はじめに
PySpark の filter 関数 は SQL でいうところの where みたいなもので、データフレームを指定した条件で絞りたい場合にフィルタリングできる関数になります。
PySpark を使用していると当たり前のようによく使う関数なのですが、フィルタリングの条件式の中で不等号演算(!=)を扱う際に、知らないと予期しない出力結果を招く可能性があるので共有します。
前提条件
本記事では以下のような簡単なデータフレーム df を作成して検証しています。
import pyspark.sql.functions as F
data = [
("田中", None),
("佐藤", 95),
("山田", 50),
]
cols= ["name","score"]
df = spark.createDataFrame(data = data, schema = cols)
display(df)
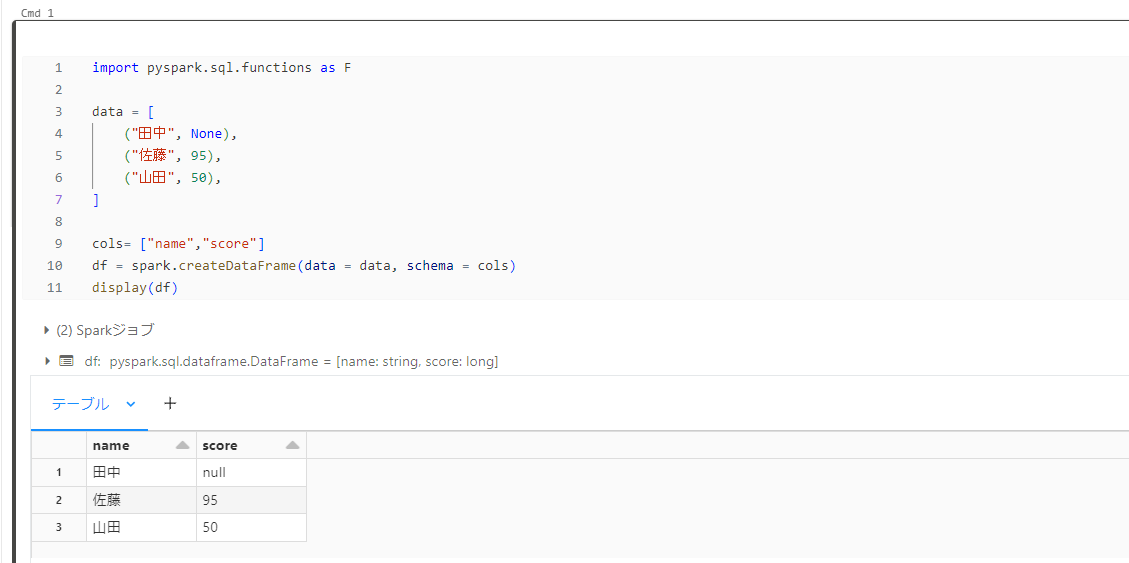
分析環境は Databricks を使っています。
case1
まず本題の前に一般的な filter 関数の使い方から見ていきます。
score カラムの値が 95 のレコードをフィルタリングしてみます。
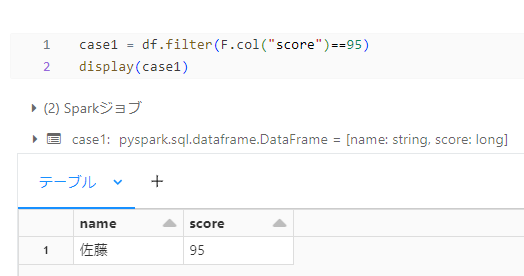
この場合、1行目で等号演算(==)を使い、うまくフィルタリングできているかと思います。
case2
こちらが本題です。
先ほどは、score カラムの値が 95 のレコードをフィルタリングしてみましたが、今度は score カラムの値が 95 でないレコードをフィルタリングしようと思います。
そのために不等号(!=)の演算を以下のように使用しました。
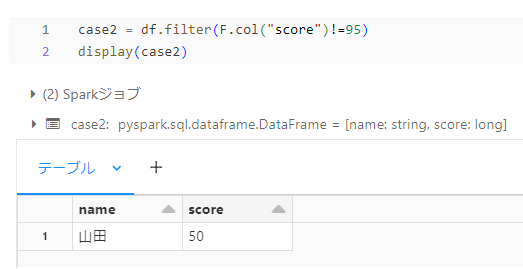
しかし結果を見て、ん?となりました。
なぜなら score カラムの値が 95 でないレコードは山田さんのレコードはもちろん、田中さんのレコードも出力されると予想していたからです。
どうやら不等号演算を使用する場合、値が 「null」 の場合は 「95 でない」という条件に当てはまらないようです。
case3
case2 の解決策になります。
score カラムの値が95でないという条件だけでは足りないので、論理演算(|)を使用して score カラムが null でもフィルタリングするように指定してあげます。
「|」 は日本語で言うところの「または」という意味になります。
以下のようにしてあげます。
「score カラムの値が 95 でない、または null のレコード」のフィルタリングです。
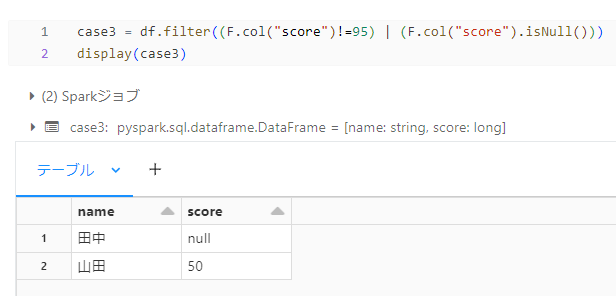
こちらでうまくいきました。
まとめ
filter 関数を使用するときは、大抵の場合上記紹介した簡単なデータフレームではなくレコード数が多いデータフレームになるかと思います。
null 値のデータもフィルタリング対象として想定していたが、実はされていなかった等の事態をふせぐためにも、filter 関数の中で不等号演算を使用する際には十分気を付けましょう。
また、不等号と似たような演算でチルダ(~)と呼ばれる Not 演算子も同様の仕様なので注意が必要です。