たまたま、遊びでプログラミング問題を解いてみました。一応解けたのですが、実行速度やメモリ使用量がよろしくなかったので、ちゃんと理解しようと思ってみました。自分のための理解したことのメモです。
問題の内容
循環リストの検出です。循環リストを含むかどうか?というのはどうやって検出するかです。
最初の回答
最初に考えたのは、結局のところ、LinkedList の next に対して、終端(この問題では、null) が存在したら、それは、循環じゃないと判断できます。ただし、循環だった場合は、永遠にループしちゃうので、要素を調べて、すでに出てきたものだったら、循環と判断すれば良いです。要素を、List にぶち込んで、Contains で調べたらええやろと思ってこんな感じでコード書きました。
public class Solution {
private List<ListNode> list = new List<ListNode>();
public bool HasCycle(ListNode head) {
if (head == null) {
return false;
}
if (head.next == null) {
return false;
}
if(list.Contains(head)) {
return true;
}
list.Add(head);
return HasCycle(head.next);
}
}
うーん。香ばしい。でも、一応動く。ただ、結果は当然のことながらよくなく。遅いし、メモリは使っとるし散々です。ソリューションの欄をみて、模範解答を勉強してみます。
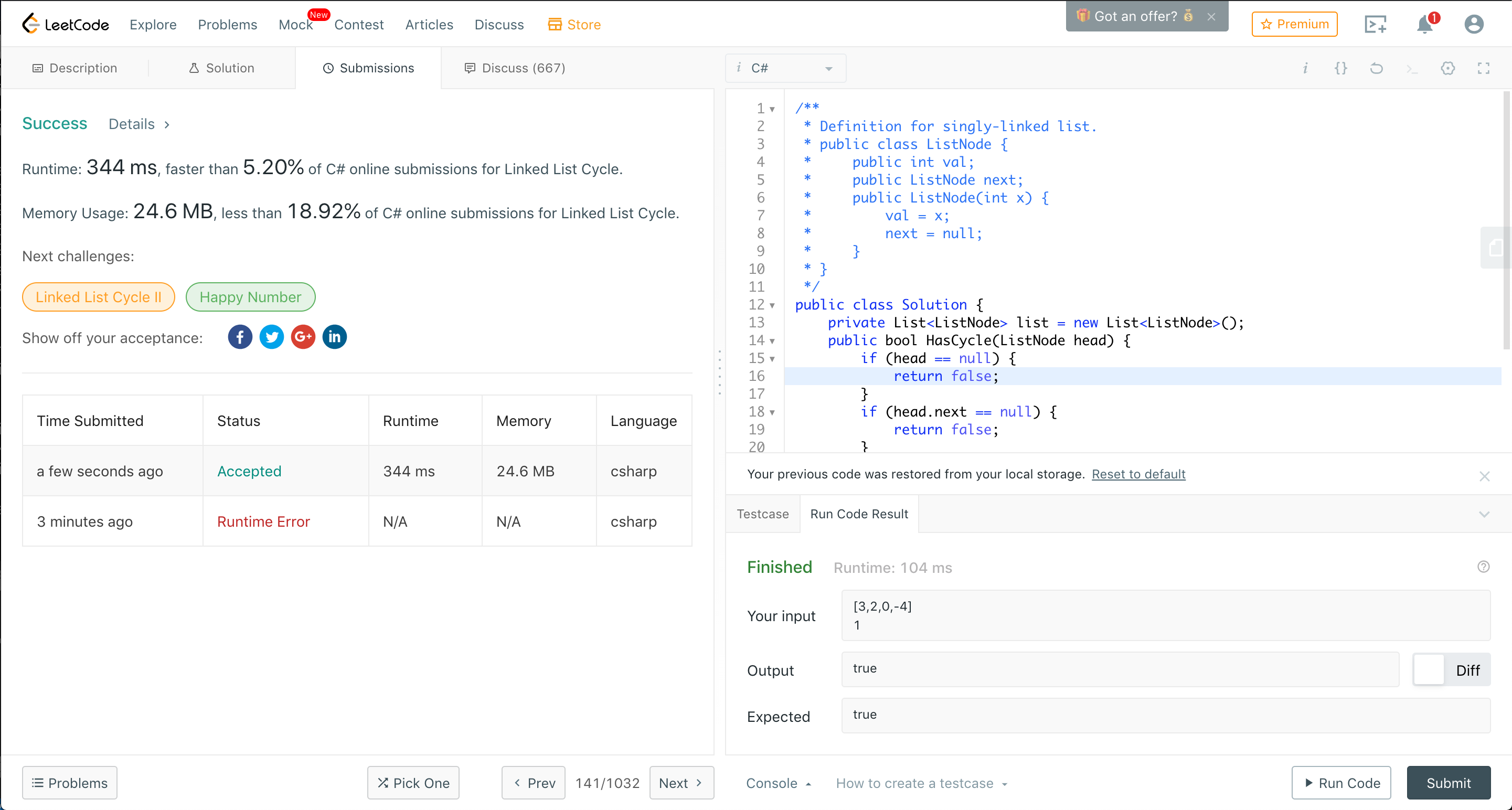
模範解答1(HashSet)
模範解答その1は、考え方は私と全く同じですが、再帰を使っていないのと、Listではなく、HashTableを使ってることです。そらそっちの方が効率がいいですね。O(1) のオーダーで検索してくれるので早いに決まってます。再帰は、やっぱちょい遅いのかなぁ。影響あるのかなと思いつつ、まずは、Hashに。速さはアップですね。まぁいい感じ。でもやっぱメモリがいまいち。そら、ライブラリのHashSet使ってるからそらそうか。じゃあ、再帰はどうなるんだろう。
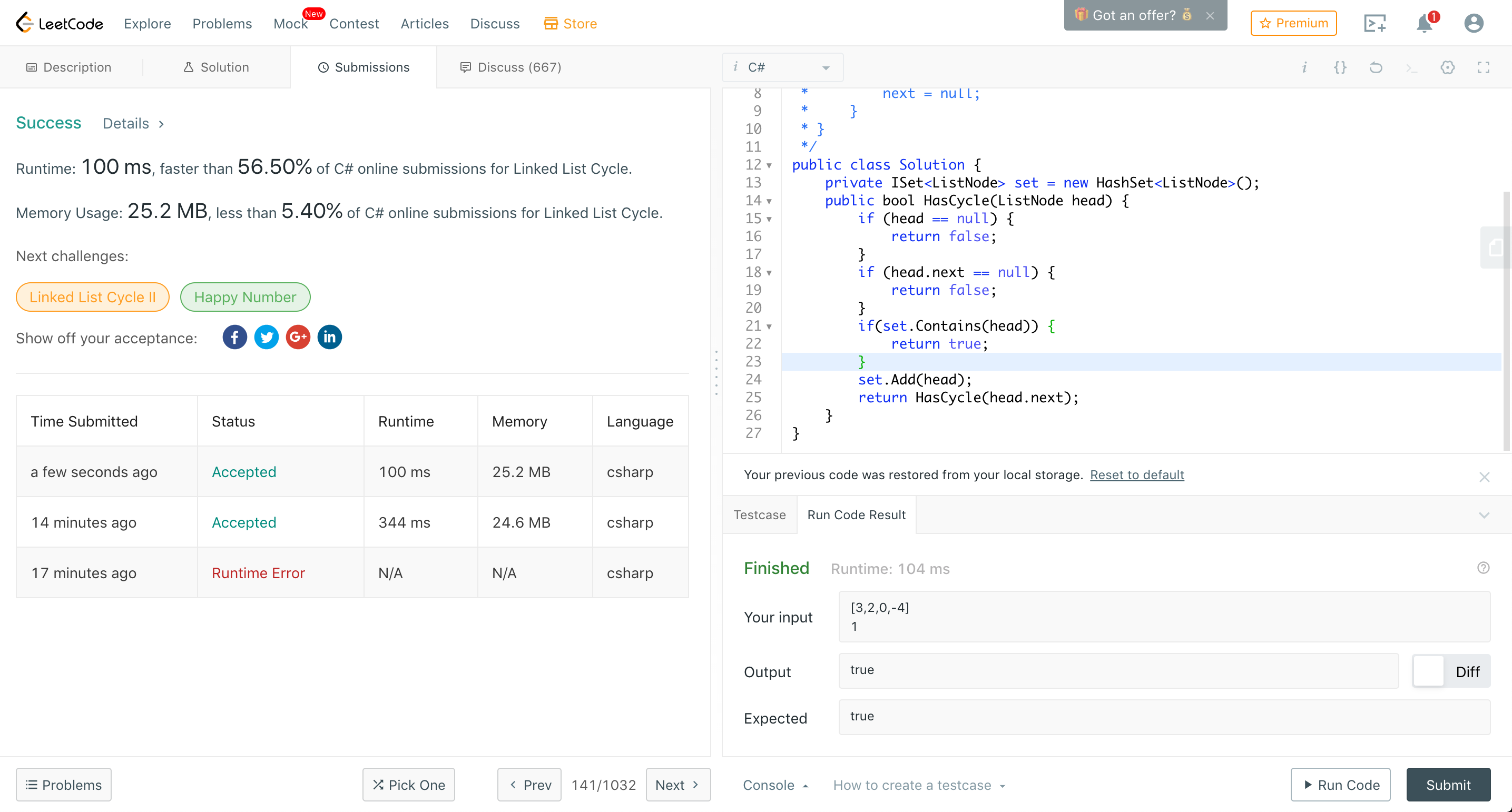
模範解答1(再帰をやめる)
public class Solution {
private ISet<ListNode> set = new HashSet<ListNode>();
public bool HasCycle(ListNode head) {
while(head != null) {
if (head == null || head.next == null) {
return false;
}
if (set.Contains(head)) return true;
set.Add(head);
head = head.next;
}
return false;
}
}
結果を見ると、速度的には変わらず、メモリ使用量が若干ましのようです。ループと再帰を比べると、スタックに積まれることを考えると、当然の結果もします。ただ、そこまで大きな影響があるわけじゃない様子です。

模範解答2
模範解答その2は、有名なアルゴリズムらしく、ListNode のオブジェクトを2つ作って、最初のものは、Fast と呼んで、速度の係数2に、2つめは、速度の係数を1にすると、最大 循環したループの長さで、2つのポインタが出会うというアルゴリズムです。
何故こうなるか?というと、循環のリストは次のようなものです。
1-> 2 -> 3 -> 4 -> 2
この場合、2 -> 3 -> 4 -> 2 -> 3.... といった具合に循環します。循環のループの要素数は3でそれが繰り返されます。さて、1つの要素の速度を2、2つめを1にするとどういうことが起こるか?というと、最初の1をのぞいて、2つめの要素(遅い方)がループに入った時点で、早い方は、すでにループに入っています。その時点で、速いのと遅いのの間にどれぐらい距離があるかわかりません。(ループの長さや、ループに入るまでの距離によります。そのループに入った時点での、遅いのと、速いのの距離がNとすると、1回ロジックが繰り返されるたびに、距離が開いていきます。N,N+1,N+2といった具合です。ただ循環ということは、円になっていますので、循環のループの数をMとすると、N+i がMになった時点で、遅いのと速いのが出会うというわけです。
よくわからないと思うのでコードをみてみましょう。
public class Solution {
public bool HasCycle(ListNode head) {
if (head == null || head.next == null) {
return false;
}
ListNode slow = head;
ListNode fast = head.next;
while(slow != fast) {
if (fast == null || fast.next == null) {
return false;
}
slow = slow.next;
fast = fast.next.next;
}
return true;
}
}
なんだこれは、凄い効率とスピードじゃないか、、、ライブラリは多くのコードを含むので、メモリはそうだろうなと思ったけど、速度もクソ速い。O(N)のオーダーなのは、前のアルゴリズムと変わらないけど、メモリは、O(1) のオーダーになったはず。同じO(N) のオーダーなのに速い理由はなんだろう。最短で、List size で終了するはずで、ループでも、ポジションP+ 循環要素数で終わるはず。
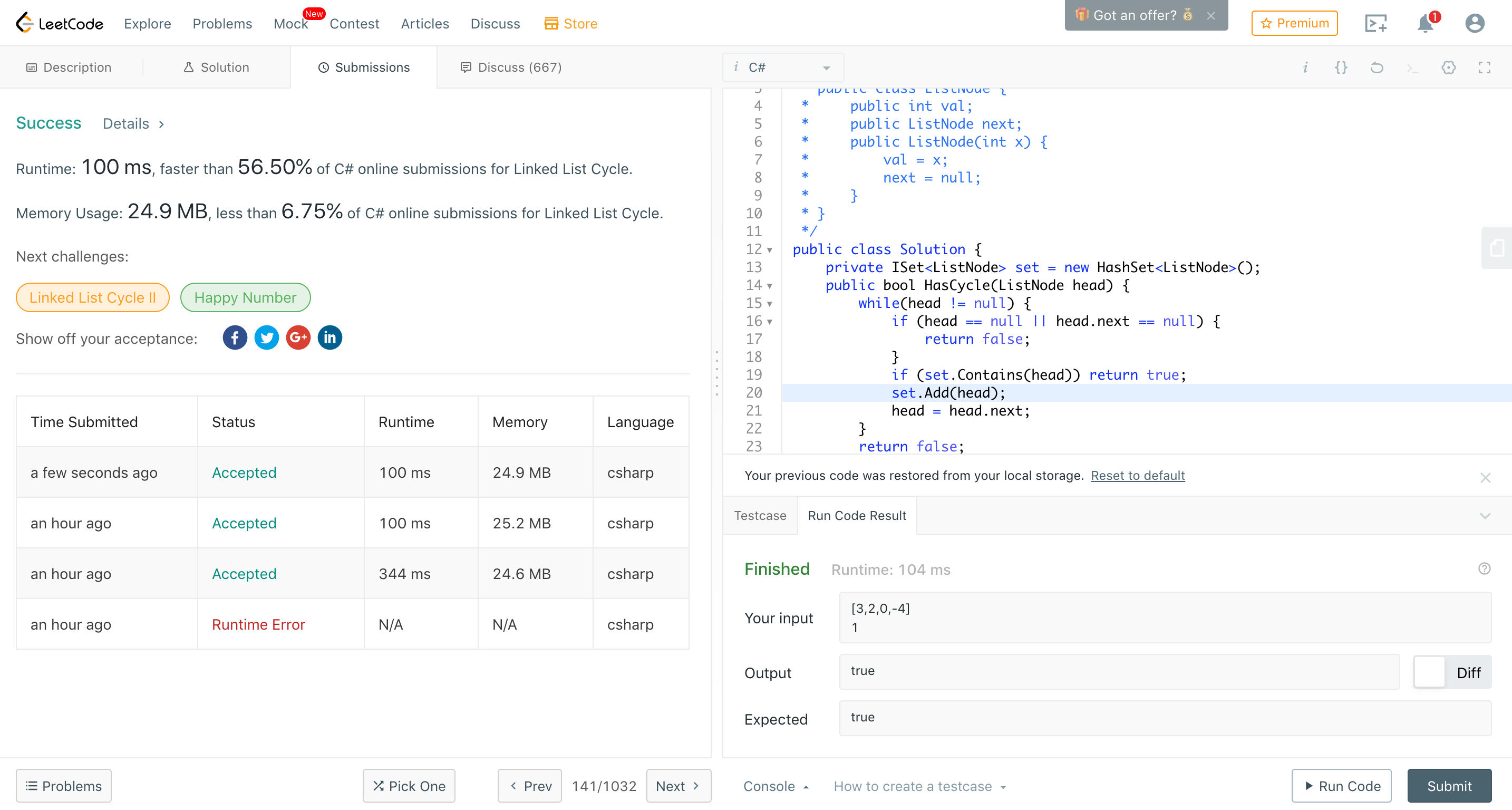
ちなみに、このアルゴリズムは最初なかなか理解でき戦でしたが、このページで理解できました。
まとめ
アルゴリズムのイディオムすげぇ。こんなの絶対思いつかないから勉強するしかないなぁ。でも理解できて気持ちが良いです。