(An English translation is available here.)
TL;DR
Stack Overflowは、ユーザーから信用を得るために、ユーザーの活動から収集した個人的な情報を開示しています(Personalized Prediction Data)。それをダウンロードして見てみたところ、{技術関連のタグ : 値}というkey-value pairがあり、その値の大きさは、私の各技術領域を数値化したものとして納得できるような内容になっていました。Stack Overflowは現時点の私の技術領域をよく分かっているようであると思いました。
前置き
アメリカではあなたはテレビを見る(watch)。
ソビエトロシアでは、テレビがあなたを監視(watch)する!
In America, you watch television.
In Soviet Russia, television watches you!
この引用は、ロシア的倒置法というものです。
ソビエトは崩壊しましたが、現代では、FacebookなどのWebサービスを利用する際は、我々がコンテンツをwatchすると同時に、企業も我々をwatchしているかのようです。
企業がユーザーの個人情報を収集する際には、例えば「収集する情報のカテゴリ」「収集した情報の使用目的」などをユーザーに周知しています。これは(少なくとも日本では)個人情報保護法に基づく措置として必要になるためです。
また、単なる法律の話だけではなく、ユーザーに信用してもらうためにも、情報収集の周知は必要になります。この「信用」を得るために、収集した情報を開示してしまおう、という企業があります。開示してしまえば、どのような情報を持っているかが一目瞭然になるためです。
Stack Overflowは、Personalized Prediction Dataをユーザーに開示しています。ユーザーはこれをダウンロードして、どんな情報を持っているのか見てみることができます。この記事は、Personalized Prediction Dataの中身をのぞいてみた、というものです。
Personalized Prediction Dataのダウンロード・分析
ダウンロードするためには、Stack Exchangeにログインした上で、Personalized Prediction Dataのページにある"Start download"という青いボタンをクリックします。なお、Stack Exchangeにログインしていないと、個人的な情報に関する箇所がnullで埋められたファイルになります。
ダウンロードしたファイルは、以下の構成のJSONファイルになります。(私の場合はこうでしたが、ユーザーごとに一部異なるかもしれません。)
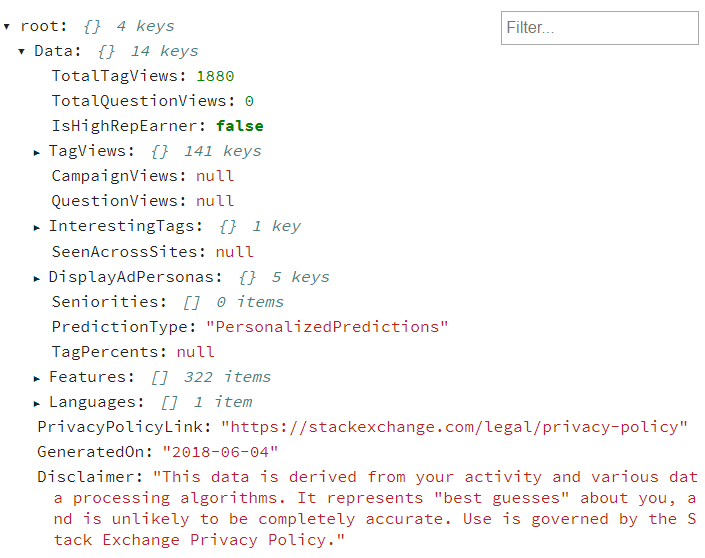
構成についてのドキュメンテーションがないので、推測で色々なデータを見てみました。
特に面白いと思ったのは、root/Data/TagViewsに入っている{ tag: value }形式のデータです。これは、Stack Overflowのtagとそのtagに対する値が入ったkey-value pairであり、例えば、
TagViews : {
c++: 440,
javascript: 183,
...
}
などと入っています。トップ20についてグラフを作成すると、次のようになりました。
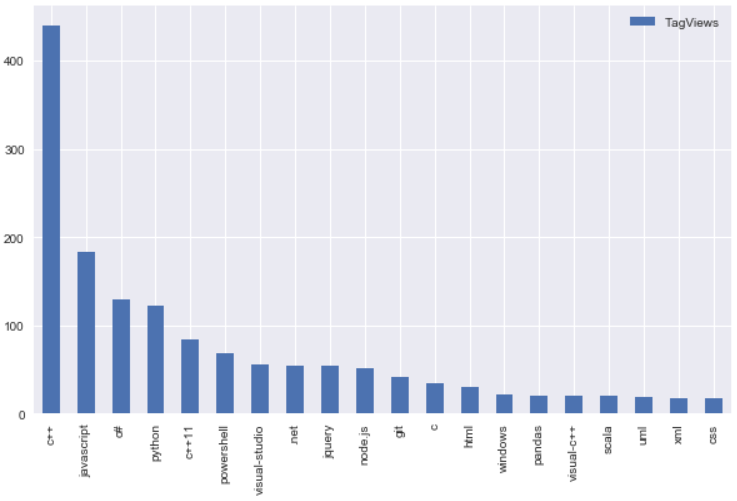
この傾向は、私の感覚に合致しています。Stack Overflowは、現時点の私の技術領域を良く分かっているようです。
詳細は、GitHubのrepositoryにJupyter notebookを置いたので、それを見てみると良いと思います。
下のバッジをクリックすると、Binderで実行できます。

おわりに
他の企業も収集した情報を開示してくれれば面白いのに、と思いました。