今回のプロジェクトで使うのに、全然触ったことが無いに等しいので、HDInsight の HBase 版を触ってみた。Linux上で動作しているらしい。」
このチュートリアルを自分なりに変えて実行してみた。
インストール
先ほどのチュートリアルに直接 ARM テンプレートをデプロイできるリンクがあるので、それをクリックする。次に適当に、セッティングをしてみる。
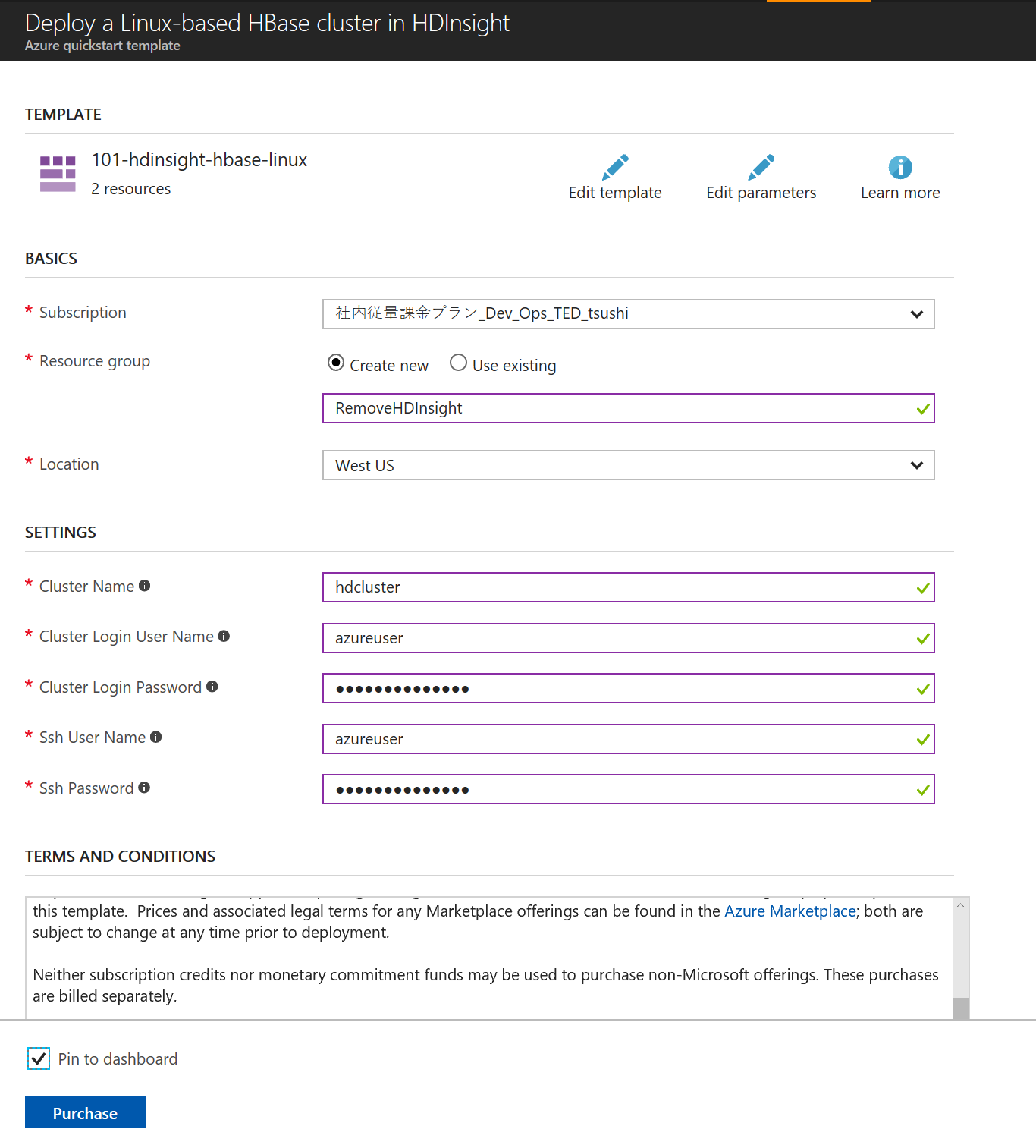
はっきり言って超簡単。ちなみに、ご丁寧に、HDInsight のクラスターはお金がかかるから、データはストレージアカウントに残したまま、HDInsight だけを消すことができる。
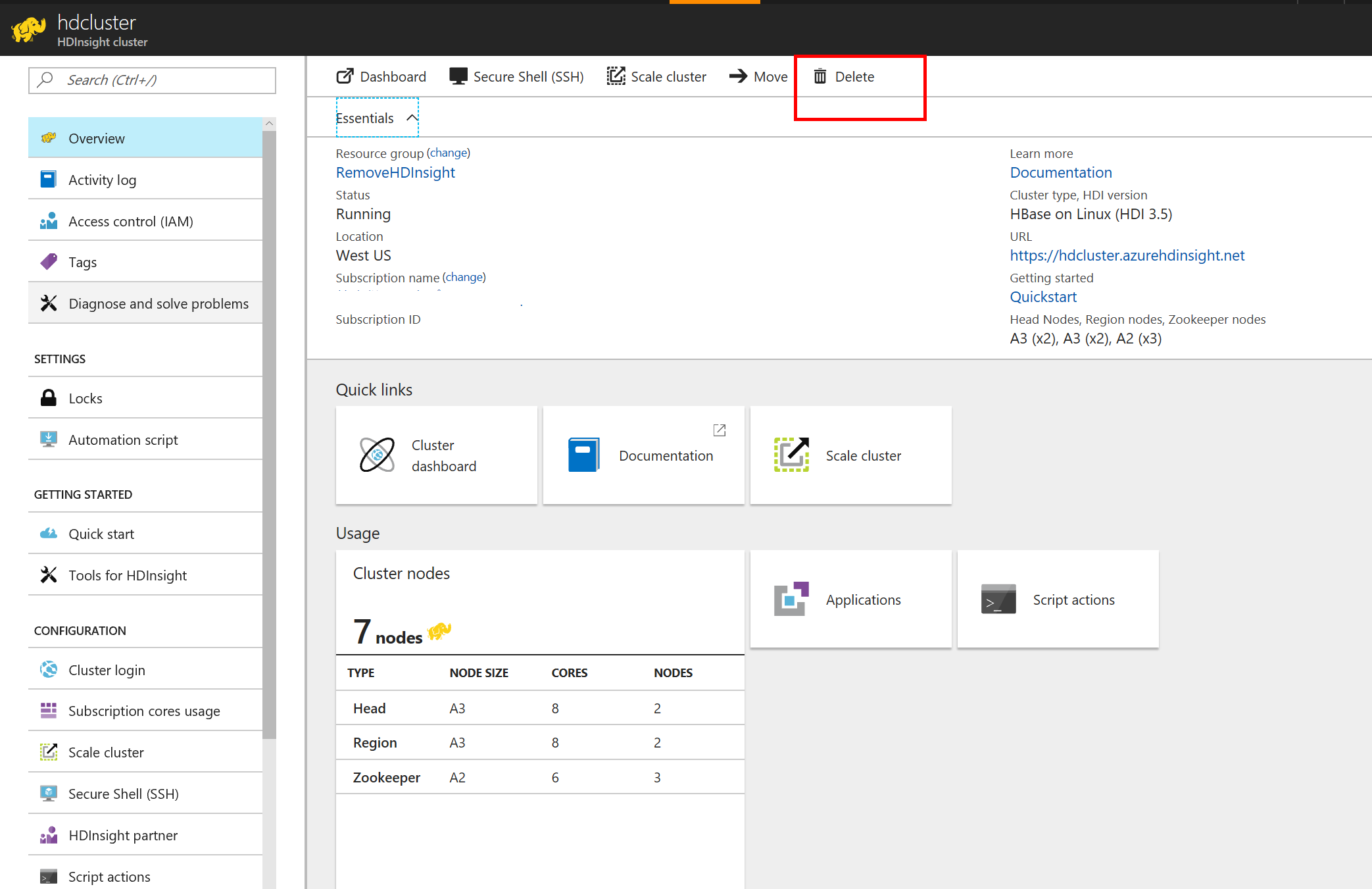
ご丁寧なダッシュボードまでできてくる。
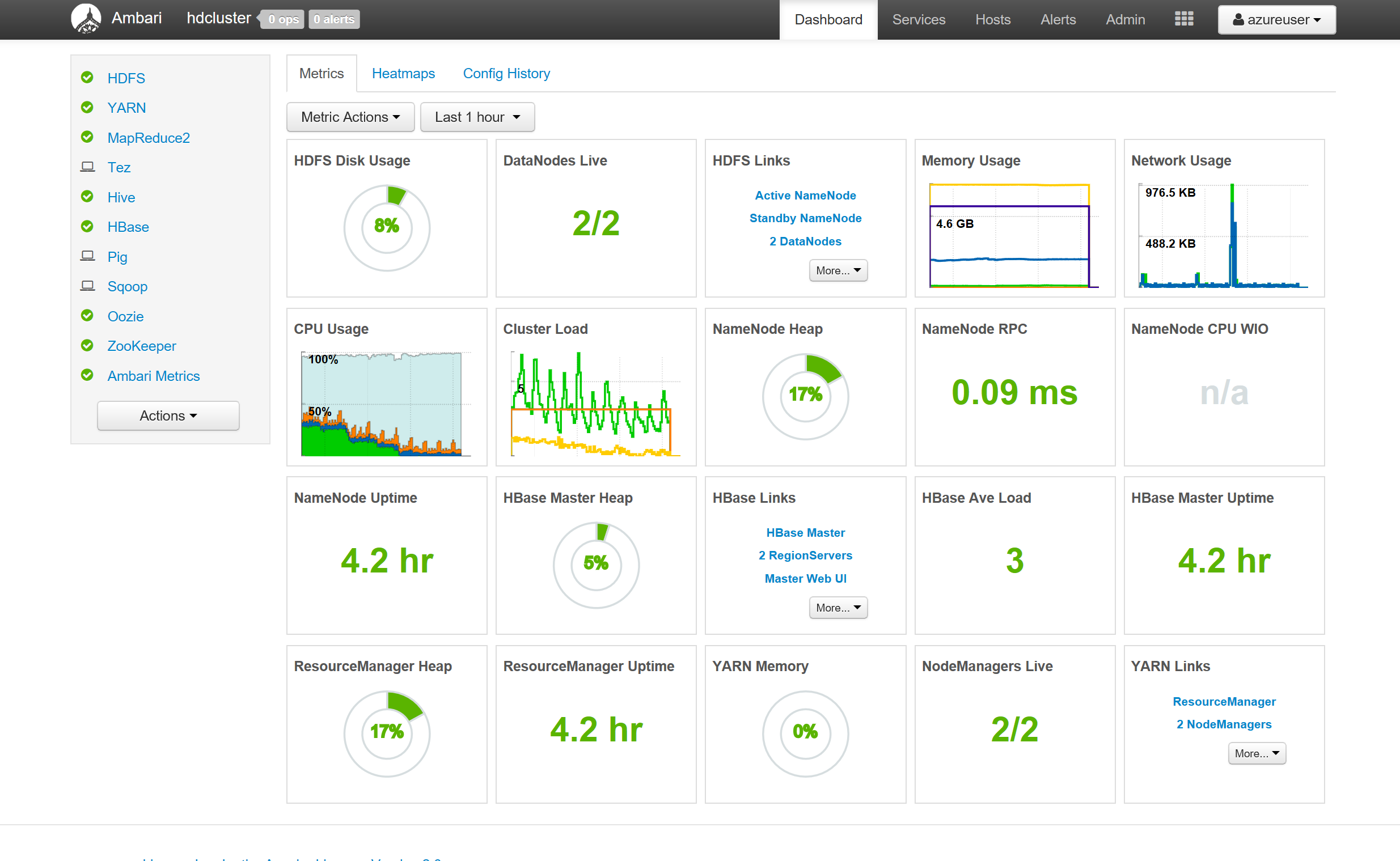
なんて至れり尽くせり。
HBase
HBase は Google の BigTable からアイデアをもらった、データモデルで、大量の構造データに高速にアクセスできるようになっているらしい。
HBase Tutorial
Introduction to HBase Schema Design
使い方
早速使ってみよう。
HBase Shell
hbase shell
で HBase のShell が起動する。
HBase のテーブルの作成
Employee 表を作ってみる。
create 'Employee', 'Personal', 'Work'
Personal, Work というのは、Column Family と呼ばれるもので、カラムのグルーピングに使えるもの。
ちなみに、テーブルを削除したい場合は
disable 'Person'
drop 'Person'
これは、先ほどの HBase Tutorial に分かりやすく書かれている。
どんなテーブルがあるかは list
hbase(main):013:0> list
TABLE
Contacts
Contacts1
Employee
3 row(s) in 0.0100 seconds
テーブルの構造は、先ほどの Column Family までなので、実際にデータを入れるときに定義する。
put 'Employee', '1', 'Personal:Name', 'Tsuyoshi'
put 'Employee', '1', 'Personal:Age', '46'
put 'Employee', '1', 'Work:Title', 'SDE'
put 'Employee', '1', 'Work:Country', 'Japan'
結果は scan コマンドで中身を見れる
hbase(main):019:0> get 'Employee', '1'
COLUMN CELL
Personal:Age timestamp=1501023224880, value=46
Personal:Name timestamp=1501023224668, value=Tsuyoshi
Work:Country timestamp=1501023225871, value=Japan
Work:Title timestamp=1501023224936, value=SDE
4 row(s) in 0.1640 seconds
HBase の Shell から抜けたいときは exitで。
データのインポート
タブ区切りのデータをインポートしてみる。
2 Volker Will 50 SDE Manager Germany
3 Damien Caro 42 Manager France
4 David Teser 35 SDE United States
これを Azure の Storage Account においてから、次のコマンドを実行する。ちなみに、下記の例は、hdclustersampleという名前のストレージアカウントに、containerという名前のコンテナを作ってその下にemployees.tsv というファイルを作った例になる。hfilieというファイル形式にして、いったん保存。
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns="HBASE_ROW_KEY,Personal:Name,Personal:Age,Work:Title,Work:Country" -Dimporttsv.bulk.output="/example/data/employeesFileOutput7" Employee wasbs://container@hdclustersample.blob.core.windows.net/employees.tsv
その後、HBase にそこから取り込んでいる。こちらのほうが大量データの時に有利なようだ。(直接 HBase にぶち込む方法もある)
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /example/data/employeesFileOutput7 Employee
このオペレーションは、ハマった。どんな意味があるかは、hbaseコマンドを素でたたいたらヘルプが出てくるのでわかるのだが、最初私は、employees.tsv ファイルをサーバーの上の普通のファイルシステムの上に置いて、file:///home/azureuser/employees.tsv とか指定していた。すると、FileNotFound のエラーが出ていて、なんでだろうと思っていた。
でもよくよく考えると当然だ。Hadoopクラスタなのだから、各クラスタのVMの該当のファイルパスのところに、ファイルがあればいいが、そんなのめんどくさい。だから、クラスタから共有してアクセスできる場所におくしかないので、ストレージアカウントが一番楽だろう。
hbase(main):002:0> scan 'Employee'
ROW COLUMN+CELL
1 column=Personal:Age, timestamp=1501023224880, value=46
1 column=Personal:Name, timestamp=1501023224668, value=Tsuyoshi
1 column=Work:Country, timestamp=1501023225871, value=Japan
1 column=Work:Title, timestamp=1501023224936, value=SDE
2 column=Personal:Age, timestamp=1501030594528, value=50
2 column=Personal:Name, timestamp=1501030594528, value=Volker Will
2 column=Work:Country, timestamp=1501030594528, value=Germany
2 column=Work:Title, timestamp=1501030594528, value=SDE Manager
3 column=Personal:Age, timestamp=1501030594528, value=42
3 column=Personal:Name, timestamp=1501030594528, value=Damien Caro
3 column=Work:Country, timestamp=1501030594528, value=France
3 column=Work:Title, timestamp=1501030594528, value=Manager
4 column=Personal:Age, timestamp=1501030594528, value=35
4 column=Personal:Name, timestamp=1501030594528, value=David Teser
4 column=Work:Country, timestamp=1501030594528, value=United States
4 column=Work:Title, timestamp=1501030594528, value=SDE
4 row(s) in 0.9880 seconds
Hive の使用
さて、HBase のテーブルを Hive から使えるようにしてみよう。beeline というツールで Hive を使ってみる。
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -n admin
次に、Hive の表を作ってみる。実態は、HBase のテーブルを参照する。SQL に近い構文でアクセスできるようにだ。
CREATE EXTERNAL TABLE hbaseemployee(rowkey STRING, name STRING, age STRING, title STRING, country STRING)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ('hbase.columns.mapping' = ':key,Personal:Name,Personal:Age,Work:Title,Work:Country')
TBLPROPERTIES ('hbase.table.name' = 'Employee');
検索してみる。クラスターを使っているのを忘れてしまうね。
select * from hbaseemployee;
+-----------------------+---------------------+--------------------+----------------------+------------------------+--+
| hbaseemployee.rowkey | hbaseemployee.name | hbaseemployee.age | hbaseemployee.title | hbaseemployee.country |
+-----------------------+---------------------+--------------------+----------------------+------------------------+--+
| 1 | Tsuyoshi | 46 | SDE | Japan |
| 2 | Volker Will | 50 | SDE Manager | Germany |
| 3 | Damien Caro | 42 | Manager | France |
| 4 | David Teser | 35 | SDE | United States |
+-----------------------+---------------------+--------------------+----------------------+------------------------+--+
beeline を抜けるのは !exit で。
!exit
REST API を使ったクラスターの操作
List
さて、REST API を通しても、HBase のテーブルを操作できる。hdcluster がHDInsight のクラスタ名、azureuser がクラスタを作った時のユーザ名、 SomePassW@rd がパスワードだとする。
$ curl -u azureuser:SomePassW@rd -G https://hdcluster.azurehdinsight.net/hbaserest/
Contacts
Contacts1
Employee
Create table
テーブルの一覧が取得できている。同様に Employee2という表を作成する。ちなみに、Column Family として、Personal, Work を指定している。
curl -u azureuser:SomePassW@rd \
-X PUT "https://hdcluster.azurehdinsight.net/hbaserest/Employee2/schema" \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-d "{\"@name\":\"Employee2\",\"ColumnSchema\":[{\"name\":\"Personal\"},{\"name\":\"Work\"}]}" \
-v
Put data
次にデータをぶち込んでいる。ちなみに途中で出てくるのは次の通り。データはBase64 で書く必要がある。Introduction to HBase Schema Designになぜそうなっているかのヒントがあった。元々RowID の長さが変わるとパフォーマンス問題が見分けにくくなるため、キーにハッシュを使うということがでてくるが、ここでは、Base64のエンコーディングなので、それとは関係ない。
Base64 の変換はBase64 Encode Decodeでどうぞ。
curl -u azureuser:SomePassW@rd \
-X PUT "https://hdcluster.azurehdinsight.net/hbaserest/Employee2/false-row-key" \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-d "{\"Row\":[{\"key\":\"MTA=\",\"Cell\": [{\"column\":\"UGVyc29uYWw6TmFtZQ==\", \"$\":\"VHN1eW9zaGkgVXNoaW8=\"}]}]}" \
-v
Select data
取得も簡単!
curl -u azureuser:SomePassW@rd \
-X GET "https://hdcluster.azurehdinsight.net/hbaserest/Employee2/10" \
-H "Accept: application/json" \
-v
* Connection #0 to host hdcluster.azurehdinsight.net left intact
{"Row":[{"key":"MTA=","Cell":[{"column":"UGVyc29uYWw6TmFtZQ==","timestamp":1501032073321,"$":"VHN1eW9zaGkgVXNoaW8="}]}]}
HDInsight はそんなに知らなくてもよさげなので、明日からはまた普通のハックに戻ります。