はじめに
構造化データを扱うのにpandasのDataFrameが良い!と風の噂で聞きました(本当は書店で立ち読みしたデータサイエンスの本で読みました).
超初心者の覚書としてメモを残しておきたいと思います.
環境
Python3.6.10
pandas-1.0.1
Jupyter notebook
まずはインストール
難しいことは何もなかった...
pip install pandas
csvファイルの読み込み
今回扱いたいデータがcsv形式だったので,csvファイルを読み込んでいきます.
少々調べたところ,pandasにはSeries,DataFrameという二つのデータ構造があり,Seriesが一次元データ,DataFrameが二次元データに対応するらしいということがわかりました(SeriesとDataFrameについては理解が甘々なので勉強し直して別の記事にできたらいいな)
とりあえず今回は,csvデータをDataFrameとして読んでいきたいと思います.
import pandas as pd
pd.read_csv('データパス',header = None)
区切り文字がカンマのcsvファイルを読みたかったので,read_csv()を使いました.
区切り文字がタブ(\t)の場合はread_table()を代わりに使用できるそうです.
また,読みたいcsvファイルには見出し行が存在しないので,headerにNoneを指定しています.
実際に読み込んだデータは,jupyter上では下図のように表示されました↓
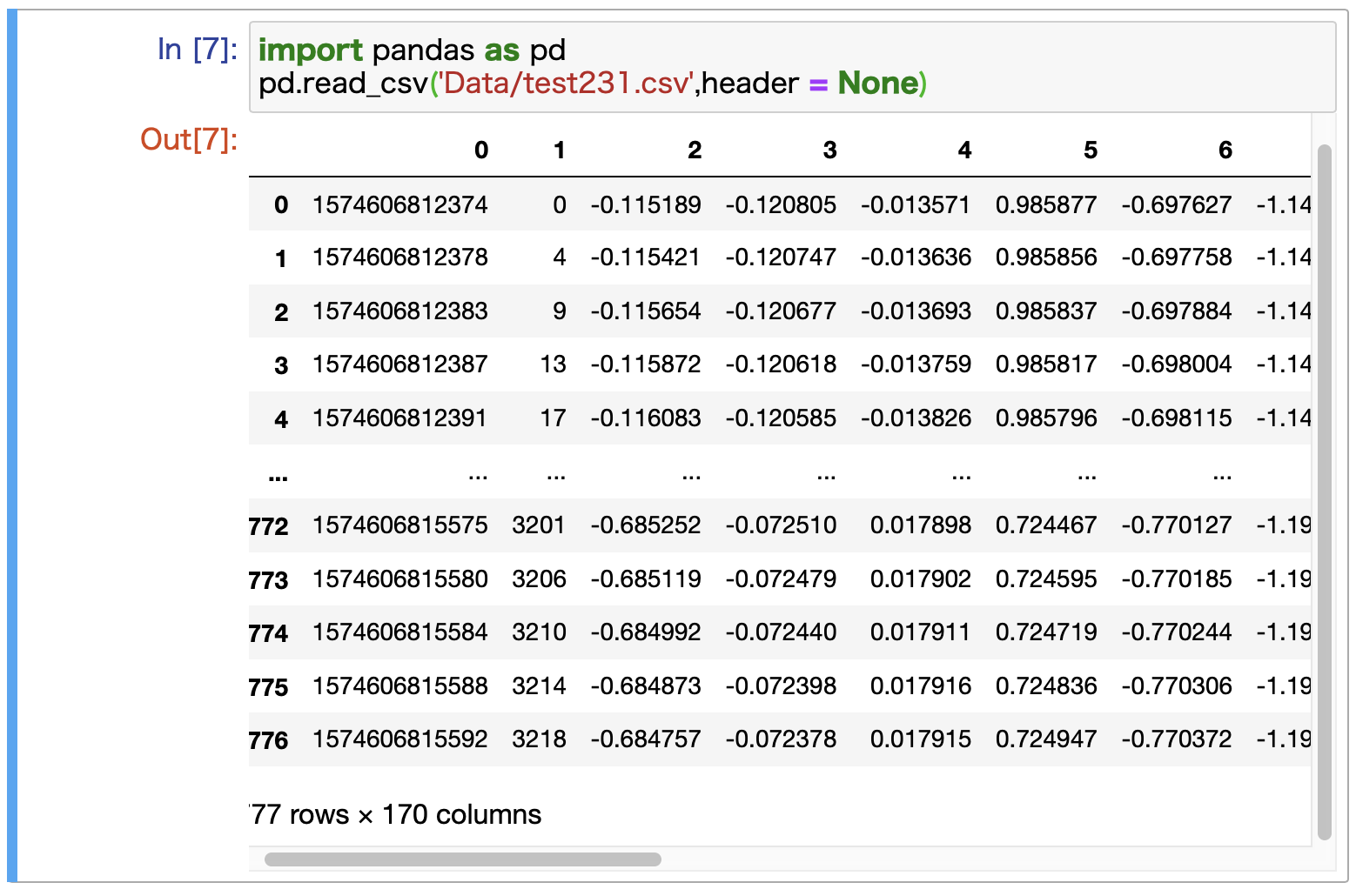
データの整形
読み込んだデータを次のように整形していきます
・0列目は不要なので削除
・1列目をインデクス(見出し列)にする
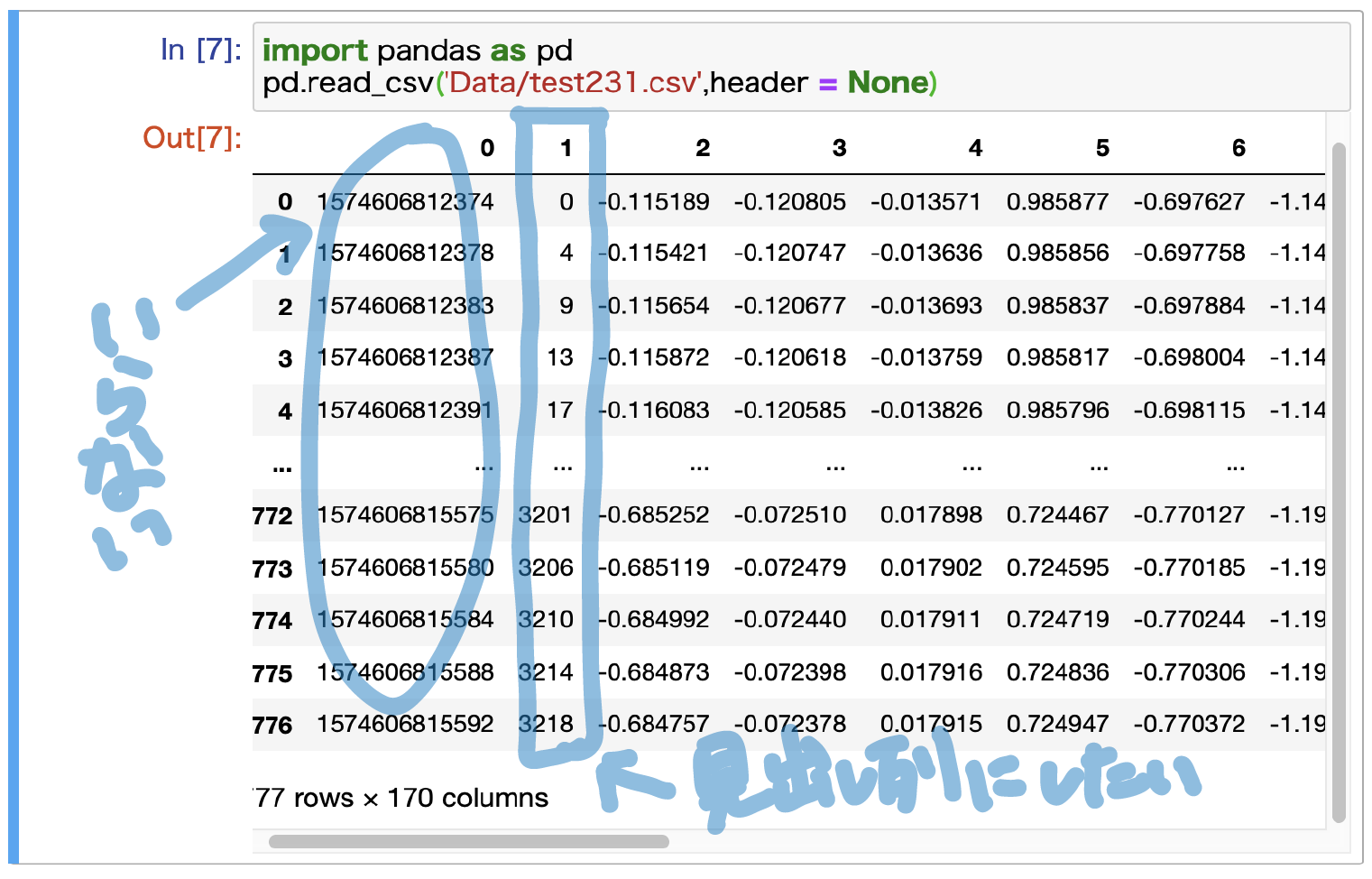
列の削除
スライスで0列目だけ切り落としていきます.
SeriesやDataFrameではインデクスに文字列を指定することもできますし,(任意の)数値を指定することもできます.特に,インデクスに数値を指定した際の混乱を避けるため,ilocやlocといったインデクス属性を用いてデータにアクセスします.
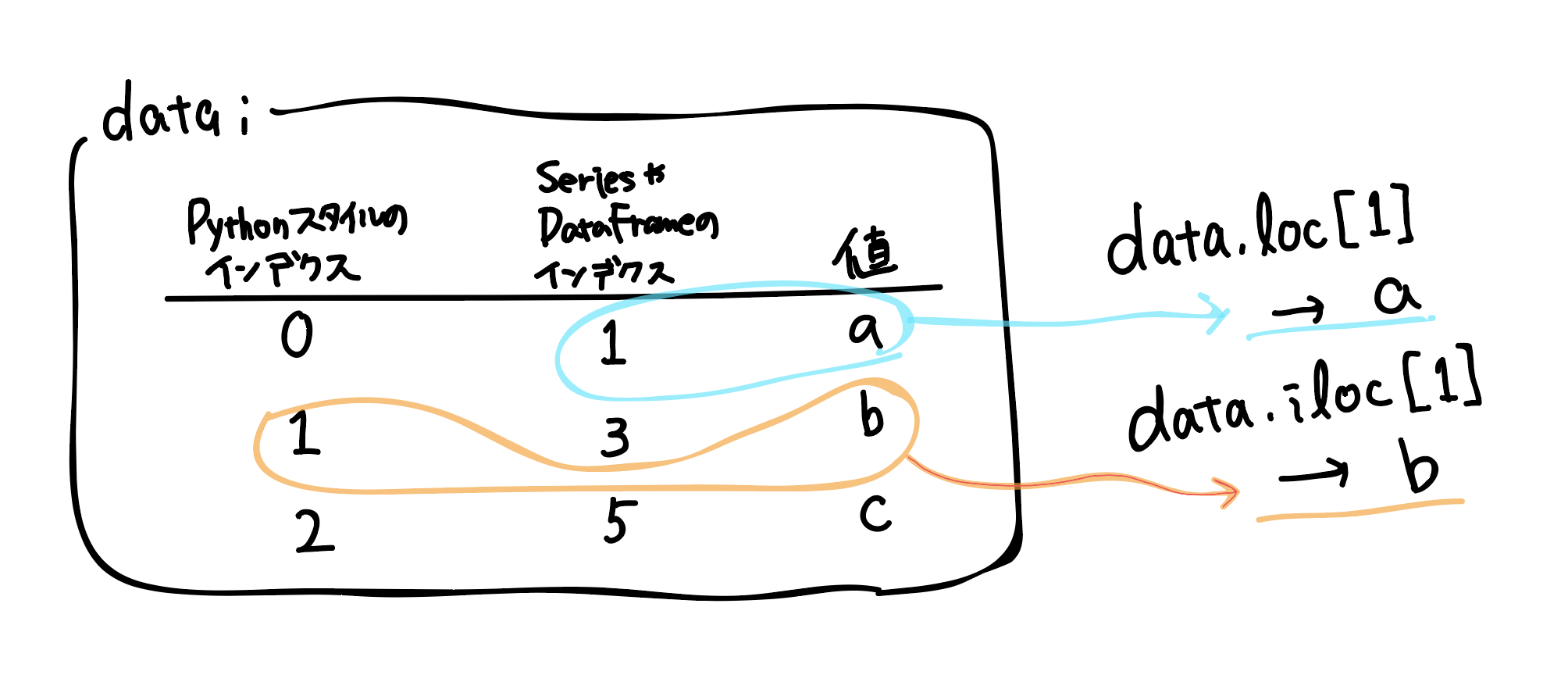
今回は(今のところ),DataFrameのインデクスは行・列の両方とも,Pythonスタイルのインデクスと一致しているので,ilocとlocのどちらを用いても同じ結果が得られます.次のようにしてデータの0行目を切り落としました(1行目以降のみ取り出しました)
# csvを読み込む
df = pd.read_csv('Data/test231.csv',header = None)
# スライスする
df.iloc[:,1:]
実際の出力↓
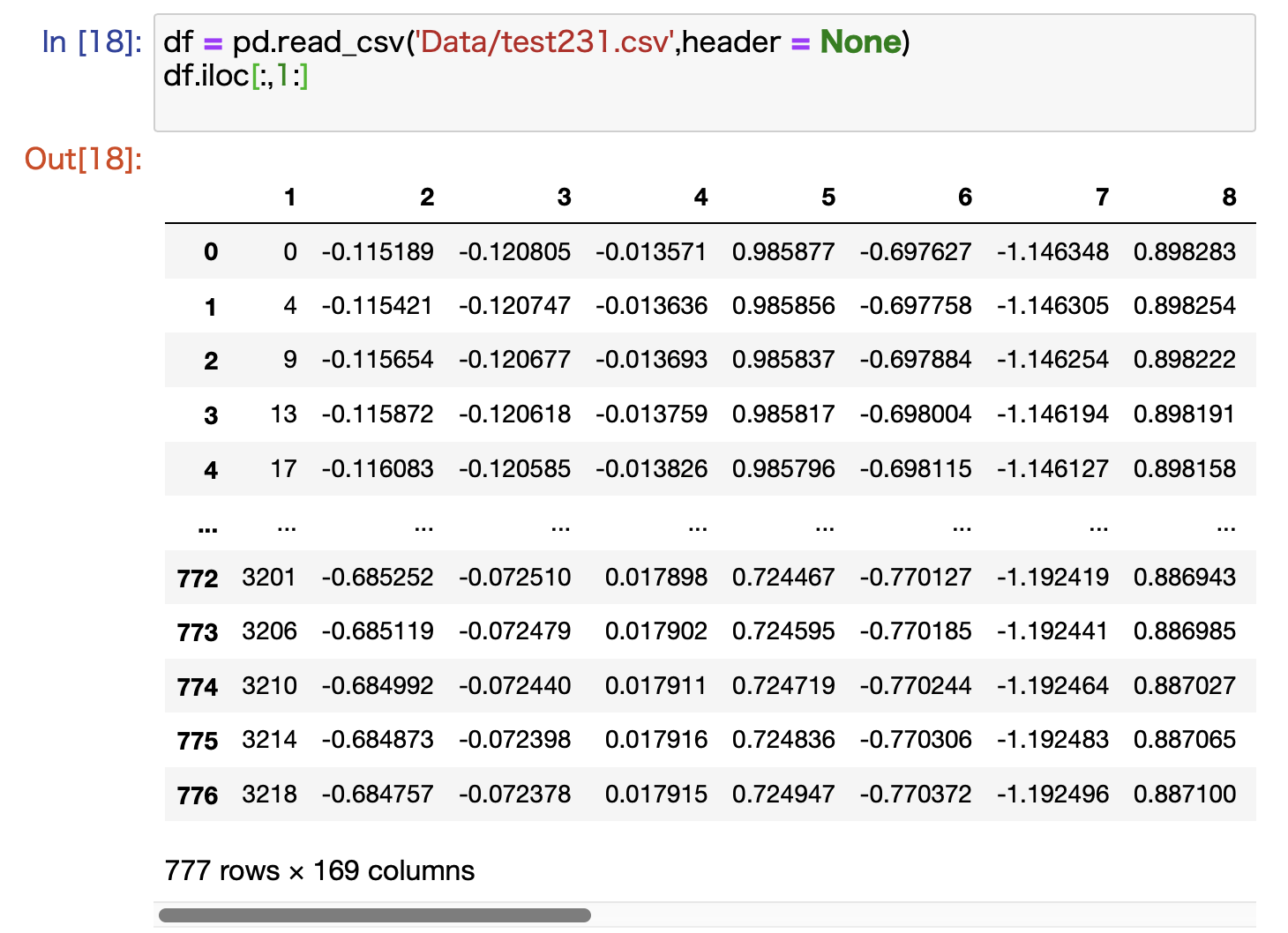
前の画像と見比べて列(columns)数が170から169になっていて,先頭一列のみが減っていると確認できました.
1列目をインデクスにする
pandasのDataFrameでは,行見出しのことをindex,列見出しのことをcolumnsと呼んでいるらしい.
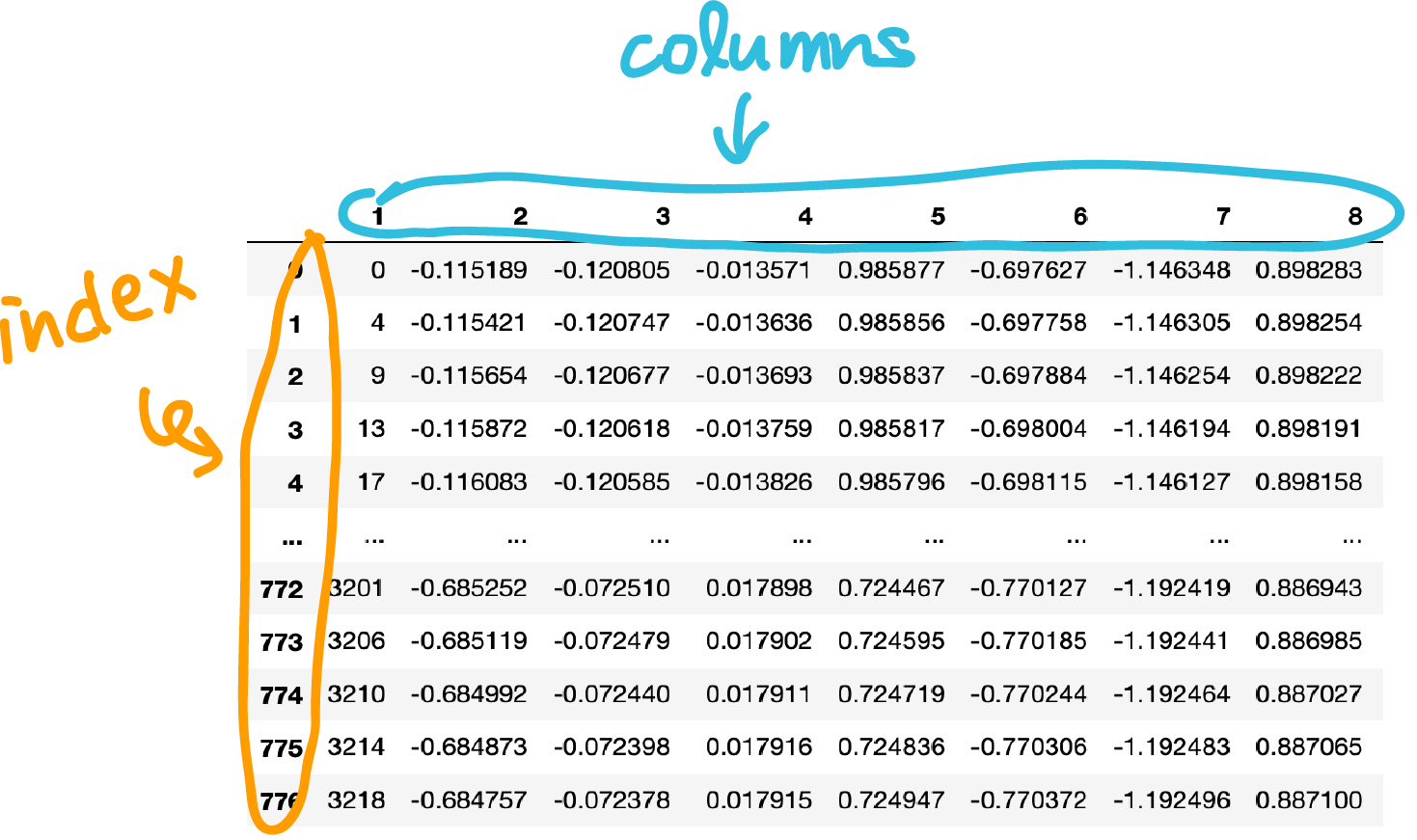
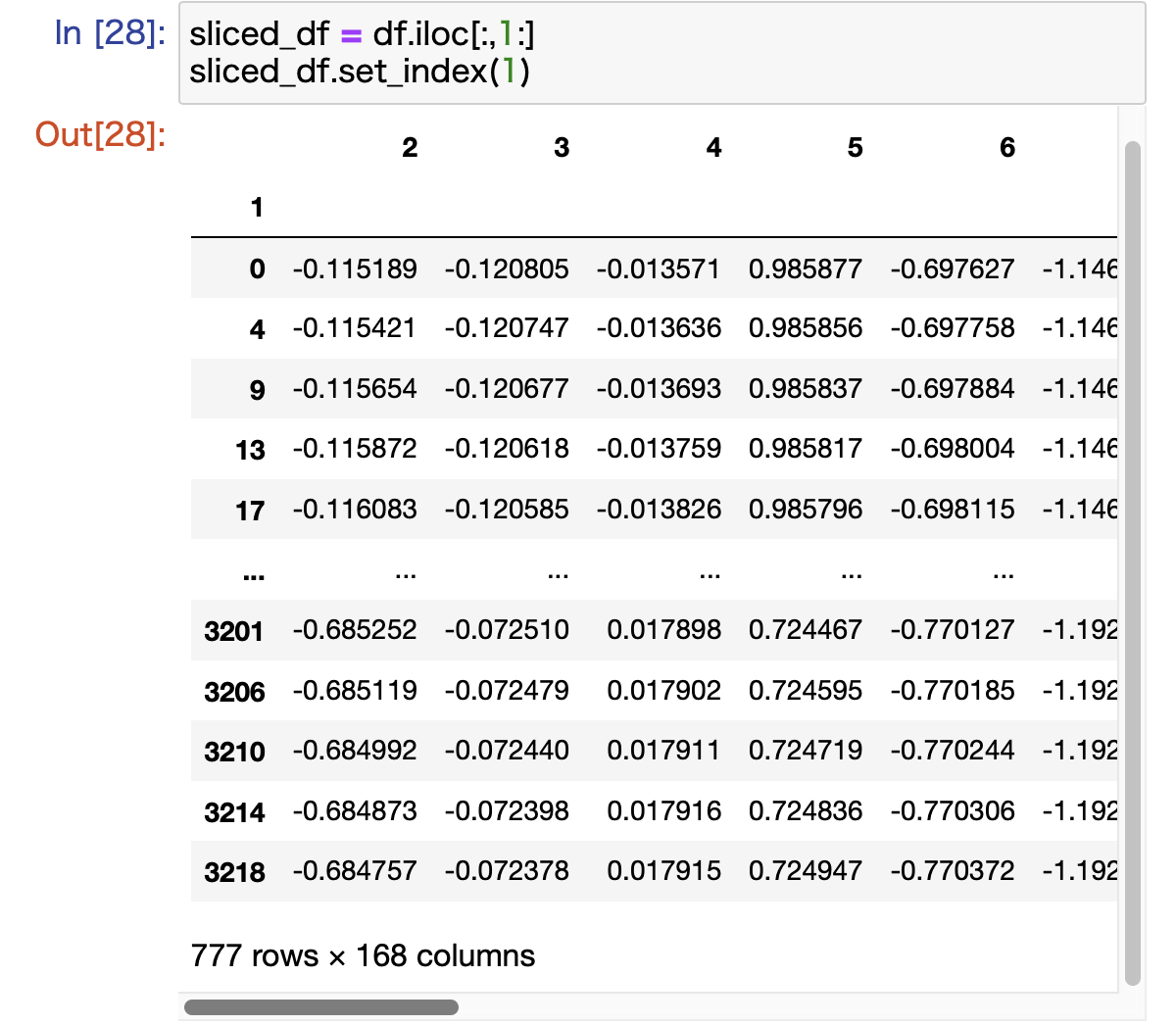
次のようにすることで,上の図で"1"という名前のついているcolumnをindexに指定することができました.
# スライスする
sliced_df = df.iloc[:,1:]
# 名前が"1"のcolumnをindexに指定する
sliced_df.set_index(1)
下のように実行できました
おわりに
次はcolumnnの名前を変えたり,このテーブルを階層データとして処理していく記録を覚書として記事にしたいと考えています.