2022/6/27(月)~2022/6/30(木)の4日間、サンフランシスコと Web 会場でData+AI Summit 2022が開催されました!
Data+AI Summit 2022 で発表された Databricks 最新情報をお知らせします。
■公式URL

Data+AI Summit 2022 とは?
Databricksは、データ収集、加工、AI・データ分析、可視化までクラウド上でのデータ利活用に必要なあらゆる機能を備えたデータ分析統合プラットフォームを提供する会社です。
そのDatabricks 社が主催する世界最大規模のデータ&AIのカンファレンスである、Data+AI Summit 2022が開催されました!
今年は、Databricks のユースケースや、事例、新機能などに関する情報が発表されています。
ログインページは下記になります。
※メールアドレスの登録が必要です
セッション 概要
Data+AI Summit 2022 FutureMetrics:ディープラーニングを使用して経済戦略計画のための多変量時系列予測プラットフォームを作成する の内容を翻訳し、まとめました。
・Future metricsとは
・多変量モデルを作成するにあたっての課題
・多変量モデルの優秀性
セッション 詳細
Future metricsとは
Future metricsとは未来を予測する方法のひとつになります。
今回では経済データを使って未来を予測し、ビジネス戦略を決定する方法です。
統計的な分析手法を用いて上昇曲線を示しながら、未来の予測を行うといったビジネスアナリティクスという手法はこれまでも存在しているのですが、目指しているのはその先にあるAIを利用したビジネス戦略です。
このプレゼンテーションに登壇されている方はエンタープライズアナリティクスと呼ばれるコンサルティングを行う会社に属しており、企業全体のビジネス上の問題点の解決に従事されています。
例えば住宅ローンであればどのようにローンを決めるのか、どのようなリスクがあるのか、何をもってリスクと判断するのか、優先的に考える残高のポートフォリオは何なのかを数か月という短い期間で解決などです。
本記事ではプレゼンターがAIを利用したビジネス戦略に向けて、多変量モデルの構築に至った経緯や過程、結果について説明していきます。
多変量モデルを作成するにあたっての課題
1. 一変量の先へ
左側はローンの貸し出し高を示すグラフになりますが、モデルの予測(水色)の精度は非常に高いことがわかります。
このモデルでは一変数でも高いパフォーマンスを出すことができます。

対して預金高を示す右側のグラフではモデルの予測にずれが生じていることが見て取れるかと思います。
これは一変数であるとモデルが予測を行うための参照する情報がただひとつしかないので、グラフのとっさの動きに対してモデルの予測が追い付かないためです。
つまり一変量モデルで得られるパフォーマンスには限界があると考えられます。
よって一変量ではなく多変量を扱うモデルの構築を行う必要があると考え、ディープラーニングへの移行を決めました。
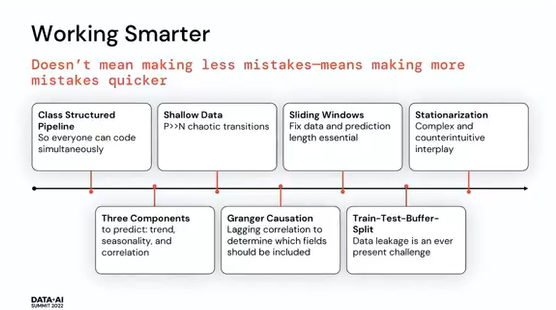
2. クラス構造のパイプライン
当初はクラス構造のパイプラインを持っていませんでした。
当時多くのチームでJupyter noteookで作業することを基本としており、分析自体も容易に行うことができていたのですが、5、6人が同じプロジェクトで同じコードに同時に取り組むことができませんでした。
Databricks環境では5、6人が同時に同じモデルで作業できます。
共有しているモデルやコードの中身ついて、利用する人がそれぞれ理解しておけば各自が与えられた仕事を行うのみになります。
ある部分で問題が起きたとしても、ミスをすべてオープンに共有できるようになり、解決がスムーズになりました。
3. 浅いデータ
モデルに学習させる際に、求められるデータ量に対して実際に用意できるデータ量は浅いことがほとんどです。
なぜならば必要なデータを集めることのできる期間は非常に限られているからです。
ディープラーニングを行う際に、データが浅いことは大きな問題点になりますが、このような場合でもうまく機能するモデルを用意する必要があります。
ここでスライディングウィンドウを利用しました。
スライディングウィンドウはデータ量が少ないときに行う一般的な処理になり、今回のケースで利用しました。
※スライディングウィンドウとはデータをウィンドウと呼ばれる単位で複数に区切り特徴量を計算していく手法になります
以下の画像ではこれらの問題以外にも発生した課題などがまとめられています。
多変量モデルの優秀性
将来予測をするにあたって2種類の出来事が存在します。
それらは予測可能な事象と不可能な事象です。
例えばカナダ政府がある日、突然余剰な現金を国民全員に配ったとします。
このような突発的な事象に関しては決して予測できるものではありません。
対して、基本的な経済については適切なデータがあれば予測することができますし、モデルに取り入れることができます。
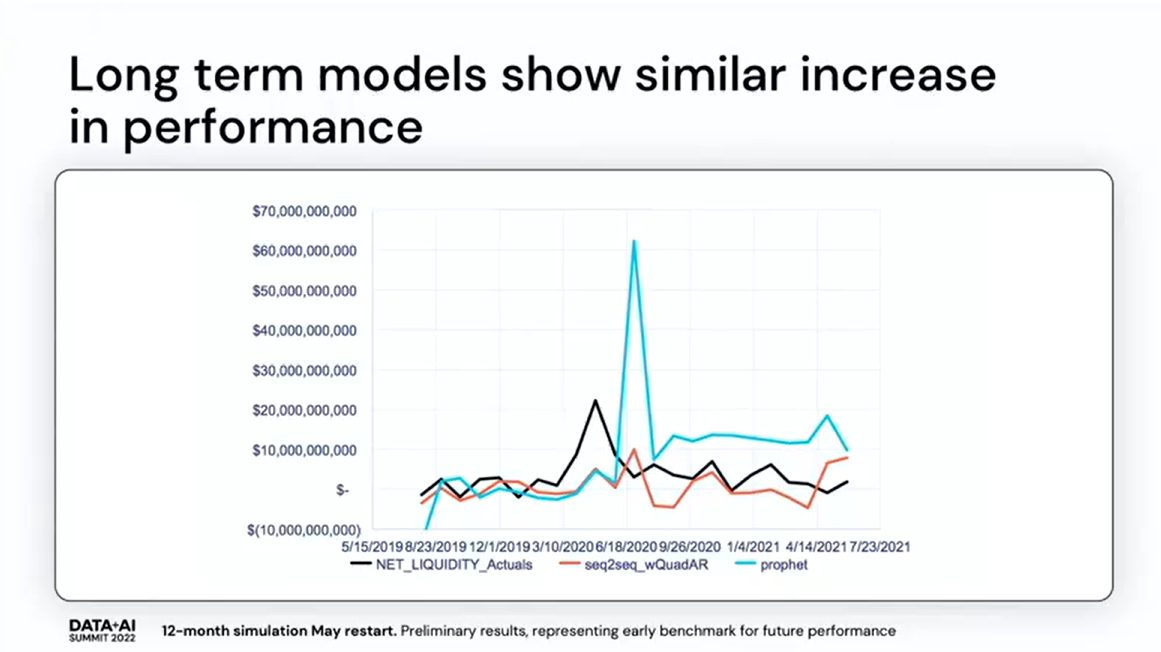
多変量モデルでは予測不可能な事象を含む長期的なパフォーマンスについては高い結果を得られています。
コロナウイルスが流行し、経済が大きく変化した2022年の4月から1年間を予測したところ、流動性の成長と変化をある程度的中させることができました。これは一変量モデルとの違いになります。
以下の画像が多変量モデルの予測(水色)になります。
セッション まとめ
データサイエンティストは単にモデルを作成するだけでなく他のたくさんの仕事の理解する必要があります。
例えばソフトウェアエンジニアがどのように働くのか、ビジネスの仕組み、住宅ローンの仕組みについてもです。
開発環境の中に身を置けば必然とたくさんの人と関わってコミュニケーションをとっていくこととなります。
これらすべての環境を統合する手段として、クラウド、Databricksを利用してコンテナ化された環境を作成しました。
モデルやJupyter Notebookでゼロからすべてを作り直すのではなく、コンテナ化された環境で複雑に絡み合うプロセスを最小することによってシンプルに、簡単に、リソースを最大限に有効活用していくことを考えていかないといけないでしょう。
Data+AI Summit 2022 最新情報更新中!
■Data+AI Summit 2022ナレコム特設サイト
https://www.knowledgecommunication.jp/product/DataAISummit2022.html
Databricks導入ご相談申し込み受付中
Twitterではナレコム最新情報を更新中です。
https://twitter.com/KnowComInc