新生活応援期間中とのことですので,"pandas"の使い方,特に日付フォーマットについて取り上げたいと思います.「Pythonはデータ分析に強い」という評判がありますが,これは以下のような「定番」パッケージによって実現されています.
- "pandas" for representing and analyzing data
- "NumPy" for basic numeriacal computation
- "SciPy" for scientific computation including statistics
- "StatsModels" for regression and other statistical analysis
- "matplotlib" for visualization
(以上,"Think Stats" より引用.)
pandas は,Seriesオブジェクト(1次元のデータ構造),DataFrameオブジェクト(2次元のデータ構造)を操作するためのパッケージで,元々,株価等の経済データを取り扱うのに必要な機能をサポートしています.いわゆる時系列データに強いライブラリと言えます.
ただ実際に出回っている時系列データを見てみると,日付の欄に"2016-03-28"と標準的なフォーマットで入っているケースもありますが,中には"28-Mar-16"のように扱いが難しいケースもあります.本記事では,様々な日付の対応方法について確認していきたいと思います.
(プログラミング環境は,Python 2.7.11 + Jupyter + IPython kernel と Python 3.5.1 + Jupyter + IPython kernel, pandas 0.18.0 です.)
できるだけデータを入力するときに日付を変換する
ここでは,時系列データをCSV(comma separated values)ファイルで読み込む場合を想定します.時系列データの分析作業では,時刻,日付をデータ構造のインデックスとすることになると思います.pandasでは,以下のようにread_csv()を使います.
次のようなCSVファイルを入力したいとき,
Date,Open,High,Low,Close
2014/12/31,17702.11914,17713.75977,17450.76953,17450.76953
2014/12/30,17702.11914,17713.75977,17450.76953,17450.76953
2014/12/29,17914.55078,17914.55078,17525.66016,17729.83984
2014/12/26,17778.91016,17843.73047,17769.00977,17818.96094
. . .
(略)
以下のようなコードを用いると,
df1 = pd.read_csv('./pandas_date_ex/example1.csv', index_col='Date', parse_dates='Date')
df1.head() # for check
df1に入力された内容は,以下のようになります.
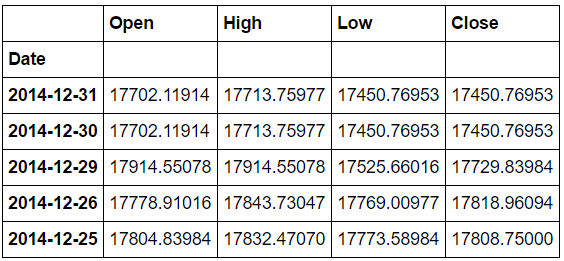
ここで確認しておく点は,一番左端の"Date"が文字列タイプでなく,数値としてDateを扱うためのTimestampタイプでなければならないということです.(分析作業の流れで,補間や回帰分析などを行う上で「文字列」のインデックスは使いたくありません.)
>>> type(df1.index[0])
pandas.tslib.Timestamp
上記のように日付がきちんとPandas.Timestampタイプに変換されていることが分かります.これはread_csv()で指定した以下のオプションが正しく機能したためです.
- index_col='Date' : 'Date'カラムをDataFrameのインデックスとする.
- parse_dates='Date' : 'Date'カラムを走査してDatetimeに変換する.
以上,標準的な日付データフォーマット(ex. '2014-12-31')ではうまく行きました.
少し難しそうな日付フォーマットの状況
次に以下のような"example2.csv"を扱います.まず,内容確認のため,オプションをつけずに,ファイル入力します.
df20 = pd.read_csv('./pandas_date_ex/example2.csv')
df20.head()
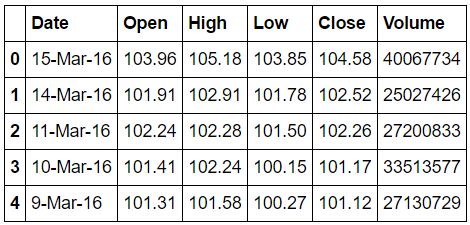
この時点では,'Date' はインデックス化されず,また変数タイプも文字列(str)のままです.このように今回は '15-Mar-16' のようにやや解読が難しそうです.この例を含めて,世の中にはいろいろな日付フォーマットがあるので,対応を考えておく必要がありそうです.
日付表記のいろいろなケース
- 年,月,日の順番が変わるケース.
- 月,日が1桁の数字になるとき,ゼロ埋めして桁数を2桁にしている,or 1桁で表示している.
- 年の表示が4桁,または下2桁.
- 月が数字表記,英字(3文字の略称)のケース
では,先ほどの"example1.csv”で使ったやり方を"example2.csv"に試してみます.オプションのつけ方を少し変えますが,これはカラムの指定をカラム名('Date')からカラム番号(=0)にしただけです.
df2 = pd.read_csv('./pandas_date_ex/example2.csv', index_col=0, parse_dates=0)
df2.head()
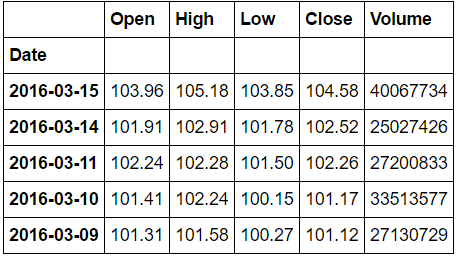
日付の解釈が難しいと思いましたが,予想外にうまく行きました.pandas.read_csv()で使用される日付パーサは,かなり優秀であるように見えます.
実は,日付の変換がうまく行かない場合を予想して,以下のようなコードを用意していました.(... Q&Aサイト/ stackoverflow を参照して作成したものです.)
f2 = '%d-%b-%y'
my_parser = lambda date: pd.datetime.strptime(date, f2)
df21 = pd.read_csv('example2.csv', index_col=0, parse_dates=0,
date_parser=my_parser)
自前でパーサを用意して,read_csv()でそれを使わせるというやり方です.しかし今回は上のやり方でうまく行ったので,このコードの出番はありませんでした.
日本語を含む日付フォーマットは?
あまり多くないと思いますが,日本語を含む日付フォーマットについて調べてみたいと思います.これまでと同じやり方を試してみます.
df31 = pd.read_csv('./pandas_date_ex/example3.csv', index_col='Date', parse_dates='Date')
df31.head()
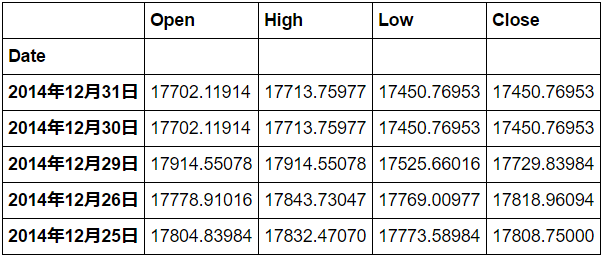
インデックス化はできているようですが,Date欄に日本語が含まれています.
>>> type(df31.index[0])
str
やはり,'Date'カラムは文字列タイプのままでした.つまり,read_csv() で指定した parse_datesオプションが機能していないということです.(例外を発生させて作業を中断する仕様ではないようです.)
このケースでは,やはり自前のパーサが必要になります.
f3 = '%Y年%m月%d日'
my_parser = lambda date: pd.datetime.strptime(date, f3)
df3 = pd.read_csv('./pandas_date_ex/example3.csv', index_col=0, parse_dates=0,
date_parser=my_parser)
df3.head()
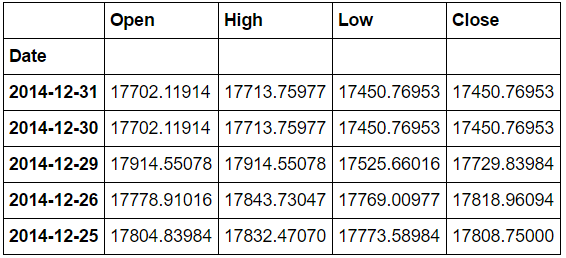
うまく行きました.最後に,このデータ(の一部)をプロットしてみます.
df3[['High', 'Low']].plot(figsize=(8,4), grid=True)
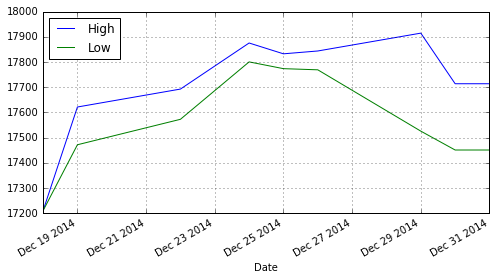
問題なさそうです.(pandasのプロット機能は,matplotlibのライブラリのwrapperとなっていますで,上図のような体裁になります.)
以上のように,pandasのread_csv()における日付パーサは,かなり広範囲に対応できるようです.また,「年」「月」など日本語を含む日付のような特殊な場合は,自前のパーサを用意することで,対応できることが分かりました.(応用として日本の元号付きの年を西暦に変換する,ということもパーサを書けばできるはずです.)
また,自前パーサでは読み取りフォーマットの指定が必要ですが,これはC言語のstrftime() の仕様に準拠しているとのことです.
(参照: https://docs.python.org/3/library/datetime.html#strftime-and-strptime-behavior )
詳細はドキュメントを確認いただくとして,よく使いそうな日付フォーマットを抜粋しておきます.(ディレクティブは大文字/小文字で役割が変わります.)
| ディレクティブ | 意味 | 例 |
|---|---|---|
| %d | 0埋め(zero padding)した10進数で表記した月中の日にち. | 01, 02, ..., 31 |
| %b | ロケールの月名を短縮形で表示します. | Jan, Feb, ..., Dec (en_US); Jan, Feb, ..., Dez (de_DE) |
| %B | ロケールの月名を表示します. | January, February, ..., |
| %m | 0埋めした10進数で表記した月. | 01, 02, ..., 12 |
| %y | 0埋めした10進数で表記した世紀あり(2桁)の年. | 00, 01, ..., 99 |
| %Y | 西暦 ( 4桁) の 10 進表記を表します. | 2011, 2012, 2013, ... |
少し細かいところに入ってしまいましたが,pandasは非常に多機能で,時系列データに限らず,いろいろなところで使われています.まずデータをpandasを使って前処理をして,整形されたデータを機械学習やDeep Learningフレームワークへの入力する作業フローもよく行われていると思います.
(日付関係クラスの理解についておことわり)
Pythonで扱う日付関係のクラスで,よく出てくるものに以下があります.
- datetime.datetimeクラス
- numpy.datetime64クラス
- pandas.Timestampクラス
私の貧しい理解で,これら3種類のクラス(特にdatetime.datetimeとpandas.Timestamp)の実態はほぼ同じものとして,本記事を書きました.しかし厳密に考えた場合,同じではないかも知れません.(記事で載せたコードの動きに影響はないと思いますが,間違い,不正確な記述がありましたら記事を訂正していきたいと考えています.ご指摘等,ありましたらお願いします.)
参考文献 (website)
- Think Stats 2nd Edition - O'reilly Media
- Python for Data Analysis - O'reilly Media
- pandas documentation (0.18.0)
http://pandas.pydata.org/pandas-docs/stable/ - Python 3 documentation - 8.1 datetime
https://docs.python.org/3/library/datetime.html - Can pandas automatically recognize dates? - stackoverflow
http://stackoverflow.com/questions/17465045/can-pandas-automatically-recognize-dates - Converting between datetime, Timestamp and datetime64 - stackoverflow
http://stackoverflow.com/questions/13703720/converting-between-datetime-timestamp-and-datetime64