はじめに
データ分析でデータを与えられて最初に行うこととして,概略の内容把握がある.データを表の形にして,特徴量は何か,データのタイプは何かを理解しようとする.これと同時に行う作業が,欠損値についての調査である.データ欠損の有無は,データ操作に影響を及ぼすのでまず有無を確認し,さらに欠損値の頻度をみる.本記事では,この作業について,PythonとRでどのように行うかについて確認していく.
(プログラミング環境は,Jupyter Notebook + Python 3.5.2 および Jupyter Notebook + IRkernel (R 3.2.3) になります.)
Pythonでのデータ欠損状況確認
データセットとして,Kaggleが提供する"Titanic"を用いることとした.データを見た方も多いと思われるが,これは,乗客の特徴量から「生存した」/「生存できなかった」を分類するものである.後述のように,欠損値が含まれているデータセットである.
まず,Pythonでpandas DataFrameにデータを読み込む.
def load_data(fn1='./data/train.csv', fn2='./data/test.csv'):
train = pd.read_csv(fn1)
test = pd.read_csv(fn2)
return train, test
train, test = load_data()
train.head()
train.csv
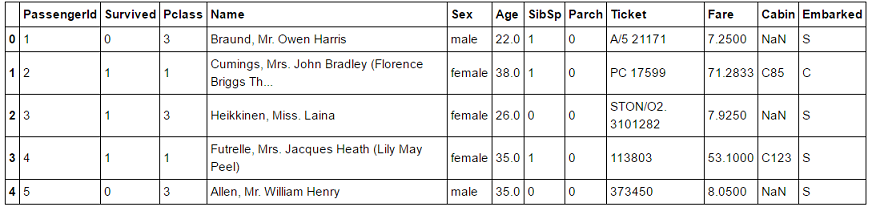
上図のように,データの最初の5行,Cabinのカラムにすでに'NaN'の表示が見て取れる.同様に test.csv についても見てみる.
test.csv
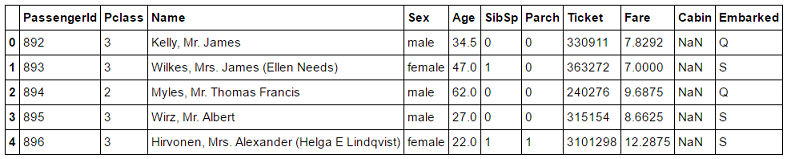
同様にCabinに'NaN'が並んでいるのが分かった.因みにデータのサイズ(shape)は,trainが (891, 12),testが (418, 11) であるので,データセットとしてそれほど大きくはない.
次にどの特徴量(カラム)にデータ欠損が含まれるかをチェックしてみる.
# check if NA exists in each column
train.isnull().any(axis=0)
# output
'''
PassengerId False
Survived False
Pclass False
Name False
Sex False
Age True
SibSp False
Parch False
Ticket False
Fare False
Cabin True
Embarked True
dtype: bool
'''
isnull() は NAかどうかを判定する関数,any() は複数箇所を包括的にみて真偽を返す関数である.any() は,axisオプションを取るので,"カラム"単位でくくりたい(="行"方向にscanしたい)場合は,axis=0 (ディフォルト値なので省略可)とする.同様に,test の方も見てみる.
# check if NA exists in each column
test.isnull().any()
# output
'''
PassengerId False
Pclass False
Name False
Sex False
Age True
SibSp False
Parch False
Ticket False
Fare True
Cabin True
Embarked False
dtype: bool
'''
上記のように,trainデータでは ['Age', 'Cabin', 'Embarked'] にデータ欠損が含まれ,testデータでは ['Age', 'Fare', 'Cabin'] にデータ欠損が含まれることが分かった.これを踏まえて「目的の分類器(classifier)のプロトタイプとして,データ欠損がある特徴量('Age', 'Fare', 'Cabin', 'Embarked') を用いないモデルを作ってみようか」とか,「でも'Age'(年齢)はいかにも分類(生存 or not)に影響しそうだよな」などと考えながら作戦をたてることになる.
次にデータ欠損の個数をカウントする.まずtrainデータ.
# count NA samples
train.isnull().sum()
# output
'''
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
'''
同様にtestデータ.
# count NA samples
test.isnull().sum()
# output
'''
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 327
Embarked 0
dtype: int64
'''
上の結果から,次の点が把握できた.
- 'Age' は,trainもtestも一定の割合でデータ欠損が含まれている.
- 'Cabin'は,train/testで大きなデータ欠損がある.
- 'Embarked' は,trainのみで2件の欠損.
- 'Fare' は,testでたったい1件の欠損.
データ分類の進め方として,「とりあえず’Cabin'は,特徴量から外してモデル化しよう!」,「’Embarked'は,2件なのでdropna() する」などと方針を決めることができる.
Rでのデータ欠損状況確認
Pythonでやった同じことをRでやってみる.まずdata frameにファイルを読み込む.
# Reread not to conver sting to factor
train <- read.csv("./data/train.csv", header=T, stringsAsFactors=F)
test <- read.csv("./data/test.csv", header=T, stringsAsFactors=F)
headerは,ヘッダ行の扱いを指定するオプション,stringsAsFactorsは,文字列から因子型(factor)へ変換する/しないを指定するオプションである.上記でファイル入力すると,trainデータフレームは以下のようになる.
train.csv
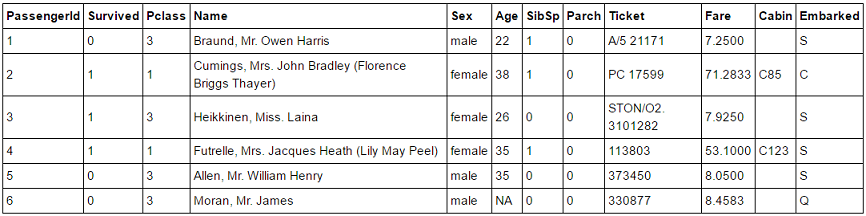
ID=6の'Moran, Mr. James'さんの年齢が,'NA’となっている.
次に各カラムの欠損値の有無を確認する.
# any() usage:
is_na_train <- sapply(train, function(y) any(is.na(y)))
is_na_test <- sapply(test, function(y) any(is.na(y)))
ここではany()が使われるのは,Pythonと同様である.次に欠損値の個数をカウントする.
# count na
na_count_train <- sapply(train, function(y) sum(is.na(y)))
na_count_train
# output
# PassengerId 0
# Survived 0
# Pclass 0
# Name 0
# Sex 0
# Age 177
# SibSp 0
# Parch 0
# Ticket 0
# Fare 0
# Cabin 0
# Embarked 0
お分かりだろうか?上でPythonにより求めた結果と異なっている.同様にtestデータも見てみる.
# count na
na_count_test <- sapply(test, function(y) sum(is.na(y)))
# output
# PassengerId 0
# Pclass 0
# Name 0
# Sex 0
# Age 86
# SibSp 0
# Parch 0
# Ticket 0
# Fare 1
# Cabin 0
# Embarked 0
こちらもPythonで求めたNAの個数と比較すると(特に'Cabin'で)大幅に減っている.何故か?
実はこの差(Python vs. R) が生じた理由は,空白("", blank)の扱い方が異なることにある.
train.csv
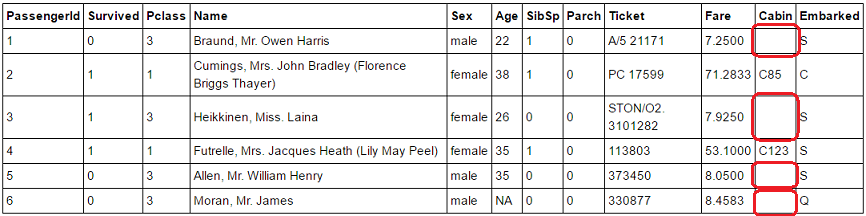
(Pythonでは読み込み時に,すでに赤枠内がNaNとなっていた.)
Python pandas でサポートされる isnull() 関数は空白("")もnullと判別するのに対し,
Rの is.na() は,空白をnaに入れない.これが原因でnaのカウントが少なくなっている.
今回,Titanicの'Cabin’は船室のIDを示すデータであるので,「空白」は(推測になるが)記録がないことが理由だろう.また,空白についてはデータ分析のフローを('Cabin'データ有の処理から)分ける可能性が高いため,プログラムとしては空白をNAにカウントするほうが好ましい.そこで,Pythonコードのように空白("")をNAとして扱うようなRスクリプトに変更する.
# Reread data with na.string option
train <- read.csv("./data/train.csv", header=T, stringsAsFactors=F,
na.strings=(c("NA", "")))
test <- read.csv("./data/test.csv", header=T, stringsAsFactors=F,
na.strings=(c("NA", "")))
read.csv() の na.strings オプションを na.strings=(c("NA", "")) と指定することで,空白("")をNAに変換してくれる.この後,NAのカウントを行ったのが,以下.
# Counting NA
na_count_train <- sapply(train, function(y) sum(is.na(y)))
na_count_test <- sapply(test, function(y) sum(is.na(y)))
出力結果:
# --- Train dataset ---
# PassengerId 0
# Survived 0
# Pclass 0
# Name 0
# Sex 0
# Age 177
# SibSp 0
# Parch 0
# Ticket 0
# Fare 0
# Cabin 687
# Embarked 2
# --- Test dataset ---
# PassengerId 0
# Pclass 0
# Name 0
# Sex 0
# Age 86
# SibSp 0
# Parch 0
# Ticket 0
# Fare 1
# Cabin 327
# Embarked 0
これでPython結果と一致した.このようにNAの定義がPython(pandas) とRで異なっていることはわかった.比較としては,Rの方が,null/NaN/NA の区分を厳密にしているように見える.pandasでは,isnull()でblank/NA/NaNをすべてNAと判定するが,そのこと自体は実用上問題なしとされているようだ.(悪く言うと pandasの扱いは「あいまい」.)
以下,Python pandasのドキュメント( http://pandas.pydata.org/pandas-docs/version/0.18.1/missing_data.html )から引用する.
Note: The choice of using NaN internally to denote missing data was largely for simplicity and performance reasons. It differs from the MaskedArray approach of, for example, scikits.timeseries. We are hopeful that NumPy will soon be able to provide a native NA type solution (similar to R) performant enough to be used in pandas.
空白(blank) のことは書かれていないが,pandasでは,単純さとパフォーマンスを考えて今のような実装としているとある.私自身,NAデータを厳密にblank/NA/NaNに分けなればならないケースに出会ったことがないので,本記事に書いたPythonでの扱い方(Rであれば,blankをNAに変換するやり方)を覚えておきたいと思う.
(参考までに,BlankからNAへの変換ですが,Rパッケージ {data.table} のfread()でも同様のオプション(na.strings)で,変換処理が行われることを確認しました.)
最後に
Kaggle Titanicは,KaggleのTutorial的なコンペであるが,Leader Boardを見ると,優秀なものから平凡なものまでスコアのばらつきが大きい.ここでスコアを上げるポイントの一つは,分類器のパラメータ調整であり,もう一つはデータの欠損値,特に 'Age' の欠損を補間する方法にあると推定される.現時点でまだ期限(12/31/2016)までに日にちがあるので,機会をみてTitanicのコンペに再トライしてみたいと思う.(Topグループは,正答率(accuracy) 1.0 を達成している,どうやるんだろう... )
参考文献 / Web site
- Pandas documentation, Working with missing data
http://pandas.pydata.org/pandas-docs/version/0.18.1/missing_data.html - Python pandas: check if any value is NaN in DataFrame - Stack overflow
http://stackoverflow.com/questions/29530232/python-pandas-check-if-any-value-is-nan-in-dataframe - Python pandas 欠損値/外れ値/離散化の処理 - Blog "StatsFragments"
http://sinhrks.hatenablog.com/entry/2016/02/01/080859 - データに欠損値(NaN)がある場合の取り扱い - Qiita
http://qiita.com/gash717/items/df8aa9c7e771ed7539cb - Titanic: Machine Learning from Disaster - Kaggle
https://www.kaggle.com/c/titanic