推計統計学
様々な種類を持つ統計学ですが、代表的なものとして「記述統計学」、「推計統計学」、「ベイズ統計学」の3種類があります。(今回は「ベイズ統計学」に関しては置いておきます。)
「記述統計学」と「推計統計学」はそれぞれ、記述統計学 = 手持ちのデータを集計する方法の学問、
推計統計学 = 手持ちのデータを分析して、まだ手に入れていないデータについて議論する方法を学ぶ学問と説明されます。
(引用:Logic of Blue 記述統計の基礎)
つまり、記述統計学ではデータ(標本)から平均や標準偏差を求めるのに対して、推計統計学では標本をベースに統計的な分析を実施して、その背後にあるデータ全体(母集団)を求めます。

大数の法則
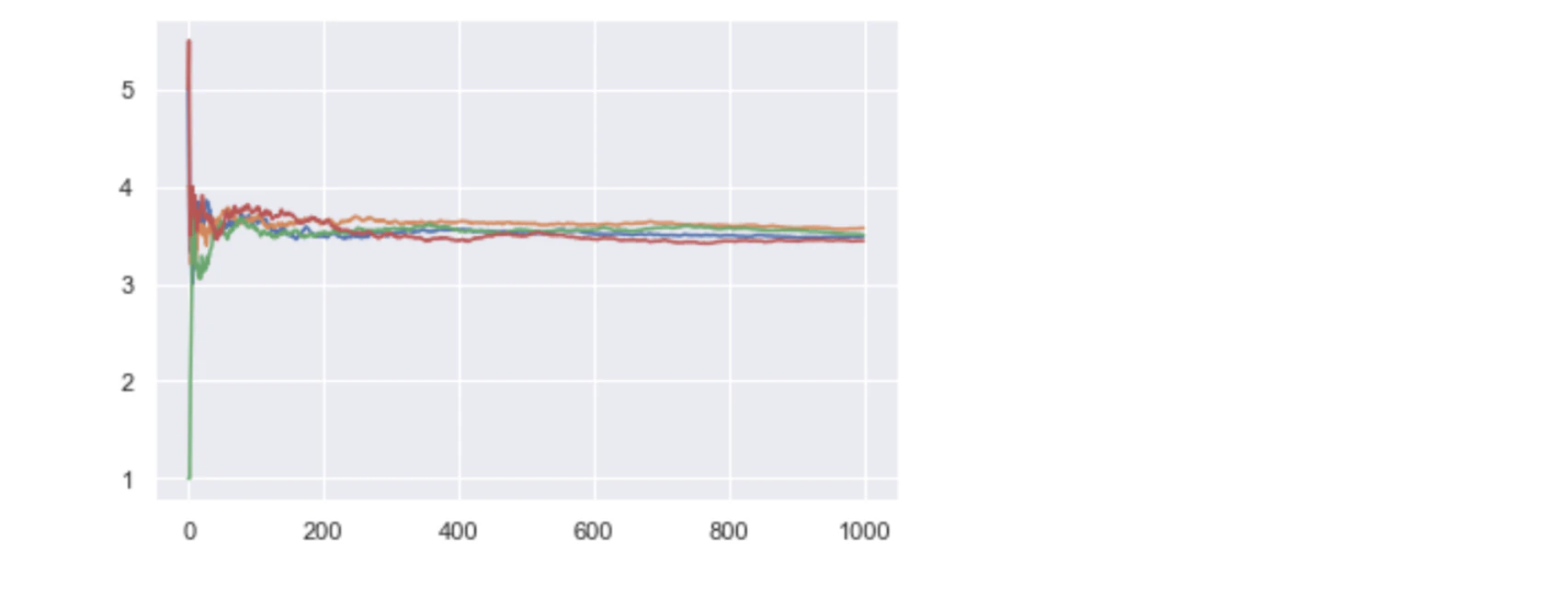
サイコロを投げて出目を調べる事を考えます。
サイコロをどんどん振っていき、それまでの平均値の軌跡をたどります。具体的には、1回目投げた時の目が $1$の時は平均 $1$、次に投げたときに $3$が出た場合は、$(1+3)/2$で平均は $2$というように、続けて平均値を計算します。
# 大数の法則
# 計算回数
calc_times =1000
# サイコロ
sample_array = np.array([1, 2, 3, 4, 5, 6])
number_cnt = np.arange(1, calc_times + 1)
# 4つのパスを生成
for i in range(4):
p = np.random.choice(sample_array, calc_times).cumsum()
plt.plot(p / number_cnt)
中心極限定理
中心極限定理は「ある母集団から無作為に抽出された標本の平均は、サンプルのサイズを大きくすると母集団の平均(母平均)に近づく」と言うもので、今の場合、サイコロを投げる回数 $N$ が増えれば増えるほど、標本平均が正規分布の形になっていく法則です。
# 中心極限定理
def function_central_theory(N):
sample_array = np.array([1, 2, 3, 4, 5, 6])
numaber_cnt = np.arange(1, N + 1) * 1.0
mean_array = np.array([])
for i in range(1000):
cum_variables = np.random.choice(sample_array, N).cumsum()*1.0
mean_array = np.append(mean_array, cum_variables[N-1] / N)
plt.hist(mean_array)
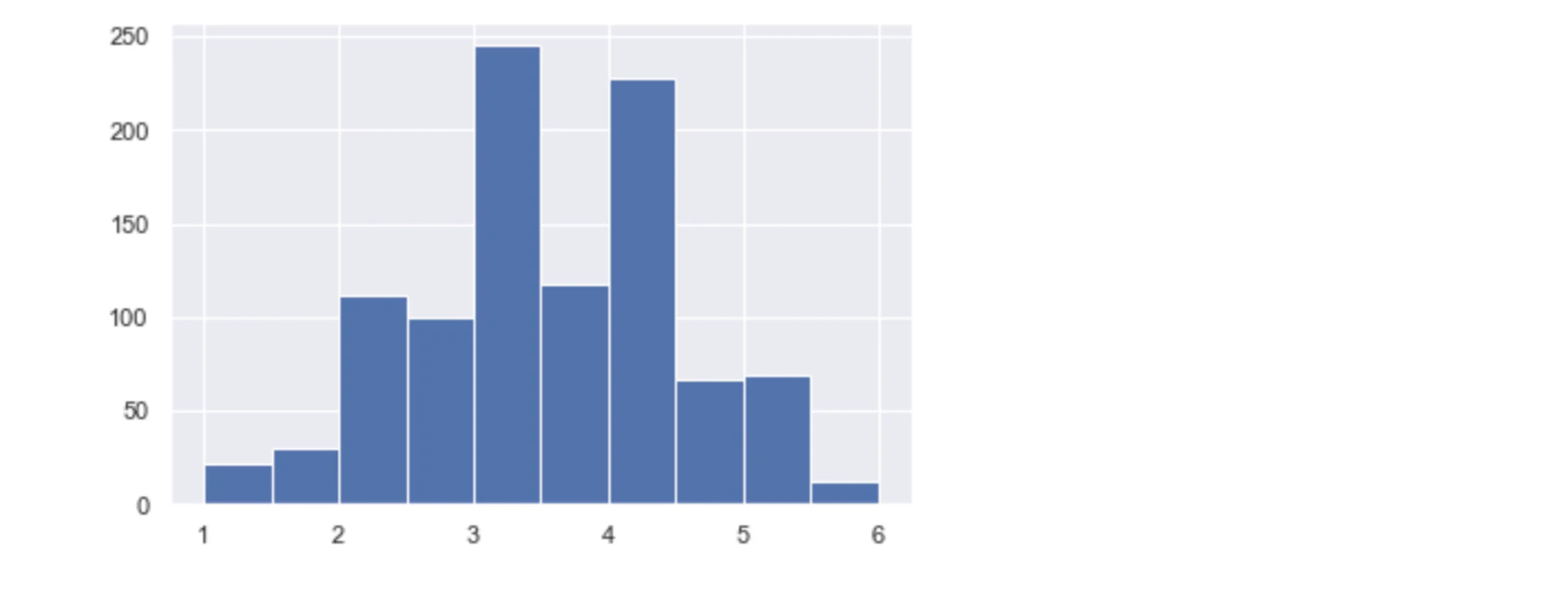
上記の関数function_central_theory(N)を用いて、 $N$ を増加させていき、その日ストグラフを見てみます。
# N=3
function_central_theory(3)
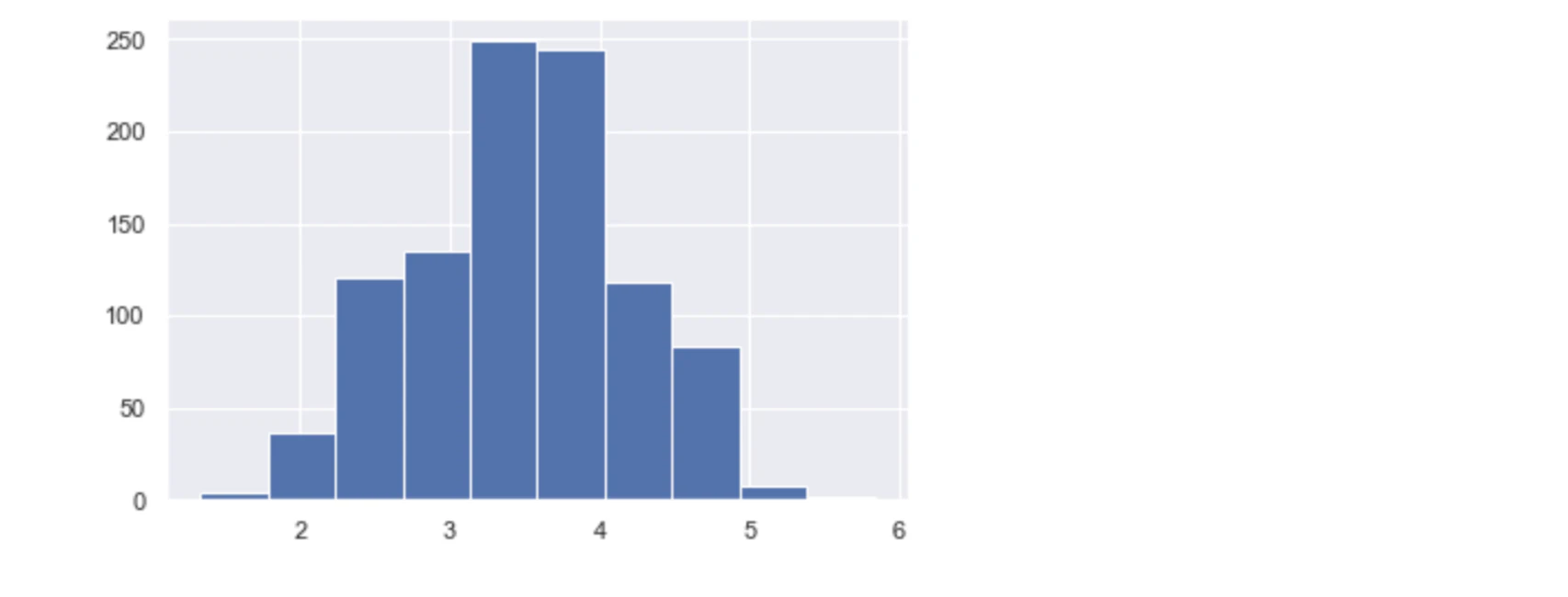
# N=6
function_central_theory(6)
# N= 10^4
function_central_theory(10**4)
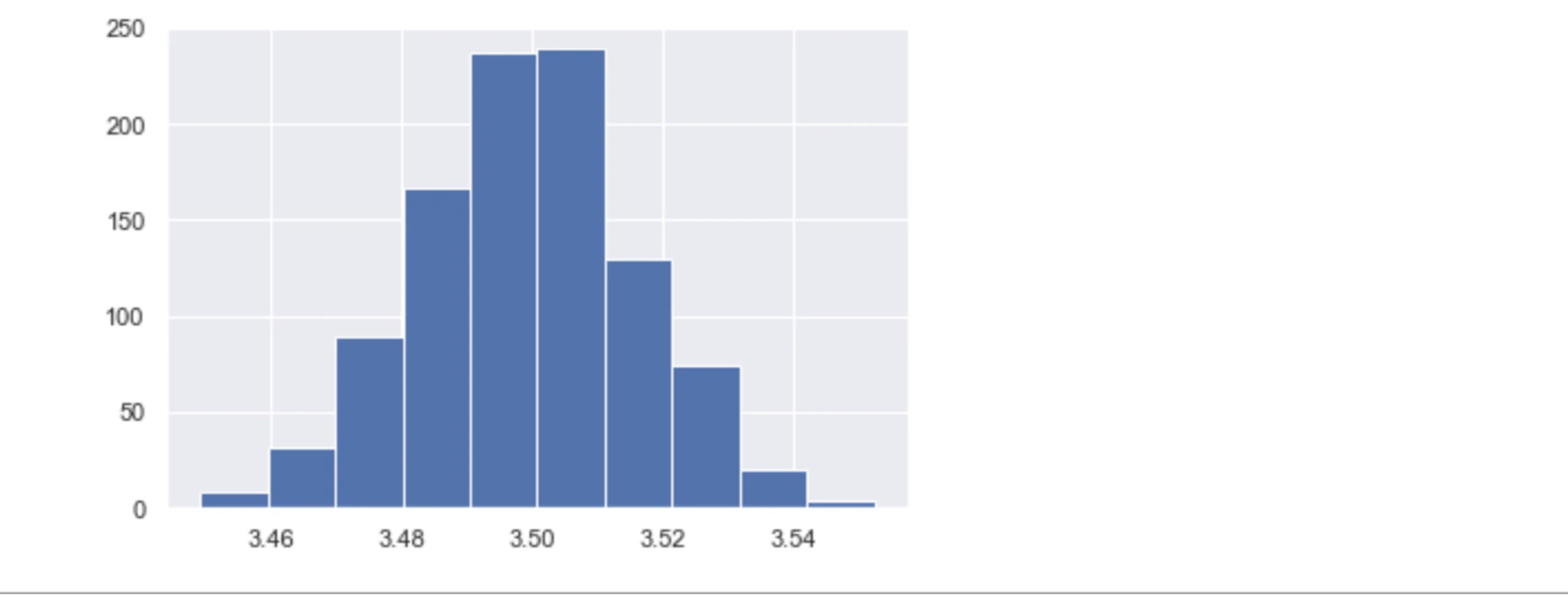
$N$ をどんどん増やしていくと、正規分布に近づいていくのが確認できます。
参考文献:
記述統計学と推計統計学の違い