今日は、次のハックで使用する Azure DataFactory を触ってみた。基本的にチュートリアルと同じ構成だが、さらっと流されている部分もすべて検証してみた。
Azure Factory は、クラウドベースのデータ統合サービスで、データドリブンワークフローをクラウド上でオーケースとレーションしたり、データの移動を自動化してくれるものだ。
様々なデータソースから、データを抽出して、データソースに同期したり、移行してくれたりする。
基本的に(Tutorial: Create a pipeline with Copy Activity using Data Factory Copy Wizard)[https://docs.microsoft.com/en-us/azure/data-factory/data-factory-copy-data-wizard-tutorial]の手順を流している。
事前準備
チュートリアルにあるように、Storage Account を作成し、SQL database を Azure 上に作成済みである。
また、テーブルも作成済み。テーブル作成は、Visual Studio で実施した。
CREATE TABLE [dbo].[emp] (
[ID] INT IDENTITY (1, 1) NOT NULL,
[FirstName] VARCHAR (50) NULL,
[LastName] VARCHAR (50) NULL
);
GO
CREATE CLUSTERED INDEX [IX_emp_ID]
ON [dbo].[emp]([ID] ASC);
私は、SQL データベースにはあまり慣れていない。ちなみに、クラスタード/非クラスタードインデックスが存在する。クラスタードは、主キーなどに使われるもので、ソートされて格納されるタイプであり、テーブルに1つしかもてない。非クラスターは、いくつも持てるが、B-Tree インデックスタイプ格納方法をとられている。O(logN) のオーダーで検索できるタイプ。
Clustered and Nonclustered Indexes Described
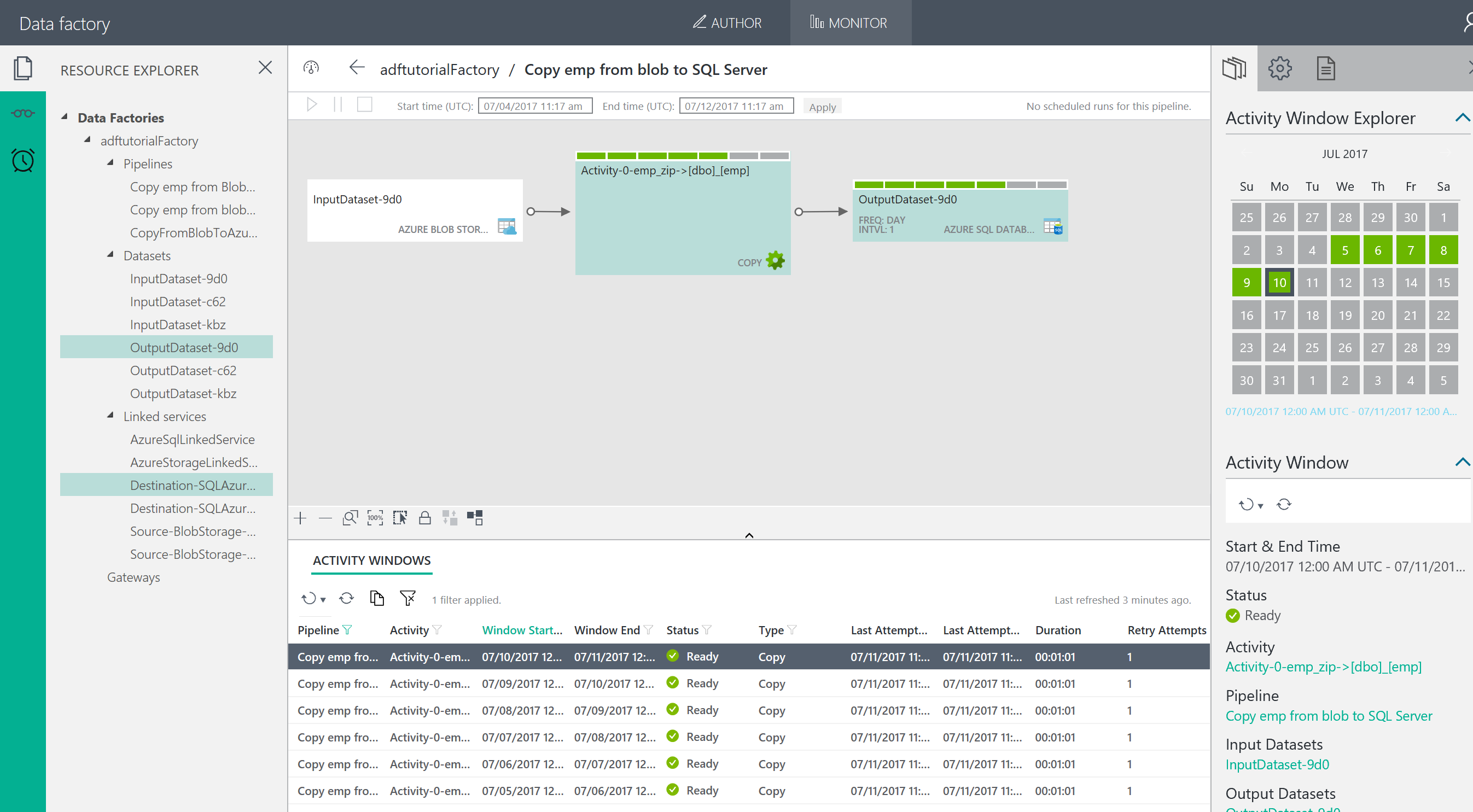
さて、テーブルが晴れたら、Data Factory で、アクションを作っていこう。
データのストレージへの格納
今回は次のようなテキストデータが存在する。
John, Doe
Jane, Doe
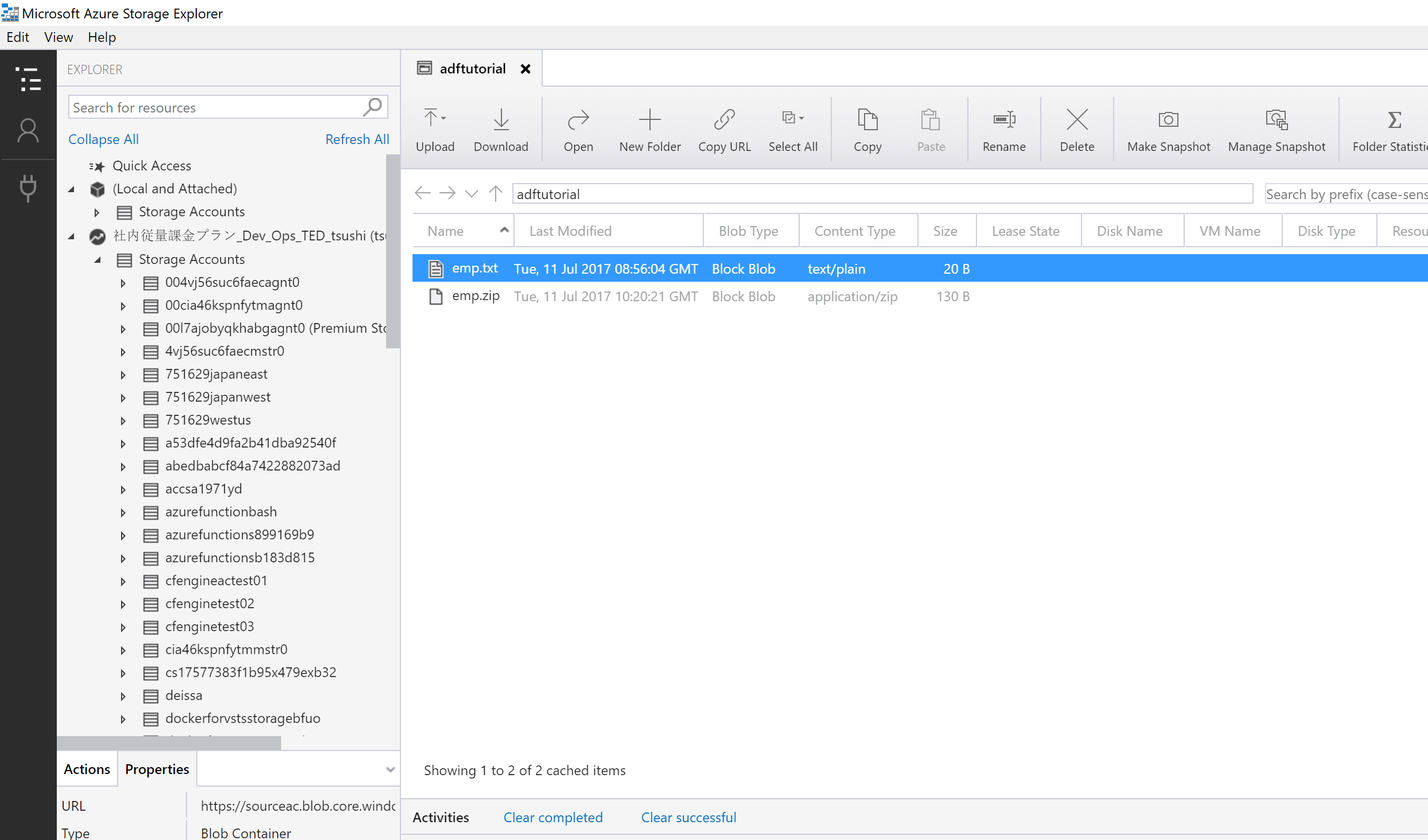
こいつが emp.txt に格納されている。これを、Storage Account のBlob Storage にアップしておく。
ちなみに、Azure のBlob Storage の操作には、Micirosoft Azure Storage Explorerがある。Linux や Mac 向けもある。こいつをつかって、テキストファイルをアップロードする。ここで、ついでに、zip 圧縮して、emp.zip もつくってあげておく。
Azure Data Factory のコンフィグレーション
Azure DataFactory での Copy Data の実行
今回は、様々な方法があるが、まずは簡単そうな Copy Data を使ってみる。ほかにも Portal からする方法、PowerShell や C# で実装する方法、ARM を使う方法などがあるようだ。
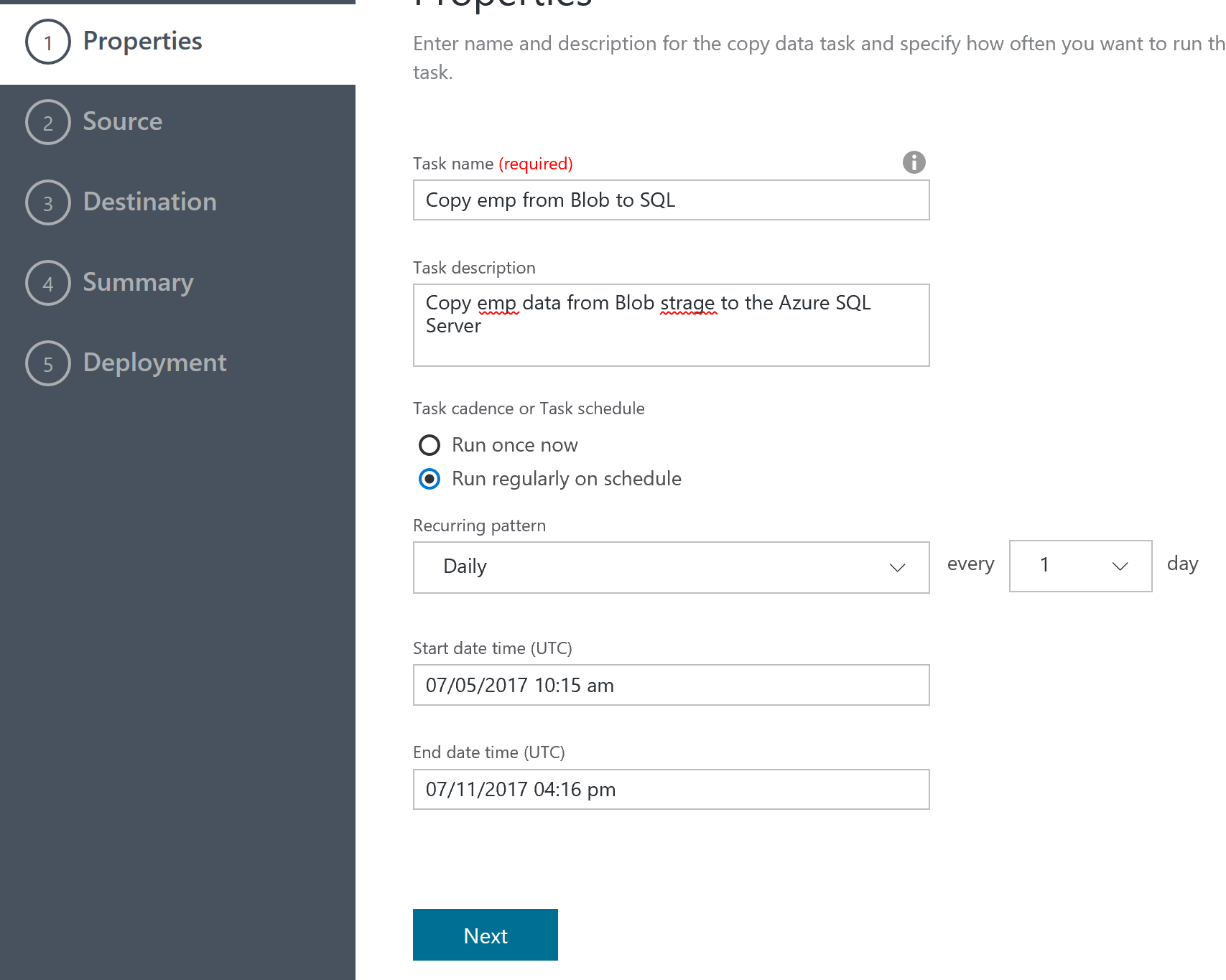
Task のコンフィグレーション
ここでは、タスクを定義している。1回だけの移行と、一定期間同期するような方法が選択できる。ここでは、同期する方法を選んで、開始日を過去日付に、終了日を本日の遅めの時間にしている。
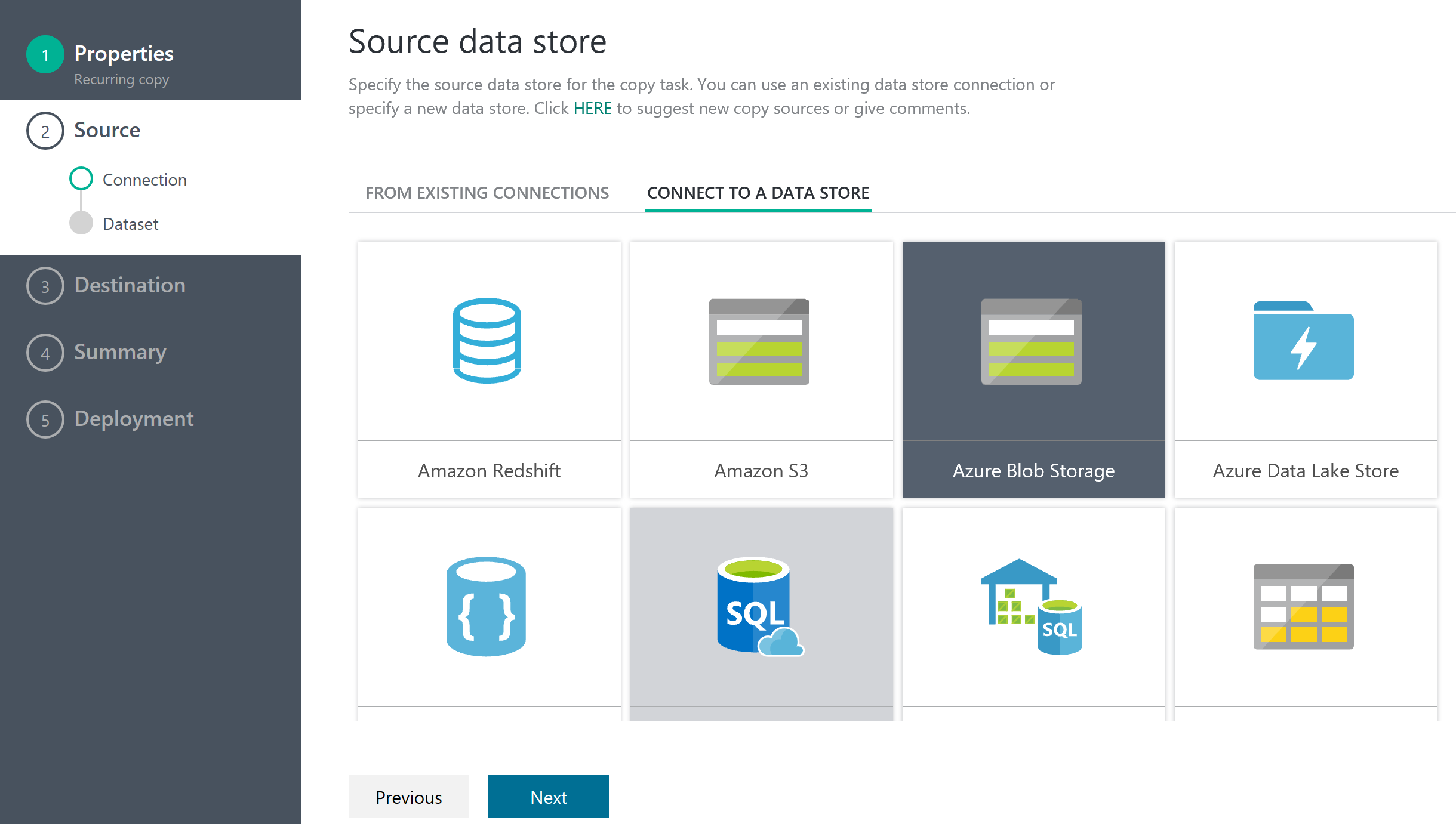
データソースの指定
データの取得元。今回は Storage Account なのでそれを指定する。様々なデータソースからデータを取得できる。どのようなデータソースが使えるかはData movement activitiesにのっている。Azure以外にも、Amazon Redshift, S3, Oracle, SAP, Sybase, Teradata など様々なデータソースから取り込める。
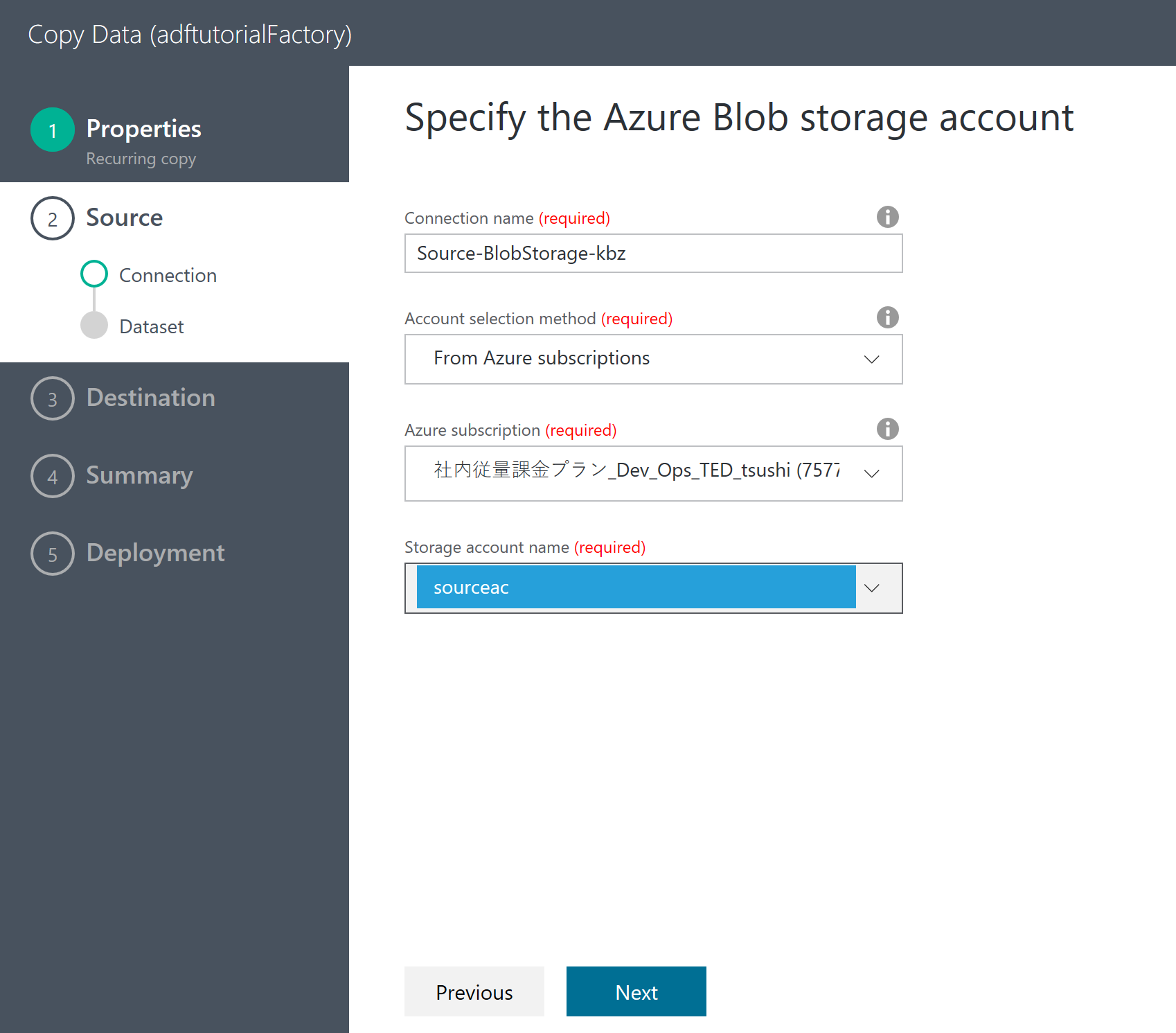
Storage Account の設定
ここでは、先に作った Storage Account を指定している。
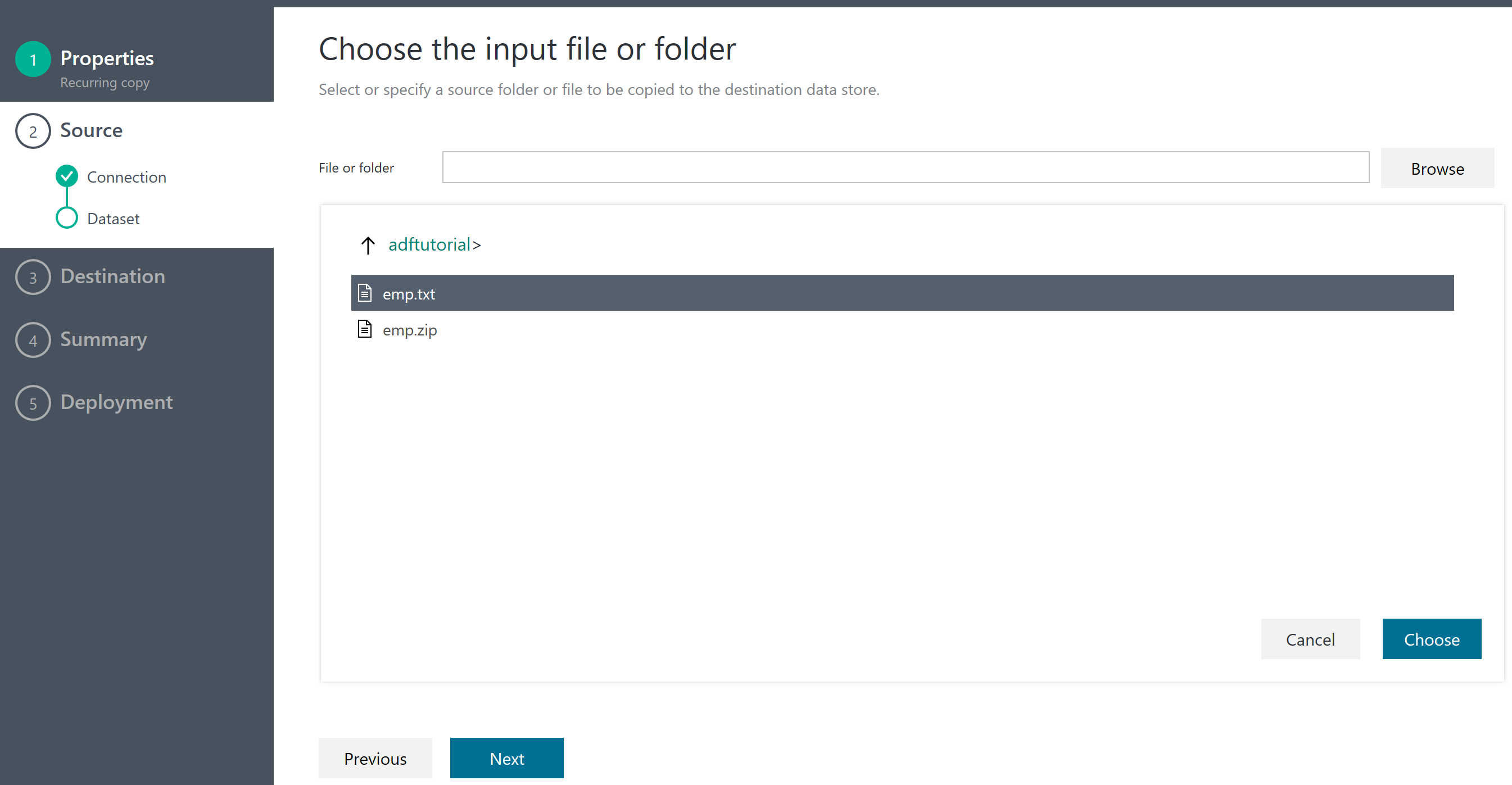
データの取り込み
そして、ファイルを選択できる。普通のプレーンテキストもいけるが、圧縮形式もいけるみたい。emp.zipを選択してみた。
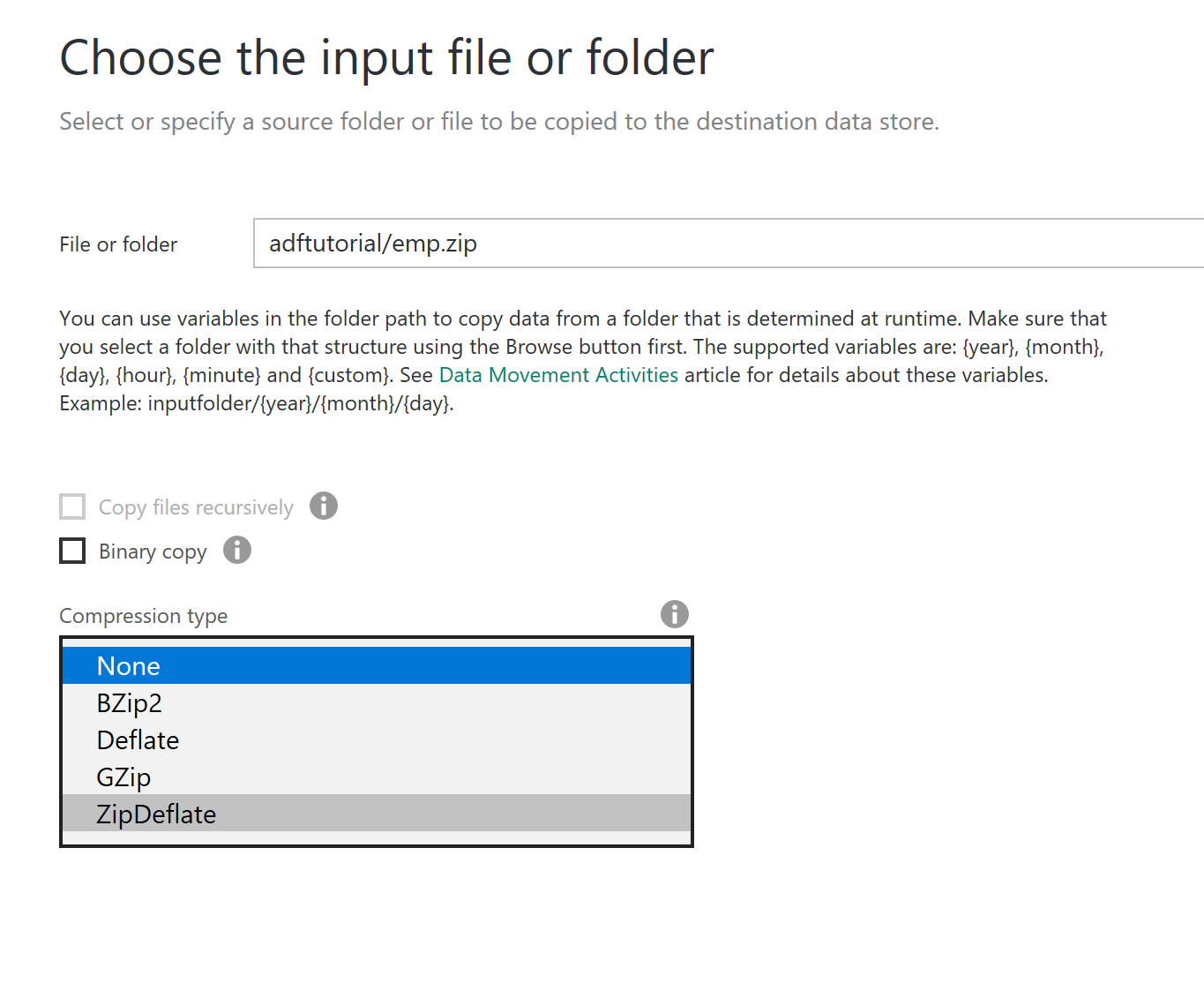
圧縮タイプを選択できるので、ZipDeflate を選択して、Zipの中身からインポートする。ちなみに、プレーンテキストは、NONEを選択する。
ファイルフォーマットの指定。ある程度自動で、検出してくれるようだ。希望のフォーマットで認識できている。
これで取り込もう
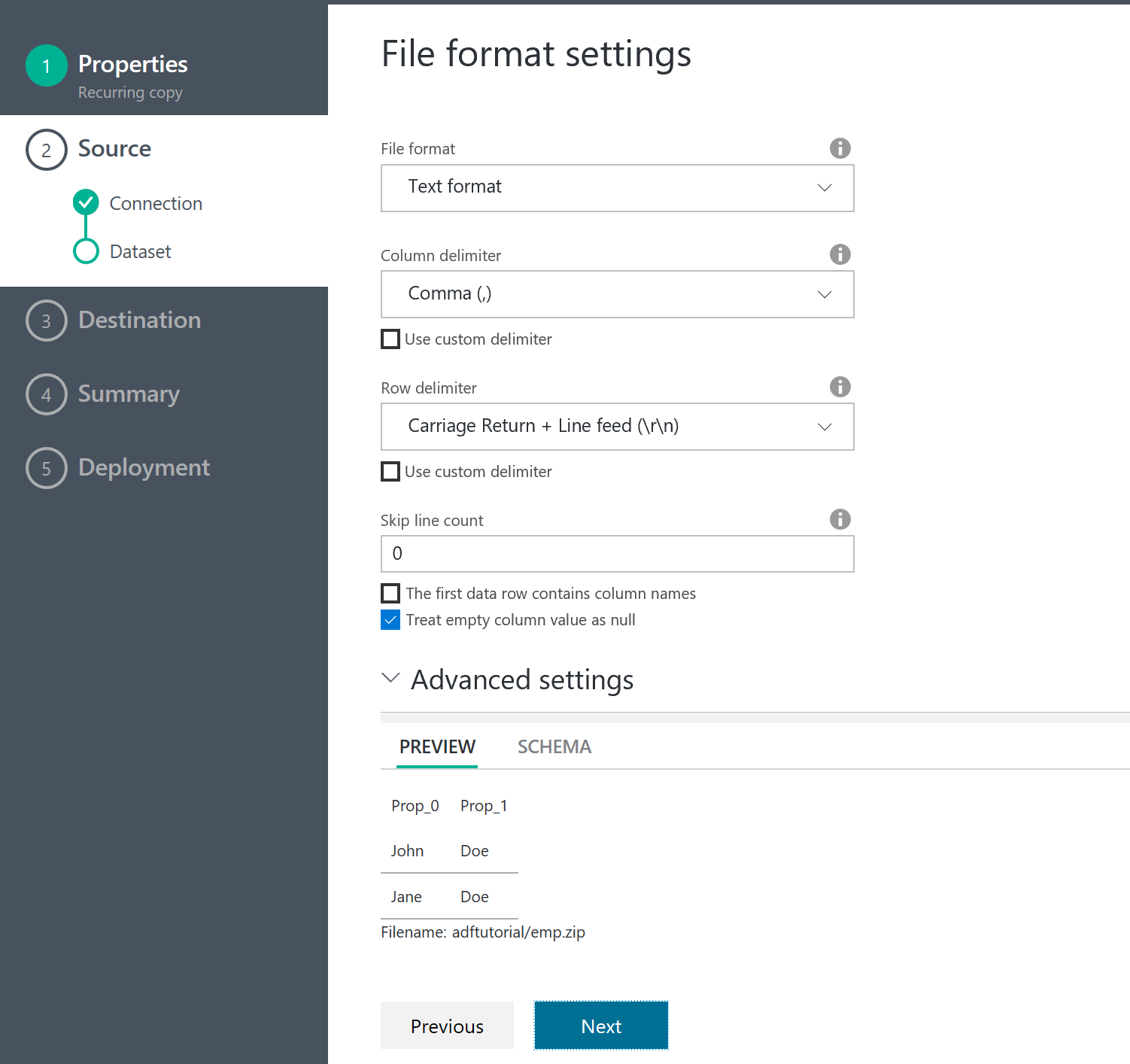
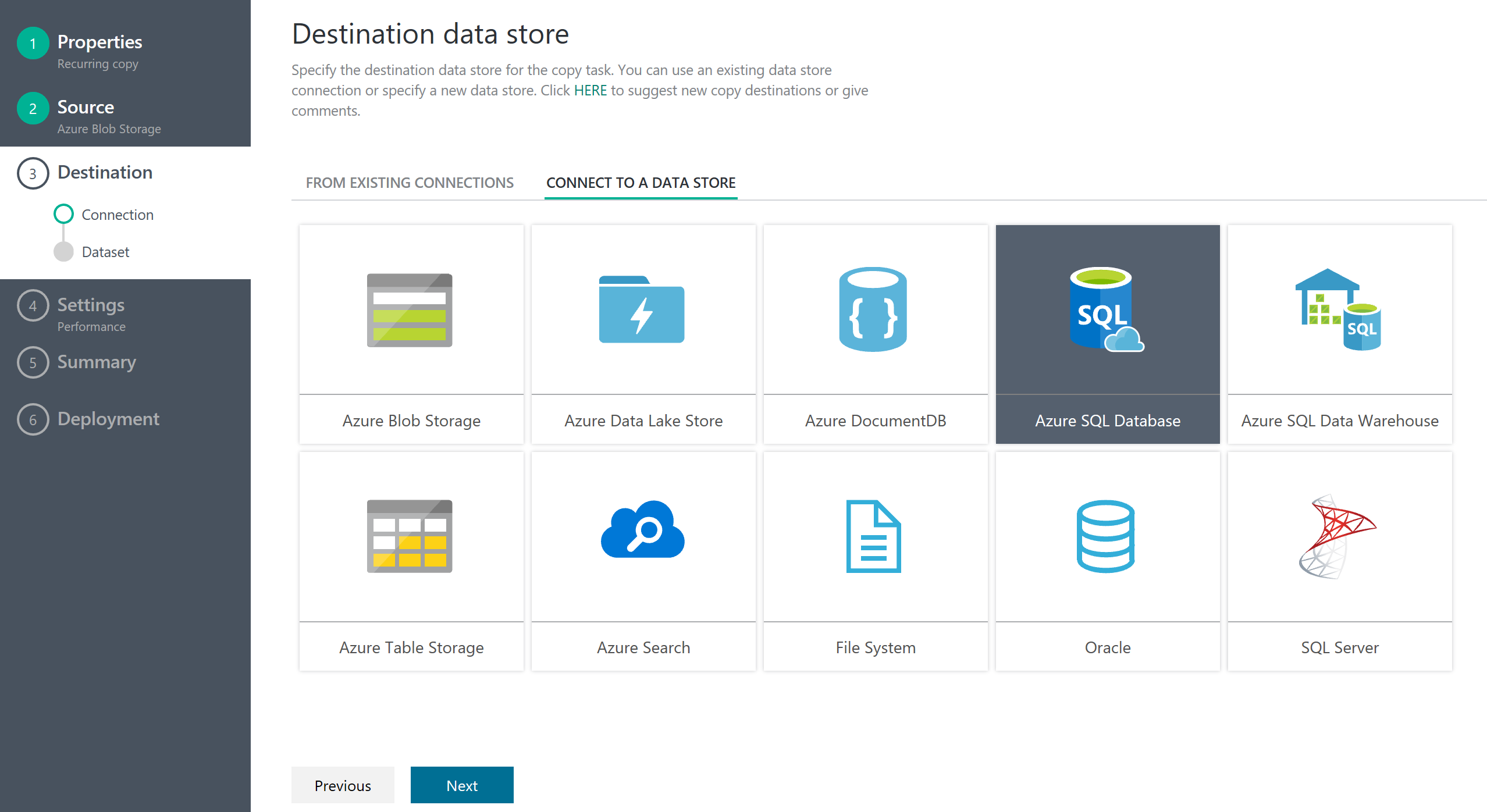
出力データソースの指定
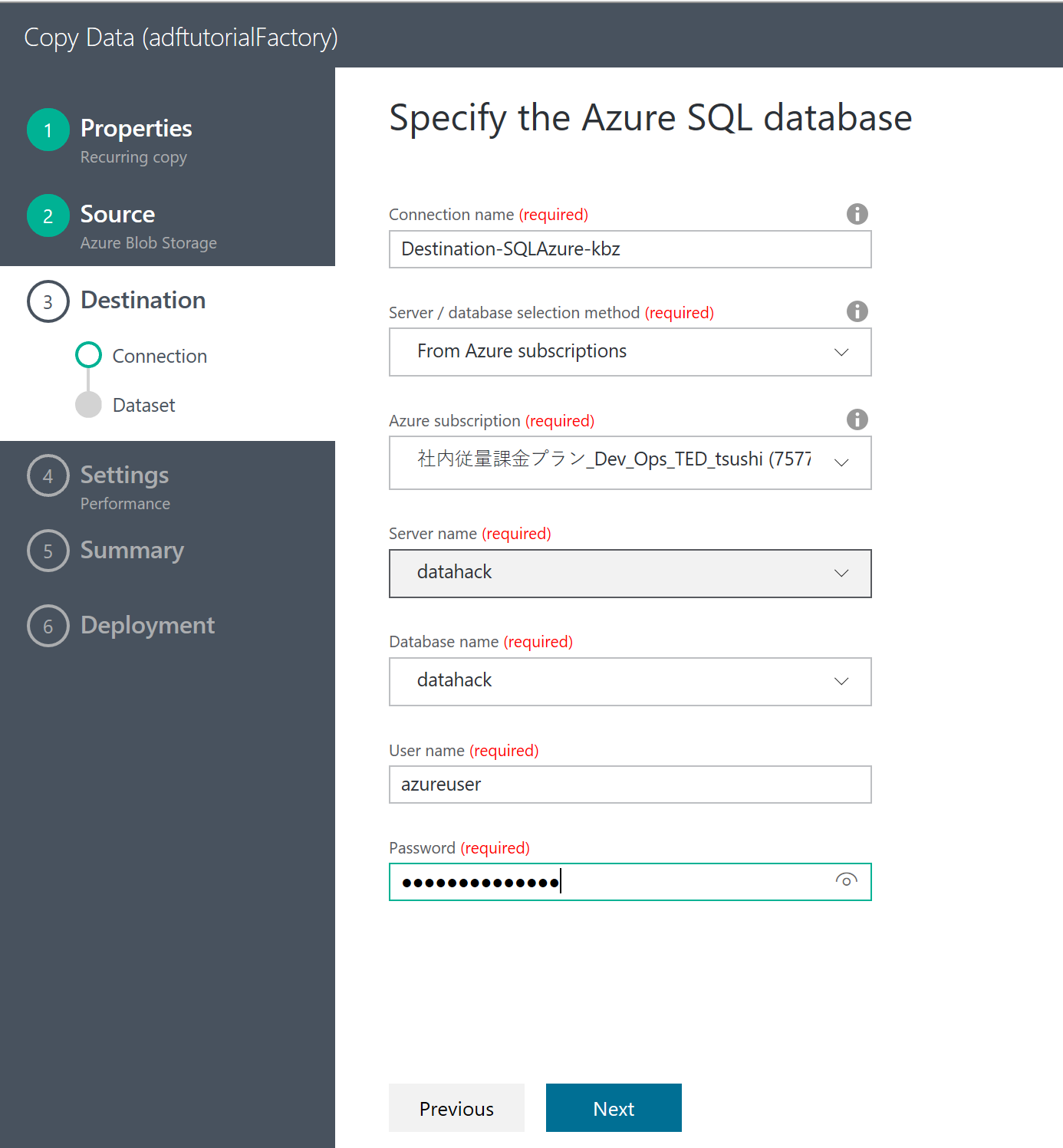
次に 出力先として、SQL Database の設定をする。
データベースの設定。ここは難しいところは何もない。
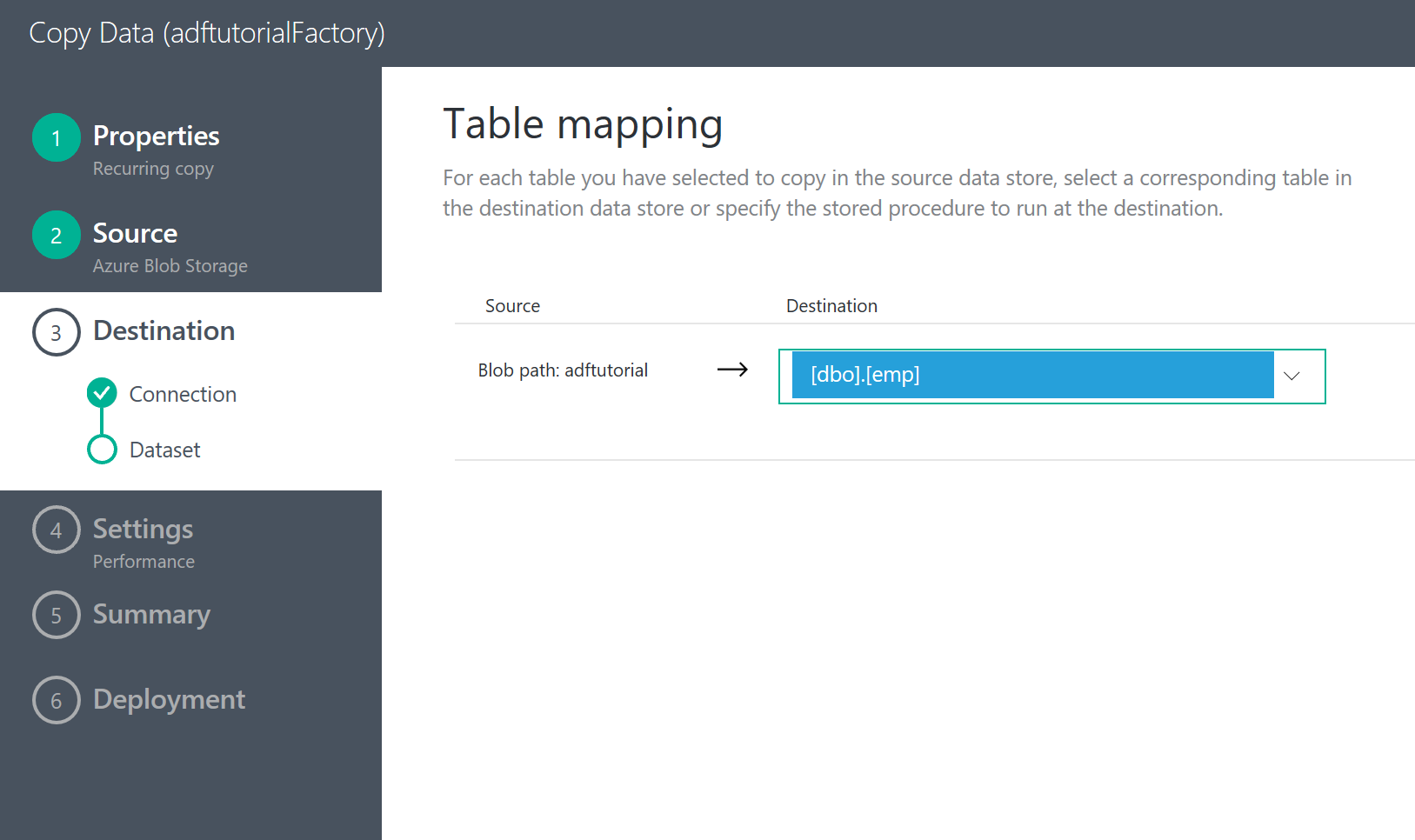
どこのテーブルに出力するかも選べる。簡単。
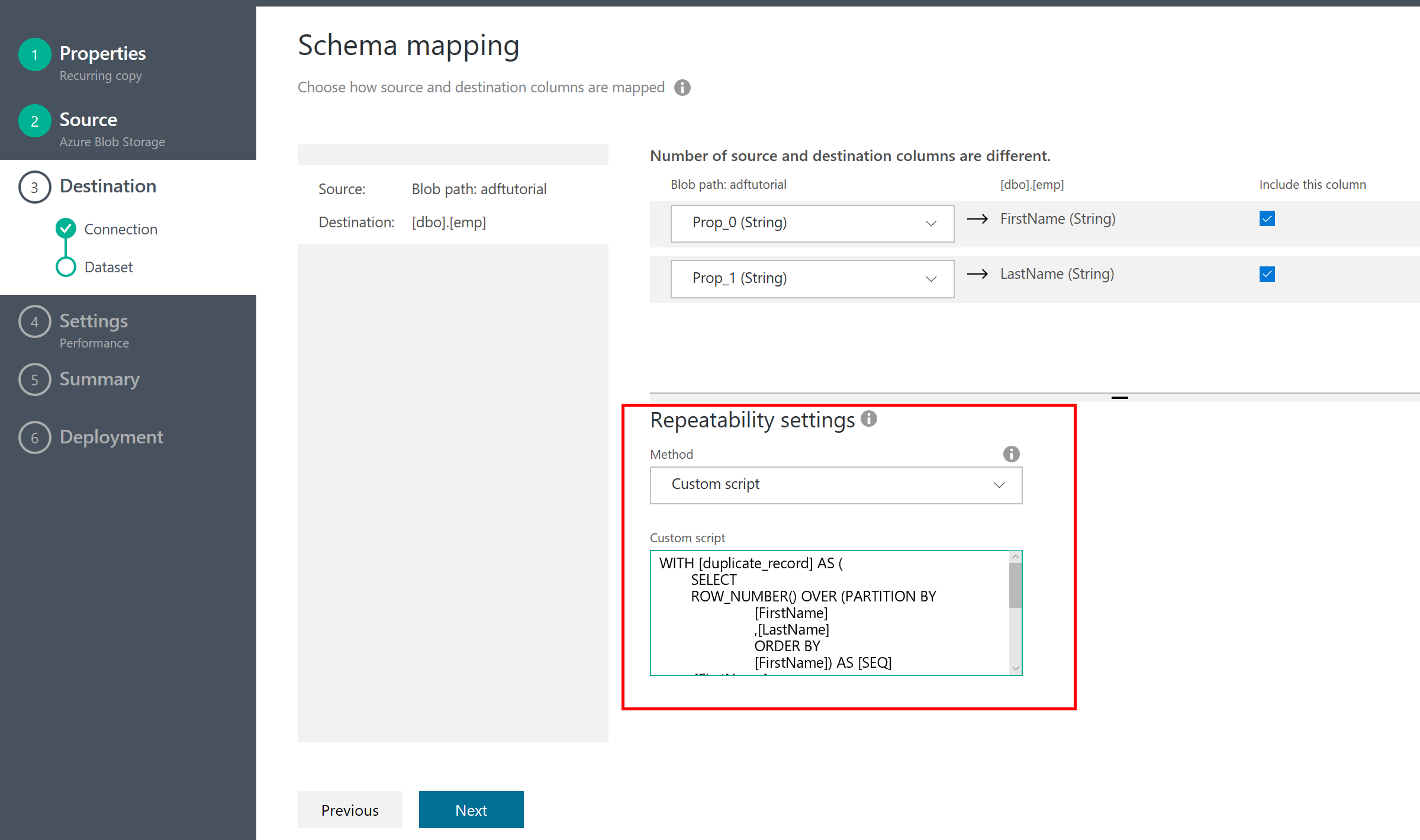
重複データを避ける
1 つだけ Tips がある。普通にこの Task を実行すると、何回もタスクが実行されるので、データが重複して記録される。これは避けたいだろう。そういうときは、Repeatability Setting を設定するとよい。ここに、SQL のカスタムスクリプトを記述する。
今回は、重複データを避けるために、重複データを削除するSQLを記述した。書き方は次のブログからもらいました。主キーのないテーブルから重複レコードを削除する。正直 SQL Database のSQLにはなじみがないので、勉強せねば。これはまた別の機会に。
WITH [duplicate_record] AS (
SELECT
ROW_NUMBER() OVER (PARTITION BY
[FirstName]
,[LastName]
ORDER BY
[FirstName]) AS [SEQ]
,[FirstName]
,[LastName]
FROM
[dbo].[emp]
)
DELETE FROM
[duplicate_record]
WHERE
[SEQ] > 1;
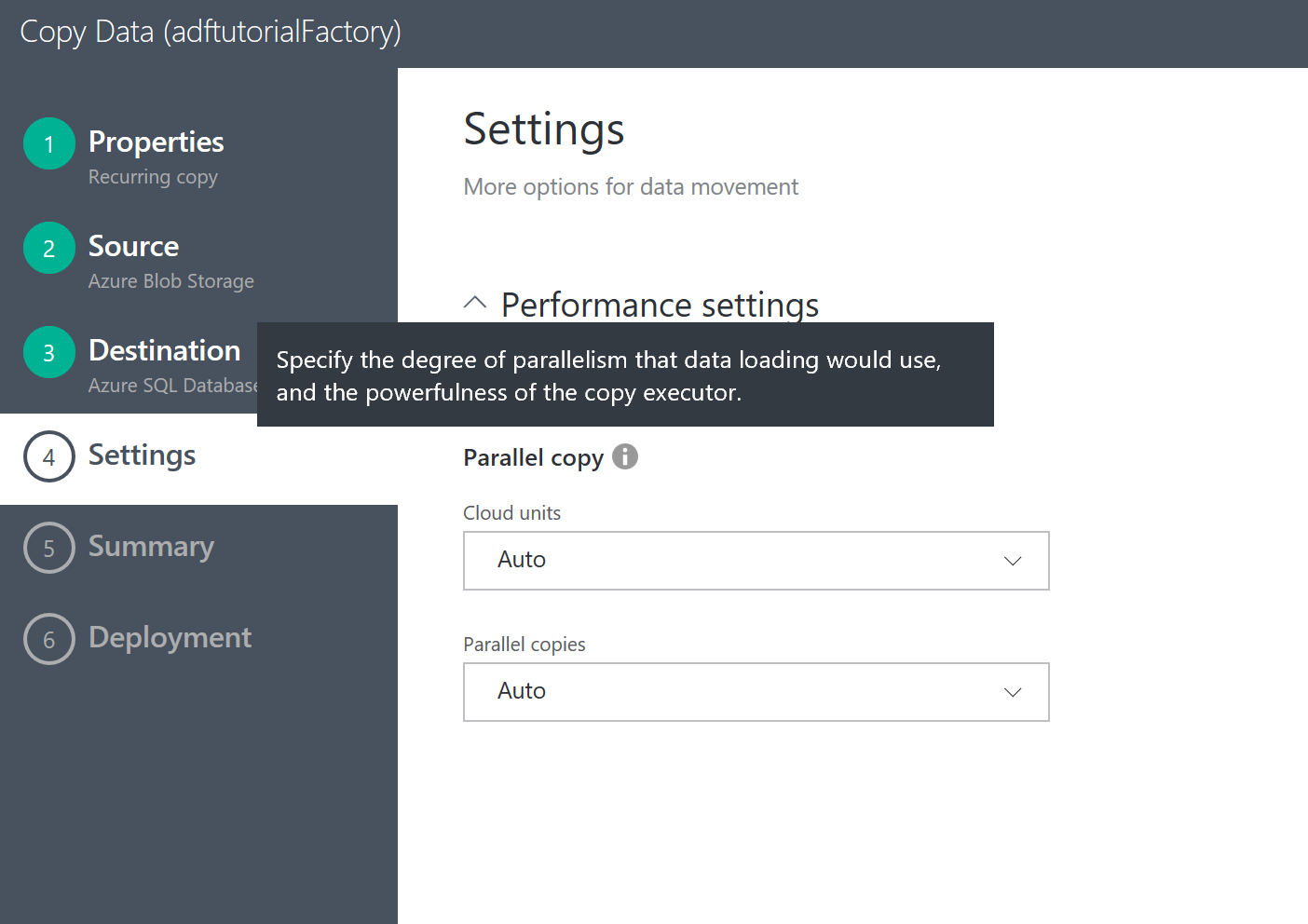
並行実行を指定して
実行すると確認画面がでて
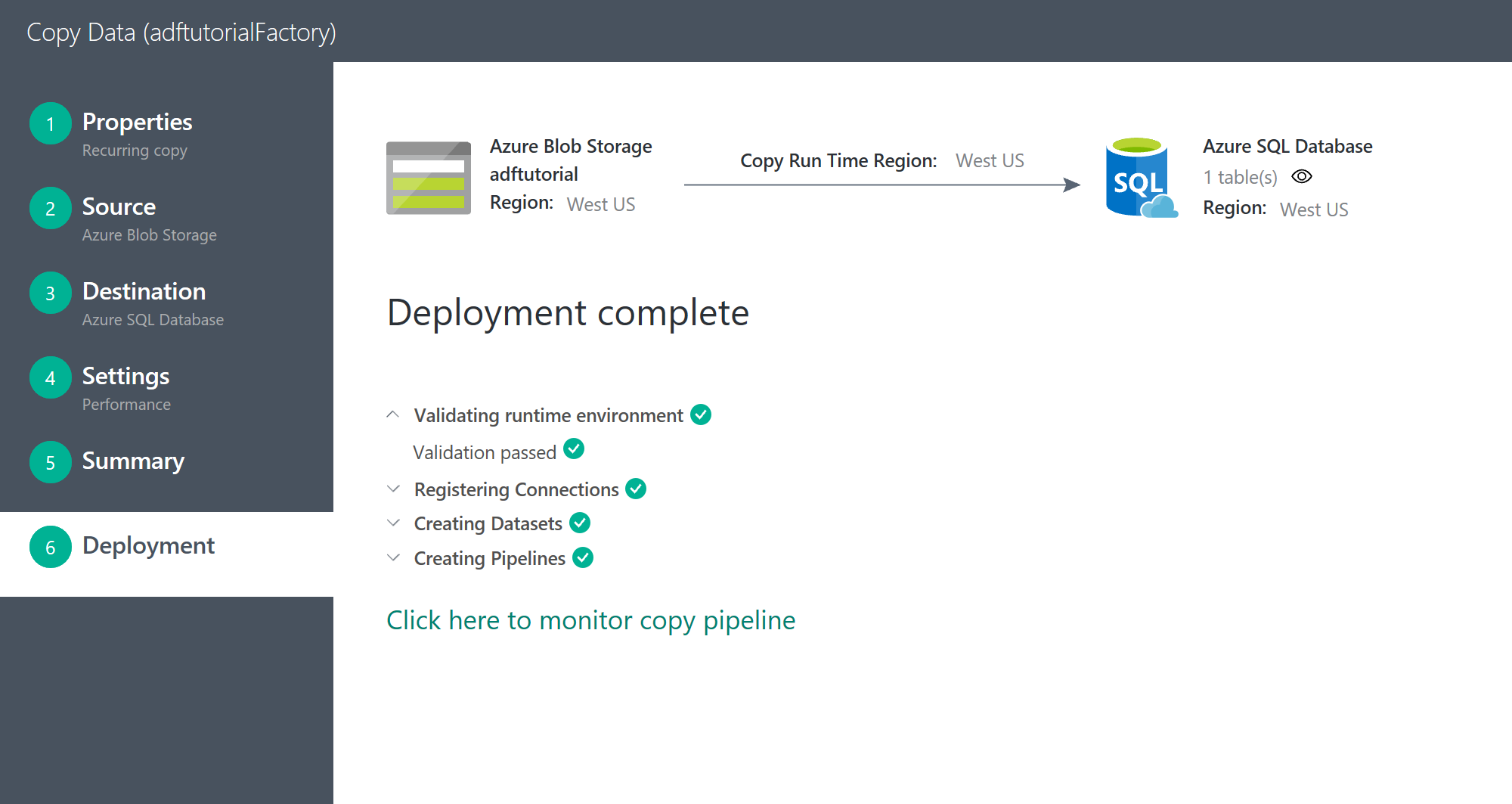
Task の実行
実行します!
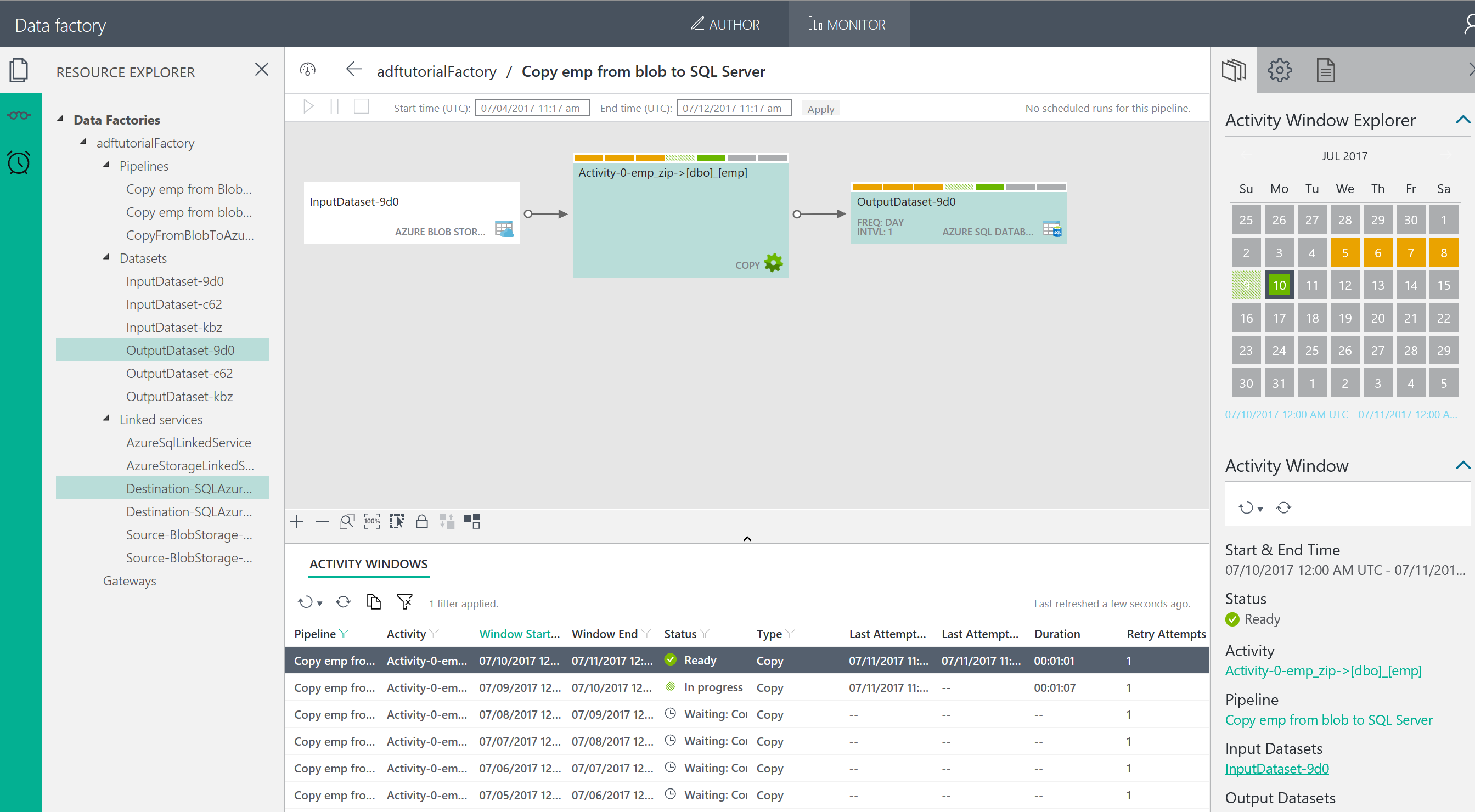
きれいに、重複データが取り除かれて、データが格納されました。
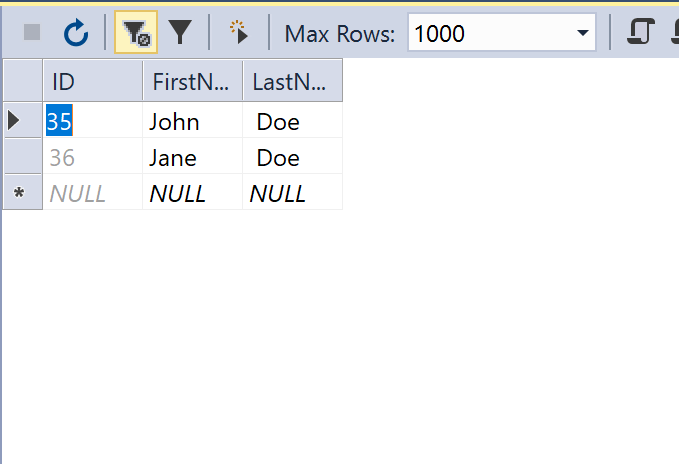
おわりに
一番簡単な手順をためしてみましたが、深堀すると面白そうなテクノロジーですね。普段格闘している Istioのような生まれたてのものと比べるとさくっと動くのでむっちゃ楽ですね!