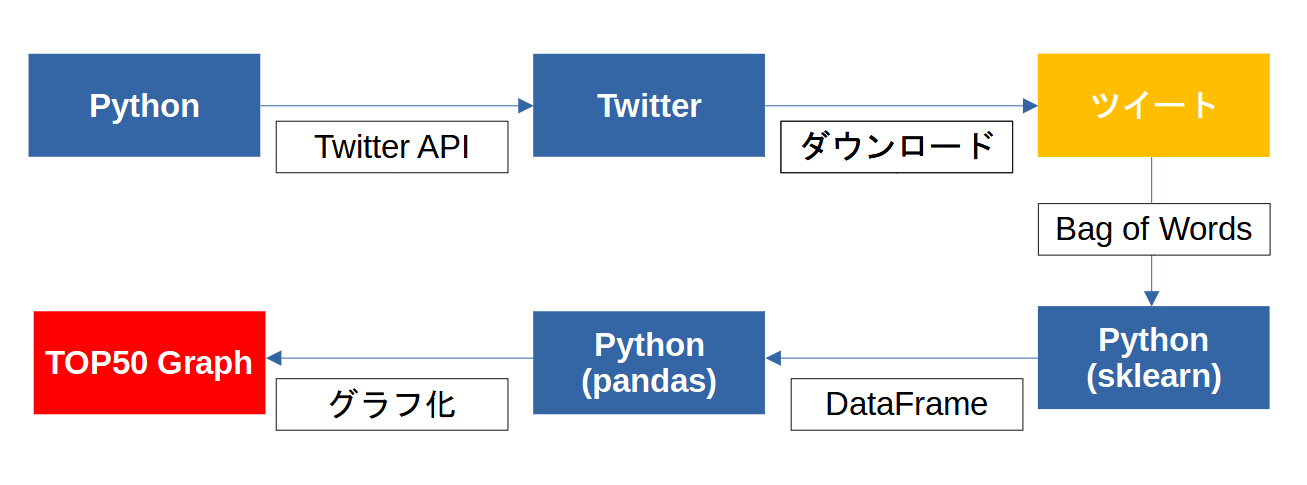
内容
機械学習の勉強で下記のような仕組みを作成してみました。
Twitter APIを使用して指定したキーワードのツイートをダウンロードします。
ダウンロードしたツイートをBag of Words(BoW)を使用して自然言語処理を実施します。
処理した内容からPandasのDataFrameを使用してキーワードTOP50のグラフを作成します。
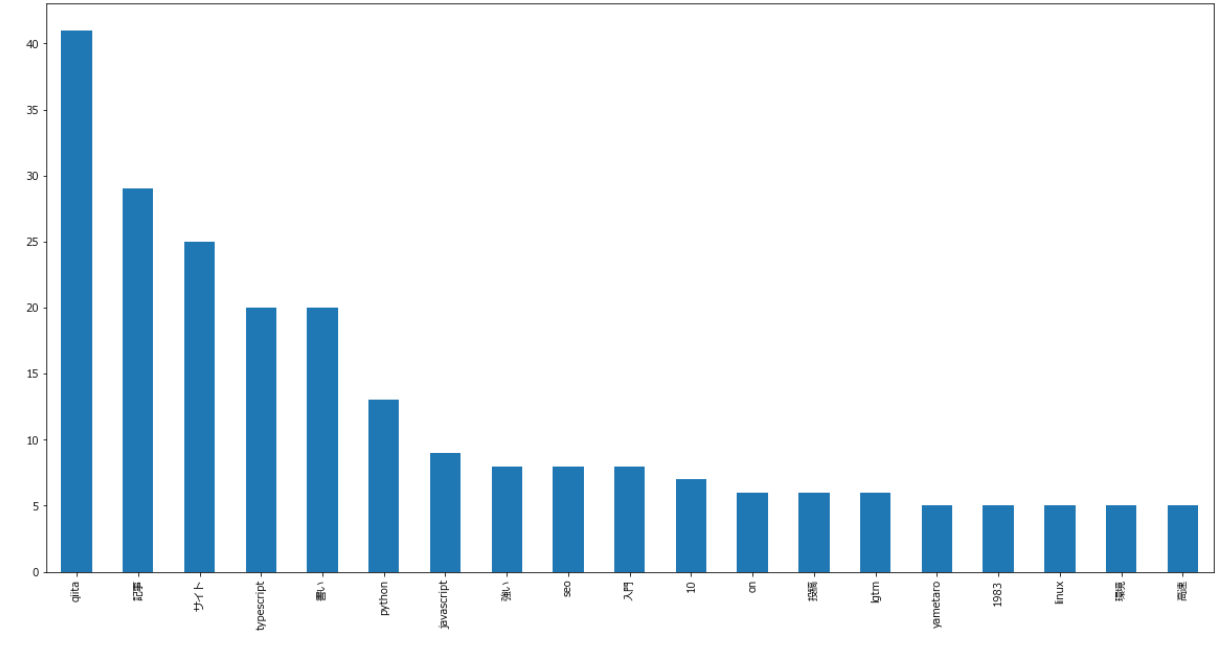
キーワードをQiita、取得ツイート数を1000に設定して取得したグラフが下記になります。
Bag of Words(BoW)
文章を単語に分割して、出現するボキャブラリの一覧を構築。各ボキャブラリが現れる回数をカウントします。
例えば「It is sunny today. How about tomorrow」という文章を下記のように単語に分割します。
「"It" "is" "sunny" "today" "How" "about" "tomorrow"」
日本語は英語のようにスペース区切りでないのでMeCabという形態素解析を使用して単語分割を行います。
例) 私は千葉に住んでいます → "私" "は" "千葉" "に" "住ん" "で" "い" "ます"
ストップワード
分析の役に立たない単語を取り除く手法です。上記だと"で" "い" "ます"など。
ストップワードのリストを作っておいて該当の単語を除外します。
Twitter API
プログラムからツイートを取得するのに必要です。
TwitterにDeveloperアカウントを申請するとAPIキーやAPIシークレットが払い出されますので
これを使用してTwiiterにアクセス可能です。
手順
モジュールダウンロード
pip install tweepy
pip install mecab-python3
MeCab設定
-
MeCabインストール
最新版をダウンロードしてインストールします。インストール時に「UTF-8」を選択します。 -
環境変数に追加
Windowsの場合MeCabの実行ディレクトリを追加します。(例)C:\Program Files\MeCab\bin
ツイートダウンロード
- API_KEYなどを入力します。
- countはダウンロードするツイートの数、keywordにキーワードを入力します。
- data/配下に日付のファルダが作成されその中にツイートがダウンロードされます。
import datetime
import os
import tweepy
# Create directory for tweet data
dt_now = datetime.datetime.now().strftime('%Y%m%d_%H%M%S')
tweet_dir = 'data/' + dt_now
os.makedirs(tweet_dir, exist_ok=True)
# Authentication to twitter api
API_KEY = 'xxxxxxxxxxxxx'
API_SECRET = 'xxxxxxxxxxxxx'
ACCESS_TOKEN = 'xxxxxxxxxxxxx'
ACCESS_TOKEN_SECRET = 'xxxxxxxxxxxxx'
auth = tweepy.OAuthHandler(API_KEY, API_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET)
# Get tweet data from twitter api
api = tweepy.API(auth)
## Number of acquisitions
count = 1000
keyword = 'Qiita'
for tweet, count in zip(tweepy.Cursor(api.search_tweets, q = keyword).items(count), range(count)):
with open(tweet_dir + '/' + str(count) + '.txt', 'a', encoding='utf-8') as f:
f.write(tweet.text)
BoW処理~グラフ作成
- tweet_data_folderに分析対象のフォルダを指定します。
- countにツイート数を入力します。(ツイートダウンロードで指定した数です。)
import numpy as np
import pandas as pd
import matplotlib
from sklearn.feature_extraction.text import CountVectorizer
import MeCab
tweet_data_folder = '20220528_140110'
count = 1000
# Insert text data to List
tweet_list = []
for i in range(count):
with open('data/' + tweet_data_folder + '/' + str(i) + '.txt', 'r',encoding='utf-8') as f:
data = f.read()
tweet_list.append(data)
# Create stop words list
path = "stop_words.txt"
stop_words = []
for w in open(path, "r", encoding='utf-8'):
w = w.replace('\n','')
if len(w) > 0:
stop_words.append(w)
# Word splitting using mecab
mecab = MeCab.Tagger("-Owakati")
mecab_text = [mecab.parse(text).strip() for text in tweet_list]
vect = CountVectorizer(min_df = 5, stop_words=stop_words)
vect.fit(mecab_text)
result = vect.fit_transform(mecab_text).toarray()
# Create Dataframe of TOP 50
df = pd.DataFrame(np.sum(result, axis=0),
columns = ['count'], index = vect.get_feature_names())
df_sort = df.sort_values('count', ascending=False).head(50)
# Create Graph of TOP
font = {'family' : 'Meiryo'}
matplotlib.rc('font', **font)
df_sort.plot(kind='bar',legend=False, figsize=(20, 10))