背景とやったこと
GCPのCloud Functionsで「りんご」なら「果物」、「いちご」なら「野菜」、のように毎回入力をペアとなる単語に変換したかったのですが、
if文でゴリゴリ変換するのと辞書型の対応表を用意して変換するのどちらが早いのか疑問に思ったので試してみました。
注)なお自分の場合はコールドスタートになることが多いので、辞書型生成も含めた所要時間を計算しています
結論
毎回辞書型の読み込みが発生する場合(AWSのLambdaやGCPのCloud Functionsのコールドスタート時など)は
if文の方が速い。
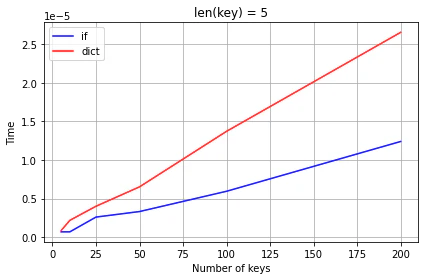
keyが5文字の場合
keyが10文字の場合
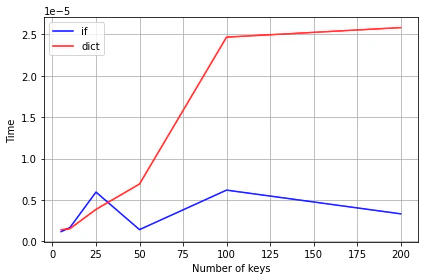
(Colab使ったので各回の処理速度が安定しなかったのかもしれません)
if文の圧勝でした。
コールドスタートでない場合は辞書型の方が速い気がするので、気が向いたら試してみます
(if文書くのめんどくさい...)
環境
Python 3
Google Colaboratory
検証条件
・キーの数を変えて同一セル内で比較するコードを100回実行し、所要時間の平均で比較
・キー数は5個、10個、25個、50個、100個、200個の6パターン
検証コード例
準備
import time
import random, string
from statistics import mean
# ランダム文字列作成(参考の「Pythonを使ってランダムな文字列を生成」からお借りしました)
def randomname(n):
return ''.join(random.choices(string.ascii_letters + string.digits, k=n))
range_ = 5
smp_dict = {}
key_list = []
for i in range(range_):
key = randomname(10)
smp_dict[key] = randomname(20)
key_list.append(key)
# if文作成
for i in range(range_):
if i == 0:
print(" if key == '{}':".format(key_list[i]))
else :
print(" elif key == '{}':".format(key_list[i]))
print(" content = '{}'".format(smp_dict[key_list[i]]))
上で出力したif文をコピペとかして検証用コード作成
rnd_key_list = smp_dict.keys()
time_list = []
for i in range(100):
start = time.time()
for key in rnd_key_list:
if key == 's9MT4kkqyg':
content = 'JpNeK8tDV1FyQfXdzTS0'
elif key == 'PKFEikSHFM':
content = 'RxhZqdfsCqLTuxBzIrdV'
elif key == '04Ex4druSy':
content = 'GmT0Jx78xPuMrOyVPuik'
elif key == 'JUJ85l8ayb':
content = 'xVtzS0HnHHEOHML87z85'
elif key == 'HnqyHAIcLm':
content = 'NRNoem9JpGUcFxvccaxD'
time_list.append(elapsed_time)
if_mean = mean(time_list)
print ("if Mean time:{}".format(if_mean) + "[sec]")
time_list = []
for i in range(100):
start = time.time()
Smp_dict = {'s9MT4kkqyg': 'JpNeK8tDV1FyQfXdzTS0', 'PKFEikSHFM': 'RxhZqdfsCqLTuxBzIrdV', '04Ex4druSy': 'GmT0Jx78xPuMrOyVPuik', 'JUJ85l8ayb': 'xVtzS0HnHHEOHML87z85', 'HnqyHAIcLm': 'NRNoem9JpGUcFxvccaxD'}
for key in rnd_key_list:
content = Smp_dict[key]
elapsed_time = time.time() - start
time_list.append(elapsed_time)
dict_mean = mean(time_list)
print ("dict Mean time:{}".format(dict_mean) + "[sec]")
検証用コードの解説
smp_dict = {}
key_list = []
for i in range(100):
key = randomname(10)
smp_dict[key] = randomname(20)
key_list.append(key)
->
ランダムな10文字をキーに、同じくランダムな20文字をバリューにした辞書型&キーリストを作成
rnd_key_list = smp_dict.keys()
->
辞書型を作成する際に順番は保持されないので、条件を同じくするために新たにキーリストを作成
@shiracamusさんから最近は保持するとのコメントいただきました!
start = time.time()
Smp_dict = {'BGM85yImoJ': 'i5GozNMNXGdfrlVgmVA0', ...}
->
計測を開始してから辞書型を読み込み