はじめに
OpenAI Codex(以下 Codex)は、自然言語からコードを自動生成・補完するAIモデルで、いわゆる最近話題のコーディングエージェントである。本記事では、Codex(CLIではなくWeb版)の導入から簡単なサンプルまでを実践してみる。
公式サイト:
1. Codex とは?
Codex は、対話形式でAIに命令しながらコードをブラウザ上で作成できるコーディングエージェントである。
主な特徴
- 対話形式で生成・修正を繰り返せる
ある程度は実行確認しながら試行錯誤して通る成果物を生成してくれる - モデルはcodex-1(OpenAI o3)
- 型チェック、テストなどの自動実行
- 命名規則やフォーマッタ、テスト標準など、プロジェクト標準を指示可能(AGENTS.md(後述))
- ブランチ作成・更新・Pull Request作成をWeb上で実行
当然、ブランチ名やPR文はAIが生成してくれる
画面はこんな感じ

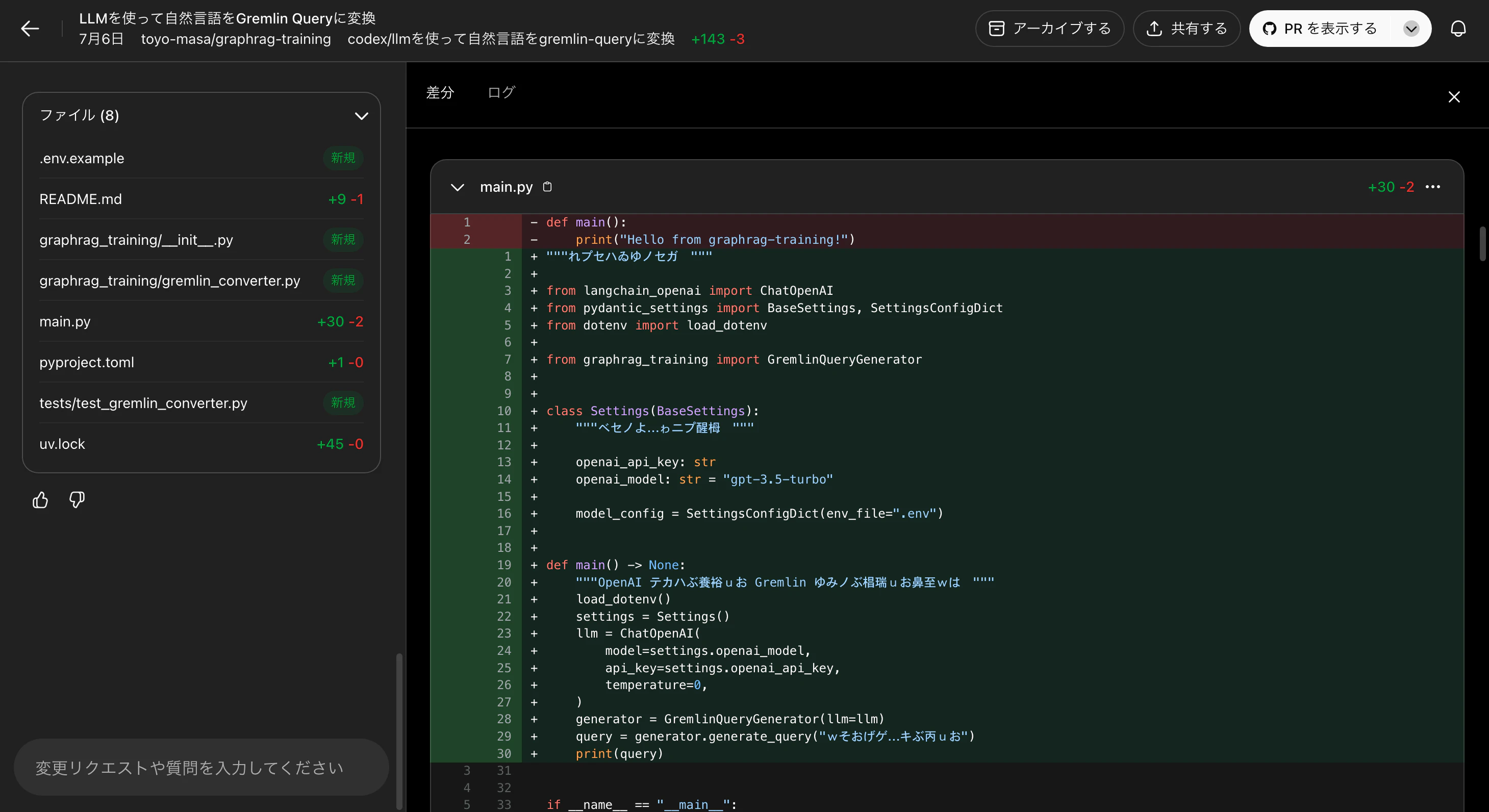
基本的には右の画面中心で、対話形式でAIに命令を出す。
2. 前提条件
- ChatGPT Plusアカウント
- GitHubアカウント
今回は、OpenAI APIを使ったのでコードを実行するなら
- OpenAI APIへの登録とAPI KEY
3. 環境構築
-
ブラウザで https://chatgpt.com/codex を開く
-
画面右上のメニューから「環境」→ 「環境を作成する」
-
GitHubのアカウントを選択(ない場合は、GitHubアカウントを追加する で追加)
-
設定画面で以下を入力
- GitHubアカウント
- リポジトリ
- 作成する環境の名前
- 作成する環境の説明
- コンテナイメージと言語バージョン(例: Python 3.12)を選択
- 今はデフォルトしか選択できないが、今後カスタムイメージを登録できるようになるかも
- 環境変数
- シークレット
- セットアップスクリプト
-
pip install等で必要ツールを記述 - 後の開発時にはリポジトリクローン後にセットアップスクリプトを実行してくれるので、ここでの実行確認は失敗するが、
pip install -r requirements.txtと書くことも可能
-
- エージェントのインターネットアクセス: ON にすると最新情報取得が可能(セキュリティ要検討)
- オフにしても環境構築(pip install ~~)だけはアクセスするようだ
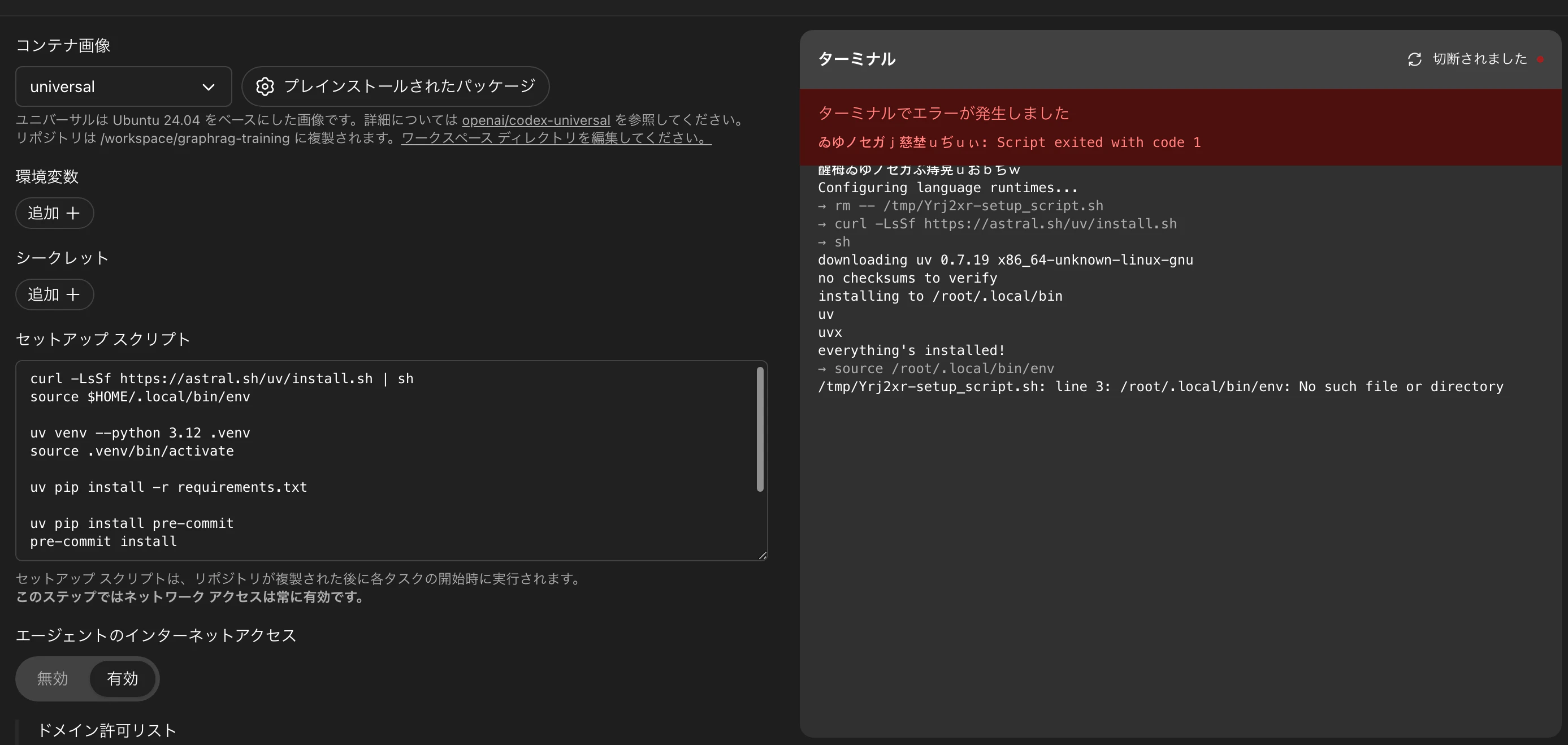
画面右側のターミナルで、コンテナ環境起動確認が可能。(画像は失敗している)
後の開発時には、ライブラリがなかったら勝手にインストールを始めるので、セットアッププロンプトに全部書かなくても詰まることはほとんどなかった。とはいえ、毎回AIが「ライブラリ読み込むで!😁」→「importエラー…?🧐」→「インストールしなきゃ!😤」→「実行!通った☺️」とやっていて毎回時間消費していたので、親切に指定した方がいい。
-
「環境を作成する」をクリックすると作成完了
上記で環境構築は終了。あとは最初のページで作成した環境と、Githubリポジトリ、ブランチを指定して指示を入力するだけ。
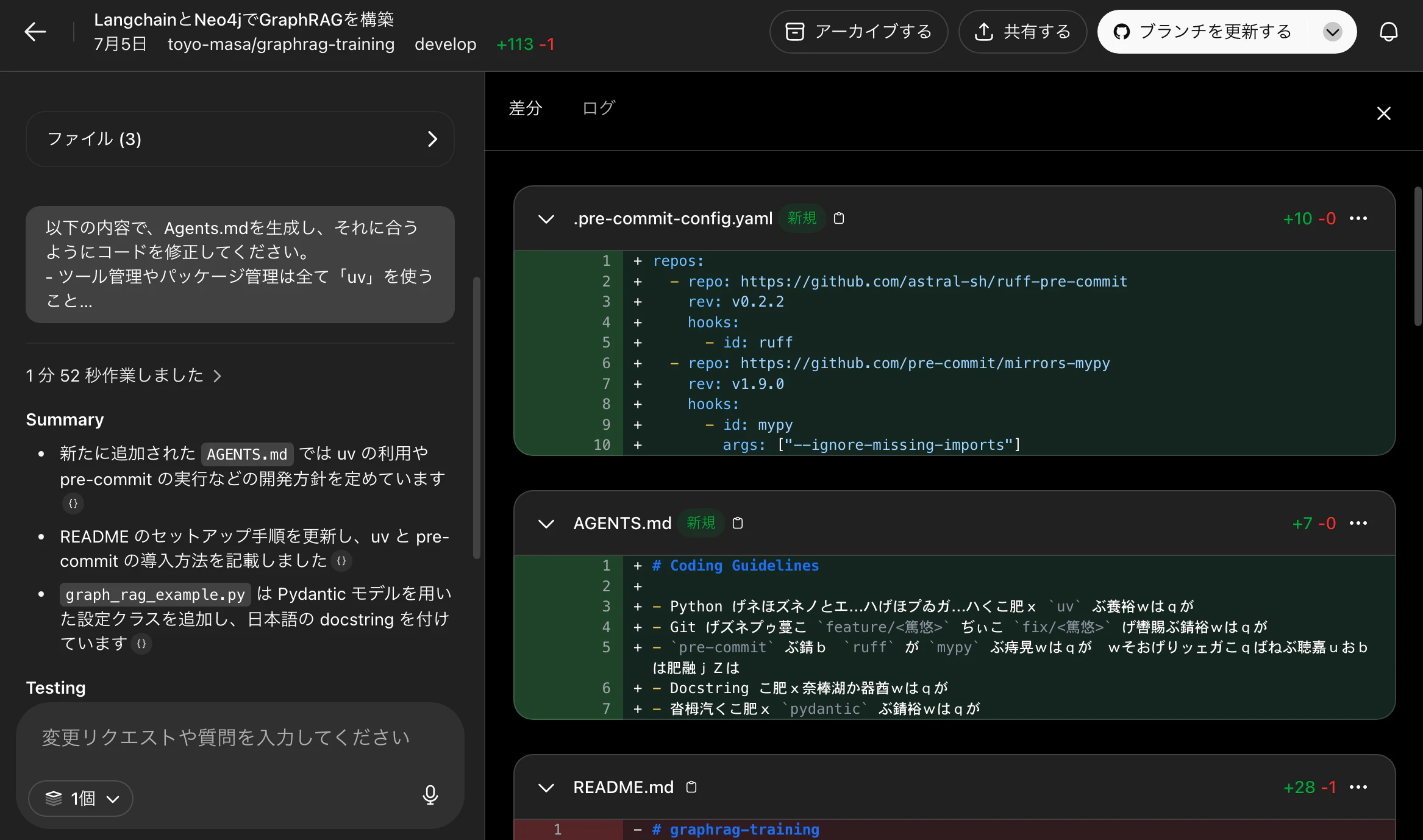
4. AGENTS.mdの設定
プロジェクトルートに AGENTS.md を配置すると、起動時に自動で読み込まれ、ガイドラインを適用できる。
例えば、普段の開発で以下のような面倒課題はないだろうか。
- 😇 変数・関数・クラス名命名規則を守ってくれない
- 😇 Docstringの記述が面倒
- 😇 pytestが通らない、そもそもテストコード作成が面倒
- 😇 pre-commitによる静的チェック実行が面倒
- 😇 pydanticによる型定義が面倒
- 😇 コミットメッセージ記述が面倒
などなど、日頃頭を悩ませる課題は多い。これらをAGENTS.mdに書けばAIはこれらを守った上でコーディングをしてくれる。(当然、100%守ってくれるわけではないが、それは人間も同じ。少なくとも筆者よりはAIの方が守ってくれている)
同じような仕組みは、最近出たコーディングエージェントはどれも備えているので、この機会にプロジェクトで明文化して是非楽をしよう。
以下に今回使用したAGENTS.mdを記載しておく。ガイドラインというよりAIへの指示も若干入っている。
# Coding Guidelines
- Python のライブラリインストールやツール実行には必ず `uv` を利用すること。
- `pip install`ではなく、`uv pip install`を使うこと。
- `pip list`ではなく、`uv pip list`を使うこと。
- `pre-commit run`ではなく、`uv run pre-commit run`を使うこと。
- `pre-commit` を使い、`black`、`ruff`、`mypy` を実行すること。すべてのコミットはこれらを通過している必要がある。
- Docstring は必ず日本語で記述すること。
- 型定義には必ず `pydantic` を使用すること。
- コミットメッセージ、プルリクエストは日本語で記載すること。
- クラス名は `PascalCase`、関数名と変数名は `snake_case` を用いること。
- 必ずテストコードを作成し、pytestを実施すること。テストは正常系と異常系の2つを用意すること。
ちなみに、これもAIと壁打ちしながら考えたので、「何のツール使えばいいか分からん」という人は、「コード品質上げたい!」とか「標準化したい!」とか雑な要望をAIに相談すればいいと思う。
5. 使ってみた
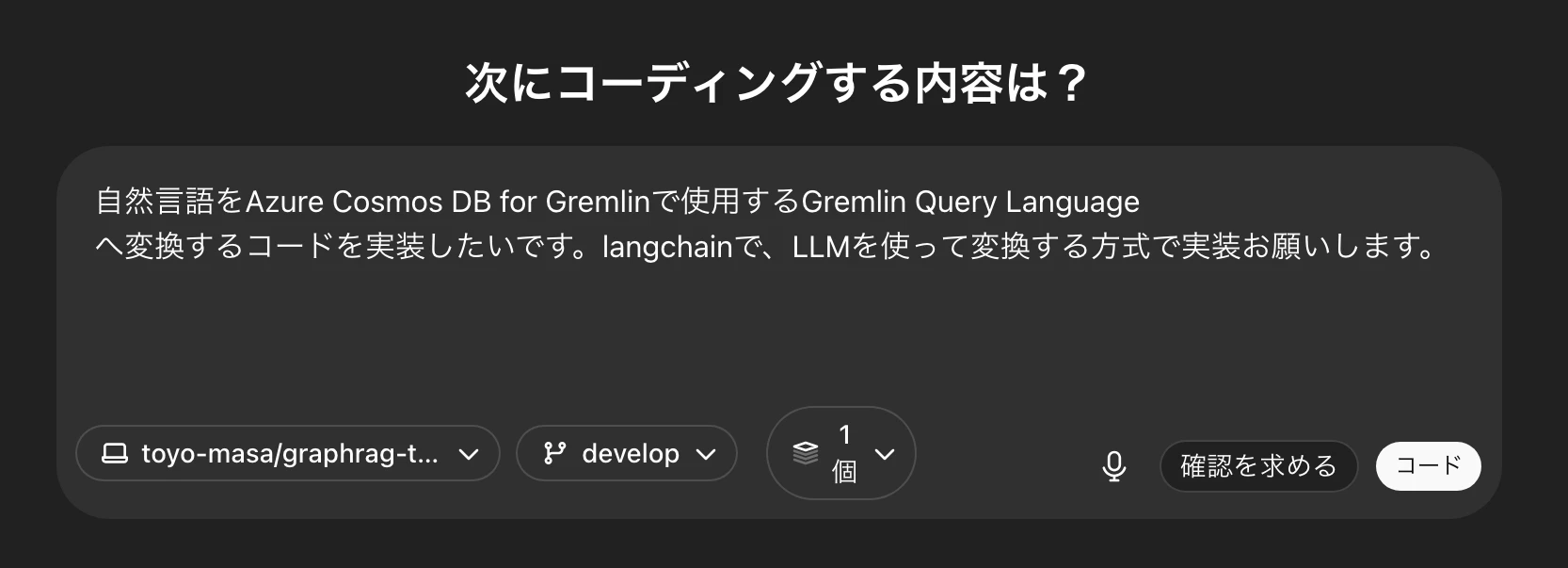
最近興味があったGraphRAG関連で、自然言語クエリからGremlin Query Languageへの変換の実装を依頼することにした。少し難しいかと思われたがチャレンジ。o4-mini-highで事前調査し、ライブラリだけ当たりをつけて、最初はざっくり依頼。インターネットアクセスはONにしている。
まずは以下のようにざっくり依頼。
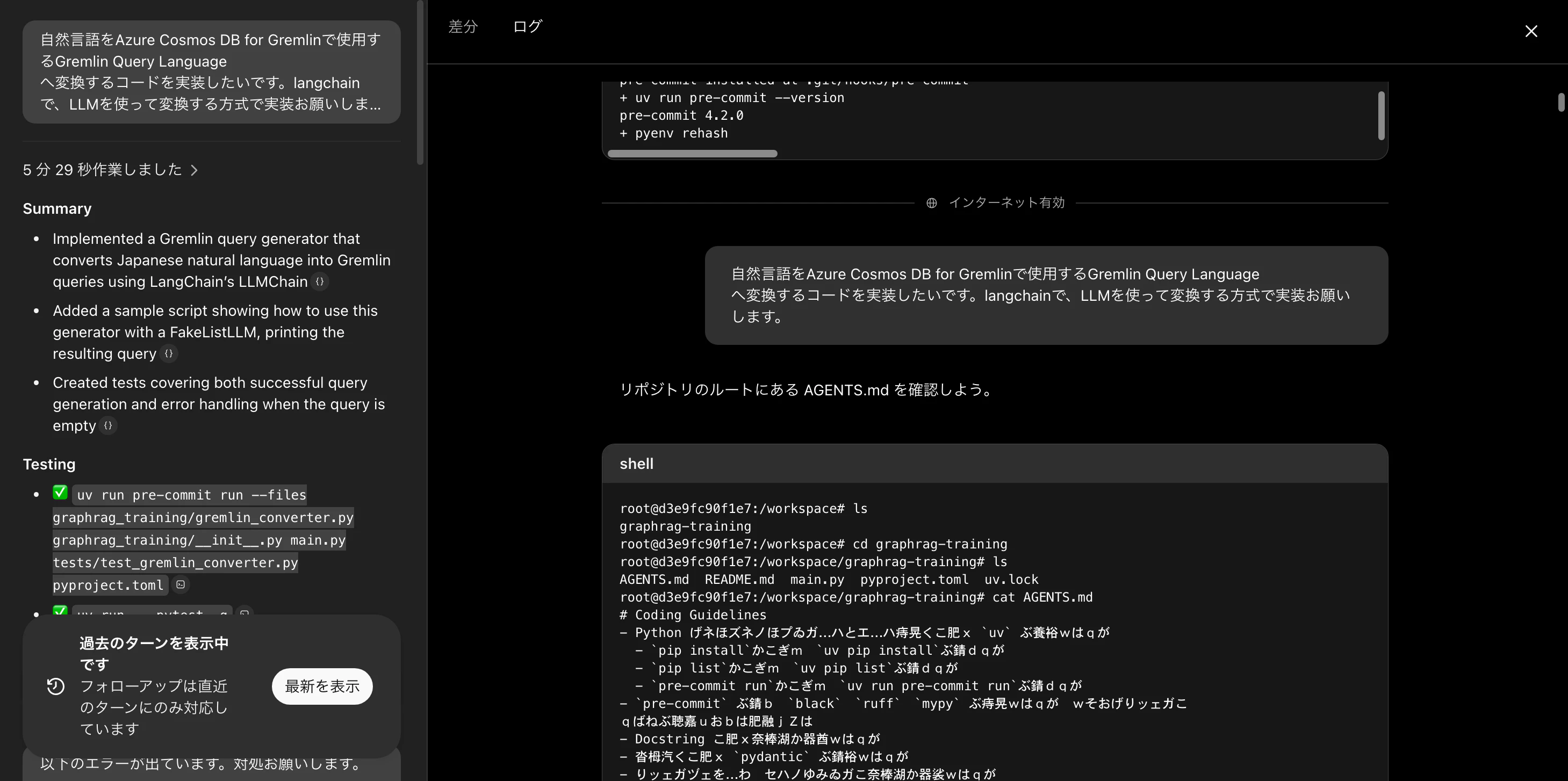
タスク欄をクリックし、生成が終了すると以下の画面に。よくあるコード差分の画面が表示される。

ログを表示すると、作業過程が確認できる。lsコマンドの実行、AGENTS.mdやuv.lockの読み込みやpytestの実行を試みていた。
画面右上の 「🐱PRを作成する」 を押すとしばらく後に 「🐱PRを表示する」 に。
「🐱PRを表示する」 をクリックすると Pull Requestsの画面に遷移
-
Pull Requestは自動で生成してくれる
-
プロンプト入力画面で設定した「develop」から「codex/llmを使って自然言語をgremlin-queryに変換」というブランチが切られていた
-
「概要」や「テスト結果」が記載してあった

※画像はMerge済みのもの -
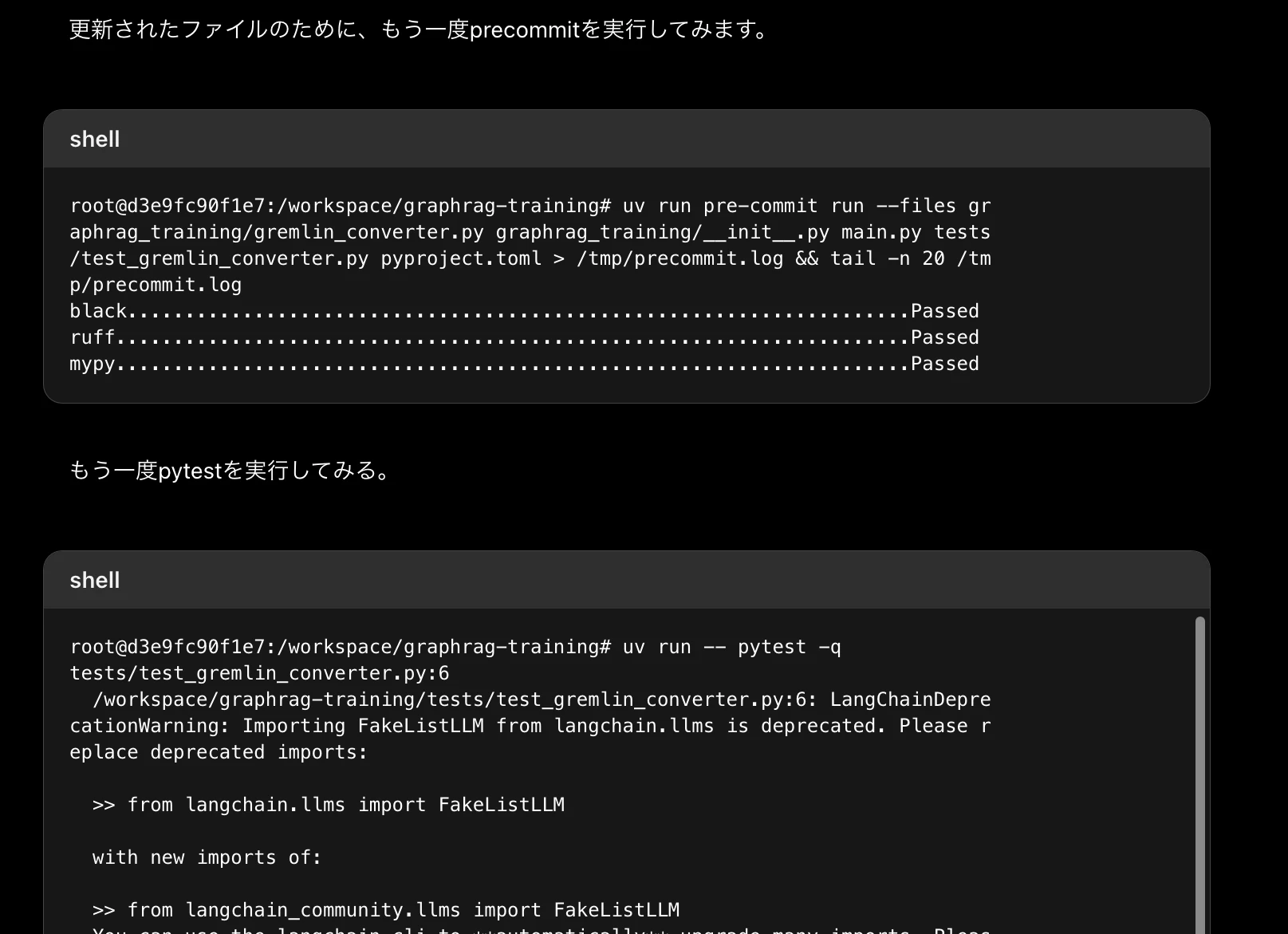
pre-commitとテストもしっかり実行していた。指示通りuvで実行できている。偉い。
ログを見ると実際に実行していることがわかる。(疑いました)
画面右上の 「🐱ブランチを更新する」 を押すとコミットが追加される。
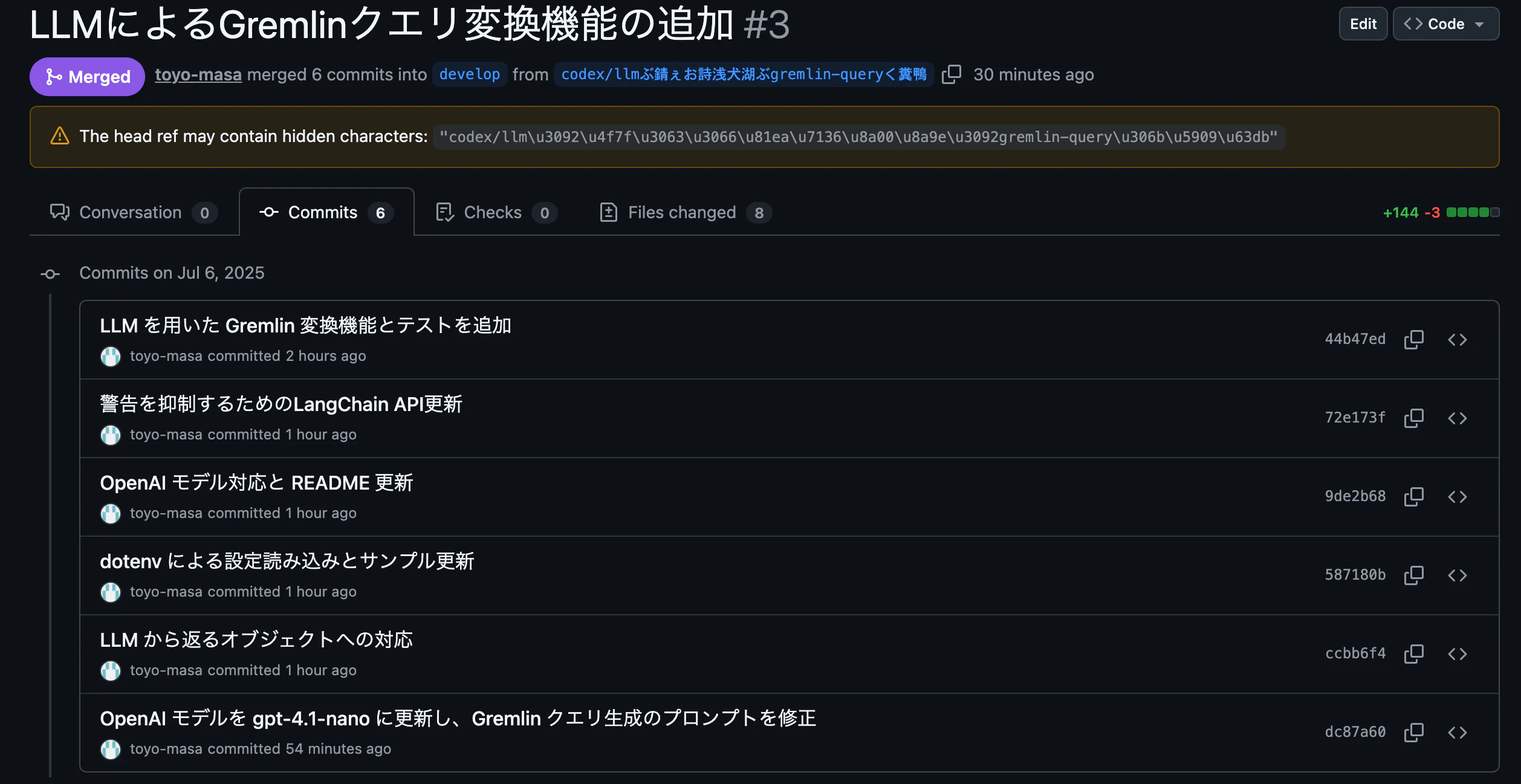
流石に一発で動くとはいかず、以下のように6回ほど試行錯誤して最終的には動作確認までできた。
プロンプトエンジニアリングを手伝った以外はスムーズだった。
以下、実際に生成されたコード。(ローカルで実行確認済み)
"""サンプルスクリプト。"""
from langchain_openai import ChatOpenAI
from pydantic_settings import BaseSettings, SettingsConfigDict
from dotenv import load_dotenv
from graphrag_training import GremlinQueryGenerator
class Settings(BaseSettings):
"""アプリケーション設定。"""
openai_api_key: str
openai_model: str = "gpt-4.1-nano"
model_config = SettingsConfigDict(env_file=".env")
def main() -> None:
"""OpenAI モデルを利用して Gremlin クエリを生成して表示する。"""
load_dotenv()
settings = Settings()
llm = ChatOpenAI(
model=settings.openai_model,
api_key=settings.openai_api_key,
temperature=0,
)
generator = GremlinQueryGenerator(llm=llm)
query = generator.generate_query("「東京に住む人の名前を取得してください」")
print(query)
if __name__ == "__main__":
main()
from __future__ import annotations
from langchain.prompts import PromptTemplate
from langchain_core.language_models import BaseLanguageModel
from pydantic import BaseModel
class GremlinQueryGenerator(BaseModel):
"""自然言語をGremlinクエリへ変換するクラス。"""
llm: BaseLanguageModel
def generate_query(self, text: str) -> str:
"""LLM を用いて Gremlin クエリを生成する。"""
prompt = PromptTemplate(
template="""
あなたは Azure Cosmos DB for Gremlin に対するクエリを作成するアシスタントです。
必ずGremlin Query Languageのみを返してください。クエリの説明や補足は不要です。
次の要求を Gremlin Query Language に変換してください。
{query}
""".strip(),
input_variables=["query"],
)
raw = (prompt | self.llm).invoke({"query": text})
result = raw.content.strip() if hasattr(raw, "content") else str(raw).strip()
if not result:
raise ValueError("生成された Gremlin クエリが空です")
return result
実行結果
g.V().hasLabel('person').has('city', '東京').values('name')
6. 所感
以下、個人的な所感を記載する。
- ✅良い: お手軽な環境構築、対話ベース、GitHub連携
- ❌微妙: ローカル実行との往復が発生し得る
結局、バグ解消には、リポジトリからクローン→こちらで実行確認しエラーを出す→Codex(Web)にコピペして修正依頼→リポジトリにプッシュ→…のループとなり、コピペが面倒だった。
7. 今後
せっかくなので、次はドキュメントをグラフ構造を生成するクエリに変換するコードをCodex CLIを使って書いてみて、Codex(Web)とCLIの使用感の比較をする。
8. 余談
途中でNeo4jに切り替えてやっていたら、とんでもないクラス名(Neo4j設定、まさかの漢字)になっていたので、そこも規則をAgents.mdに定めて従ってとお願いした。Neo4jSettingに修正はされていた。(学習データにそんなのあったの?)
class Neo4j設定(BaseSettings):
"""Neo4j 接続設定用のモデル。"""
url: str = "bolt://localhost:7687"
username: str = "neo4j"
password: str = "password"
index_name: str = "documents"
node_label: str = "Document"
embedding_property: str = "embedding"
class Config:
env_prefix = "NEO4J_"