機械学習の課題で大量の画像ファイルを扱う場合,ファイル名をリストにして,学習プロセス(train process)で逐次画像を読み込むことはよく行うと思われる.ただ用意されているサンプル数と,学習プロセスでのミニバッチ・サイズとの関係で,どうしても学習の後半で端数が生じて扱いが複雑になりがちである.
例えば,データサンプル数 num = 100 で ミニバッチ・サイズ batch_size = 30 の場合,
- ミニバッチを3回実行し,10のサンプルは使わない.
- 次のミニバッチでサイズを調整する (batch_size = 10).
- 次のミニバッチサイズで,不足するサンプル数(20)は,一度使ったサンプルを再利用する.
の方法が考えられる.サンプル数が大きければ上記1の選択肢でいいと思うが,訓練データを大切に使いたい場合,選択肢2, 3を選びたくなる.
ここでは選択肢3の方法をdequeで実装してみる.
dequeとは
入門Python3から説明を引用する.
deque(デックと発音する)は,両端キューのことで,スタックとキューの機能を持っている.シーケンスのどちらの端でも要素を追加,削除できるようにしたいというときに便利だ.
この説明を図示すると以下のようになる.
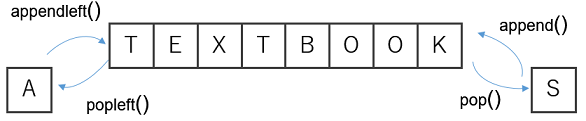
今回は「データサンプルの使い回し」のため,deque.rotate() の機能を用いた.(「データを使ったら回転,使ったら回転, ...」の処理を行います.)
実装
データファイルが,以下のように展開されているケースを考える.
$ ls deque_ex/*.jpg
deque_ex/img_0.jpg deque_ex/img_3.jpg deque_ex/img_6.jpg deque_ex/img_9.jpg
deque_ex/img_1.jpg deque_ex/img_4.jpg deque_ex/img_7.jpg
deque_ex/img_2.jpg deque_ex/img_5.jpg deque_ex/img_8.jpg
まず,扱うファイル名のリスト(デック)作り.
import glob
from collections import deque
import numpy as np
def mk_list():
fname_list = glob.glob('*.jpg')
sorted_fn = sorted(fname_list)
deq_fname = deque()
deq_fname.extend(sorted_fn) # 'extend' is right,
# 'append' is not good.
return deq_fname
ポイントは,リストをデックに追加する際,deque.append() ではなく,deque.extend() を用いることである.
>>>
deque(['img_0.jpg',
'img_1.jpg',
'img_2.jpg',
'img_3.jpg',
'img_4.jpg',
'img_5.jpg',
'img_6.jpg',
'img_7.jpg',
'img_8.jpg',
'img_9.jpg'])
データリスト(正確にはdequeクラス)と要求数から,データを返す関数は以下の通り.(リストのスライスとdeque.rotate()を使います.)
def feed_fn_ver0(dq, num):
feed = list(dq)[-num:]
dq.rotate(num)
return feed
これを使って5回,データを 3 sample ずつ取り出した状況は以下の通り.
0: ['img_7.jpg', 'img_8.jpg', 'img_9.jpg']
1: ['img_4.jpg', 'img_5.jpg', 'img_6.jpg']
2: ['img_1.jpg', 'img_2.jpg', 'img_3.jpg']
3: ['img_8.jpg', 'img_9.jpg', 'img_0.jpg']
4: ['img_5.jpg', 'img_6.jpg', 'img_7.jpg']
データデックの終端から 3 sampleずつ,取り出すことができた.順番にこだわらない機械学習のプロセスで用いるのには問題はないが,「終端から」というのが少し気持ち悪いので,「始端から」に直し,また要求データ長のチェックを入れたのが,次のコード.
def feed_fn_ver1(dq, num):
'''
dq : data source (deque)
num : request size (int)
'''
# check length
assert num <= len(dq)
feed = list(dq)[:num]
dq.rotate(-num)
return feed
my_list = mk_list()
for i in range(5):
print(' Feed [', i, ']: ', feed_fn_ver1(my_list, 3))
>>>
Feed [ 0 ]: ['img_0.jpg', 'img_1.jpg', 'img_2.jpg']
Feed [ 1 ]: ['img_3.jpg', 'img_4.jpg', 'img_5.jpg']
Feed [ 2 ]: ['img_6.jpg', 'img_7.jpg', 'img_8.jpg']
Feed [ 3 ]: ['img_9.jpg', 'img_0.jpg', 'img_1.jpg']
Feed [ 4 ]: ['img_2.jpg', 'img_3.jpg', 'img_4.jpg']
上手く動いた.ランダムシャッフルしたデータでは,以下の通り.
def mk_list_shuffle():
fname_list = glob.glob('*.jpg')
np_list_fn = np.array(fname_list)
np.random.shuffle(np_list_fn)
deq_fname = deque()
deq_fname.extend(list(np_list_fn))
return deq_fname
my_list = mk_list_shuffle()
for i in range(5):
print(' Feed [', i, ']: ', feed_fn_ver1(my_list, 3))
>>>
Feed [ 0 ]: ['img_9.jpg', 'img_7.jpg', 'img_6.jpg']
Feed [ 1 ]: ['img_1.jpg', 'img_8.jpg', 'img_3.jpg']
Feed [ 2 ]: ['img_4.jpg', 'img_0.jpg', 'img_2.jpg']
Feed [ 3 ]: ['img_5.jpg', 'img_9.jpg', 'img_7.jpg']
Feed [ 4 ]: ['img_6.jpg', 'img_1.jpg', 'img_8.jpg']
すこし分かりにくいが,目を凝らすときちんと循環してデータが供給できているのが分かる.この関数(feed_fn_ver1())を用いれば,機械学習の訓練プロセスがシンプルに書けるはずである.
(上のコードは,Python 2.7.11, Python 3.5.1 の環境で確認しました.)
参考文献 (web site)
- 入門Python3 http://www.oreilly.co.jp/books/9784873117386/
- Python Documentation - collections https://docs.python.org/2/library/collections.html