この記事はfusicアドベントカレンダーその2 23日目の記事です。
fusicではつい先日までPythonで学ぶ強化学習の緑本の輪読会をしていました。
そんな中、「なーーんかJuliaで強化学習のパッケージねーかなー」とおもいつつ、調べても何がいいかわからない状態が続きました。
そもそもJuliaを触っているのが弊社で自分だけなんで、聞いてもいい返事は返ってきません。
めんどくせー、Juliaのslackのworkspaceできいたれ。
そうおもって、ききました。
Q: 「強化学習を今勉強してんだけど、なーんかいいパッケージないと?」
A:「ReinforcementLearning.jlとかいいと思うよ!夏にQ-Learningの開発したやで」
心優しく教えてもらいました。
せっかく教えてもらったんで、こいつを今回ちょっとだけ触ってみました。
入門編ということで!
CartPole
たぶん、一番有名なはず。
台車に立てられた棒を倒さないように左右に動かすゲームです。
この環境について、すでにこのパッケージに梱包されている深層強化学習を使って、実践してみましょう!
packageのインポート
using ReinforcementLearning, ReinforcementLearningEnvironments, Flux
上で書いてる通り、Fluxを使います。上のパッケージを追加しておいてください。
環境について
env = CartPoleEnv(;T=Float32)
ns, na = length(observation_space(env)), length(action_space(env)) # (4, 2)
device = :cpu
- 状態空間
- 位置
- 速度
- 角度
- 角速度
の4つがあります。
で、行動に関して言えば、右か左かしかないので2が設定されています。
layerの定義
layer1 = Dense(ns, 128, relu)
layer2 = Dense(128, 128, relu)
layer3 = Dense(128, na)
neural_network_q = NeuralNetworkQ(model = Chain(layer1, layer2, layer3),
optimizer = ADAM(),
device = device)
3層のネットワークに128このノードを連結させてます。
4つの行動から、左か右かの判断をさせるため、4:128:2 の順でつなげます。
戦略と報酬
ϵ_selector = EpsilonGreedySelector{:exp}(ϵ_stable = 0.01, decay_steps = 500)
q_base_policy = QBasedPolicy(learner = BasicDQNLearner(approximator = neural_network_q,
batch_size = 32,
min_replay_history = 100,
loss_fun = huber_loss),
selector = ϵ_selector)
ε-greedy法を選択します。
Agentの定義
circular_risa_buffer = circular_RTSA_buffer(capacity = 1000,
state_eltype = Float32,
state_size = (ns,))
agent = Agent(
π = q_base_policy,
buffer = circular_risa_buffer
)
bufferについてはなんだかよくわかっていませんが、Policyを改善するために、Agentと環境とを行き来しているものみたいです。
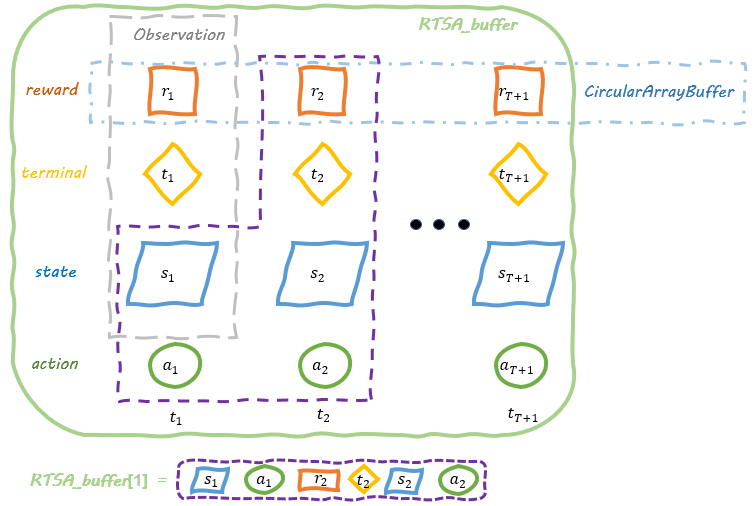
こんな感じらしいです。
学習してみます
hook = ComposedHook(
TotalRewardPerEpisode(),
TimePerStep()
)
run(agent, env, StopAfterStep(10000; is_show_progress=true); hook = hook)
Progress: 100%|███████████████████████████████████████████████████████████████| Time: 0:00:11
hookへ報酬と学習時間を保存していきます。
自分の環境だと、ざっと11秒程度で終わりました。早いですね。
遷移を可視化するとこんな感じです。
using Plots
plot(hook[1].rewards, xlabel="Episode", ylabel="Reward", label="")
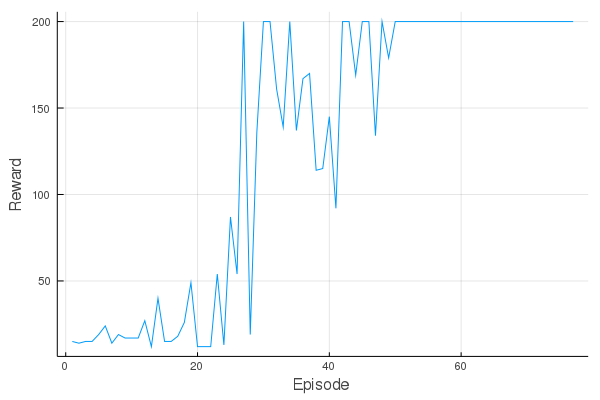
50エピソード超えたあたりくらいで、満点を取っています。
ふむ、なんか過学習してる気がするんですが。
Note
ReinforcementLearning.jlを普通にインストールしても出来ませんでした。
masterブランチから落としてきましょう。
using Pkg; Pkg.add(PackageSpec(name="ReinforcementLearning", rev="master"))
で出来ます。
感想
自分の強化学習に対する理解が浅いため、いまいち理解出来ない部分も多かったです。
ドキュメントが豊富、、、とは言い難いですが、サンプルもあるし、開発途中っぽいので、ウォッチして行こうかなと思います。
ありがとう。教えてくれたJuliaの人よ。
結果
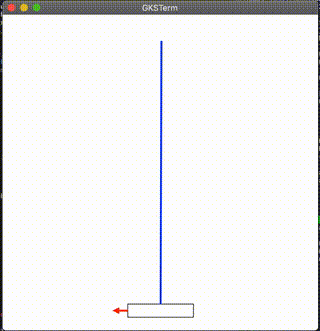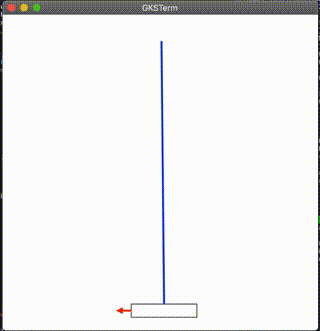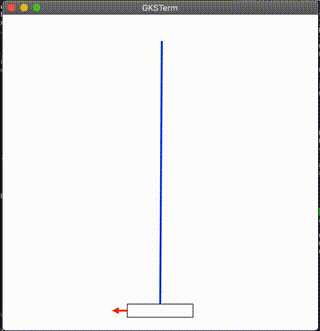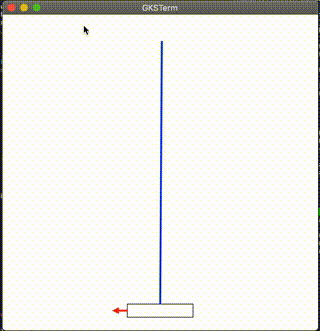
んん?ww
多分良くないのかな。わかんねえ
学ばなければ。