強化学習について学んでいる大学4年生です。もう卒業です。
単純に、AIの力で儲けることができないかなと思って研究に着手しましたが、
金融関連だからか検索しても全然情報が出てこないんですよね...
そこで自分が今年行った研究「深層強化学習による投資戦略の獲得」
についてつらつら書き、どこかの誰かの参考になればと思います。
(学会等には出稿したことがありませんので悪しからず...論文を探しても出てきません。)
(お金儲けの研究と書きましたが、情報商材等ではありません。変なURLへの誘導もないので安心してご覧ください。)
今回は(1)ということで導入を、
(2)(3)以降で実際の理論やプログラムを説明していきたいと思います。
また今回投稿する内容は、授業等で学習したという訳ではなく全て独学で学んできた内容です。間違っているだろう箇所が随所に見受けられるかと思いますが温かい目で見ていただけたら幸いです。
よろしくお願いします。
強化学習(方策勾配法)ってなんぞ?
まず、強化学習について興味を持ったきっかけ「AlphaGo」について例に強化学習とは何か簡単に紹介します。
AlphaGo

ざっくり説明すると、(本当にざっくりです。専門家の方々すみません)

- 囲碁環境から、現在の盤面を取得
- その盤面を強化学習エージェントが読み込み
- 打てる手の確率分布を出力
- 確率分布から次の一手を確率的に決定
というのが盤面から打つ手を決定する一連の流れです。
打てる手の確率分布を出力
というのがミソで、今の盤面に応じて
次に打ったほうがいい、打ったら勝ちに近くなるような手は確率を高く、
打ったらピンチになってしまう手には確率を低くするような
"適切な"確率分布を出力することが目標です。
そうして、そんな強化学習エージェントの入出力を可能にしてくれるのが、
深層学習でおなじみ"ニューラルネットワーク"であり、
そのニューラルネットの出力する確率分布を"適切に"学習させるのが強化学習の役割になります。
だから二つ合わせて深層強化学習っていうんですね。
Alpha Goのここがすごい
AlphaGoもとい深層強化学習は
「現在の環境に応じて適切な確率分布を学習する」アルゴリズムと言えますが
このアルゴリズムのすごいことは
- 「"定石"と呼ばれる人が発見してきた知識を使わずに学習している」
- 「実時間内に収束している」
- 「人間を遥かに凌駕する強さである」
ことなんですよね、、、
人が何十年、何百年と勝負をしながら発見してきた知識がいとも容易く敗れ去ってしまうほど、
囲碁において強靭な力を発揮しているのがこの深層強化学習なのです。
株式投資への応用
深層強化学習の詳しい理論等々はとりあえず置いておいて
「現在の環境に応じて適切な確率分布を学習する」というアルゴリズムが株価にも使えるのでは?と考えました。
人は株式売買において、
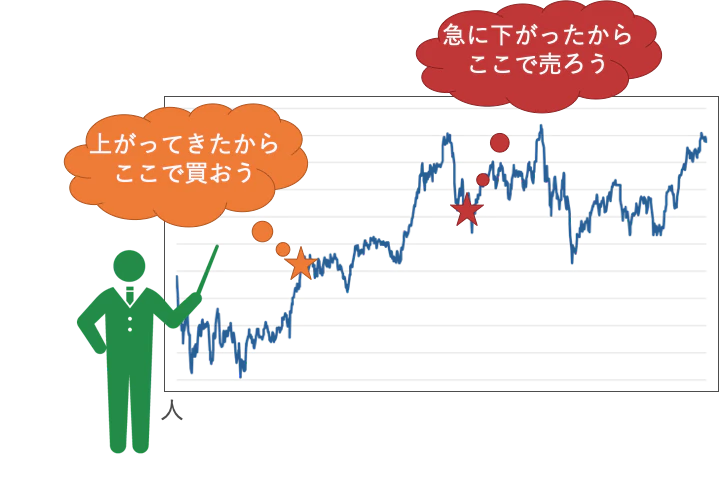
こんな風に過去から現在の値動きに応じて取引しますよね。
もちろん先々のことが分かっていないので失敗することもあります。
これを強化学習エージェントが、株価を読み取って
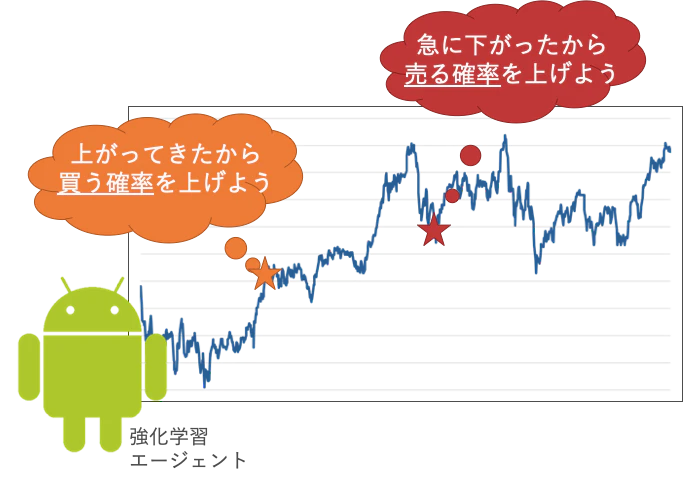
という風に、確率に変換して取引することは可能そうじゃないですか?
株価をピンポイントで当てなくても、次の時点での売買の確率を求めることが出来れば
お金を儲けることは十分に可能です。
従って

ということが、今回の目標であり、プログラムの中身でもあります。
結果について
結果が悪かったら読んでもらう意味がなくなってしまうので先に出しておきます。
しかし説明不足な点が大いにあることも承知しております。詳細な結果や手法に関しては後日投稿しますので、今はこの強化学習手法でも確率は収束し、人間を凌駕しているかどうかは置いておいて、ある程度の利益が出せるのかな?程度に考えていただければと思います。
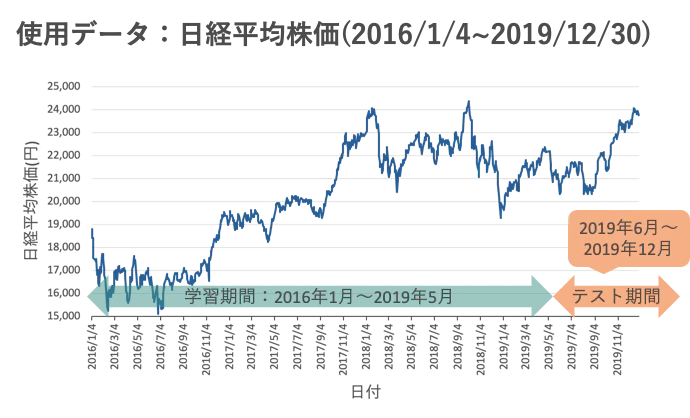
学習データ↓
学習の様子↓
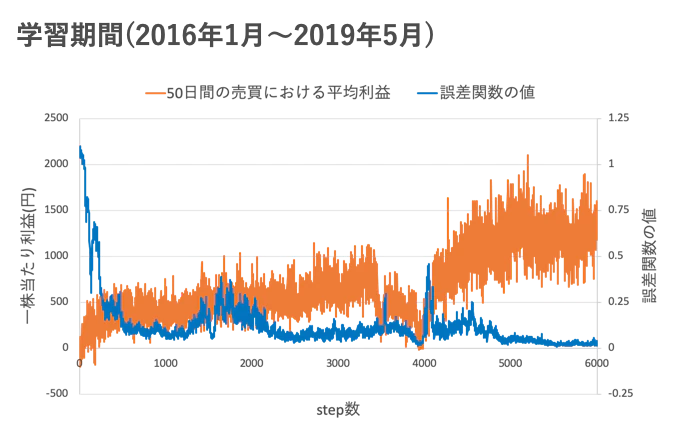
- 青色の線がニューラルネットワークの誤差関数の値です。
- 0に近づくほど確率が収束していることが分かります。
- オレンジ色の線が学習期間における50日間の間に得られた平均利益です。
step数を重ねるごとに平均利益が上昇していますね。
売買に関しては、
-
「買いポジションをとる」
-
「売りポジションをとる(空売り)」
-
「解消する、またはポジションを持たない」
の3つの出力を用意しており、1単位の日経平均株価を必ず購入(売却)出来る前提のもと、1単位を買ったり売ったりさせている状況です。 -
具体的な出力の設計
-
ニューラルネットワークそのものの構造
-
売買ルール
-
強化学習アルゴリズム
-
実際のプログラム
-
詳細な結果(テスト期間の結果を含む)
に関しては後日投稿していきたいと思います。
長い投稿になるかもしれませんが、どうかお付き合いください。
よろしくお願いします。