はじめに
前職を退職後、少し時間に余裕があったため、以前から興味があったデータサイエンスの学習をしてみようと思い立ち、Aidemyのデータ分析コースを受講中。
このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています。
本記事の概要
どのようなテーマを扱うか考えながら電車に乗っていて、ふと窓の外に目をやると遠くに富士山が見えていました。富士山が見えるとなぜかテンションがあがります。
ですが、富士山の姿を間近で拝みたいと富士山近郊を訪れても、なぜかいつも厚い雲に覆われて姿を現してくれません。
こんな近くにいるのに見えないなんて・・😂・・目の前にどーーんと広がる富士山の景色を見たい!ということで、気象データから富士山の見え方を予測してみました。
*分析環境はGoogle Colaboratoryを使用しています。
使用したデータ
- 気象データ : 気象庁のホームページより、以下の気象データをダウンロードしました。
- - 地点:富士山頂、富士、静岡
- - 項目: <時別値>気温、降水量、降雪の深さ、風向/風速、相対湿度、天気、雲量
- 実際には値がないデータも多く、すべての項目を予測に使用しているわけではありません。
- - 期間: 2022年11月1日~2023年10月16日 9:00 12:00 15:00 時点
- 富士山の見え方のデータ : 静岡県のホームページの365日ライブラリーで、過去1年間の富士山の画像を見ることができます。
こちらのページから「気象データと同様の期間・時間」「富士宮」の画像データをダウンロードし、目視で見えているかどうかを確認しデータを作成しました。
(0: 全く見えない、 1: 見える(一部分だけ見える、霞がかっているが見えるも含む))
作成したプログラム
1. データ準備
静岡県のホームページからスクレイピングで富士山の画像をダウンロードしました。まず2022年11月1日から2023年9月30日までのデータを落としました。コードは以下の通りです。import requests
# 静岡県公式HP ライブカメラ富士山ビュー > 365日ライブラリー から写真を取得する
def download_photos(url):
img = requests.get(url)
if img.status_code== requests.codes.ok:
save_path = "photo/" + url.split('/')[-3] + url.split('/')[-2] + url.split('/')[-1]
with open(save_path,'wb') as f:
f.write(img.content)
else:
pass
# 2022年11月1日~2023年9月30日までの写真を取得(富士宮からの写真、9時、12時、15時時点の写真)
ym_list = {'202211','202212','202301','202302','202303','202304','202305','202306','202307','202308','202309'}
d_list = {"01","02","03","04","05","06","07","08","09","10","11","12","13","14","15","16","17","18","19","20","21","22","23","24","25","26","27","28","29","30","31"}
t_list = {"09","12","15"}
for m in ym_list:
for d in d_list:
for t in t_list:
url = "https://www.pref.shizuoka.jp/~live/archive/" + m + d +"fujinomiya/" + t +"/l.jpg"
download_photos(url)
とりこんだファイルをLocalフォルダに保存して、目視で見えているかどうかを判断しました。
#ファイルをLocalフォルダに保存
!zip -r /content/download.zip /content/photo
from google.colab import files
files.download("/content/download.zip")
本当は、ここで画像認識をさせてみたかったのですが、今回は時間と気力の関係で断念しました。今後試していきたいと思います。
2. データの読み込み
1.で作成した富士山の見え方のデータ(0: 全く見えない、 1: 見える(一部分だけ見える、霞がかっているが見えるも含む))と気象庁HPからダウンロードした気象データのcsvファイルをDataFrame型として読み込みをし、2つのデータを日付けをキーにして内部結合しました。import pandas as pd
from datetime import datetime
from google.colab import drive
drive.mount('/content/drive')
#データの読み込み
#Viewデータ:0:見えない、1: 見える(一部分だけ見える/霞がかかって見えるも含む)
df_View = pd.read_csv("/content/drive/MyDrive/Aidemy最終成果物/Fuji_View.csv")
#日付列をdatetime型にして時系列に変換
df_View["Date"] = pd.to_datetime(df_View["Date"])
#weatherデータ:気象庁のHPよりダウンロードした富士山、富士、静岡の気象データ
df_weather = pd.read_csv("/content/drive/MyDrive/Aidemy最終成果物/Weather data.csv",encoding="shift-jis")
#日付列をdatetime型にして時系列に変換
df_weather["Date"] = pd.to_datetime(df_weather["Date"])
#df_Viewとdf_weatherを日付けをキーにして内部結合
df = pd.merge(df_View, df_weather, how="inner", on = "Date")
3. データの確認と前処理
読み込んだデータを確認してみましょう。#データの確認
df.info()

1件もデータがない項目がたくさんあるので、これらをまず削除します。
(富士山:降水量、風向、風速、雲量、降雪、天気、富士:雲量、降雪、天気、静岡:雲量)
#データの入っていない項目を削除
df = df.drop(["MtFuji_Sum_precipitation","MtFuji_windspeed","MtFuji_wind_direction","MtFuji_cloud","MtFuji_Sum_snow","MtFuji_weather","Fuji_cloud","Fuji_Sum_snow","Fuji_weather","Shizuoka_cloud"],axis=1)
データの頭5件をみてみます。
print(df.head().T)
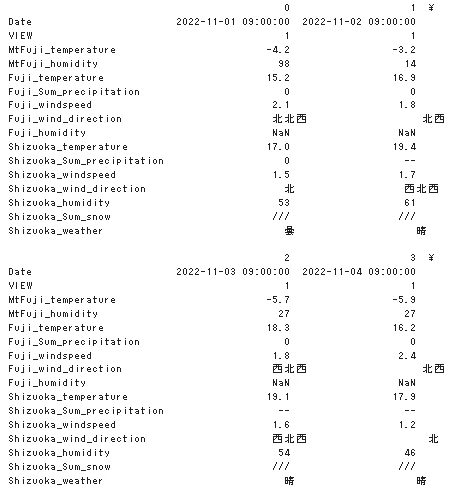
データに「///」や「--」が含まれてしまっているようです。またNaN(欠損値)もありそうです。
まずは、「///」や「--」を取り除いてみます。
import numpy as np
#「///」や「--」が含まれているので置換する
df = df.replace(["///","--"],np.nan)
次に、気温や湿度など数値データがはいっているはずの項目が一部object型になってしまっているようなので、float型に変換をしておきます。
#object型になってしまっている項目をfloat型へ変更
df=df.astype({"Fuji_temperature":float,"Fuji_Sum_precipitation":float,"Fuji_windspeed":float,"Fuji_humidity":float,"Shizuoka_Sum_precipitation":float})
データ統計量を確認してみます。
#数値データの統計量を表示
display(df.describe())
#カテゴリカルデータの統計量を表示
display(df.describe(exclude='number'))

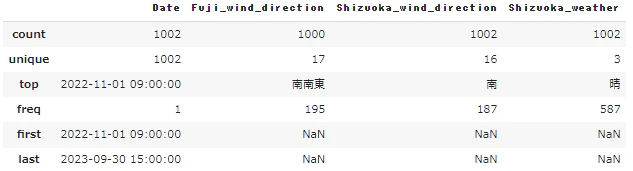
静岡の降水量、降雪データは欠損が多いため、今回の特徴量からは外すこととします。
富士の湿度データの欠損値の処理については、富士の湿度と静岡の湿度は、平均がほぼ同じなため、静岡の値で補完することとします。
#欠損値が多い項目を削除
df = df.drop(["Shizuoka_Sum_precipitation","Shizuoka_Sum_snow"],axis=1)
#富士の湿度の欠損値への対応。富士の湿度と静岡の湿度は、平均がほぼ同じなため、静岡の値で補完する
df["Fuji_humidity"].fillna(df["Shizuoka_humidity"],inplace=True)
富士の気温、降水量、風向、風速データに欠損があるので、欠損データの内容を確認してみます。
#欠損データを確認。Fuji_temperature の欠損データ(2件)を確認。
display(df[df["Fuji_temperature"].isnull()])

すべての項目について、同じデータ内で欠損していますので、このデータは削除することとします。
#他の項目も多く欠損しているので、データから削除する。
df = df.drop([347,681],axis=0)
df = df.reset_index(drop=True)
再度データを確認してみましょう。
#数値データの統計量を表示
display(df.describe())
#カテゴリカルデータの統計量を表示
display(df.describe(exclude='number'))

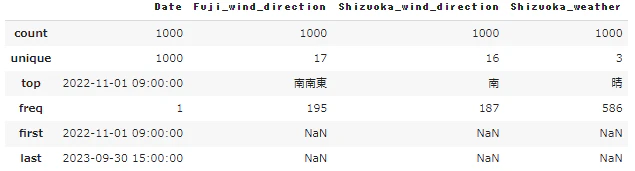
欠損値がなくなり外れ値もなさそうなので、こちらのデータで分析をしていきましょう。
風向、天気データは、One-hot Encodingを施し、モデルが扱えるように変換をしておきます。
#風向きと天気データにOne-hot Encodingを施す
df = pd.get_dummies(df, columns=["Fuji_wind_direction","Shizuoka_wind_direction","Shizuoka_weather"])
4. 学習と評価
ひとまずこちらのデータでロジスティック回帰で学習と評価をしてみます。 訓練データと検証データの分割方法はホールドアウト法とKFold法の両方を試してみます。#ひとまずロジスティック回帰分析してみる。①
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
import numpy as np
target = df['VIEW']
df_table = df.drop(["Date","VIEW"],axis=1)
#ホールドアウト法
X_train ,X_val ,y_train ,y_val = train_test_split(
df_table, target,
test_size=0.2, shuffle=True,random_state=0
)
# モデルを定義し学習
model = LogisticRegression(max_iter=7000)
model.fit(X_train, y_train)
# 訓練データに対しての予測を行い、正答率を算出
y_pred = model.predict(X_train)
#検証データに対しての予測を行い、正答率を算出
y_pred_val = model.predict(X_val)
#正答率を表示
print('-'*10 + 'Result(ホールドアウト法)' +'-'*10)
print(f'Train_acc :{accuracy_score(y_train, y_pred)}')
print(f'Valid_acc :{accuracy_score(y_val, y_pred_val)}')
# 乱数を固定
np.random.seed(0)
#KFold法
cv = KFold(n_splits=7, random_state=0, shuffle=True)
train_acc_list = []
val_acc_list = []
for i ,(trn_index, val_index) in enumerate(cv.split(df_table, target)):
X_train ,X_val = df_table.loc[trn_index], df_table.loc[val_index]
y_train ,y_val = target[trn_index], target[val_index]
# モデルを定義し学習
model = LogisticRegression(max_iter=7000)
model.fit(
X_train, y_train
)
# 訓練データに対しての予測を行い、正答率を算出
y_pred = model.predict(X_train)
train_acc = accuracy_score(
y_train, y_pred
)
train_acc_list.append(train_acc)
#検証データに対しての予測を行い、正答率を算出
y_pred_val = model.predict(X_val)
val_acc = accuracy_score(
y_val, y_pred_val
)
val_acc_list.append(val_acc)
print('-'*10 + 'Result(k-Fold)' +'-'*10)
print(f'Train_acc : {train_acc_list} , Ave : {np.mean(train_acc_list)}')
print(f'Valid_acc : {val_acc_list} , Ave : {np.mean(val_acc_list)}')

検証データでの正解率が77%となりました。うーん。もう少し上げたいところです。
5. データの可視化
各特徴量の傾向や目的変数(見え方)との関係を可視化して確認していきます。- 見え方の分布と月別の傾向
まずは見え方の分布と月別の傾向を見てみます。
#富士山の見え方の分布と月別の傾向をみてみる。
import seaborn as sns
import matplotlib.pyplot as plt
#見え方ごとに集計してグラフ化
display(df['VIEW'].value_counts(ascending=False,normalize=True))
sns.countplot(x="VIEW", data=df)
#月ごとの集計をだす。
df_View_M = pd.crosstab(df["Date"],df["VIEW"]).resample("MS").sum()
print(df_View_M)
#月別のグラフを作成
df_View_M.plot.bar(stacked=True)
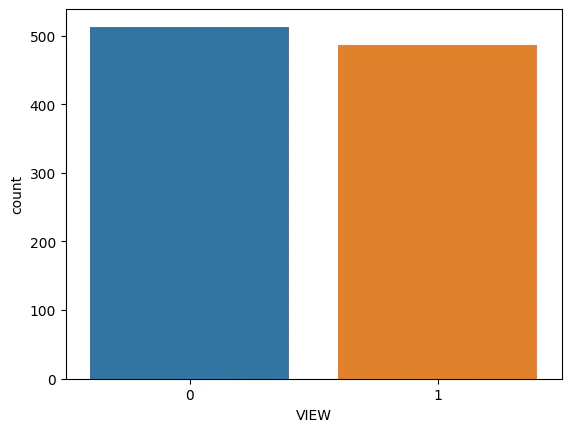
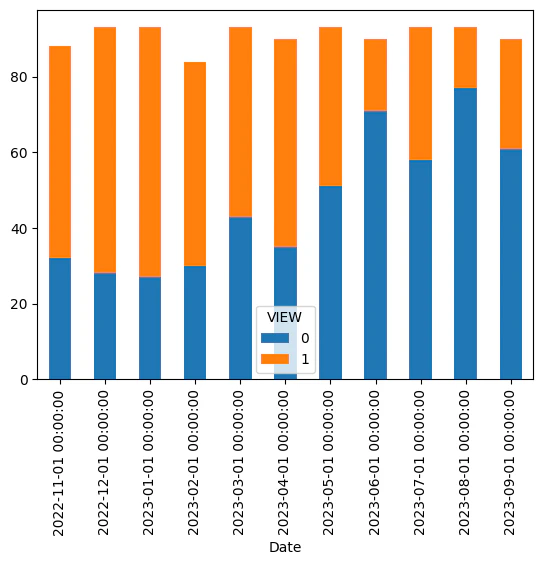
見えなかったときの方がやや多いが、大きな偏りはない。月別にみると11月から4月の期間がその他に比べて見えるときが多いといえる。
- 各特徴量間の相関
次に、各特徴量間の相関を見てみます。
#カラム間の相関を可視化
plt.figure(figsize=(20,20))
sns.heatmap(df.corr(),vmax=1,vmin=-1,annot=True)
plt.show()
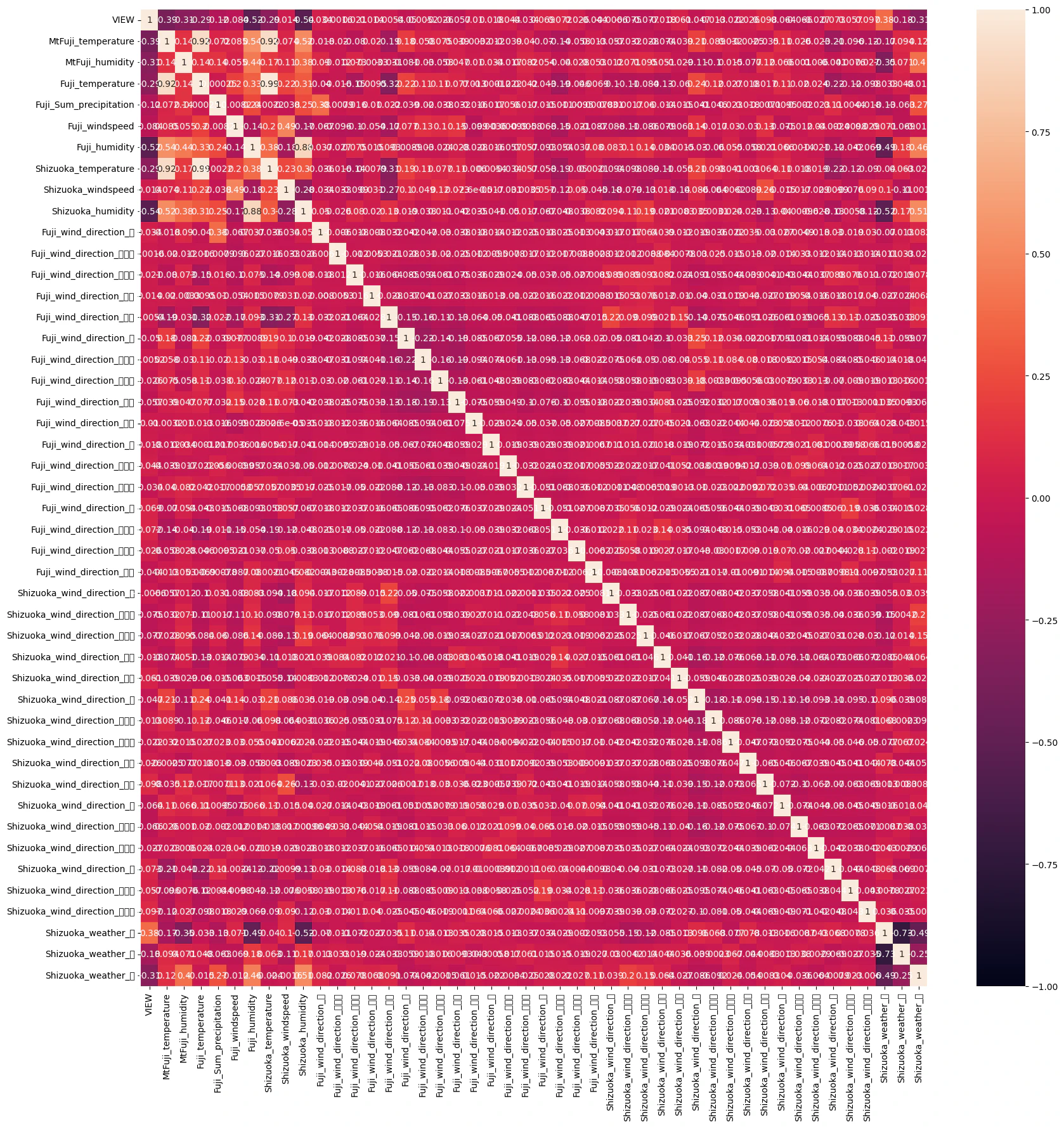
各地の温度・湿度、静岡の天候との相関がみられるが、風向きや風速との相関は低そう。
- 湿度との関係
続いて各地の湿度と見え方の関係を見てみます。
# 湿度について可視化(富士山)
df['MtFuji_humidity_C'] = pd.cut(df['MtFuji_humidity'],[0,10,20,30,40,50,60,70,80,90,100])
df_graph = pd.crosstab(df["MtFuji_humidity_C"],df["VIEW"],normalize= 'index')
df_graph.plot.bar(stacked=True)
df = df.drop(["MtFuji_humidity_C"],axis=1)
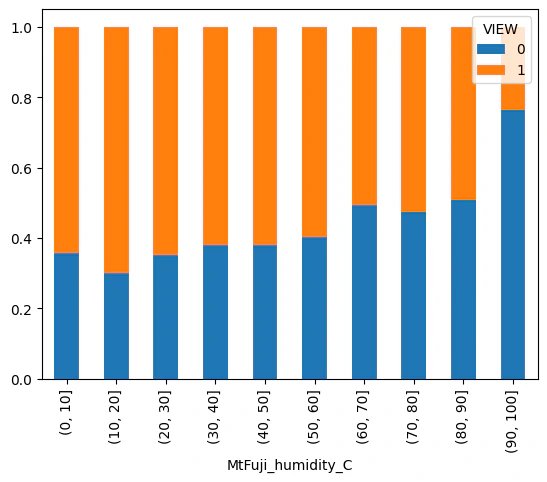
富士山の湿度が90%を超えると見えない割合が多くなります。
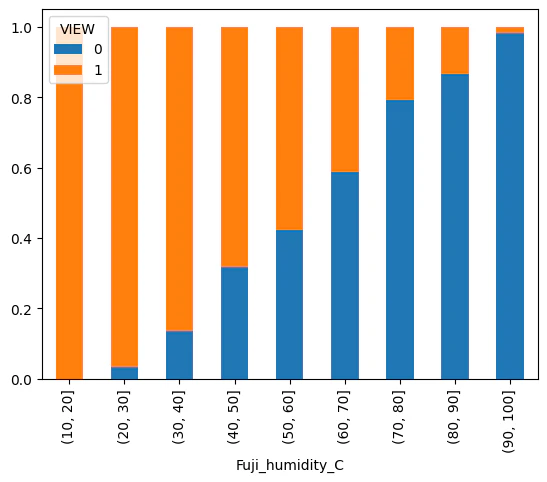
# 湿度について可視化(富士)
df['Fuji_humidity_C'] = pd.cut(df['Fuji_humidity'],[0,10,20,30,40,50,60,70,80,90,100])
df_graph = pd.crosstab(df["Fuji_humidity_C"],df["VIEW"],normalize= 'index')
df_graph.plot.bar(stacked=True)
df = df.drop(["Fuji_humidity_C"],axis=1)
# 湿度について可視化(静岡)
df['Shizuoka_humidity_C'] = pd.cut(df['Shizuoka_humidity'],[0,10,20,30,40,50,60,70,80,90,100])
df_graph = pd.crosstab(df["Shizuoka_humidity_C"],df["VIEW"],normalize= 'index')
df_graph.plot.bar(stacked=True)
df = df.drop(["Shizuoka_humidity_C"],axis=1)
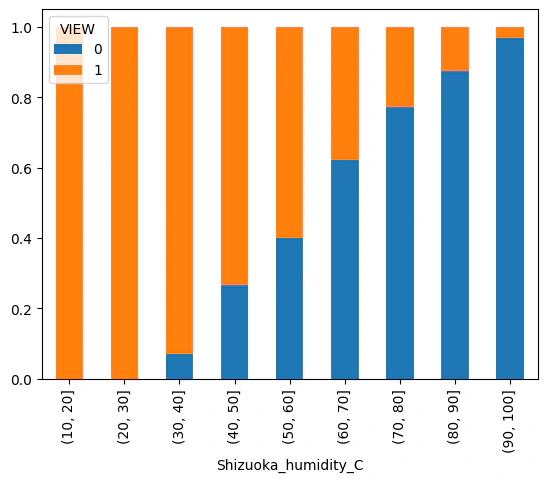
湿度が高くなればなるほど見えない割合が増えていきます。
- 気温との関係
同様に気温と見え方の関係も見ていきます。
# 気温について可視化(富士山)
df['MtFuji_temperature_C'] = pd.cut(df['MtFuji_temperature'],[-40,-30,-20,-10,0,10,20,30,40])
df_graph = pd.crosstab(df["MtFuji_temperature_C"],df["VIEW"],normalize= 'index')
df_graph.plot.bar(stacked=True)
df = df.drop(["MtFuji_temperature_C"],axis=1)
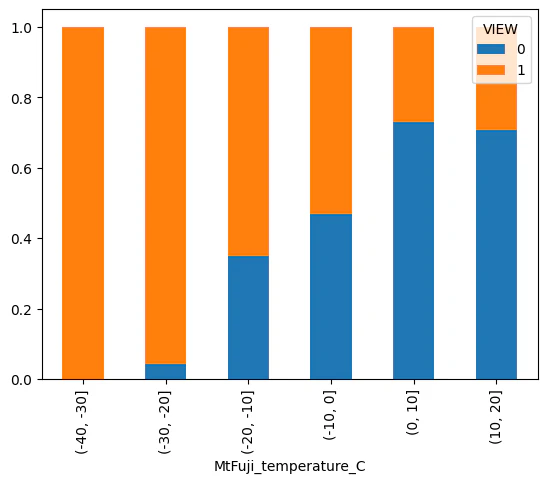
# 気温について可視化(富士)
df['Fuji_temperature_C'] = pd.cut(df['Fuji_temperature'],[-40,-30,-20,-10,0,10,20,30,40])
df_graph = pd.crosstab(df["Fuji_temperature_C"],df["VIEW"],normalize= 'index')
df_graph.plot.bar(stacked=True)
df = df.drop(["Fuji_temperature_C"],axis=1)
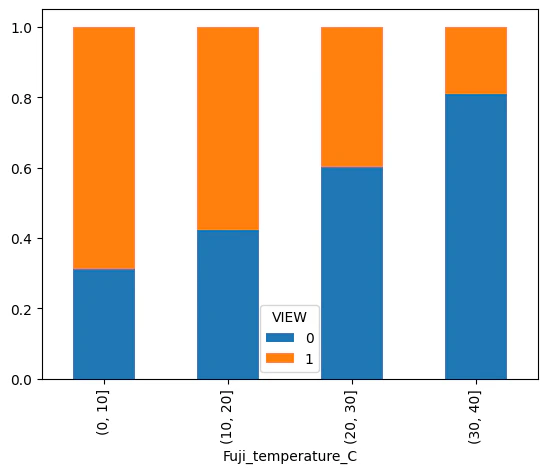
# 気温について可視化(静岡)
df['Shizuoka_temperature_C'] = pd.cut(df['Shizuoka_temperature'],[-40,-30,-20,-10,0,10,20,30,40])
df_graph = pd.crosstab(df["Shizuoka_temperature_C"],df["VIEW"],normalize= 'index')
df_graph.plot.bar(stacked=True)
df = df.drop(["Shizuoka_temperature_C"],axis=1)
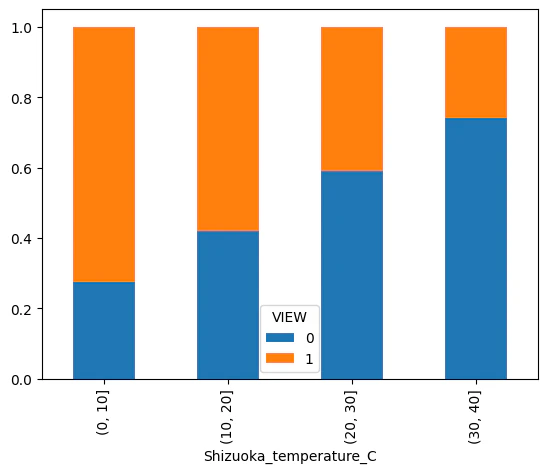
気温があがると見えない割合が増えていきます。
- 天気との関係
続いて静岡の天気との関係を見ていきます。
# 静岡の天候について可視化(晴れ)
sns.countplot(x='Shizuoka_weather_晴', hue='VIEW', data=df)
plt.show()
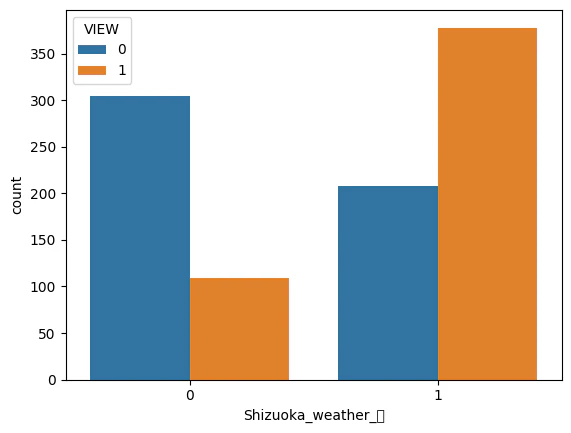
静岡の天気が晴れであれば、晴れでない日よりも見える確率があがるは当然だが、晴れでも見えない日が意外と多い。
静岡の天気が晴れのときの湿度と見え方の数をカウントしてみました。
#静岡の天気が晴れのときの湿度と見え方
df['Shizuoka_humidity_C'] = pd.cut(df['Shizuoka_humidity'],[0,10,20,30,40,50,60,70,80,90,100])
df_cross = pd.crosstab([df["Shizuoka_weather_晴"],df["Shizuoka_humidity_C"]],df["VIEW"])
print(df_cross)

晴れでも湿度が高いと見えない割合が高くなってくる。
6. 特徴量エンジニアリング
- 風向データ
風向については現在の北北西などの16方位のデータをOne-hot Encodingすると16項目の特徴量になるため、シンプルに東・西・南・北のデータに分解してみる。
# <追加>風向(Fuji_wind_direction,Shizuoka_wind_direction)を東西南北のデータに変更
wind_direction = ["Fuji_wind_direction","Shizuoka_wind_direction"]
for WD in wind_direction:
NORTH = []
for i in range(df.shape[0]):
if df[WD].str.contains('北')[i] == True :
NORTH.append(1)
else:
NORTH.append(0)
df[WD+"_NORTH"]= NORTH
SOUTH = []
for i in range(df.shape[0]):
if df[WD].str.contains('南')[i] == True :
SOUTH.append(1)
else:
SOUTH.append(0)
df[WD+"_SOUTH"]=SOUTH
WEST = []
for i in range(df.shape[0]):
if df[WD].str.contains('西')[i] == True:
WEST.append(1)
else:
WEST.append(0)
df[WD+"_WEST"]=WEST
EAST = []
for i in range(df.shape[0]):
if df[WD].str.contains('東')[i] == True:
EAST.append(1)
else:
EAST.append(0)
df[WD+"_EAST"]=EAST
#Fuji_wind_direction,Shizuoka_wind_directionを削除
df = df.drop(["Fuji_wind_direction","Shizuoka_wind_direction"],axis=1)
このデータをもとにロジスティック回帰で学習と評価を行ってみた結果です。

少し正解率があがりました。
- 温度と湿度の数値データ
続いて温度と湿度の数値データをカテゴリカル変数化した上で、One-hot encodingを施します。
#温度と湿度の数値データをカテゴリカル変数化
df['MtFuji_temperature_Band'] = pd.cut(df['MtFuji_temperature'],[-40,-30,-20,-10,0,10,20])
df['Fuji_temperature_Band'] = pd.cut(df['Fuji_temperature'],[0,10,20,30,40])
df['Shizuoka_temperature_Band'] = pd.cut(df['Shizuoka_temperature'],[0,10,20,30,40])
df['MtFuji_humidity_Band'] = pd.cut(df['MtFuji_humidity'],[0,20,40,60,80,100])
df['Fuji_humidity_Band'] = pd.cut(df['Fuji_humidity'],[0,20,40,60,80,100])
df['Shizuoka_humidity_Band'] = pd.cut(df['Shizuoka_humidity'],[0,20,40,60,80,100])
#One-hot Encoding
df = pd.get_dummies(df, columns=["MtFuji_temperature_Band","Fuji_temperature_Band","Shizuoka_temperature_Band","MtFuji_humidity_Band","Fuji_humidity_Band","Shizuoka_humidity_Band"])
このデータをもとにロジスティック回帰で学習と評価を行ってみた結果です。

今度は下がってしまいました。カテゴリカル変数化はしないデータを使用します。
- 標準化
温度、湿度など単位や基準が異なるデータが含まれているため、データの標準化を行ってみます。
正解率の良かった風向の処理を行ったデータをもとに、標準化した上で、ロジスティック回帰で学習評価を行ってみます。
#ロジスティック回帰分析(データ標準化を行う)
target = df['VIEW']
df_table = df.drop(["Date","VIEW"],axis=1)
#ホールドアウト法
X_train ,X_val ,y_train ,y_val = train_test_split(
df_table, target,
test_size=0.2, shuffle=True,random_state=0
)
#訓練データと検証データの標準化
X_train_std = (X_train-X_train.mean())/X_train.std()
X_val_std = (X_val-X_train.mean())/X_train.std()
# モデルを定義し学習
model = LogisticRegression(max_iter=7000)
model.fit(X_train_std, y_train)
# 訓練データに対しての予測を行い、正答率を算出
y_pred = model.predict(X_train_std)
#検証データに対しての予測を行い、正答率を算出
y_pred_val = model.predict(X_val_std)
#正答率を表示
print('-'*10 + 'Result(ホールドアウト法)' +'-'*10)
print(f'Train_acc :{accuracy_score(y_train, y_pred)}')
print(f'Valid_acc :{accuracy_score(y_val, y_pred_val)}')
# 乱数を固定
np.random.seed(0)
#KFold法
cv = KFold(n_splits=3, random_state=0, shuffle=True)
train_acc_list = []
val_acc_list = []
for i ,(trn_index, val_index) in enumerate(cv.split(df_table, target)):
X_train ,X_val = df_table.loc[trn_index], df_table.loc[val_index]
y_train ,y_val = target[trn_index], target[val_index]
#訓練データと検証データの標準化
X_train_std = (X_train-X_train.mean())/X_train.std()
X_val_std = (X_val-X_train.mean())/X_train.std()
model = LogisticRegression(max_iter=7000)
model.fit(X_train_std, y_train)
y_pred = model.predict(X_train_std)
train_acc = accuracy_score(y_train, y_pred)
train_acc_list.append(train_acc)
y_pred_val = model.predict(X_val_std)
val_acc = accuracy_score(y_val, y_pred_val)
val_acc_list.append(val_acc)
print('-'*10 + 'Result(k-Fold)' +'-'*10)
print(f'Train_acc : {train_acc_list} , Ave : {np.mean(train_acc_list)}')
print(f'Valid_acc : {val_acc_list} , Ave : {np.mean(val_acc_list)}')
結果です。

少し正解率があがりました。
データ標準化を行い、k-Fold法で分類することとします。
7. モデルの評価・比較とパラメータチューニング
ここからは、アルゴリズムの検討とパラメータの最適化を行います。ここではいったんホールドアウト法にて分類して最適モデルとパラメータの探索をしてみようと思います。- ロジスティック回帰
#ロジスティック回帰
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
target = df['VIEW']
df_table = df.drop(["Date","VIEW"],axis=1)
#ホールドアウト法
X_train ,X_val ,y_train ,y_val = train_test_split(
df_table, target,
test_size=0.2, shuffle=True,random_state=0
)
#訓練データと検証データの標準化
X_train_std = (X_train-X_train.mean())/X_train.std()
X_val_std = (X_val-X_train.mean())/X_train.std()
model=LogisticRegression()
# ハイパーパラメーターの値の候補を設定
model_param_set_grid = {model: {
"penalty": ["l1", "l2", "elasticnet"],
"C": [0.01, 0.1, 1, 10],
"solver": ["newton-cg", "lbfgs", "liblinear", "saga"],
"max_iter": [7000],
"class_weight": [None, "balanced"],
"random_state": [0]}}
max_score = 0
best_param = None
# グリッドサーチでハイパーパラメーターを探索
for model, param in model_param_set_grid.items():
clf = GridSearchCV(model, param)
clf.fit(X_train_std, y_train)
y_pred_val = clf.predict(X_val_std)
score = accuracy_score(y_val, y_pred_val)
if max_score < score:
max_score = score
best_param = clf.best_params_
print("ハイパーパラメーター:{}".format(best_param))
print("ベストスコア:",max_score)
model.fit(X_train_std, y_train)
print()
print('調整なし')
print(model.score(X_val_std, y_val))

- SVM
コード全体は上記と同じ
model=SVC()
# ハイパーパラメーターの値の候補を設定
model_param_set_grid = {model: {
"C": [0.01, 0.1, 1, 10],
"kernel": ["linear", "rbf"],
"gamma": ["scale", "auto", 0.01, 0.1, 1.0],
"class_weight": [None, "balanced"],
"random_state": [0],
}}

- RandomForest
model=RandomForestClassifier()
# ハイパーパラメーターの値の候補を設定
model_param_set_grid = {model: {
'n_estimators': [10, 20, 30, 50, 100, 300],
'max_depth': (10, 20, 30, 40, 50, None),
"class_weight": [None, "balanced"],
"random_state": [0],
}}

- k-NN
model=KNeighborsClassifier()
# ハイパーパラメーターの値の候補を設定
model_param_set_grid = {model: {
"n_neighbors":[1, 3, 5, 7, 9, 11, 15, 21], # 近傍点の数
"weights": ['uniform', 'distance'], # 近傍点の重み付けの方法
}}

MLPとLightGBMも試してみます。
- MLP
#MLP
import tensorflow as tf
import random
import os
from tensorflow.keras.utils import to_categorical
# 乱数を固定
tf.random.set_seed(0)
np.random.seed(0)
random.seed(0)
os.environ["PYTHONHASHSEED"] = "0"
target = df['VIEW']
df_table = df.drop(["Date","VIEW"],axis=1)
#ホールドアウト法
X_train ,X_val ,y_train ,y_val = train_test_split(
df_table, target,
test_size=0.2, shuffle=True,random_state=0
)
#訓練データと検証データの標準化
X_train_std = (X_train-X_train.mean())/X_train.std()
X_val_std = (X_val-X_train.mean())/X_train.std()
# モデルを定義
model = tf.keras.models.Sequential([
tf.keras.layers.Input(X_train_std.shape[1]),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(16, activation='relu'),
tf.keras.layers.Dense(2, activation='softmax')
])
# モデルをコンパイル
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01),
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(
X_train_std, to_categorical(y_train),
batch_size=256, epochs=100, verbose=False
)
y_pred = np.argmax(model.predict(X_train_std),axis=1)
train_acc = accuracy_score(
y_train, y_pred
)
print(train_acc)
y_pred_val = np.argmax(model.predict(X_val_std),axis=1)
val_acc = accuracy_score(
y_val, y_pred_val
)
print(val_acc)

- LightGBM
#LightGBM
import lightgbm as lgb
target = df['VIEW']
df_table = df.drop(["Date","VIEW"],axis=1)
#ホールドアウト法
X_train ,X_val ,y_train ,y_val = train_test_split(
df_table, target,
test_size=0.2, shuffle=True,random_state=0
)
#訓練データと検証データの標準化
X_train_std = (X_train-X_train.mean())/X_train.std()
X_val_std = (X_val-X_train.mean())/X_train.std()
# ハイパーパラメーターを定義
lgb_params = {
"objective":"binary",
"metric": "binary_error",
"force_row_wise" : True,
"seed" : 0,
'learning_rate': 0.1,
'min_data_in_leaf': 5
}
# LigthGBM用のデータセットを定義
lgb_train = lgb.Dataset(X_train_std, y_train)
lgb_valid = lgb.Dataset(X_val_std, y_val)
model = lgb.train(
params=lgb_params,
train_set=lgb_train,
valid_sets = [lgb_train, lgb_valid],
num_boost_round=100,
callbacks=[
lgb.early_stopping(stopping_rounds=50, verbose=True),
lgb.log_evaluation(100),
],
)
y_pred = model.predict(X_train_std)
train_acc = accuracy_score(y_train, np.where(y_pred>=0.5, 1, 0))
print(train_acc)
y_pred_val = model.predict(X_val_std)
val_acc = accuracy_score(y_val, np.where(y_pred_val>=0.5, 1, 0))
print(val_acc)

モデルの比較の結果、LightGBMが一番良い結果となりましたので、k-Foldで分類の上、LightGBMで学習評価してみましょう。

一番良い結果となりました!
8. 実証
こちらのモデルを使って、訓練データに含まれていない10月の気象データを使って富士山の見え方を予測し、実際どうだったか確認をしてみます。 #2023年10月の気象データをもとに10月1日から16日朝9:00の見え方を予測をしてみます。(LightGBM)実証コードまとめ
import pandas as pd
import numpy as np
from datetime import datetime
from datetime import timedelta
import lightgbm as lgb
#訓練データの読み込みとデータ処理
#Viewデータ:0:見えない、1: 見える(一部分だけ見える/霞がかかって見えるも含む)
df_View = pd.read_csv("/content/drive/MyDrive/Aidemy最終成果物/Fuji_View.csv")
#日付列をdatetime型にして時系列に変換
df_View["Date"] = pd.to_datetime(df_View["Date"])
#weatherデータ:気象庁のデータより、富士山、富士、静岡の気象データ(平均気温、降水量合計、日照時間、平均風速、平均湿度、平均雲量、降雪量合計、最多風向、天気概況(昼)、天気概況(夜))
df_weather = pd.read_csv("/content/drive/MyDrive/Aidemy最終成果物/Weather data.csv",encoding="shift-jis")
#日付列をdatetime型にして時系列に変換
df_weather["Date"] = pd.to_datetime(df_weather["Date"])
#df_Viewとdf_weatherを日付けをキーにして内部結合
df = pd.merge(df_View, df_weather, how="inner", on = "Date")
#実証データの読み込みと処理
#Viewデータ:0:見えない、1: 見える(一部分だけ見える/霞がかかって見えるも含む)(今回は空欄)
df_View_act = pd.read_csv("/content/drive/MyDrive/Aidemy最終成果物/Fuji_View_2023Oct.csv")
#日付列をdatetime型にして時系列に変換
df_View_act["Date"] = pd.to_datetime(df_View_act["Date"])
#df_Viewとdf_weatherを日付けをキーにして内部結合
df_act = pd.merge(df_View_act, df_weather, how="inner", on = "Date")
# All
# 訓練データとテストデータを結合しdf_tableを作成
df_table = pd.concat([df,df_act],axis=0).reset_index(drop=True)
# 訓練データとテストデータを判定するためのカラムを作成
df_table['Test_Flag'] = 0
df_table.loc[df.shape[0]: , 'Test_Flag'] = 1
#データの入っていない項目を削除
df_table = df_table.drop(["MtFuji_Sum_precipitation","MtFuji_windspeed","MtFuji_wind_direction","MtFuji_cloud","MtFuji_Sum_snow","MtFuji_weather","Fuji_cloud","Fuji_Sum_snow","Fuji_weather","Shizuoka_cloud"],axis=1)
#「///」や「--」が含まれているので置換する
df_table = df_table.replace(["///","--"],np.nan)
#object型になってしまっている項目をfloat型へ変更
df_table=df_table.astype({"Fuji_temperature":float,"Fuji_Sum_precipitation":float,"Fuji_windspeed":float,"Fuji_humidity":float,"Shizuoka_Sum_precipitation":float})
#欠損値が多い項目を削除
df_table = df_table.drop(["Shizuoka_Sum_precipitation","Shizuoka_Sum_snow"],axis=1)
#富士の湿度の欠損値への対応。富士の湿度と静岡の湿度は、平均がほぼ同じなため、静岡の値で補完する
df_table["Fuji_humidity"].fillna(df_table["Shizuoka_humidity"],inplace=True)
#他の項目も多く欠損しているので、データから削除する。
df_table = df_table.drop([347,681],axis=0)
df_table = df_table.reset_index(drop=True)
#天気データにOne-hot Encodingを施す
df_table = pd.get_dummies(df_table, columns=["Shizuoka_weather"])
# <追加>風向(Fuji_wind_direction,Shizuoka_wind_direction)を東西南北のデータに変更
wind_direction = ["Fuji_wind_direction","Shizuoka_wind_direction"]
for WD in wind_direction:
NORTH = []
for i in range(df_table.shape[0]):
if df_table[WD].str.contains('北')[i] == True :
NORTH.append(1)
else:
NORTH.append(0)
df_table[WD+"_NORTH"]= NORTH
SOUTH = []
for i in range(df_table.shape[0]):
if df_table[WD].str.contains('南')[i] == True :
SOUTH.append(1)
else:
SOUTH.append(0)
df_table[WD+"_SOUTH"]=SOUTH
WEST = []
for i in range(df_table.shape[0]):
if df_table[WD].str.contains('西')[i] == True:
WEST.append(1)
else:
WEST.append(0)
df_table[WD+"_WEST"]=WEST
EAST = []
for i in range(df_table.shape[0]):
if df_table[WD].str.contains('東')[i] == True:
EAST.append(1)
else:
EAST.append(0)
df_table[WD+"_EAST"]=EAST
#Fuji_wind_direction,Shizuoka_wind_directionを削除
df_table = df_table.drop(["Fuji_wind_direction","Shizuoka_wind_direction"],axis=1)
#訓練データと実証データをわける
Train = df_table[df_table['Test_Flag']==0]
Act = df_table[df_table['Test_Flag']==1].reset_index(drop=True)
print(Act["Date"])
target = Train['VIEW']
Train = Train.drop(["Date","VIEW","Test_Flag"],axis=1)
Act = Act.drop(["Date","VIEW","Test_Flag"],axis=1)
#KFold法
cv = KFold(n_splits=3, random_state=0, shuffle=True)
# ハイパーパラメーターを定義
lgb_params = {
"objective":"binary",
"metric": "binary_error",
"force_row_wise" : True,
"seed" : 0,
'learning_rate': 0.1,
'min_data_in_leaf': 5
}
for i ,(trn_index, val_index) in enumerate(cv.split(Train, target)):
X_train ,X_val = Train.loc[trn_index], Train.loc[val_index]
y_train ,y_val = target[trn_index], target[val_index]
#訓練データ、検証データ、実証データの標準化
X_train_std = (X_train-X_train.mean())/X_train.std()
X_val_std = (X_val-X_train.mean())/X_train.std()
X_act_std = (Act-X_train.mean())/X_train.std()
# LigthGBM用のデータセットを定義
lgb_train = lgb.Dataset(X_train_std, y_train)
lgb_valid = lgb.Dataset(X_val_std, y_val)
model = lgb.train(
params=lgb_params,
train_set=lgb_train,
valid_sets = [lgb_train, lgb_valid],
num_boost_round=100,
callbacks=[
lgb.early_stopping(stopping_rounds=50, verbose=True),
lgb.log_evaluation(100),
],
)
y_pred_act = model.predict(X_act_std)
print(np.where(y_pred_act>=0.5, 1, 0))
10月1日~16日の9:00時点の気象データを使って予測をしてみた結果がこちらです。
| 日付 | 予測結果 | 富士山画像 | 結果 |
|---|---|---|---|
| 2023/10/1 | 0 |  |
見えない〇 |
| 2023/10/2 | 1 |  |
見える〇 |
| 2023/10/3 | 1 |  |
見える〇 |
| 2023/10/4 | 0 |  |
見えない〇 |
| 2023/10/5 | 0 |  |
見える× |
| 2023/10/6 | 1 |  |
見える〇 |
| 2023/10/7 | 1 |  |
見える〇 |
| 2023/10/8 | 1 |  |
見える〇 |
| 2023/10/9 | 0 |  |
見えない〇 |
| 2023/10/10 | 0 |  |
見える× |
| 2023/10/11 | 1 |  |
見えない× |
| 2023/10/12 | 1 |  |
見える〇 |
| 2023/10/13 | 1 |  |
見える〇 |
| 2023/10/14 | 1 |  |
見える〇 |
| 2023/10/15 | 0 |  |
見えない〇 |
| 2023/10/16 | 1 |  |
見える〇 |
ということで正解率 約81% でした!
おわりに
まだまだ初心者できちんと理解できていないところも多く、ひとつひとつ復習しつつわからないところを調べつつで思ったよりも時間がかかってしまいましたが、良い機会になりました。
次に静岡方面に旅行に行く際には、事前に天気予報の情報をモデルにあてはめ見え方予測をして、富士山が見える日に行きたいと思います![]()
また今回、富士山の見え方は写真をもとに自分で目視して確認しデータを作成しましたが、今後、画像認識の勉強をして自動で認識させてみたいと思います。