最近,Deep Learning Frameworkのリリースが続いている.私は,普段は TensorFlow を使うことが多いのだが,Blog記事やGitHubの情報について,ChainerやPyTorchのコードを参考にする機会も多い.特に最近,GitHubにてPyTorchコードが増えており,PyTorchが気になる存在である一方,学習する上での情報量はChainerが多いか?といった悩ましい状況となっている.
ここでは,簡単なコードを書きながら,2つのFramework(Chainer vs. PyTorch) を比較してみたい.
(プログラミング環境は,以下になります:
- Chainer 2.0.0
- PyTorch 0.1.12
- Python 3.5.2 (or 3.5.3) )
Chainerで線形回帰を実装
まず必要なパッケージをimportする.
import chainer
from chainer import Function, Variable
import chainer.functions as F
できるだけシンプルな書き方を確認したいので,今回,chainer.links は用いないこととする.(注.Chainerドキュメントには,chainer.links の方が新しいパッケージなのでこちらの使用が推奨されるとありました.Chanier APIの変遷に対して,少し注意が必要のようです.)
# Target値 (3.0, 4.0), これを元に学習データサンプルを作成する.
W_target = np.array([[3.0]], dtype=np.float32) # size = [1, 1]
b_target = 4.0
# Model Parameters
# dtype = torch.cuda.FloatTensor # Uncomment this to run on GPU
W = Variable(np.random.randn(1, 1).astype(np.float32) * 0.01,
requires_grad=True)
b = Variable(np.zeros([1, 1], dtype=np.float32), requires_grad=True)
ChainerのVariableクラスでW, bを定義している.Chainer初心者なのでドキュメントでVariableを確認する.(少し引用させていただきます.)
Variables
class chainer.Variable(data=None, *, name=None, grad=None, initializer=None, update_rule=None, requires_grad=True)
Array with a structure to keep track of computation.Every variable holds a data array of type either
numpy.ndarrayorcupy.ndarray.A variable object holds a data array and a
VariableNodeobject of a computational graph. If the variable is constructed by the user, the node is root and does not hold any parent. If the variable is constructed by aFunctionobject, the node holds a reference to its parent called creator. This reference is used in backpropagation to backtrack the graph.
Computational graphにおける変数ノードを保持するとある.TensorFlow/TheanoにおけるTensorと同様のものと推測されるが,"Tensor"という言葉は使っていない.使い方は,データを引数としてnumpy.ndarray(GPU演算では cupy.ndarray)を与え,Variable型インスタンスを得ている.後で,勾配計算が必要であれば(ほとんどのパラメータで勾配計算が必要のはずだが),requires_grad=True を指定する.
線形回帰のコードに戻る.
def model(x, W, b):
# 線形回帰モデルの定義
y1 = F.matmul(x, W)
b1 = F.broadcast_to(b, x.shape)
y = y1 + b1
return y
def get_batch(W_target, b_target, batch_size=32):
# バッチ・データの準備
x = np.random.randn(batch_size, 1).astype(np.float32)
y = x * W_target + b_target
return Variable(x), Variable(y)
関数 model(x, W, b) は,モデル式 y = W * x + b の計算を行う."numpy"の計算であれば,bias b を加算する際,ブロードキャストして,b を適切な形に拡張(要素コピー)してくれるが,"Chainer"(chainer.functions) では明示的にブロードキャスト処理を行う.次の関数 get_batch() は,乱数を使って訓練データ(train data)を生成し,Variable型に変換して戻り値としている.
# Train loop
for batch_idx in range(100):
# Get data
batch_x, batch_y = get_batch(W_target, b_target)
# Forward pass
y_pred = model(batch_x, W, b)
# 損失関数 MSE(mean square error)
loss = F.mean_squared_error(y_pred, batch_y)
# Manually zero the gradients after updating weights
# パラメータの勾配をゼロ化する.(重要)
W.cleargrad()
b.cleargrad()
# Backward pass
loss.backward()
# Apply gradients - パラメータを更新
learning_rate = 0.1
W.data = W.data - learning_rate * W.grad
b.data = b.data - learning_rate * b.grad
# Stop criterion
if loss.data < 1.e-3:
break
学習ループでは,訓練データから予測値 y_pred を計算し,それを使って損失(loss)を求めている.その後,損失を loss.backword() で逆伝搬させ,勾配を計算し,パラメータを更新する.また学習ループは,損失が所定しきい値より小さくなったケースで処理を終えるようにしている.
計算結果は,次の通り.
Loss: 0.0008 after 23 batches
==> Learned function: y = 2.9819 x + 3.9815
==> Actual function: y = 3.0000 x + 4.0000
PyTorchで線形回帰を実装
同じことをPyTorchでやって見るが,コードの比較を始める前に,PyTorchの状況を把握しておきたい.
Fig.1 History - Deep Learning Frameworks
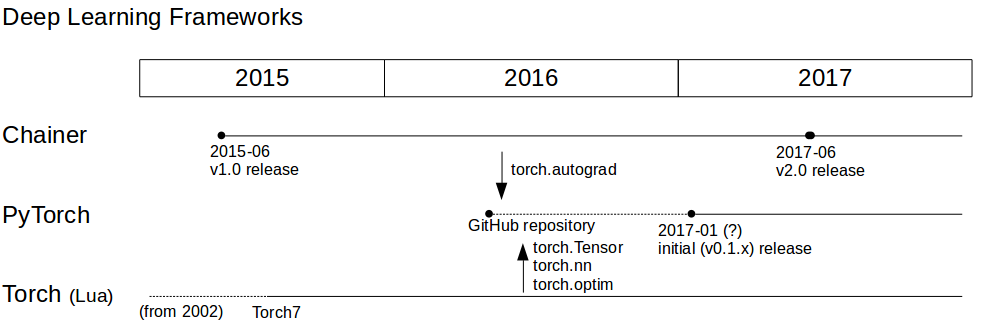
(図は,Internetの情報を元にしており,詳細に関して不正確なところがあるかも知れません.)
(追記:初稿でTorch 7 を2017−02リリースと記載していましたが誤りでした.もっと歴史は古いようです.Torchでは,バーション・スキームで管理していないとのことで詳細はわかりませんでした.)
まず,Chainerは,2015年に最初の版(v1.0)がリリースされ,つい先日,2017年にv2.0がリリースされた.プログラミング言語として Lua を用いるTorchは,かなり歴史が古く,2002年に最初のリリースがあったようである.そのバージョンの更新を重ね,現在は Torch7 となっている.PyTorchは,2016年にGitHubのリポジトリが立ち上がり,2017年に入ってβバージョンがリリースされている.PyTorchの基本的なコンセプトは,Torchから引き継がれているが,勾配計算に関わる部分 torch.autograd は Chainer の影響を大きく受けている.
では,PyTorchのコードを見ていこう.
import numpy as np
import torch
import torch.nn.functional as F
from torch.autograd import Variable
PyTorchでは,上記パッケージをimportする.
# Target値 (3.0, 4.0)
W_target = torch.FloatTensor([[3.0]]) # size = [1, 1]
b_target = 4.0
# Model Parameters
dtype = torch.FloatTensor
# dtype = torch.cuda.FloatTensor # Uncomment this to run on GPU
W = Variable((torch.randn(1, 1) * 0.01).type(dtype), requires_grad=True)
b = Variable(torch.zeros(1, 1).type(dtype), requires_grad=True)
ここは,線形回帰モデルのターゲット値と,用いる変数(Variable)を定義する部分であるが,Chainerには登場しない,torch.Tensor を用いている.PyTorchのドキュメントを参照すると,Tensorは,
A
torch.Tensoris a multi-dimensional matrix containing elements of a single data type.
であるが,コンセプトとしては,Framework(PyTorch)専用のマトリクス・オブジェクトになるかと思う.この torch.Tensor には以下のものがあるとのこと.
torch.Tensor
| Data type | CPU tensor | GPU tensor |
|---|---|---|
| 32-bit floating point | torch.FloatTensor |
torch.cuda.FloatTensor |
| 64-bit floating point | torch.DoubleTensor |
torch.cuda.DoubleTensor |
| 16-bit floating point | N/A | torch.cuda.HalfTensor |
| 8-bit integer (unsigned) | torch.ByteTensor |
torch.cuda.ByteTensor |
| 8-bit integer (signed) | torch.CharTensor |
torch.cuda.CharTensor |
| 16-bit integer (signed) | torch.ShortTensor |
torch.cuda.ShortTensor |
| 32-bit integer (signed) | torch.IntTensor |
torch.cuda.IntTensor |
| 64-bit integer (signed) | torch.LongTensor |
torch.cuda.LongTensor |
上記のように,CPU演算とGPU演算でTensorタイプを使い分けるようである.また,Variable コンストラクタに渡す引数も,Chainerは "numpy"クラスのもの(numpy.ndarray)であったのが,PyTorchでは torch.Tensor を渡すことに注意したい.上のコードでは,torch.randn() と torch.zeros() で乱数及びゼロの torch.Tensor を生成し,必要に応じて .type(dtype) で CPU tensor と GPU tensor に変換し直している.(CPU演算では,torch.randn(), torch.zeros() 自体が torch.Tensor インスタンスを作るので .type(dtype) は冗長となるが,GPU演算に対する互換性により上のようにしている.)requires_grad の使い方は Chainer と同じである.
def model(x):
# 線形回帰モデルの定義
y = torch.mm(x, W) + b.expand_as(x)
return y
def get_batch(batch_size=32):
# バッチ・データの準備
x = torch.randn(batch_size, 1)
y = torch.mm(x, W_target) + b_target
return Variable(x), Variable(y)
モデルの定義は,Tensorレベルで行う.このあたりは,"Theano", "TensorFlow"に近いように見える.関数 "get_batch()" では,訓練データを乱数で発生させ,Variableオフジェクトに変換して戻り値としている.Chainerとの違いを確認しておきたい.(Chainer: numpy.ndarrayからVariabelに変換,PyTorch: torch.TensorからVariableに変換.)
この後,損失を定義し勾配を計算する,という流れは,前のコードと同じとなる.
# 損失関数 MSE(mean square error)
loss_fn = torch.nn.MSELoss(size_average=True)
# Train loop
for batch_idx in range(20):
# Get data
batch_x, batch_y = get_batch()
# Forward pass
y_pred = model(batch_x)
loss = loss_fn(y_pred, batch_y)
loss_np = loss.data[0]
# Backward pass
loss.backward()
# Apply gradients
learning_rate = 0.1
W.data = W.data - learning_rate * W.grad.data
b.data = b.data - learning_rate * b.grad.data
# Manually zero the gradients by torch.Tensor.zero_()
# パラメータの勾配をゼロ化する.(重要)
W.grad.data.zero_()
b.grad.data.zero_()
# Stop criterion
if loss_np < 1.e-3:
break
Chainerにあった,cleargrad() のVariableメソッドが無いので,W.grad.data.zero_(), b.grad.data.zero_() のように,torch.Tensorレベルで勾配をリセットしている.計算の結果は,次の通り.
Loss: 3.9375e-03 after 19 batches
==> Learned function: y = [ 2.98094225] x + 3.9527
==> Actual function: y = [ 3.] x + 4.0000
(本来,乱数seedを設定して計算結果の再現性(Chainer vs. PyTorch)を見たほうがいいのかも知れませんが,本記事ではコーディングの比較が目的なので,計算結果の詳細比較は行っていません.)
(2つのコードはこちら(gist)にアップロードしました.)
雑感
いわゆる「Autograd系」の Chainer と PyTorch を簡単なコードで比較してみた.PyTorchでは,過去の遺産である torch.Tensor を引き継ぎ, numpy変数から,torch.Tensor を間に挟んでVariable(変数)に変換するというところが,なんとも Hybrid 感をかもし出している.ここのコンセプトの違いを理解すれば,Chainer - PyTorch間のコード移植は,スムーズに行くと予想される.
しかしながら,PyTorchの勢いはすごい.まだリリースされて半年だが,GitHubの至るところでPyTorchのコードを目にするようになってきた.自分自身は他のライブラリでコード作成を行っているが,「Autograd系」のFramework(Chainer / PyTorch) についても,使いこなせるように(少なくともコードを読めるように)勉強を進めていきたい.
参考文献,web site
- Chainer Documentation
https://docs.chainer.org/en/stable/ - PyTorch Documentation
http://pytorch.org/docs/index.html - PyTorch Tutorials
http://pytorch.org/tutorials/ - Stanford University, cn231n, Lecture 8 slides
http://cs231n.stanford.edu/syllabus.html