はじめに
本記事では Azure Databricks についてまだ馴染みのないデータに関わるエンジニア向けに、Databricksについての概要の解説や基本的な操作方法について説明していきます。
少々ボリュームはありますが、本記事のみで Azure Databricks が一通り使えるような内容となっております。
注意点について
- Azure Databricks のワークスペースは既に準備されているという前提のもと進めていきます。ワークスペースの準備がまだお済でない場合、こちらに Azure databricks ワークスペースの作成方法が記載されていますので参考にしていただければと思います。
- Databricks は大規模データの分析時に真価を発揮するサービスにはなりますが、今回はチュートリアルとして小さなサンプルデータを使用します。
- Python や SQL の知識があると本記事の内容はより理解が深まります。
- 今後のアップデート状況などにより一部 Databricks 上の UI が変更される可能性があることをご了承ください。
本記事のゴール
以下を理解することを想定しております。
- Azure Databricks とは
- Databricks を使用するメリット
- 基本的な Azure Databricks の操作手順
- クラスターの作成
- DBFS 内にデータのアップロード
- ノートブックの立ち上げ
- データの簡単なETL処理(読み込み-加工-DBへ保存)
- 作成したテーブルの可視化
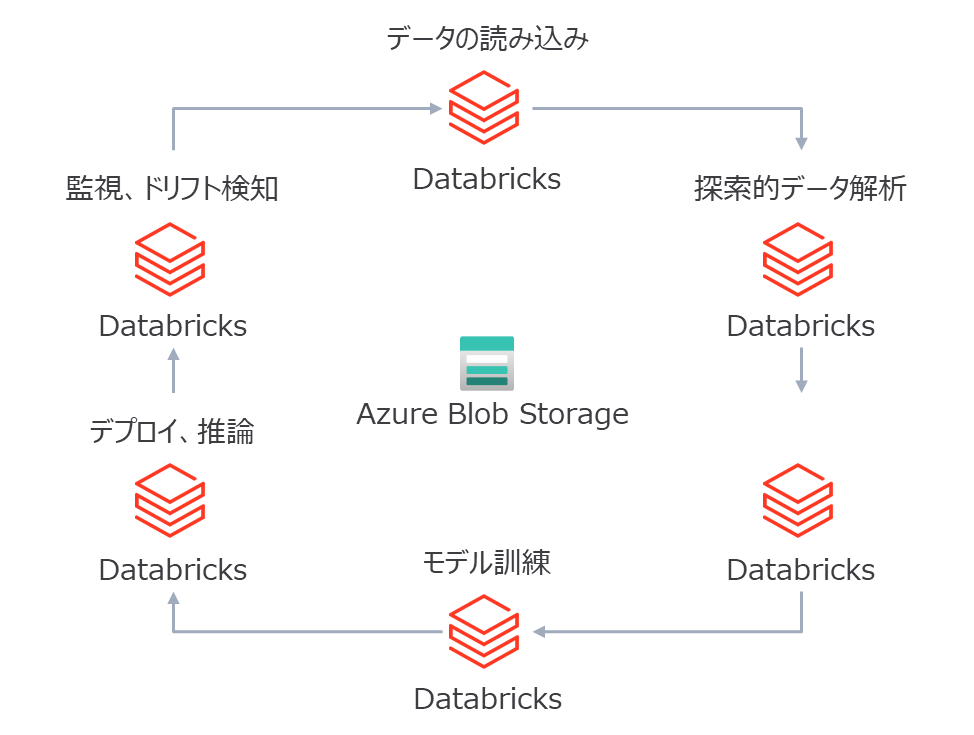
Azure Databricks とは
Databricks は Databricks 社によって開発された統合データ分析プラットフォームです。
このプラットフォームを Azure のクラウドサービスとして最適化して利用できるものにしたのが Azure Databricks になります。
Azure Blob Storage を中心としたデータの ETL 処理や、機械学習モデルの開発・管理、Redash という BI ツールの機能を用いた可視化など、すべて Databricks 内で作業が完結できるのが主な特徴になります。
Databricks を利用するメリット
Databricks には今までデータを扱う上で問題となっていた点を解決するような様々な機能を利用できることがメリットとなります。
- 分析用途による他サービスとの連携が必要なく Databricks で完結可能
- Apache Spark による分散処理をベースにしており、大規模なデータを高速で処理することが可能
- Delta lake を利用した信頼性の高いデータ処理が可能(後ほど解説 *1)
- ノートブック上で複数の言語(Python, R, SQL, Scala)を使い分けられる
- 複数人でワークスペースを利用できるので共同開発が可能
- ノートブックのバージョン管理、ジョブの実行にも対応
本記事ではすべてのメリットについて解説できるわけではありませんが、Azure Databricks を使い始める上で重要になる基本的な使い方の部分を解説できればと思います。
基本的な Azure Databricks の操作手順
クラスターの作成
クラスターとは
クラスターとはノートブックで行う処理やデータベースの操作などを行うために必要な計算リソースになります。
実際に処理は裏側で VM によって行われ、クラスターなしにデータを扱うことはできません。
まずはデータを扱う前にクラスターの作成から始めます。
クラスターの作成
Azure Databricks のワークスペースを開き、左側の項目にある「Compute」とあるのでクリックします。
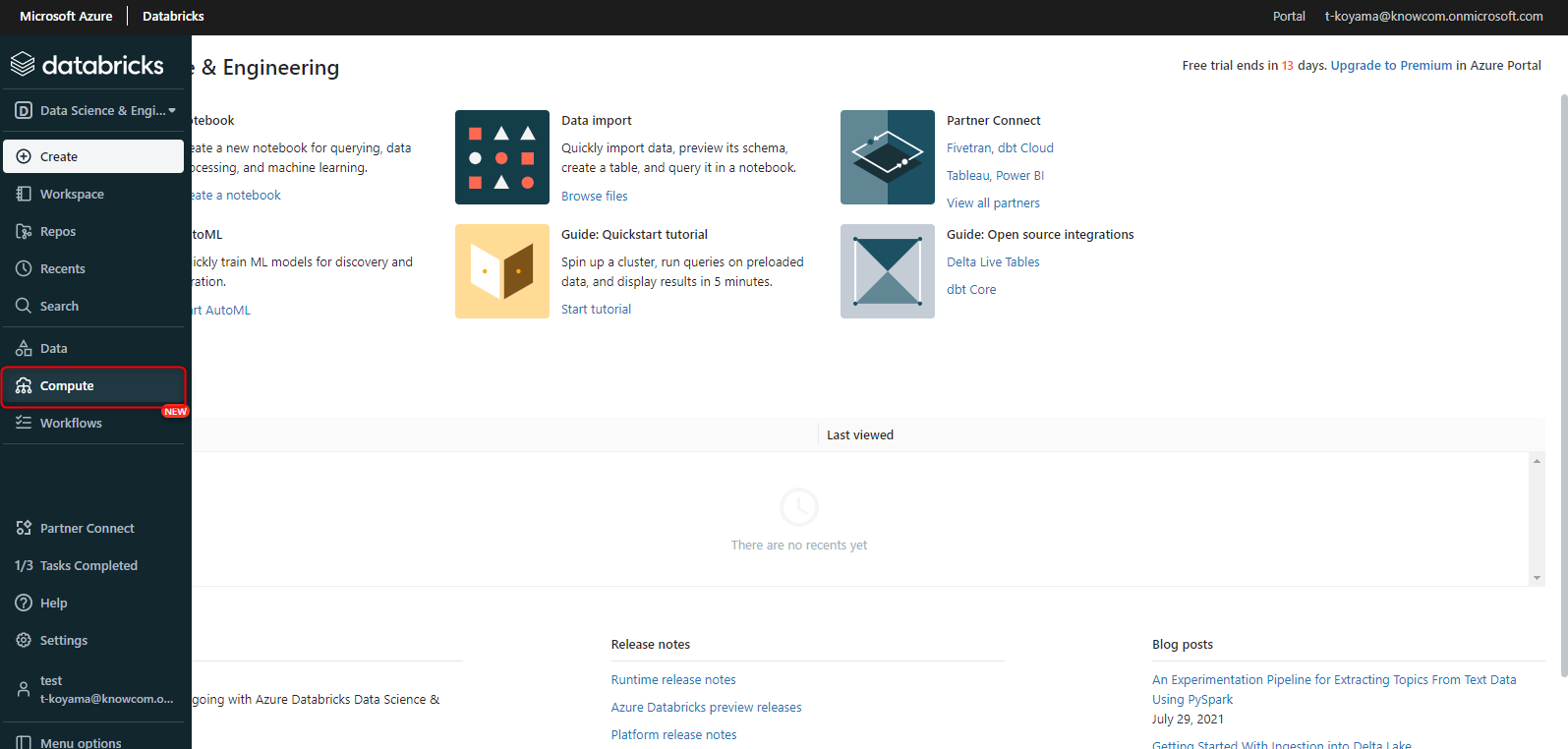
「Create Cluster」をクリックします。
クラスターの詳細を決める画面になりますが、以下の画像のように設定しました。
上から順に解説をおこなっていきます。
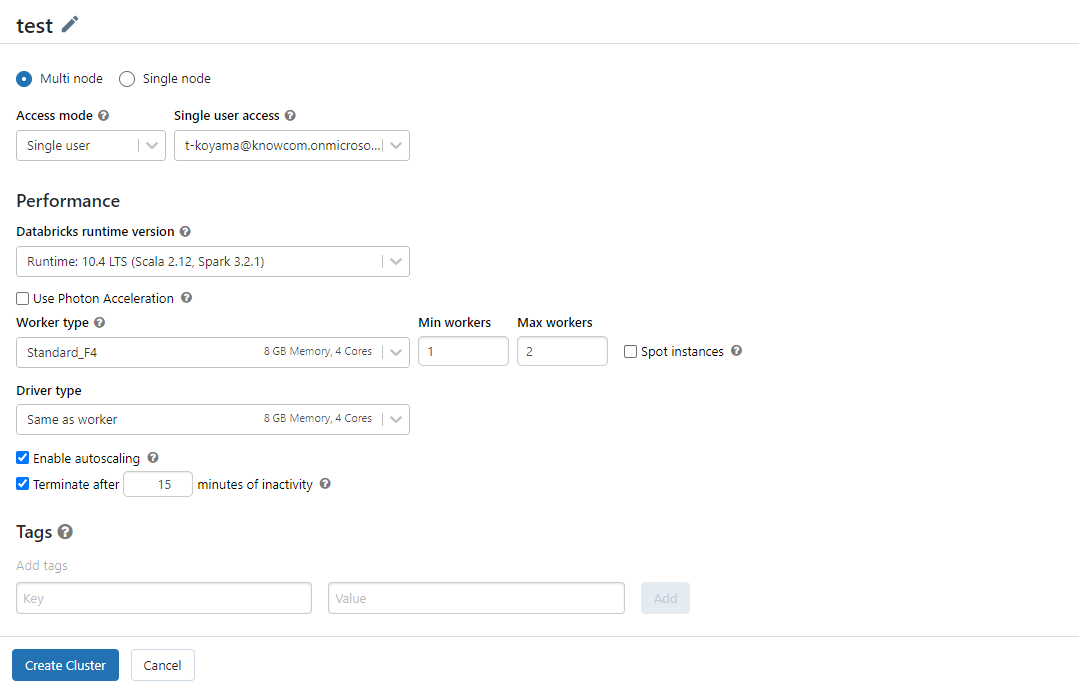
-
クラスター名
任意で指定してください。こちらでは「test」としております。 -
Multi node と Single node
分散処理をするには 「Multi node」を選択します。 -
Access mode と Single user access
Access mode では クラスターを対象者を1人に絞る、もしくは共同メンバーと共有できるようにするのかを決定します。また扱える言語も限定することができます。本記事では筆者のみしかクラスターを使用しないため「Single user」と指定しています。
必要に応じて変更してください。「Single user」と指定した場合のみ、Single user access でクラスターを扱う対象者を指定できます。
-
Databricks runtime のバージョン
バージョンですが、デフォルトのままで特に問題ありません。 -
Use Photon Acceleration
より高速なクエリパフォーマンスを実現したい場合に Photon エンジンを利用できます。
今回必要ないのでチェックは入れません。 -
Worker type と Driver type
クラスターには Worker type と Driver type の2種類が存在します。Spark において Driver type は処理を細かなタスクへと分解していき、実行するために計算リソースのリクエストを送るなど処理を管理するような役割を持ちます。
対して Worker type は実際に割り当てられたタスクを実行する役割を持ちます。Spark の内部処理についての詳細はこちらの Spark 公式ドキュメントに記載されております。
クラスターのスペックについてですが、用途によって種類は非常に多いです。
今回は大きなデータは扱いませんので小さな「Standard_F4」を選択しました。
今後もし大きなデータを扱う場面で処理の重さを感じればスペックをあげるなどの検討が必要になってきます。Worker と Driver で種類を変えることもできます。
今回は「Same as worker」を選択することによって同じにスペックにしました。Driver は 1つのみしか設定できませんが、Worker は複数にすることができます。
数が多いほどタスクをそれぞれの Worker に分散させていることになります。
今回は オートスケーリング機能(後ほど解説 *2)を使って Woker 数の最小を1、最大を2にしました。 -
Enable autoscalling
オートスケーリング機能 *2 は処理の重さによって自動で Worker 数を調整してくれる機能になります。
処理に対して必要以上の Worker が起動することを防ぎます。
コストを抑えることができる便利な機能なのでチェックを入れました。 -
Terminate after [ ] minutes of inactivity
こちらはクラスターの操作が一定時間ない場合にクラスターを自動で停止する機能になります。
Azure Databricks ではクラスターが起動している時間の分だけ課金されていく仕組みです。
クラスターを使用していないにも関わらず、クラスターの停止を怠ると思わぬ課金が発生することになります。
そのような思わぬ課金を防ぐためにも自動停止機能は必ずチェックを入れましょう。[ ] の中には10から10000の間の数字を入れ、自動停止までの時間を分単位で指定します。
今回は15分操作がなければ自動停止するように設定しました。
最後に「Create cluster」をクリックするとクラスターの作成完了となります。
クラスター作成の完了には数分かかるため少々お待ちください。
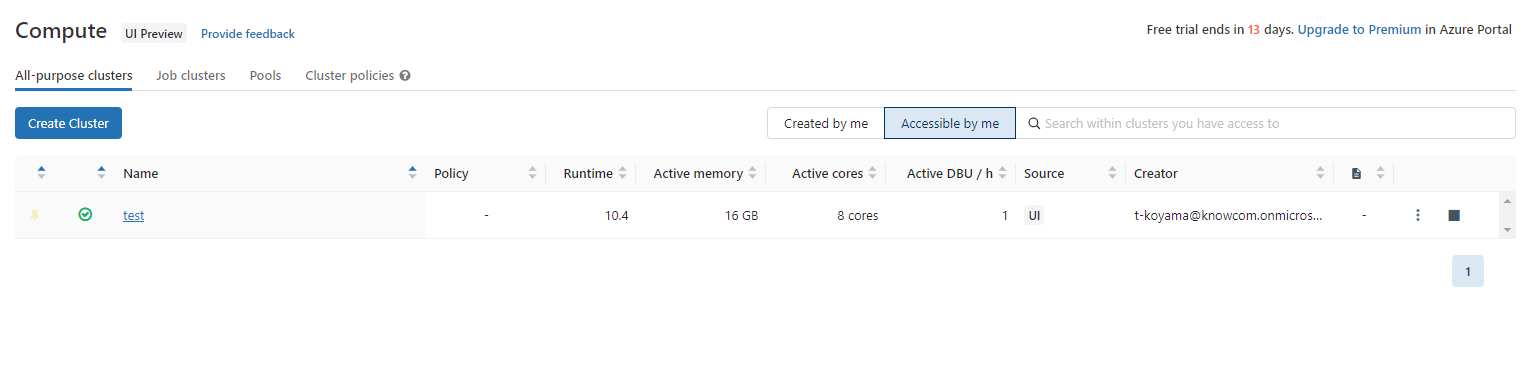
成功すればクラスターを作成する直前の「Compute」の画面から以下の画像のように確認できるようになります。
クラスター名(test)の左に緑のチェックマークがついていればクラスターが起動している状態です。
クラスター名をクリックすると、クラスターの起動、停止、設定の変更なども行えます。
クラスターの作成はこれで以上です。
DBFS 内にデータのアップロード
DBFS とは
DBFS(Databricks File System の略) とは Databricks のワークスペースにマウントされた 分散ファイルシステムのことです。
実は DBFS にアップロードしたファイルは Azure Blob Storage へ格納されます。
Databricks のワークスペースのユーザーであればワークスペース上から追加の認証情報なしに DBFS へアクセスすることが可能です。
データの準備
これから DBFS 内にデータのアップロードを行っていきます。
アップロードする前に使用するデータの準備から始めます。
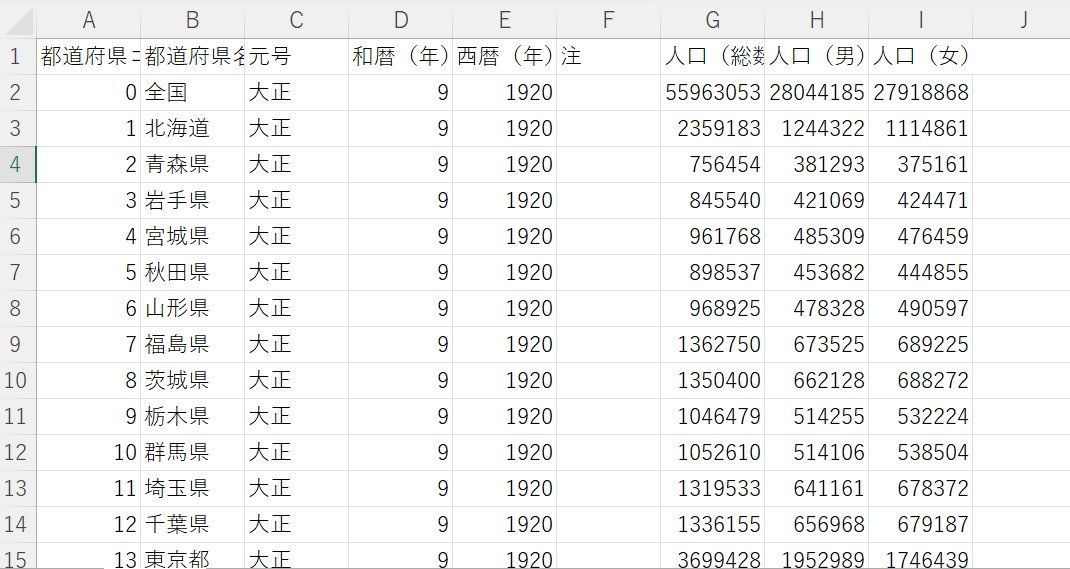
こちらから CSV データ(c01.csv)をダウンロードしようと思います。
CSV ファイルを開けてみると時系列に沿って全国と都道府県別の人口の推移が男女別と総数で記録されてるようなデータが確認できました。
データのアップロード
データが準備できたので DBFS へアップロードしていきましょう。
左のサイドバーから「Data」をクリックし、「Create Table」をクリックします。
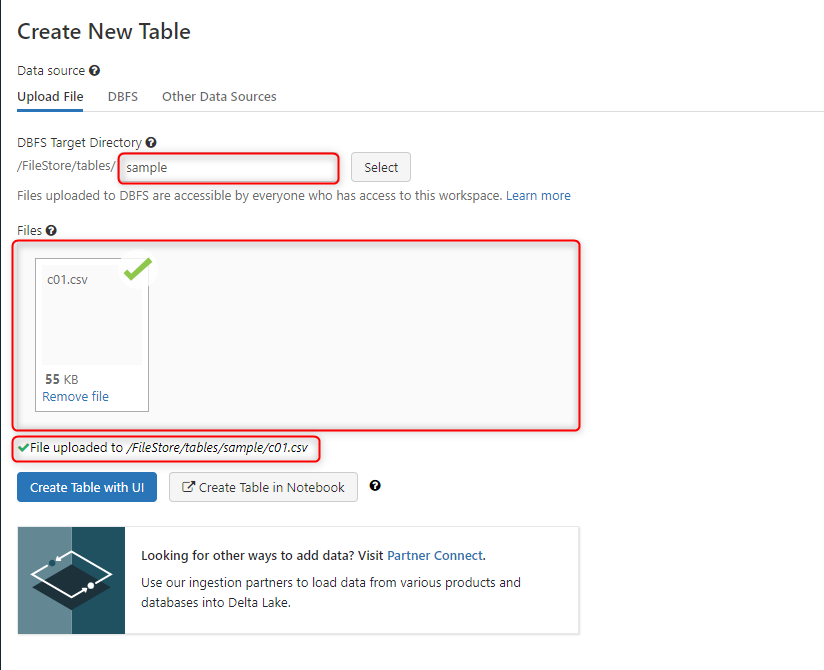
次の画面に進むと、まずファイルを格納する場所を指定します。
DBFS 内は始めからデフォルトでデータの用途別にフォルダ構成がいくつかされてます。
それらのフォルダ構成は DBFS ルートと呼ばれます。
「FileStore/tables」はDBFS ルートのひとつになります。
この画面から新しいデータのアップロードする際は、アップロード先に上記のDBFS ルート上のどこかでなければいけません。
今回は画像の赤枠内に「sample」と記述し、「FileStore/tables」直下に新たなフォルダを作成して CSV データの格納場所に指定しました。
赤枠の中に何も書かなければ「FileStore/tables」直下に新しいファイルがアップロードがされます。
データの整理ができるフォルダ構成になっていれば任意の場所にアップロードしていただいて問題ありません。
次に2つめの赤枠の部分をクリックします。
するとローカルファイルが開くのでダウンロードした CSV データを指定します。
クリックベースで行えるので特に問題なく操作できると思います。
3つ目の赤枠のような文がでたらアップロードの成功となります。
この章での操作は以上になります。
「Create Table with UI」や「Create Table in Notebook」をクリックすると、アップロードしたファイルをテーブルとしてデータベースに書き出すこともできます。
しかし、後にノートブック上でテーブル作成を行うのでこの章では飛ばします。
ノートブックの立ち上げ
ノートブックではデータの読み込み、加工、データベースへの書き込みなど様々な操作をコードベースで行うことができます。
早速ノートブックを立ち上げていきましょう。
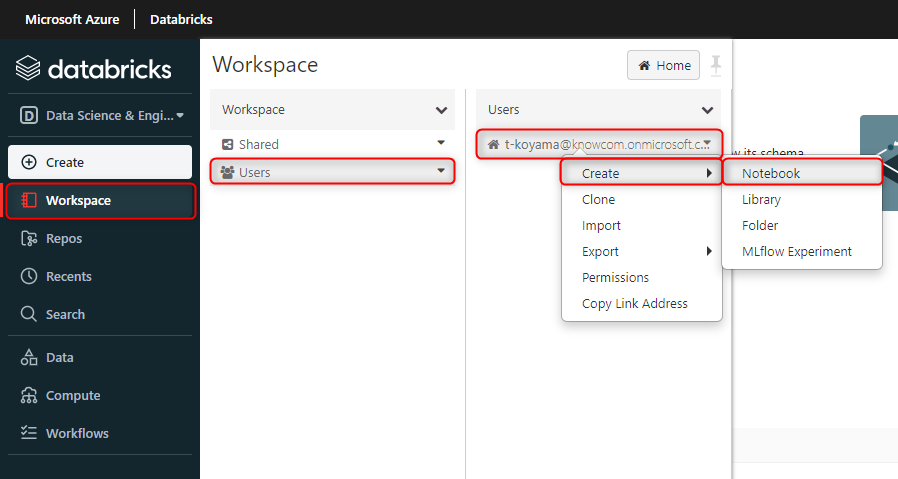
左のサイドバーから、「Workspace」、「Users」とクリックしていきます。
ユーザーご自身のメールアドレスにカーソルを合わせて右クリックします。
すると複数の項目が出てくるので「Create」、「Notebook」とクリックしてください。
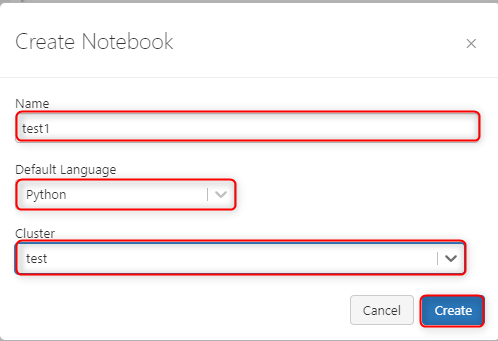
ノートブック名を任意に指定してください。
こちらでは「test1」としております。
次にデフォルトで使用するプログラミング言語を選択します。
選択できる対象は Python、SQL、R、Scala です。
基本は選択した言語でコードを記述します。
しかしノートブック上では選択した以外の言語もマジックコマンドにより使用できます。
今回は Python を指定します。
最後に作成したクラスターを指定して「Create」をクリックしましょう。
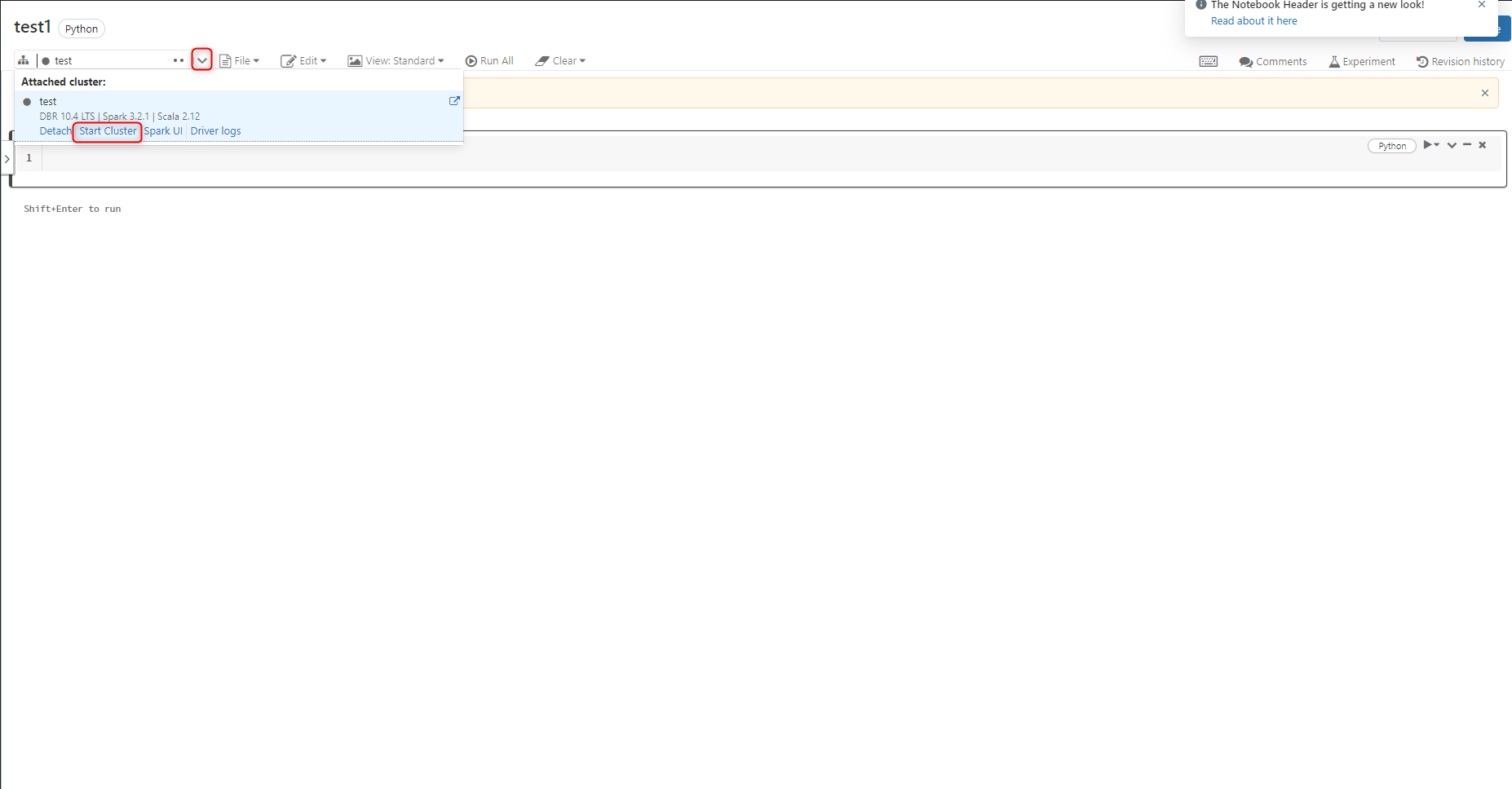
ノートブックが作成できました。
ノートブックを使用する際にクラスター名の左にある丸の色が灰色であれば、クラスターは起動していないので赤枠の部分から起動しましょう。
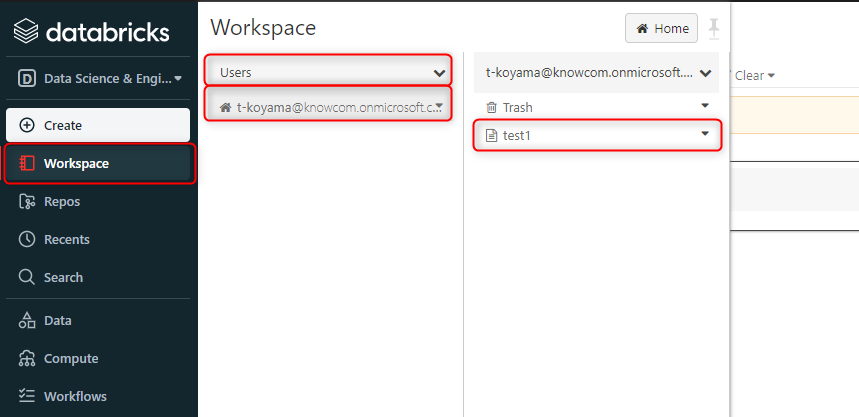
作成したノートブックはご自身のメールアドレスの配下に存在しています。
作業を終えて閉じたノートブックは次の作業時に再びここから開くことができます。
複数人で開発する場合でも、共同メンバーのメールアドレスの配下にある他メンバーが作成したノートブックを開くことが可能です。
ノートブックの作成はこれで終了です。
次の章では実際にノートブックを触っていきます。
データの簡単なETL処理(読み込み-加工-DBへ保存)
ノートブックを使用して、アップロードした CSV データを扱っていきます。
ここからは Python で PySpark のデータフレームを利用したコーディングが中心になってきます。
PySpark は Spark の Python 用 API を使用して、Spark を Python で扱えるようにしたものです。
分散処理を用いて大容量のデータを分析するためのフレームワークである Spark を Python の文法で記述することができます。
Databricks では PySpark がデフォルトで使用できるようになっています。
今回扱うのは少量のデータなので PySpark を使うメリットはあまり感じられません。
ですが今後大きなデータを使うことも想定して PySpark を使っていきます。
データの読み込み
ノートブックを開き、クラスターを起動し終えた状態から進めていきます。
データを読み込みましょう。
以下のコードをセル内に記述します。
from pyspark.sql.types import *
population_csv = "dbfs:/FileStore/tables/sample/c01.csv"
# スキーマ指定
schema = StructType([
StructField("都道府県コード",StringType(), False),
StructField("都道府県名",StringType(), False),
StructField("元号",StringType(), False),
StructField("和暦(年)",StringType(), False),
StructField("西暦(年)",StringType(), False),
StructField("注",StringType(), False),
StructField("人口(総数)",IntegerType(), False),
StructField("人口(男)",IntegerType(), False),
StructField("人口(女)",IntegerType(), False),
])
# データの読み込み
df = spark.read\
.format("csv")\
.options(header="true")\
.option('charset', 'shift-jis')\
.load(population_csv, schema=schema)
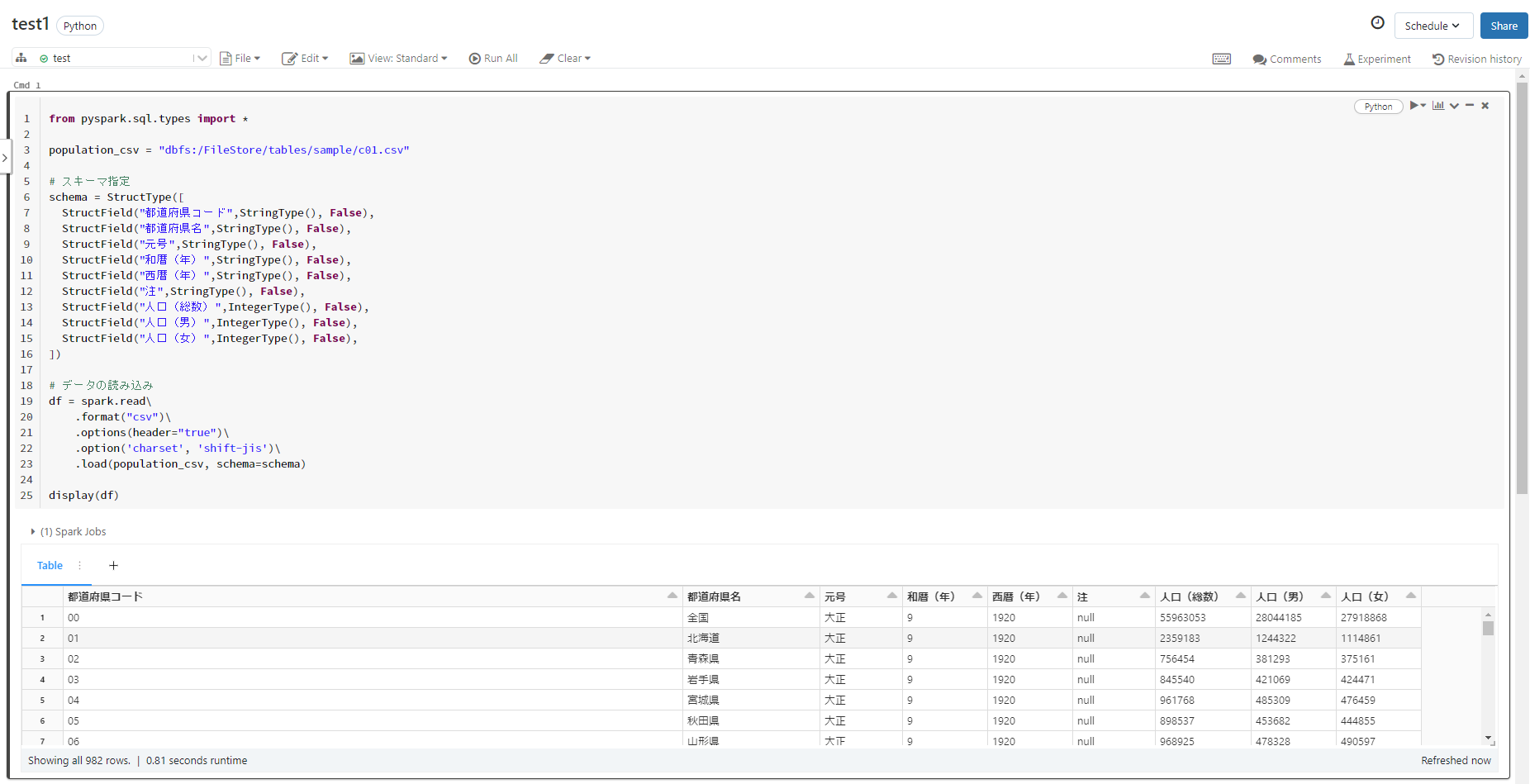
display(df)
まずデータ型を定義するためのモジュールをインポートします。
次に対象データのパスを指定します。
読み込むデータのスキーマの定義もします。
そして「spark.read ~」でデータを読み込んでいきます。
読み込むデータの形式を「csv」と指定、1行目をヘッダー、そして日本語の文字化けを防ぐためのオプションを付けます。
対象データのパスと定義したスキーマを「load」の引数に指定して変数の「df」に読み込みましょう。
読み込んだデータは「display」で出力することができます。
セルの実行は「Ctrl + Enter」で行えるので実行しましょう。
すると以下の画像の下の部分のように読み込んだデータが出力されていることが確認できます。
データ加工
データが読み込めたので加工に入っていきます。今回はカラム名だけ英語に変更しましょう。
次のセルで以下のコードを実行します。
# カラム名の変更
df = df.withColumnRenamed("都道府県コード","prefectures_code").\
withColumnRenamed("都道府県名","prefectures").\
withColumnRenamed("元号","era").\
withColumnRenamed("和暦(年)","year_jp").\
withColumnRenamed("西暦(年)","year").\
withColumnRenamed("注","note").\
withColumnRenamed("人口(総数)","population").\
withColumnRenamed("人口(男)","man_population").\
withColumnRenamed("人口(女)","woman_population")
display(df)

カラム名が変更できたことを確認できました。
今回は Azure Databricks の基本的な操作手順の流れが理解できることを目標としているので加工をここまでにします。
もちろん実現したい要件によってはより複雑なデータ加工が必要とされます。
今後ノートブックで複雑なデータ加工をしていく場合、Databricks というよりは PySpark を深く学んでいく必要があるかと思います。
データの保存
加工が終わったのでデータをデータベースへと保存していきます。
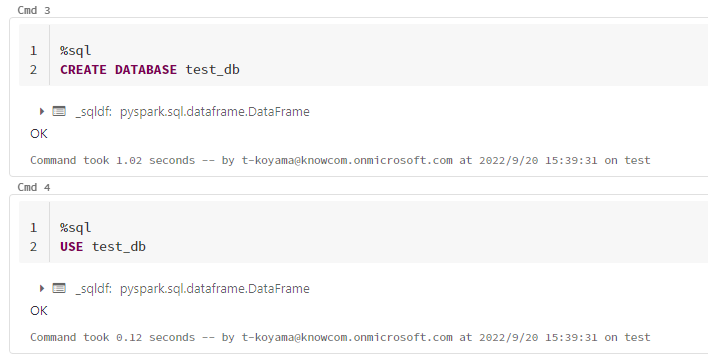
新しいデータベースの作成とデータベースへの移動は SQL で行いましょう。
Databricksではセルの始めにマジックコマンド「%sql」と打つことにより SQL 文を記述できます。
処理によって言語の特性をいかした記述しやすい言語での使い分けが可能になります。
CREATE DATABASE で 「test_db」 という名前のデータベースを作成しました。
そして USE を使用して作成したデータベースに移動しました。
%sql
CREATE DATABASE test_db
%sql
USE test_db
次に作成したデータベースにテーブルを書き出していきます。
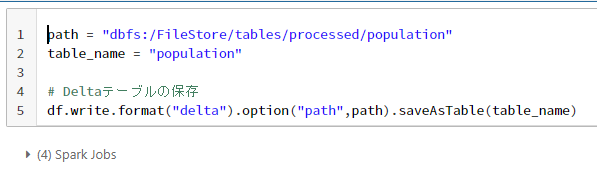
まず保存先のパスとテーブル名を決めます。
書き出しには write を使います。
format に「delta」と指定し、先ほど決めた保存先のパスとテーブル名を入れればデータベースに保存可能です。
path = "dbfs:/FileStore/tables/processed/population"
table_name = "population"
# Delta 形式のテーブルの保存
df.write.format("delta").option("path",path).saveAsTable(table_name)
Delta lake について
ここで format に指定した「delta」とは何なのでしょうか。
まず Databricks では、テーブルを保存する際に Delta lake *1 と呼ばれる オブジェクトストレージ上で構築されるストレージレイヤーを利用することができます。
Delta lake の利点は従来の Data lake では実現できていなかった信頼性の高い読み書きを可能にします。
信頼性の高い読み書きとは何かを理解するために、Delta lake に保存された Delta 形式のテーブルの構造を実際に確認してみましょう。
以下の画像は先ほど保存した Delta 形式のテーブルの構造です。
parquet ファイル + ログが記録されたフォルダ という構造で成り立っています。

Delta 形式のファイルはテーブルのトランザクションをログで管理しているのが大きな特徴になります。
トランザクションが管理されていることによって、
- 処理に問題が起きたことによるデータ破損の防止
- 複数の人数で同時にテーブルを操作してもデータの整合性を保つ
といった信頼性の高い読み書きを実現しているのです。
ログをたどることによってテーブルの過去の任意の時点にロールバックすることも可能です。
他にも
- オブジェクトストレージに構築されるのでストレージコストが安価
- 構造化・半構造化・非構造化に関わらずデータの集約が可能
- 高速なクエリの実行
- バッチ処理、ストリーミング処理を同時に行える
など Delta lake には Data lake と DWH を良いとこ取りしたようなメリットが含まれています。
Delta lake を利用するにはテーブルを保存する際に format を「delta」とすることで Delta 形式のテーブルとして保存することができるのです。
Delta lake について、より詳細な情報はこちらを参照ください。
データベースとテーブルの確認
作成したデータベースやテーブルは Databricks の ワークスペースで確認することができます。
サイドバーの「Data」から作成したデータベースの名前とテーブルの名前があるのがわかります。
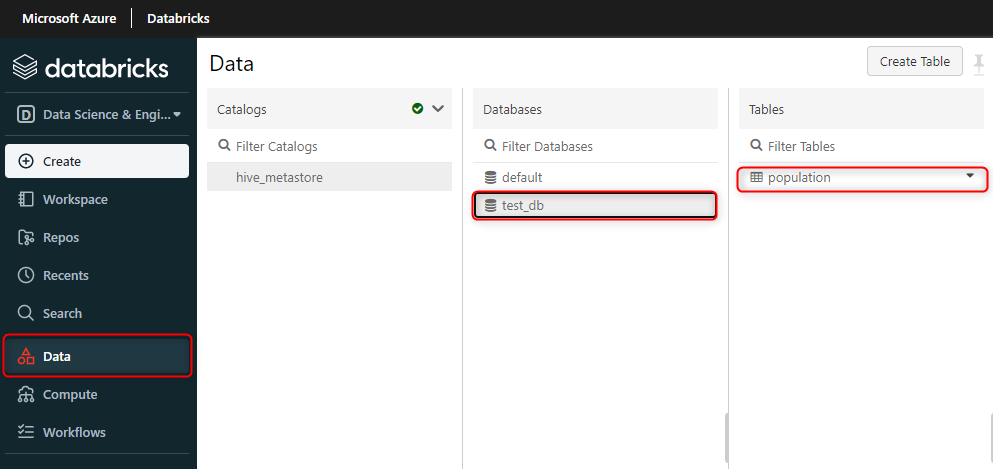
以上でこの章の工程はすべて終了です。
作成したテーブルの可視化
前章で作成した Delta 形式のテーブルを可視化していきましょう。
まず新しいノートブックを立ち上げて、クラスターを起動してください。
必ずしも新しいノートブックを使う必要があるわけではありません。
しかし、ノートブックを用途によって使い分ける方が整理されるのでおすすめです。
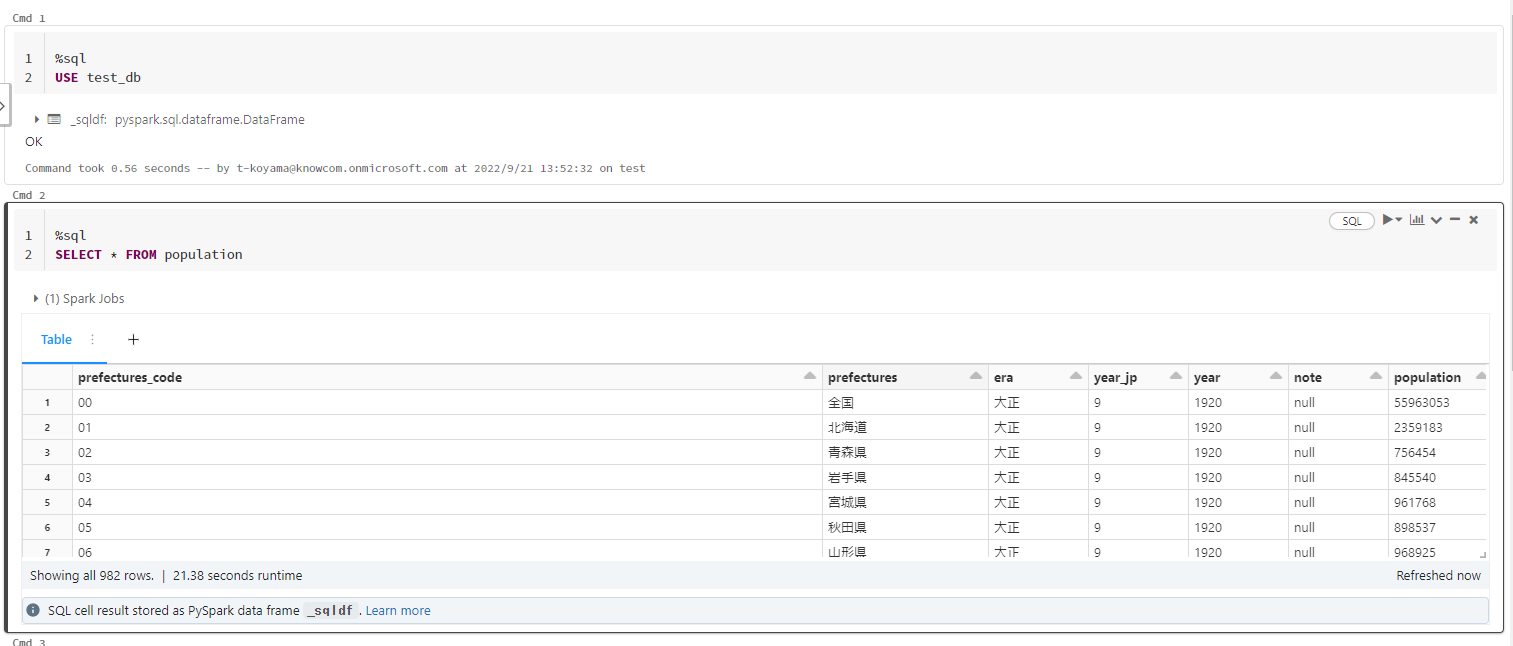
データの中身の確認
作成したテーブルをデータベースからSQLクエリで呼び出してみましょう。
%sql
USE test_db
%sql
SELECT * FROM population
問題なく出力されていそうです。
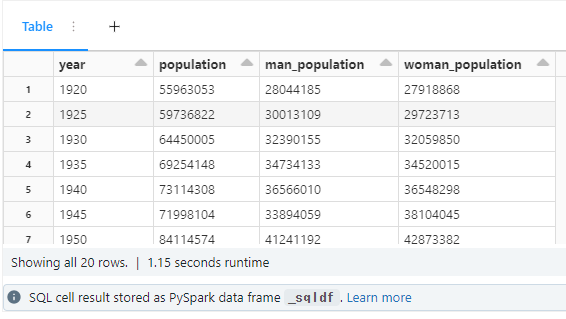
クエリの実装
可視化に必要な情報だけをクエリで抽出します。
今回は、時系列に沿って全国の人口の推移を総人口、男女別で抜き出してみました。
%sql
SELECT
year,
population,
man_population,
woman_population
FROM
population
WHERE
prefectures = "全国"
ORDER BY
year
結果は以下の画像のようなテーブルが出力されます。
ここから抽出した情報の可視化の作業に入ります。
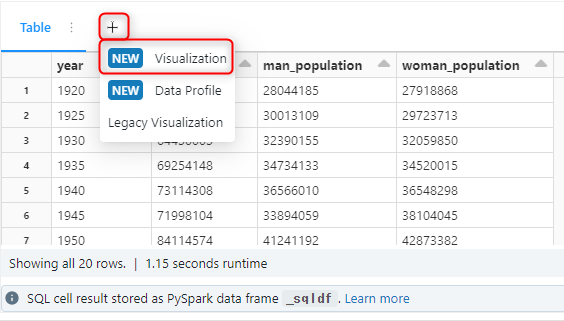
可視化
先ほどクエリで必要な情報を抽出した時のテーブルから、赤枠にある「Visualization」をクリックします。
次の画面では GUI ベースで自由度のあるビジュアルを作成することができます。
「General」のタブではグラフの種類を選択し、X 軸のカラム、Y 軸のカラムを選んでいきます。
Y 軸のカラムは複数選ぶことも可能です。
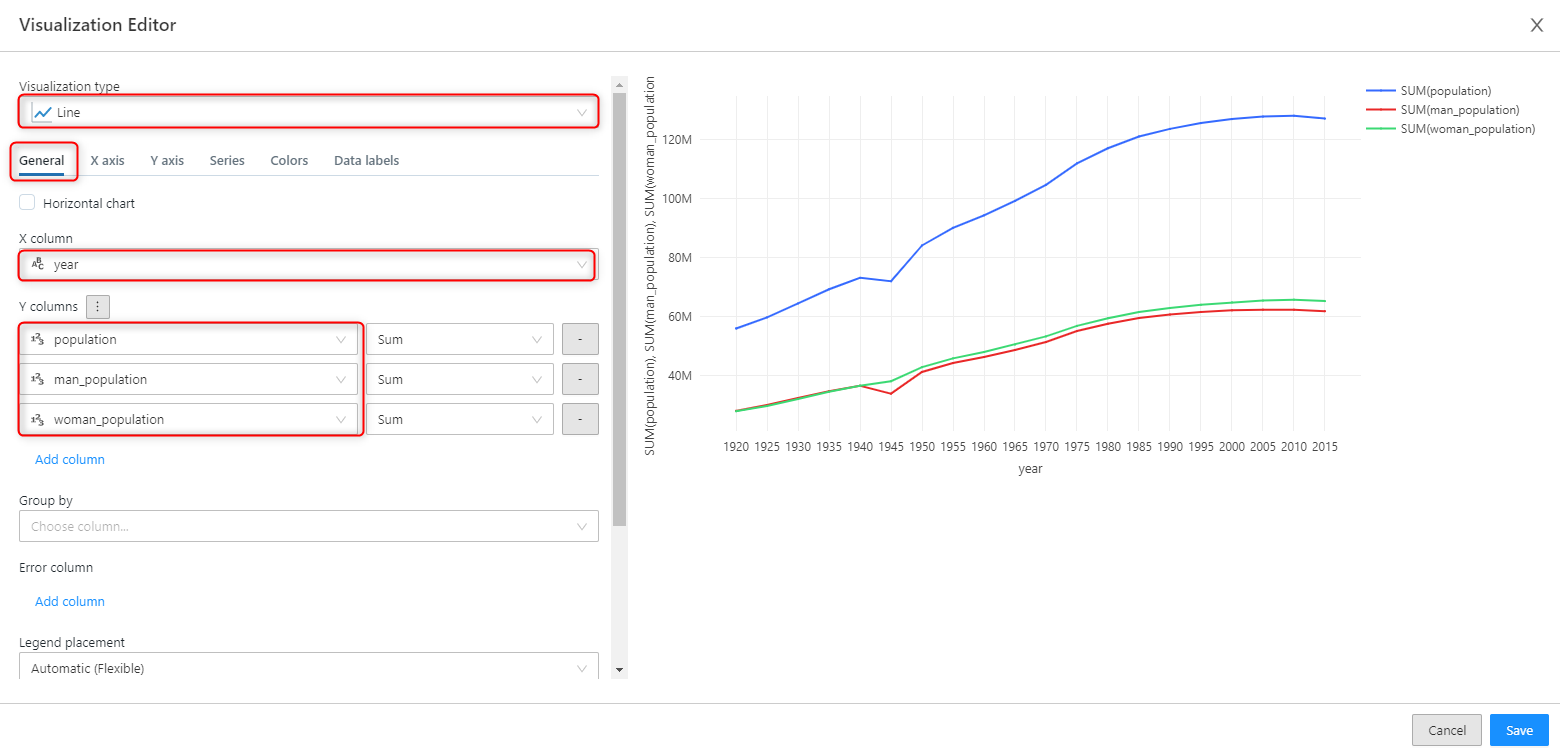
「Series」など他のタブではラベル名を自由に決めることができるといった細かな設定を行えます。
設定がし終えたら右下にある「Save」をクリックしましょう。
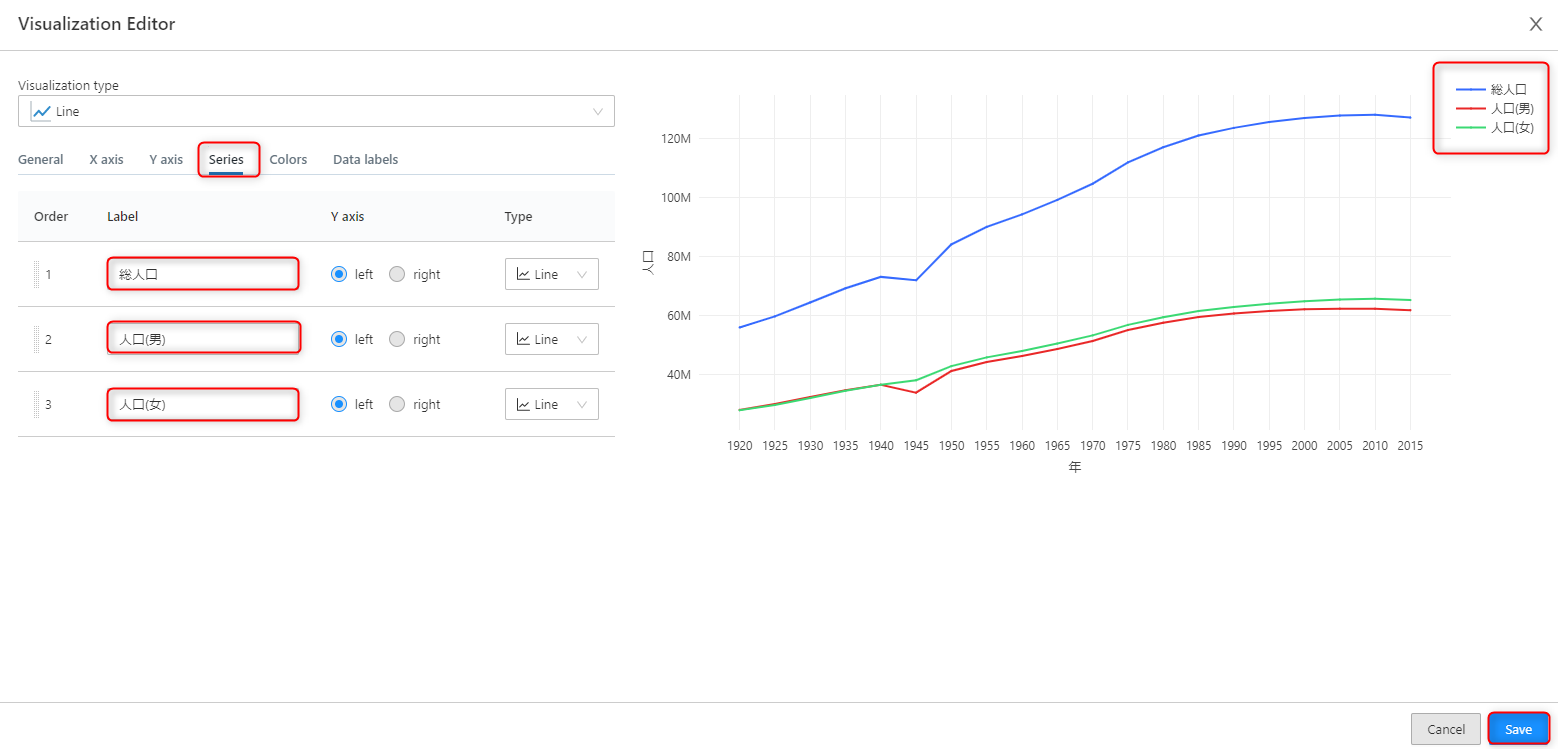
ビジュアルが完成しました。
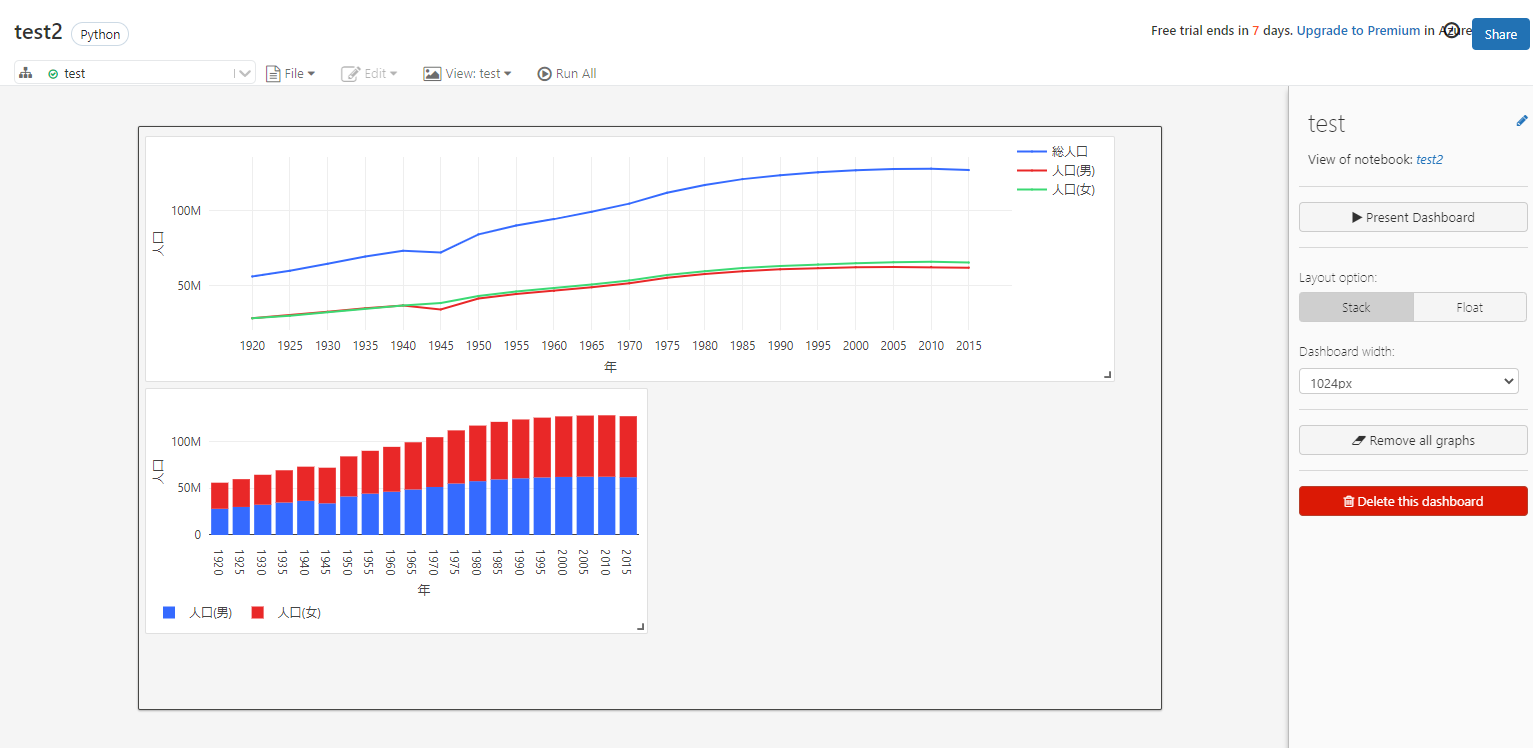
昔から年々増えていた人口が、近年は増えなくなっている。男性よりも女性の人口の方が若干多いことがわかりますね。
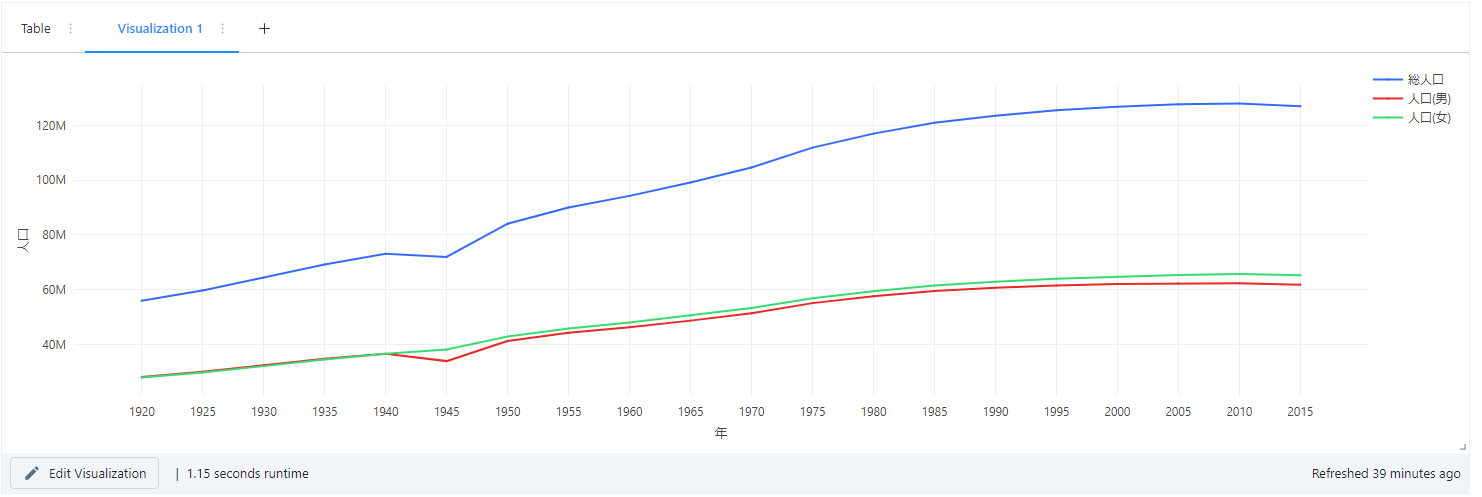
ちなみにビジュアルは「+」から複数作成することも可能です。
試しに別のグラフでビジュアルを作成してみました。
ビジュアル作成画面で「Stacking」という機能を有効にして、男女の人口を棒グラフで積み上げて総人口を表現することも可能です。
作成したビジュアルはノートブックのダッシュボードに張り付けることもできます。
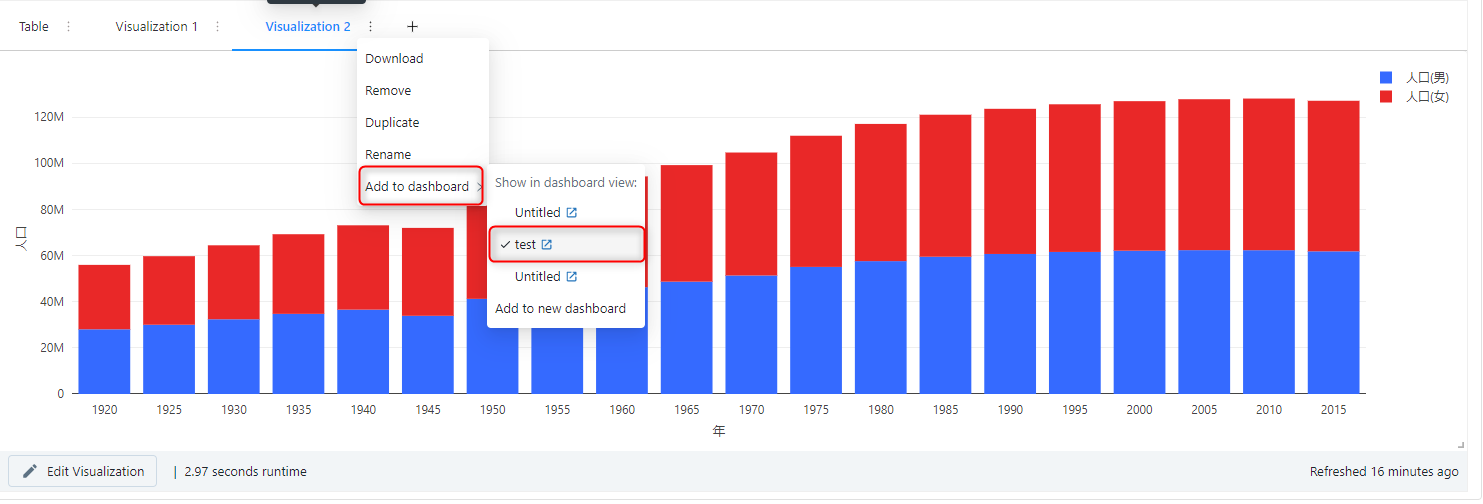
作成したビジュアルを2つともダッシュボードに並べることができました。
注意点としてダッシュボードで共有できるビジュアルは同じノートブック内で作成したビジュアルのみになります。
また、Databricks SQL にも同じようにテーブルを可視化してダッシュボード機能を構築できる機能はありますが、今回ご紹介したものとは別物になります。
以上でテーブルの可視化は完了しました。
まとめ
本記事では Azure Databricks について、利用するメリットや実際に使ってみながら基本的な機能についてノンストップで解説しました。
長い記事にはなってしまいましたが、実際に手を動かしながら最後まで読んでいただくと確実に Azure Databricks の使用感が掴めるようにはなっているかと思います。
まだまだ紹介しきれていない機能はたくさんありますが、本記事で今後 Azure Databricks を使いこなせるようになるきっかけとなれば幸いです。