1. はじめに
本記事は、ロボットにおけるトップカンファレンスであるRSS 2024 (Robotics: Science and Systems)で発表された「3D Diffusion Policy」の論文紹介記事だ。
本研究は、3D次元表現とDiffusion Policyを組み合わせた、視覚模倣学習に関する研究だ。
既存研究は2次元(画像)ベースの拡散モデルに焦点を当てていたのに対して、3次元(Point Cloud)に着目することで、以下の3つ特性を獲得している。
-
効率性と効果性
- 学習に必要なデモンストレーションの数を大幅に削減しつつ、高精度な動きを生成可能
-
高い汎化性能
- 3次元特性によって、空間、視点、外観など複数の面から汎化性能を獲得
-
安全性
- ベースラインであったDiffusion Policyでは予期しない動作を生成していたのに対して、提案手法は不規則な行動生成を行わない
本記事で使用している図は、下記の論文から引用している。
論文の詳細が気になる人は、プロジェクトページ→論文→GitHubの順番で見ることをおすすめする。
プロジェクトページ
論文(A)
2. 先行研究との比較
視覚的模倣学習
模倣学習は、ロボットが人間のようなスキルを取得するための効率的な手法だ。
当初は、ロボットの状態のみを用いたいたが、周辺の環境変化への耐性が低かった。
そのため、現在は画像などの視覚情報と組み合わせて行う方法が主流となっている。
3次元表現と拡散モデルを組み合わせた研究はなかったが、3次元表現とTransformerを組み合わせた研究(Peract, ACT3D, 3D Diffusier Actorなど)はあった。
しかし、これらの研究は (1)複雑なタスクに適していない点 や、(2)行動生成に時間がかかってしまう点が課題となってしまっていた。
ロボットにおける拡散モデル
拡散モデル(Diffusion Model)は生成AIの一種であり、高い表現力の持つ画像生成技術として成功した。
身近なサービスとしては、Stable Diffusionが当てはまる。
その表現力の高さから、近年ロボット工学分野においても利用されており、模倣学習や強化学習、Motion Planningなど応用先は多岐にわたる。
特に、Diffusion Policyを始めとした模倣学習手法が注目を集めている。
多くの研究は、主に画像とロボットの状態に焦点を当てているのに対して、本研究は3次元表現に着目している。
細かなスキル学習
ロボットで人間のようなスキルを実現することは、長年の研究テーマである。
強化学習や模倣学習を用いてこのテーマを研究しているはあるが、強化学習は複雑な報酬設計が、模倣学習は学習に必要なデモンストレーションの量が課題となっていた。
本研究では、最小限のデモンストレーションで複雑なスキルを習得することを、模倣学習アルゴリズ自体を改善し、この課題を解決している。
3. 技術や手法のキモ

上の図のように、ロボットを三人称視点で写したPoint Cloudを使用する。
取得したPoint Cloudから背景を切り取った後、FPS (Farthest Point Sampling)によって点群をダウンサンプリングし、データ量を減らす。
その後、3層のMLPを用いた特徴量抽出とLayer Normalizationを行う。
最終的にはロボットの状態(現在の各関節の角度など)と共に、Diffusion Policyの入力として使用されている。
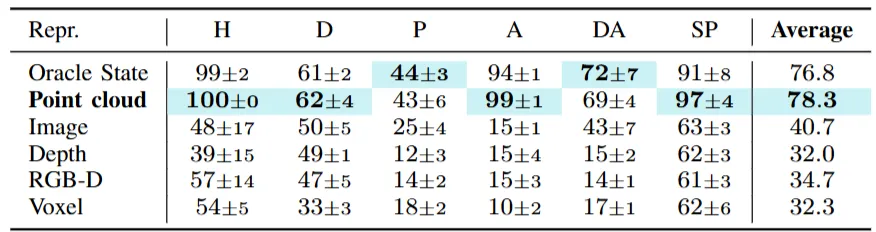
3次元表現手法の比較
まず最初に、本研究では以下の6つの3次元表現手法を比較している。
結果的には、Point Cloudが適していることが明らかになった。
- Oracle State:環境の完全な状態情報を直接取得できる理想的な状態表現(シミュレーション内)
- Point Cloud:物体や環境の3D座標点の集合で、センサー計測などに基づく表現
- Image:カメラで取得した2D画像情報
- Depth :各ピクセルの距離情報を持つ深度画像
- RGB-D:RGBカラー画像と深度情報を組み合わせたデータ
- Voxel:3D空間を格子状に分割した体積要素(ボクセル)による表現
特長量抽出手法の比較
Point Cloudの特徴量抽出手法として、提案手法を含む7つの手法の比較を行った。
結果としては、提案手法である3層のMLPからなるシンプルな抽出手法が最高精度となった。

MLPのような昔からある定番手法が、最新手法より優れてた要因としては、正規化手法による影響が大きい。
最新手法の多くがBatch Normalizationを使用しているのに対して、Diffusion Model内にあるEMAがBatch Normalizationに対応していないからだ。
そのため、Diffusion Modelを用いた研究では、Layer NormalizationやGroup Normalizationを用いたものが多い。
詳細が気になる人は、以下のブログでの解説を読んでみてほしい。

4. 検証方法
シミュレーター上での検証
シミュレータ上では72種類のタスクで評価を行った。
結果として、Diffusion Policyと比較した際、タスク成功率を24.2 %向上させた。
また、Diffusion Policyは学習の収束に3,000 Epoch必要だったのに対して、本研究は約500 Epochで収束が可能だ。


実世界での検証
実世界では(b)のように、Franka Armにロボットハンドを取り付けて行っている。
RGB-Dカメラとしては、Intel製のRealSense L515をロボットと作業場全体が映る場所に設置して行っている。



獲得した特性の詳細
汎化性能の高さは下図のように、対象物以外の物体が散らかっている中で、学習時とは異なる色・形状の物体対して同様の行動生成を行えるかで、評価を行っていた。
結果として、提案手法の成功率が最も高かった。

特に、物体の形状に関しては全く異なるジャンル・サイズに対しても有効なことが明らかとなった。

5. 議論
効率的なモデルアーキテクチャを開発したが、最適な3次元表現方法が発見できていない。
また、今回検証したタスクは比較的短時間のモノが多いため、より長期的なタスクに関しては検討の余地がある。
6. 次に読むべき論文
GenDP : 3D Semantic Fields for Category-Level Generalizable Diffusion Policy
拡散モデルと3次元表現に加えて、基盤モデルも組み合わせることで、より細かな動作生成を可能にしている。