1.はじめに
こんにちは、株式会社ジールの田崎です。AWS GlueのJOBを利用する際によくあるエラーとその対処方法についてまとめました。
Glue JOBでよく発生するエラーをインフラの観点から図で解説していきたいと思います。
今後、エラーが起きた際のトラブルシューティングに役立てて頂ければ幸いです。
2.Glueの基本的な構成
AWS GlueはAWSが提供しているETL基盤です。サーバレスで実行できるため、インフラ面を意識せずともすぐにETLパイプラインを構築することが出来ます。
データ分析基盤を構築する際の基本的な構成図及び通信の方法は下記でございます。
①スケジュール/手動実行等で、Glue JOBを実行する。
②Glueコンソールにて作成した接続定義に記載のサブネット内にて、Glue JOBが起動する。
(実態はENIという、サブネット内の空いているIPアドレスが割り振られた部品が起動する)
③サブネット内から各データソース/ターゲットに対して通信が行われる。

インフラの観点から見た場合、③にてエラーが発生する場合が多いので、2章ではそちらについて解説させて頂きます。
3.よくあるエラーについて
本章では、インフラの観点からGlueで発生しがちなエラーについて説明致します。
1.接続時にエラーが出てしまう、起動するがS3にデータが作成されない等
接続時のエラーについては、主に3つの原因が考えられます。
①Glue JOBから対象リソースへの経路(ルート)が無い
②Glue JOBに設定しているIAMロールに、リソースへのアクセス許可が含まれていない
③セキュリティグループにて、対象リソースへのアクセスが許可されていない
詳しく見ていきましょう。
①Glue JOBから対象リソースへの経路が無い
S3への接続時に起こりがちなエラーです。
S3はサブネットの外にあるリソースのため、
サブネット内で起動したGlue JOBからS3への経路が無い場合はエラーが返されます。
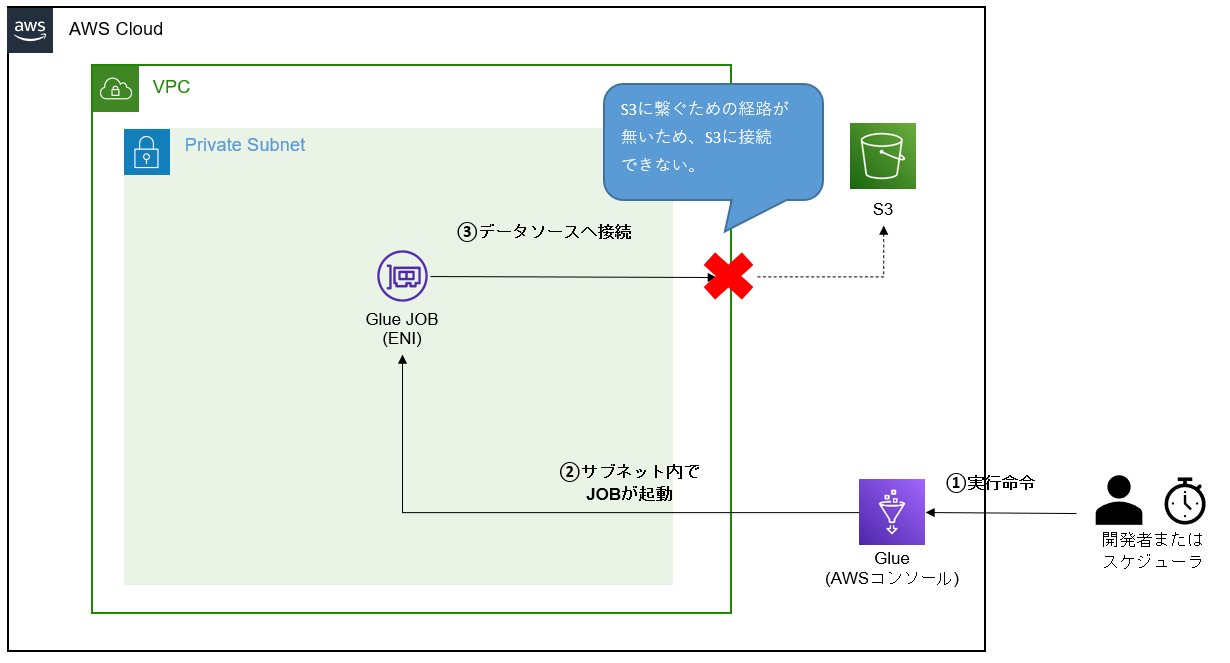
S3と通信を行うためには、ゲートウェイ型VPCエンドポイントを経由させる必要があります。
※NATゲートウェイ&インターネットゲートウェイを経由してのアクセスも可能ですが、
ここでは割愛させて頂きます。

その上で、Glue JOBが起動しているサブネットのルーティングテーブルに
ゲートウェイ型VPCエンドポイントへの経路があるかを確認しましょう。
(通常は、ゲートウェイ型VPCエンドポイントを作成した時点で自動で経路が追加されます。)
図の通り、ゲートウェイ型VPCエンドポイントはVPCと紐づくものであるため、
まずは使用しているVPCにS3のゲートウェイ型VPCエンドポイントがアタッチされているかを確認しましょう。
また、RedshiftやRDS等のインスタンスへの接続を行う場合も、
ルートテーブルの確認を行い経路があるかを確認しましょう。
②Glue JOBに設定しているIAMロールにリソースへのアクセス許可が含まれていない
リソースへの接続は出来ても、Glue JOBに設定するIAMロールにS3バケットへのアクセスが
許可されていなければエラーが出てしまったり、
実行が出来てもデータが作成されない等の事象が起きてしまいます。
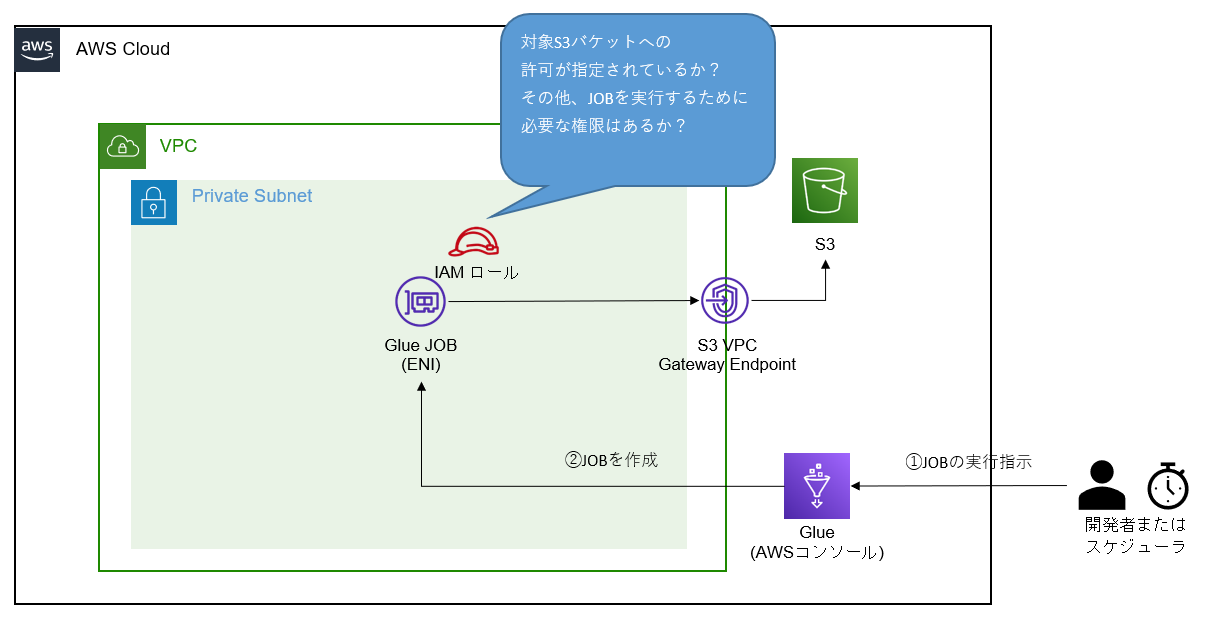
では、どのようなIAMポリシーが必要なのでしょうか?
基本的には、AWSマネージドポリシーである「AWSGlueServiceRole」を利用することで
Glue JOBを実行することが出来ます。
AWSGlueServiceRoleでは、Glue JOBを稼働させる際に必要とされる権限がデフォルトで入っています。
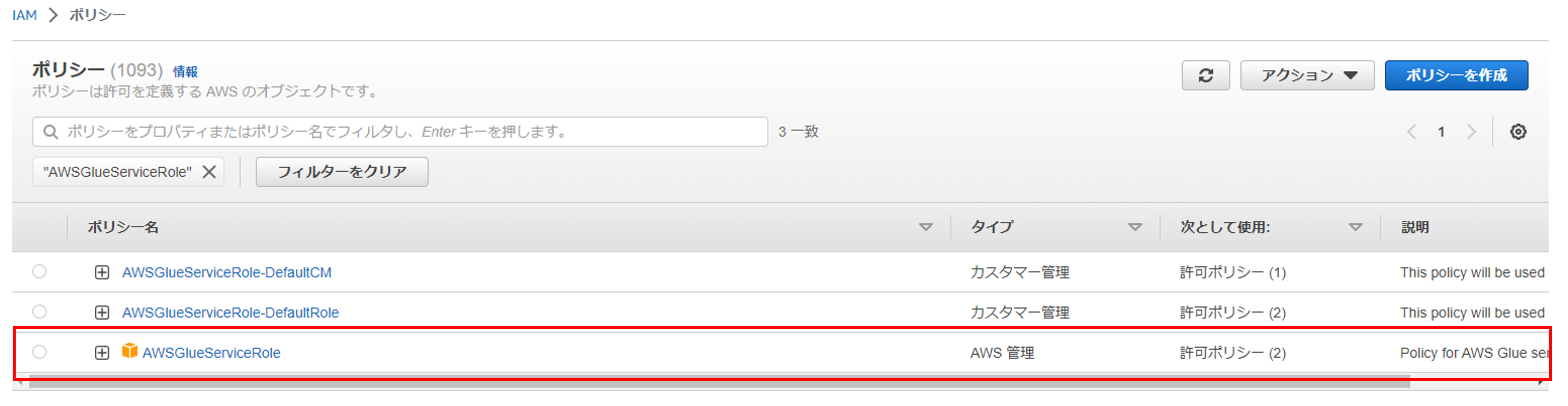
中身はこんな感じです。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"glue:*",
"s3:GetBucketLocation",
"s3:ListBucket",
"s3:ListAllMyBuckets",
"s3:GetBucketAcl",
"ec2:DescribeVpcEndpoints",
"ec2:DescribeRouteTables",
"ec2:CreateNetworkInterface",
"ec2:DeleteNetworkInterface",
"ec2:DescribeNetworkInterfaces",
"ec2:DescribeSecurityGroups",
"ec2:DescribeSubnets",
"ec2:DescribeVpcAttribute",
"iam:ListRolePolicies",
"iam:GetRole",
"iam:GetRolePolicy",
"cloudwatch:PutMetricData"
],
"Resource": [
"*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:CreateBucket"
],
"Resource": [
"arn:aws:s3:::aws-glue-*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::aws-glue-*/*",
"arn:aws:s3:::*/*aws-glue-*/*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::crawler-public*",
"arn:aws:s3:::aws-glue-*"
]
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:*:*:/aws-glue/*"
]
},
{
"Effect": "Allow",
"Action": [
"ec2:CreateTags",
"ec2:DeleteTags"
],
"Condition": {
"ForAllValues:StringEquals": {
"aws:TagKeys": [
"aws-glue-service-resource"
]
}
},
"Resource": [
"arn:aws:ec2:*:*:network-interface/*",
"arn:aws:ec2:*:*:security-group/*",
"arn:aws:ec2:*:*:instance/*"
]
}
]
}
しかし、このデフォルト権限では、S3に対してのアクションを"Resource"句にて
S3のバケットを"aws-glue-*"等で絞り込んでしまっているため、
独自でバケットを作成している場合はそのバケットのオブジェクトに対しての
読み込み・書き込みを行うことは出来ません。
(JOBが実行出来てもデータが作られない等の問題が発生する。)
この場合、「AWSGlueServiceRole」のJSONの内容をコピーし、
S3バケットの部分のみを自分が作成したバケット名に置換したIAMポリシーを新規作成し、
Glue JOB実行用のIAMロールに含めることで解決することが出来ます。
変更前
"Resource": [
"arn:aws:s3:::aws-glue-*/*",
"arn:aws:s3:::*/*aws-glue-*/*"
]
変更後
"Resource": [
"arn:aws:s3:::<自分のバケット名>/*",
"arn:aws:s3:::*/*aws-glue-*/*"
]
S3へのアクセスが拒否される、S3のファイルが読み込めない、作成されない場合は、
こちらの設定を見直してみましょう。
③セキュリティグループにて、対象リソースへのアクセスが許可されていない
RedshiftやRDS等サブネット内で起動するインスタンスにはセキュリティグループというものが設定されています。
(インスタンス単位で付与するファイアウォールのようなもの。S3には付かない。)
そのセキュリティグループに、Glueからのアクセス許可が付与されていない場合は通信を行うことが出来ません。

Glueと接続先のDB(Redshift,RDS等)との通信を行う際、
Glue JOBと接続先DBに対して以下のようにセキュリティグループを設定する必要があります。

インバウンドルールでは、GlueからRedshiftへの任意のTCPポート0-65535の範囲内で
通信を受け付けることを許可します。
ただし、ソースを自身のセキュリティグループ"SG_Example"に絞り込むことで、
あくまで"SG_Example"と紐づいているものとしか通信させないようにしています。
この設定を行うことで、Redshiftからしてみれば、Glue JOBは、TCPポート0-65535を使用し、
かつ"SG_Example"が付与されているため、インバウンド通信は問題無く許可されます。
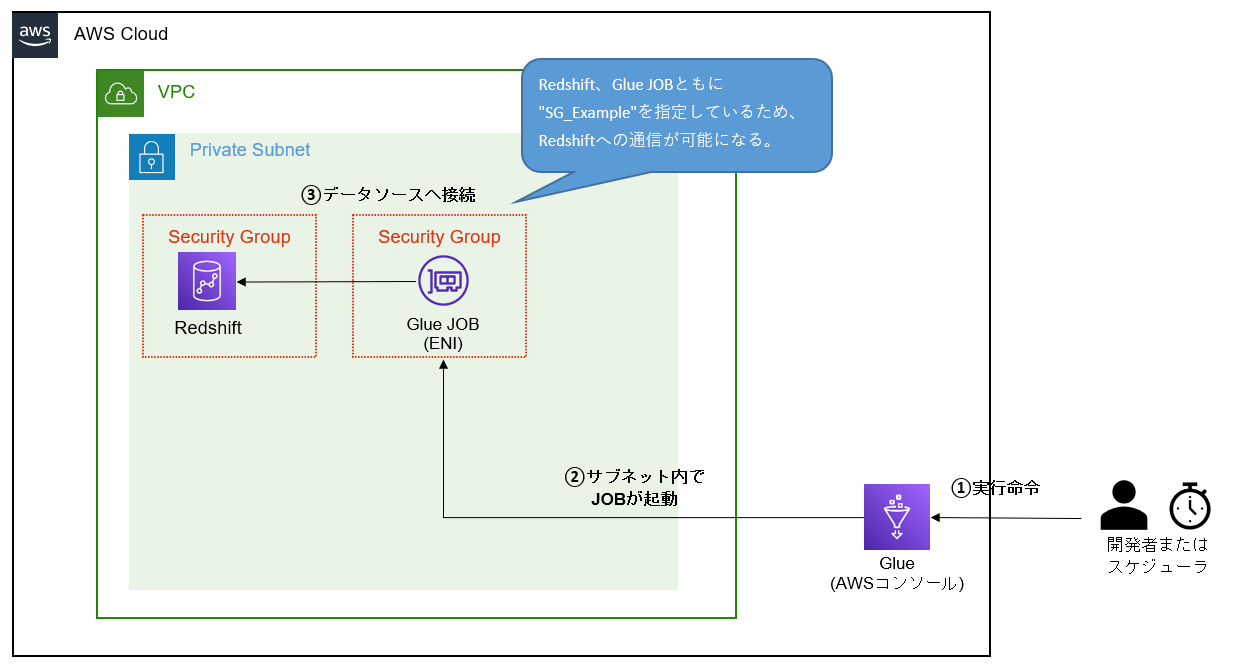
こちらの設定は、RedshiftであればRedshiftコンソール、GlueならばGlueコンソールのConnectionにて
確認することが出来ます。
AWS公式ドキュメントでは、この設定方式は「自己参照ルール」と呼ばれております。
引用元:
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/setup-vpc-for-glue-access.html
2.DBユーザーの権限の問題
上記1の内容を全てクリアした上でJOBを実行してもなおエラーが出る場合があります。この場合、考えられる原因は、JOBで指定しているDBユーザーの対象テーブルへの権限が無い事によることがほとんどです。
JOBを実行した際、DBユーザーによる権限が起因として返されるエラーメッセージは以下のようなものです。
"An error occurred while calling o97.getDynamicFrame. Exception thrown in awaitResult:"
・・・ぱっと見、何が原因なのか分からないですよね(笑)
しかし、CloudWatchなどで詳しくエラーログの内容を見てみると、
"permission denied for schema XXX"
のような、いかにもDB起因のエラーが記録されていることがあります。
この場合、実行しているJOBで
・どのような操作を
・どのスキーマの
・どのテーブルで
を行っているのかを確認することが必要です。
どんな操作を行っているのかを確認できたところで、
クライアントツール等からそのユーザーでDBに実際にログインし、
実際にそのクエリを実行してみてエラーが返ってくるかを確認してみましょう。
ここでエラーが返ってくるようであれば、単純にDBユーザーのクエリの実行権限が
足りないということになるので、GRANT文などでそのDBユーザーに対して権限を付与しましょう。
3.まとめ
サーバレスということもあり、Glueではインフラ面を意識することはあまりないかもしれません。しかし、JOBが動いている裏側で、どのような通信や部品が行われているのかを把握することにより、
よりエラーの解決スピードを上げることが出来るのではないでしょうか。