同僚が困っていたので、支援することになって、久々に Docker をやる事になったので、リハビリ兼ねて Kafka をビデオで学んで、最終的に、k8s の上で動かす helm chart を書くところまでしようと思っている。
最近C#のコーディングばかりだったので、しばらく触っていないので、思い出すためにもちょっと動かしてみた。kafka は Zookeeper と連係して、メッセージを捌くメッセージングの仕組みで、Azureでいうと、EventHubなんだけど、Scalaで出来ているっぽく、細かい制御が出来そう。最近EventHubがKafkaのインターフェイスを持つようになったので、最終的に連係させて、Azureのサービスを使いやすくしてみたい。
Docker を思い出す
最初にイメージを探したが、なんと公式イメージが無い。Spotify とかの野良のイメージはあるけど、公式は無い。今回は、kafka に多大な貢献するをしている、confluent のイメージを使ってみたい。
このイメージは、DockerHubで見るとDockerfileへのリンクがなくて見つけにくかったが、上記のリンクのところにある。パラメータの設定がたくさん必要なので、素直にconfluentのページを見るのが良さげ(上記のリンク)
Zookeeper を起動する
これは簡単で、次の通り。kafka は Zookeeper に依存している。上記のConfluent のページのまんま。
docker run -d \
--net=host \
--name=zookeeper \
-e ZOOKEEPER_CLIENT_PORT=32181 \
-e ZOOKEEPER_TICK_TIME=2000 \
-e ZOOKEEPER_SYNC_LIMIT=2 \
confluentinc/cp-zookeeper:5.1.2
設定を確認すると、想像がつくけど、TICK_TIME と SYNC_LIMIT がわからない。TICK_TIME 1回のTickの間隔。SYNC_LIMITは、ZooKeeperでフォロワーがリーダーにシンクする間隔。Tickの単位。つまり、4000 milliseconds 詳細はこちら。
kafka を起動する
これも、confluent をそのままで、
docker run -d \
--net=host \
--name=kafka \
-e KAFKA_ZOOKEEPER_CONNECT=localhost:32181 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:29092 \
-e KAFKA_BROKER_ID=2 \
-e KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 \
confluentinc/cp-kafka:5.1.2
これもだいたい想像がつく。ブローカのIDが2で、REPLICATION_FACTOR=1なのでシングル構成。あとは、リスナーのポートと、Zookeeperのアドレス。
Topicを作成する
Kafkaは全く知らんので、こちらのチュートリアルにしたがって見る。
まともにインストールすると超めんどくさい。(Scalaとか入れないといけない)だから、Dockerでなんとかしたい。
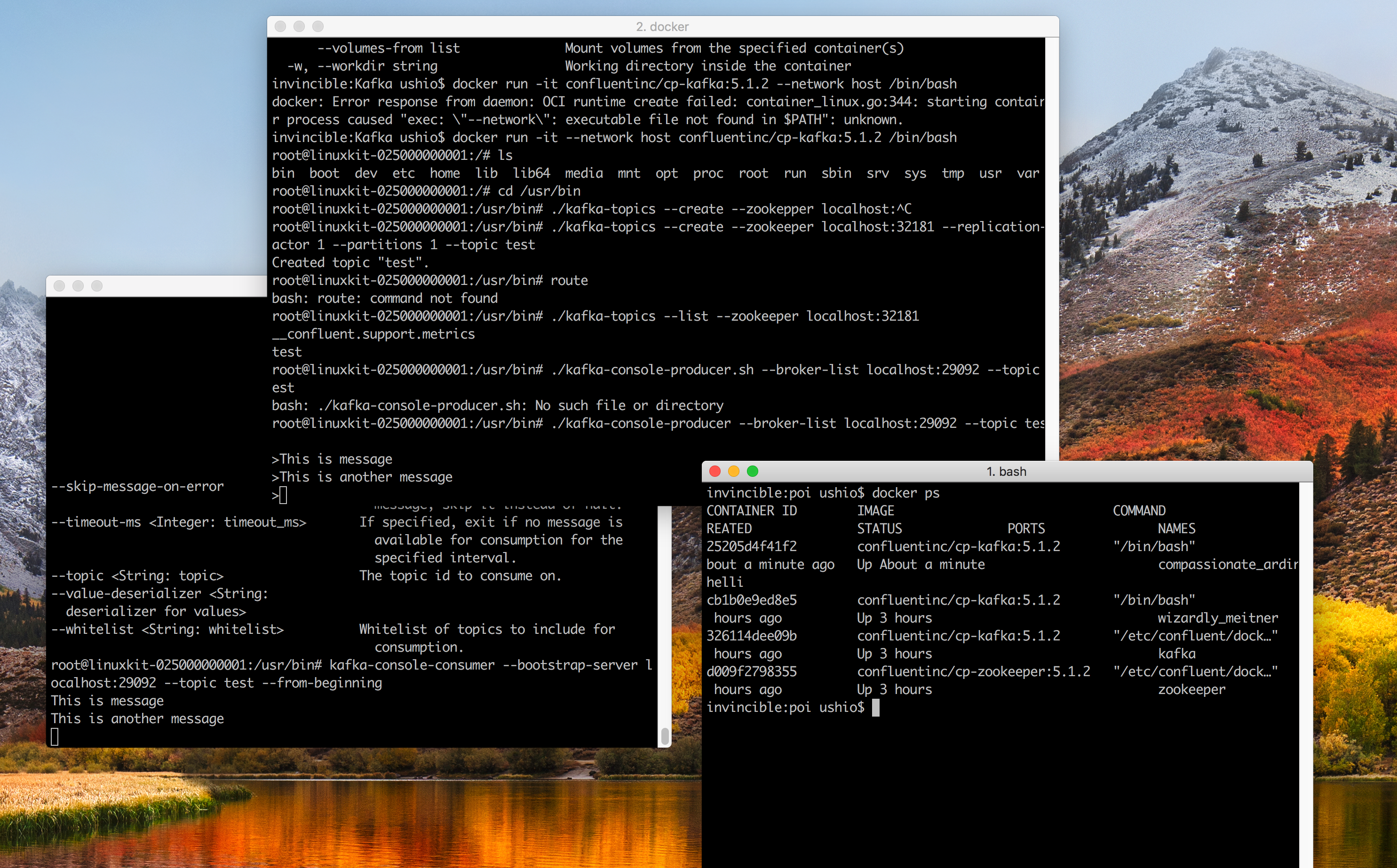
$ docker run -it --network host confluentinc/cp-kafka:5.1.2 /bin/bash
インタラクションモードで起動している。 network を host にしているのは、ホストコンピュータのポートをコンテナから参照したいから。上記のサンプルのdocker run でもそうなっている。まぁ手抜きなのだが、手元で実行して試すためにはいいだろう。ちなみに、network の設定の、bridge(default) と host の違いは、こちらの StackOverflow で丁寧に解説してくれている人がいた。
次にTopic を作成する。cp-kafka のイメージでは、上記のQuickStartで使われているシェルが、/usr/binの下に配置されてる。それを実行してみよう。レプリケーションファクター1、パーティション、トピック名が test という単純な設定
root@linuxkit-025000000001:/# cd /usr/bin
root@linuxkit-025000000001:/usr/bin# ./kafka-topics --create --zookeeper localhost:32181 --replication-factor 1 --partitions 1 --topic test
Created topic "test".
Producer でメッセージを送る
Consumer 本来は、 Java か Scala かで書くのだが、すでにサンプルが作られているので、動かしてみよう。先ほどTopicを作ったコンテナでそのまま実行する。
root@linuxkit-025000000001:/usr/bin# ./kafka-console-producer --broker-list localhost:29092 --topic test
>This is message
>This is another message
>
これで、トピックにメッセージが2つ送信された。まだ読み込みはされていないので、カーソルは一番最初のまま。ポートは、上記のものに合わせている。
Consumer を起動する
例によってインストールが面倒なので、Dockerで動かそう。
$ docker run -it --network host confluentinc/cp-kafka:5.1.2 /bin/bash
root@linuxkit-025000000001:/# cd /usr/bin
root@linuxkit-025000000001:/usr/bin# kafka-console-consumer --bootstrap-server localhost:29092 --topic test --from-beginning
This is message
This is another message
しっかりとメッセージがコンシュームされた。デフォルトでは、読み込みは、オートコミットモードなので、自動的にコミットされている。
コードを読む
Producerと、Consumerのコードは多分単純だからみてみよう。コンソールを読みこんで、KafkaProducerのオブジェクトにSendメッセージを送るだけ。単純ね。ちなみに、シャットダウンフックで、クローズされるようになっている。
ConsoleProducer.scala
def main(args: Array[String]): Unit = {
try {
val config = new ProducerConfig(args)
val reader = Class.forName(config.readerClass).getDeclaredConstructor().newInstance().asInstanceOf[MessageReader]
reader.init(System.in, getReaderProps(config))
val producer = new KafkaProducer[Array[Byte], Array[Byte]](producerProps(config))
Runtime.getRuntime.addShutdownHook(new Thread() {
override def run() {
producer.close()
}
})
var record: ProducerRecord[Array[Byte], Array[Byte]] = null
do {
record = reader.readMessage()
if (record != null)
send(producer, record, config.sync)
} while (record != null)
} catch {
case e: joptsimple.OptionException =>
System.err.println(e.getMessage)
Exit.exit(1)
case e: Exception =>
e.printStackTrace
Exit.exit(1)
}
Exit.exit(0)
}
Consumer 側は、基本的に、Consumerのオブジェクトで、メッセージを受け取るけど、自分でPollingのループを回す必要がある。receiveメソッドで受け取って、それを出力しているだけですね。ちなみに、このクラスを見るとコンフィグが相当ややこしい感じ。こんな単純なのに、なんでたくさん設定するんだろう。
ConsoleConsumer.scala
def process(maxMessages: Integer, formatter: MessageFormatter, consumer: ConsumerWrapper, output: PrintStream,
skipMessageOnError: Boolean) {
while (messageCount < maxMessages || maxMessages == -1) {
val msg: ConsumerRecord[Array[Byte], Array[Byte]] = try {
consumer.receive()
} catch {
case _: WakeupException =>
trace("Caught WakeupException because consumer is shutdown, ignore and terminate.")
// Consumer will be closed
return
case e: Throwable =>
error("Error processing message, terminating consumer process: ", e)
// Consumer will be closed
return
}
messageCount += 1
try {
formatter.writeTo(new ConsumerRecord(msg.topic, msg.partition, msg.offset, msg.timestamp,
msg.timestampType, 0, 0, 0, msg.key, msg.value, msg.headers), output)
} catch {
case e: Throwable =>
if (skipMessageOnError) {
error("Error processing message, skipping this message: ", e)
} else {
// Consumer will be closed
throw e
}
}
if (checkErr(output, formatter)) {
// Consumer will be closed
return
}
}
}
まとめ
こんな感じで、簡単にハローワールドレベルを試すことが出来た。次は、AKSで動かして、Helmチャート化やなぁ。