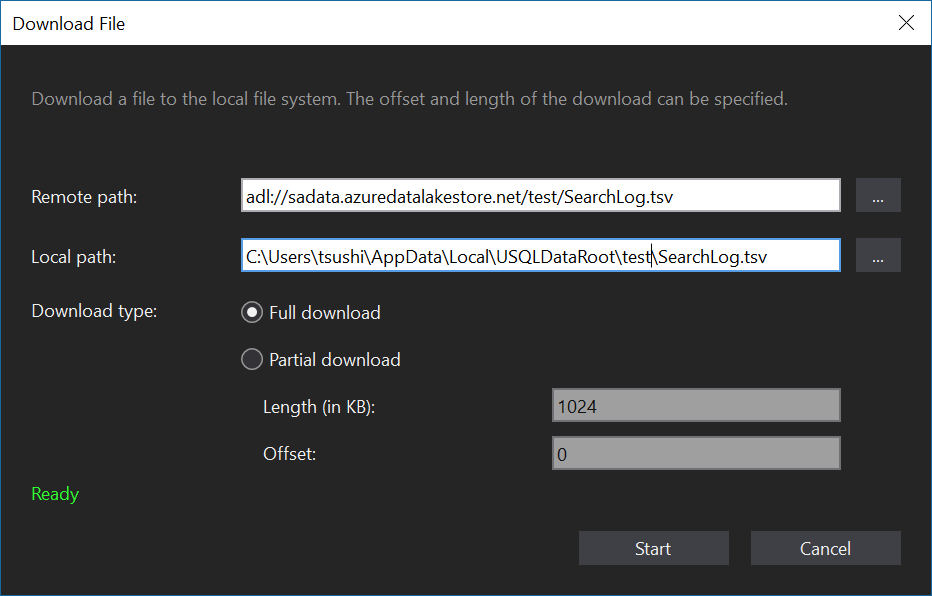
データから、U-SQL テンプレートの生成

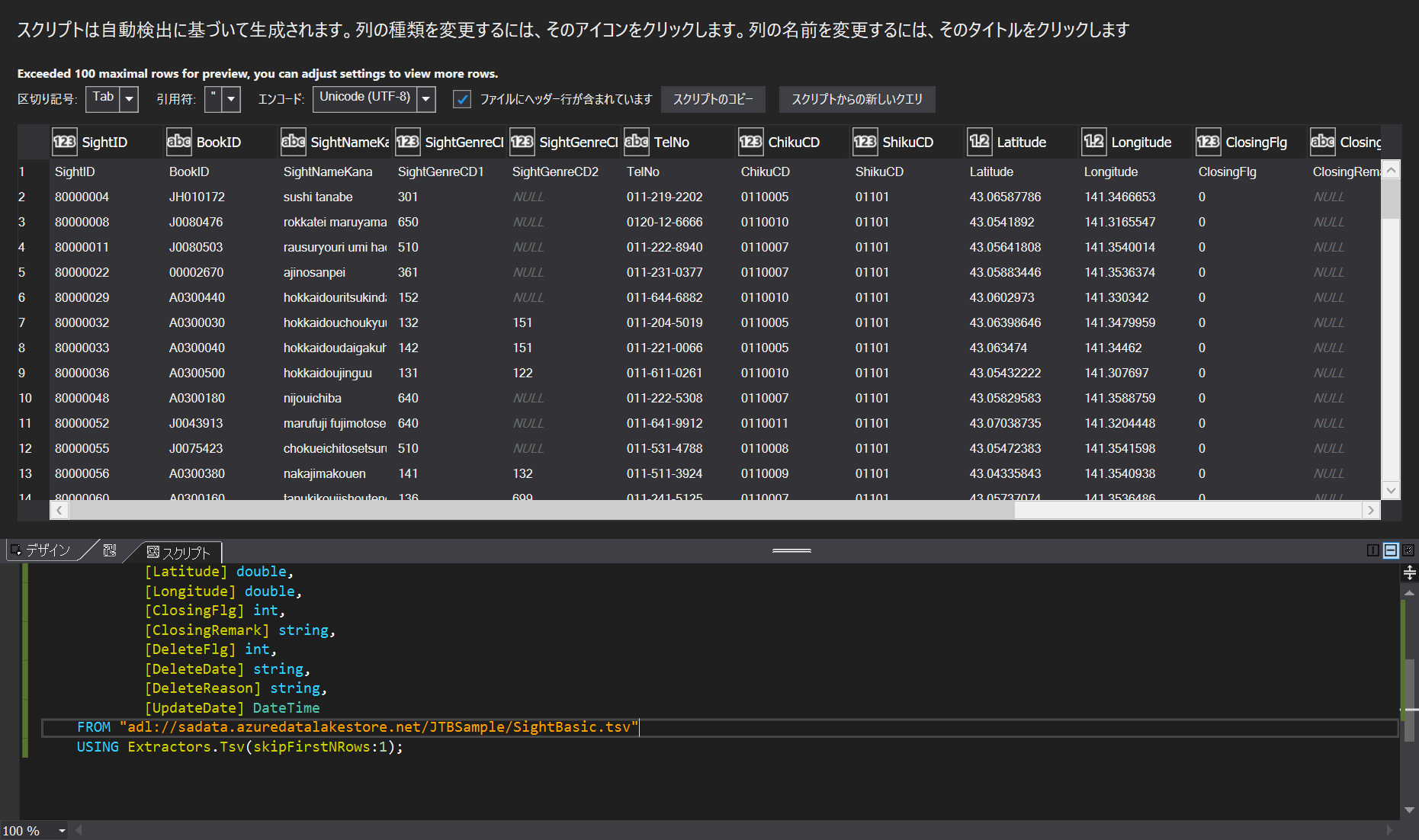
先ほどアップロードしたデータが、Visual Studio からも見れるようになっています。Preview データを見ることができます。Create EXTRACT Script で、この場合は、tsv のデータ構造から、スクリプトのテンプレートを生成してくれます。これはラクですね。
U-SQLの記述
U-SQL は、これらのデータに対してSQLを書いてデータの整形・分析が可能です。まるでRDBみたい。Hive を思い出します。
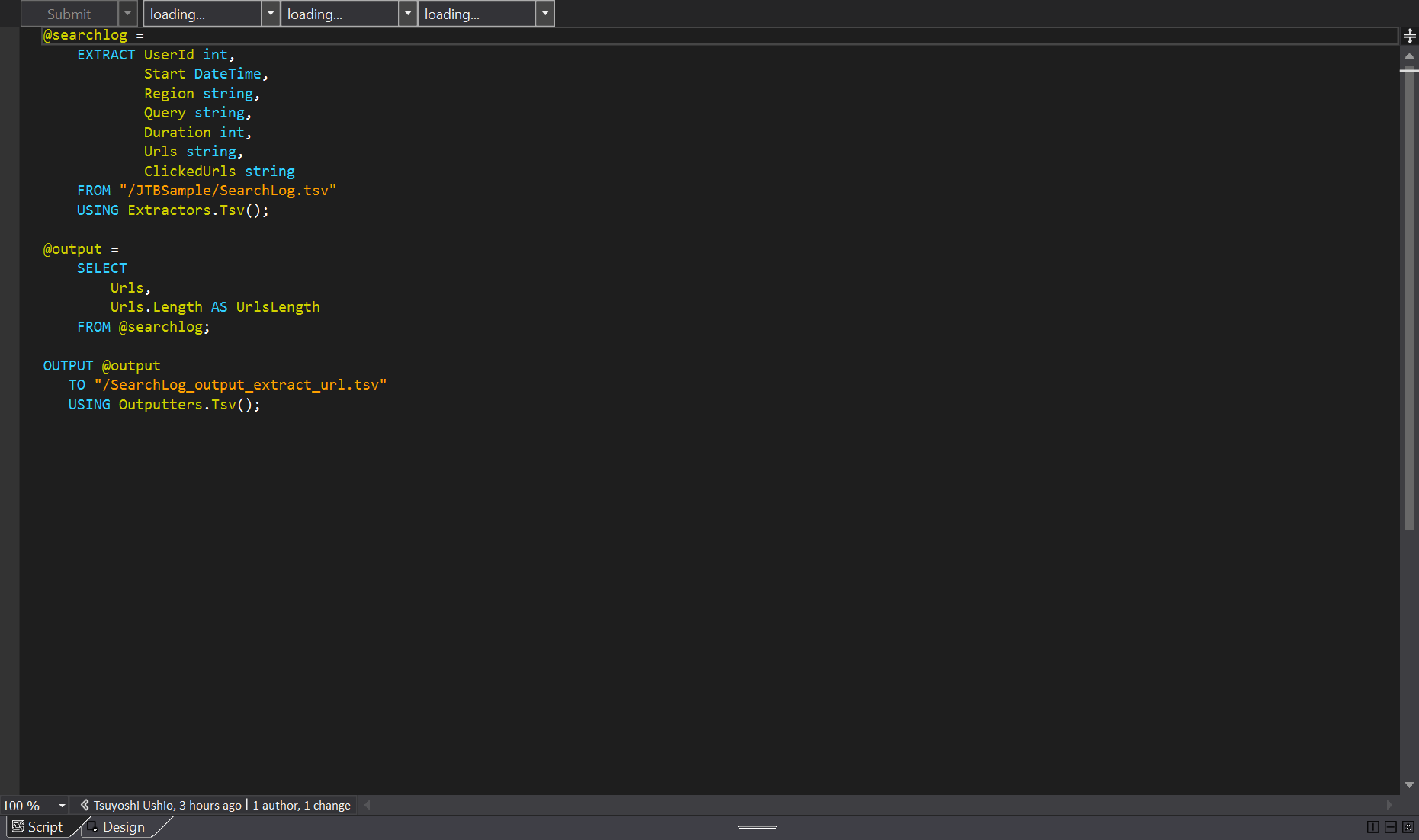
大体コードをみれば、想像がつくのではないでしょうか? Join なども書くことができます。
決定的なガイド
Data Lake はちょっ教えてもらっただけですが、csv, tsv みたいなデータをストアして、分析するには本当に楽な仕組みのようです。大量・大容量のデータも扱えます。じゃあ、このツールのハック力をあげようとしたらやはり、U-SQL を如何にうまく書けるか?になるでしょう。その場合、とってもいいページがあります。
これをやれば完璧らしいです。ガチで触るようになったら触ってみよう