はじめに
この記事は、これまでに自分が学んできた知識をもとにデータを駆使する企業の段階を6つにわけた結果をまとめたものです。現時点での自分の思考整理が目的なので、後々更新される可能性があります。
企業におけるデータ活用のフェーズ
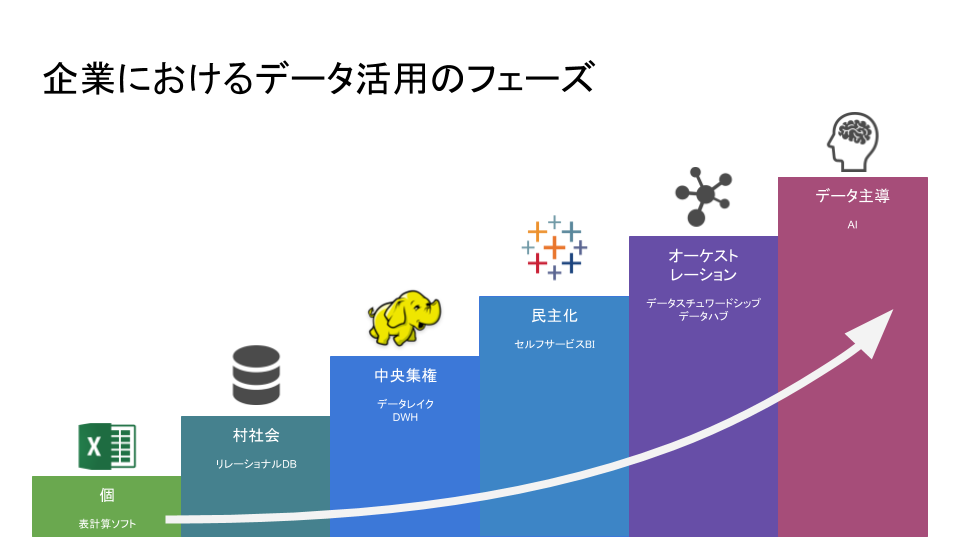
個
組織としてデータの活用をしておらず、個人が表計算ソフトなどを使用して、PCでデータを集計している段階です。KKDで意思決定をしているので全くデータをみない企業、データリテラシー以前にITリテラシーが低い企業はこの段階にいるでしょう。
この段階が次の段階に進むには、IT部門を設立する必要があるでしょう。もし、IT部門があるのにも関わらず、個の段階にいるのであれば、コーポレート部門とIT部門を橋渡しするための組織的な改善が必要かと思われます。基幹システム内にはデータが蓄積されているはずなので、適当な基幹システムが導入できていないか、コーポレート部門のITリテラシーが低いためにうまく活用できていない可能性があります。
村社会
特定の事業の中でのみデータ活用がなされサイロ化している段階です。この段階では、リレーショナルデータベースに必要なデータが蓄積されていることが多いです。
事業規模が小さいうちは全く問題ありませんが、事業規模が大きくなるに従って、リレーショナルデータベースのパフォーマンスが直接データ分析の性能限界になってしまう問題や、データが分断されているために事業横断でのシナジーを生めないという問題が起こります。
とはいえ、ニーズがないのに、最初からデータレイクを作るのは、過大な投資になってしまう恐れがあるため、オススメはしません。
中央集権
組織横断的なデータ活用のために、中央集権的なDWHやデータレイクが構築されている段階です。HadoopクラスタやAmazon Redshiftに多様なデータを大量に蓄積し、全量分析を行います。ビッグデータ活用と呼ばれるのは、この段階からでしょう。
この段階で、扱うデータの量と多様性が急激に増加し始め、データエンジニアやアナリストといったデータ関連の専門職が欲しくなります。
中央集権は、データが一元的に蓄積・管理される利便性があるものの、社内から依頼がデータエンジニアやアナリストに集約されるようになり、人手不足でデータ活用の速度が逆に低下する問題が起こります。人手不足を解消しようにも、データ関連の専門職は業界全体で大きく不足しています。AWS Redshiftといったクラウドサービスを利用し、必要なデータエンジニアを減らしたりするのも手ですが、データリテラシーを高める教育ができていないと、青天井にデータを蓄積したり、コンピューティングリソースを無駄に浪費してしまい、却ってお金がかかってしまうかもしれません。
民主化
セルフサービスBIツールなどを使用して、利用者がDWHやデータレイクを自前で利用できるようになっている段階です。中央集権における人手不足の問題が、利用者が参加することで改善されます。この段階では、社内でTableauやQlik、Power BIなどが普及しています。
しかし、人手不足の問題が解決する一方で、ガバナンスの問題が立ち上がります。利用者が個々にデータを生産するために、重要な意思決定の場で個人が試しに作ったデータが使われてしまったり、部署毎に同じ目的で異なる定義のデータが乱立してしまったりします。
誤ったデータによる意思決定は、データ活用によって得られる利益よりも大きな損害を生む恐れがあります。
オーケストレーション
エンタープライズデータガバナンスが導入され、データの発生から消費までのデータパイプラインのオーケストレーションが適切に行われるようになっている段階です。この段階になると、社外のデータ連携も、ある程度安全に行えるようになります。
データの重要性に応じて、データクオリティSLAが適切に定義され、エンタープライズデータハブが設計されたりします。データが事業の中核を担うようになるため、社内でのデータ活用のロードマップの重要性が増します。このため、データ活用を統括するChief Data Officer(CDO)オフィスの設立が検討されるようになります。
また、ここまでくると、データサイエンティストのような、データから新たな価値を創出するような研究者に近い人材が、より欲しくなります。(この段階に至っている時点で、十二分に経営層がデータの重要性を理解しているので、データサイエンティストは自前で抱えているはずですが。)
データ主導
機械学習などの技術により、人の業務の一部を学習した機械が代替する段階です。コンテンツフィルタリングが自動化されていたり、データディスカバリにより事業の課題点を自動的に可視化したり、履歴書の合否判断が自動化されたりと、データが事業の中に大きく組み込まれていきます。
この段階での問題は、データの活用をどこまで推進すべきかという倫理的な問題です。ビジネスにあまりに特化してしまい、倫理的な誤りを冒さないようEthical OSなどを参照し、倫理面からのガバナンスも進めるべきでしょう。
おわりに
この段階分けが正しいとは思っていませんが、こういった定義を自分でしておくことにより、より仕事を進めやすくなると思っています。もし、自分のこの拙いまとめが、他の方のインスピレーションに繋がればなお嬉しく思います。