JVMバイトコード入門
この記事は編纂中です。不定期で稀に更新されます。
Javaのバイトコードの解説だけで本が一冊書けるという事実に後になって気づいたため、筆者がこのページを最後まで書き切る可能性は稀です。ご了承ください。
目標
難読化ツールを自作できるようになる・難読化を解読できるようになる。
バイトコード操作ライブラリ「ASM」を使いこなす。
JVMバイトコードが読めると何が嬉しいのか
JVMバイトコードが読めると以下のようなことができます。
- 難読化ソフトウェアの開発を行うことができる。
- 逆に難読化の解除を行う。
- Java言語で書かれたマルウェアやチートソフトウェアを解析する。
- Javaプログラムを改竄して、任意の状態をプログラムから引き出す。
- 自作プログラムに簡単な独自難読化機構を組み込む。
特に「1. 難読化ソフトウェアの開発」は思ったより簡単で、Proguardにあるような基本的な機能であれば一人で数カ月間頑張ってれば難なく作れてしまう(個人差あります)ため、JVMバイトコードを読めるようになれば一人で起業して難読化ソフトウェアを売ったりするのも夢ではないのかなと思います。
また「5. 自作プログラムに簡単な独自難読化機構を組み込む」ことができるようになることで、自作のJavaプログラムがリバースエンジニアリングされづらくなります。GitHubに難読化を解除するようなツールが出回っておりJVMバイトコードの知識がなくても難読化解除ができるような状況下において、独自の難読化を追加することで既存ツールでの対応が不可能になり、専門家による解析が要求されるようになるため難読化を解除するのに必要なコストが格段に増加します。
プログラムの動作原理とコンパイルの意味
JVMの世界において、ある瞬間において実行されるプログラムの内容は「データ」と「命令」のみによって規定されます。
例えばList#sizeメソッドを呼び出す瞬間であれば、「sizeが呼び出されるListオブジェクトが(スタックの一番上に)データとして存在」し、かつその瞬間の命令は「(スタックの一番上にあるデータに対して)sizeという名前のメソッドを0個の引数を用いて実行する」ということになります。
スタックというのはデータを配置する置き場のようなもので、JVMの場合、命令が読み込むデータは常にこの「スタック」に保持されます。
またこのスタック以外にも「ヒープ」と呼ばれる領域にもデータは保持されますが、大容量のデータを保持できる一方スタックに比べて低速で、しかもヒープ領域のデータはJVMの命令を介して間接的にのみ読み込み・更新が行われるためバイトコードを触れていてもあまり意識する必要はないでしょう。
例えば配列をプログラムで扱う場合、配列の実体のデータはヒープに保持されますが、その配列への参照はスタック内に保持されます。JVMの各種命令においてその参照を渡してあげることで、JVMの命令経由でその配列に対して様々な操作を行うことが可能です。
スタックと命令
先程述べたように、JVMでは命令が読み込むデータは常に「スタック」に存在する訳ですが、具体的にスタックというのはどのような構造になっているのでしょうか?
分かりやすいように図を用いて説明すると、スタックは以下のようにデータを縦に並べたような構造になっています。
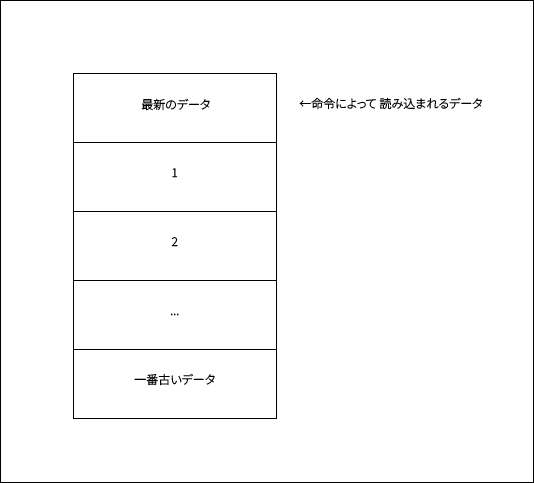
スタックに保持されるデータの数は命令によって増えたり減ったりしますが、その際必ずスタックの一番上のデータから読み込まれ、またスタックにデータが追加される際も、一番上にデータが追加されます。
この説明を聞いてまず疑問に思うことは、「それではスタックの一番下側にあるデータにアクセスしたい場合はどうすればいいのか?」ということでしょう。結論から言うと、JVMでは「ローカル変数」を用いてスタックのデータをヒープに格納することで、この問題を解決しています。
例えばint型のデータであれば、「ISTORE n」命令(nは任意の数値)でスタックの一番上にあるデータをn番目の変数に格納し、また「ILOAD n」を行うことでn番目の変数に格納されている変数をスタックの一番上に持ってくることができます。
なおJVMでの制約として、メソッドが呼び出された段階でのスタックを、呼び出されたメソッド側から変更することはできません。
(筆者メモ: 後でメソッドが呼び出されたときのスタックの構成を書く。)
JVM命令の例
以下のような例を考えてみます。
int i = 100 + 10 - 1;
この場合のJVM命令は以下のようになります。
BIPUSH 100
BIPUSH 10
IADD
ICONST_M1
ISUB
ISAVE 0
ではこの場合の例について、順を追って見ていきましょう。
1行目: BIPUSH 100
これは「100」という数字をスタックに載せるということを意味しています。
2行目: BIPUSH 10
2行目もBIPUSHですね。スタックマシンでは読み込まれたデータを上に積んでいくので、スタックマシンは上から「10」、「100」という順番で載っています。
3行目: IADD
3行目にはIADD命令が来ました。IADD命令は、スタックの一番上と二番目に上のintを加算して、計算結果をスタックの一番上に格納します。この際計算に使われた数値はスタックから取り除かれます。従ってスタックに載っていた「100」、「10」を加算すると「110」ですから、スタックには「110」という数値のみが残ることになります。
4行目: ICONST_M1
4行目にはICONST_M1が来ました。ICONST_M1は「-1」をスタックに載せるという意味です。BIPUSH命令はintをスタックに載せる命令ですからBIPUSHでいいんじゃないの?なぜ-1だけ別の命令があるの?と思うかもしれませんが、JVMは最適化のために数値を読み込む命令が複数あり、-1から5までの範囲ならICONST命令、byteの範囲ならBIPUSH、shortの範囲ならSIPUSH、intもしくはlongの範囲であればLDC命令を使います。ただ必ずしもBIPUSHを使わなければいけないというわけでもなく、「BIPUSH -1」などとしても正常に動作します。あくまでも最適化のためだけの命令というわけです。
5行目: ISUB
5行目にはISUBとありますが、これはIADDとほぼ同じで、スタックの二番目に上のintから一番上のintを減算して、スタックに載せます。従ってスタックに載っていた「-1」、「110」に対してISUB命令を行うとスタックには「109」が残ることになります。
6行目: ISAVE 0
次で最後です!ISAVE命令は、スタックの一番上にあるintをローカル変数に格納します。JVMバイトコードの世界ではローカル変数に名前はなく、0、1、・・・というように0からの連番で管理されています(デバッグ情報としてデコンパイラで見たときにローカル変数の名前を残すこともできる)。すなわち「ISAVE 0」は、この「メソッド内の0番目のローカル変数にintを格納する」という意味になります。ここで格納されたローカル変数は、ILOAD命令を呼び出すことでローカル変数からスタックに取り出すことができます。