Kaggleなどのコンペで人気のXGBoostをiOSアプリで動作させたので、その方法を紹介します。
XGBoostとは
勾配ブースティング決定木 (GBDT, Gradient Boosting Decision Tree)を実装したライブラリです。
GBDTとは
勾配ブースティング決定木とは、手短に説明すると『決定木を複数組み合わせたアンサンブル学習の一種で、勾配降下法を用いて学習を行うもの』です。
決定木とは、木構造を用いて回帰や分類を行う手法です。アンサンブル学習は、複数の決定木を用いて予想の精度を上げる手法です。
ブースティングというのは、アンサンブル学習の一種で、それぞれの学習器を直列に学習する手法です。それ以外のアンサンブル学習の手法としては学習器を並列に学習させるバギングなどがあります。例えば、ランダムフォレストはバギングの一種です。
勾配降下法とは、ディープラーニングでもよく用いられる手法で、重みを少しずつ更新して勾配が最小になるように学習する手法です。
図で説明します
駆け足過ぎたので、図で説明します。
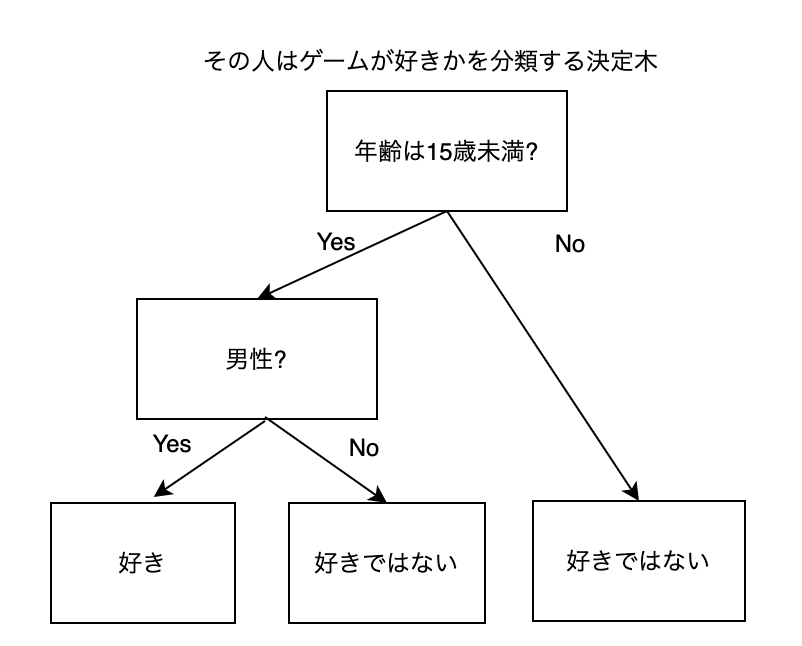
例えば、決定木は下の図のようにして、その人がゲーム好きかどうかを予想します。
【決定木の例】
ブースティングを用いた場合は、複数の決定木を用いて予想値を修正していきます。
【ブースティング決定木の例】
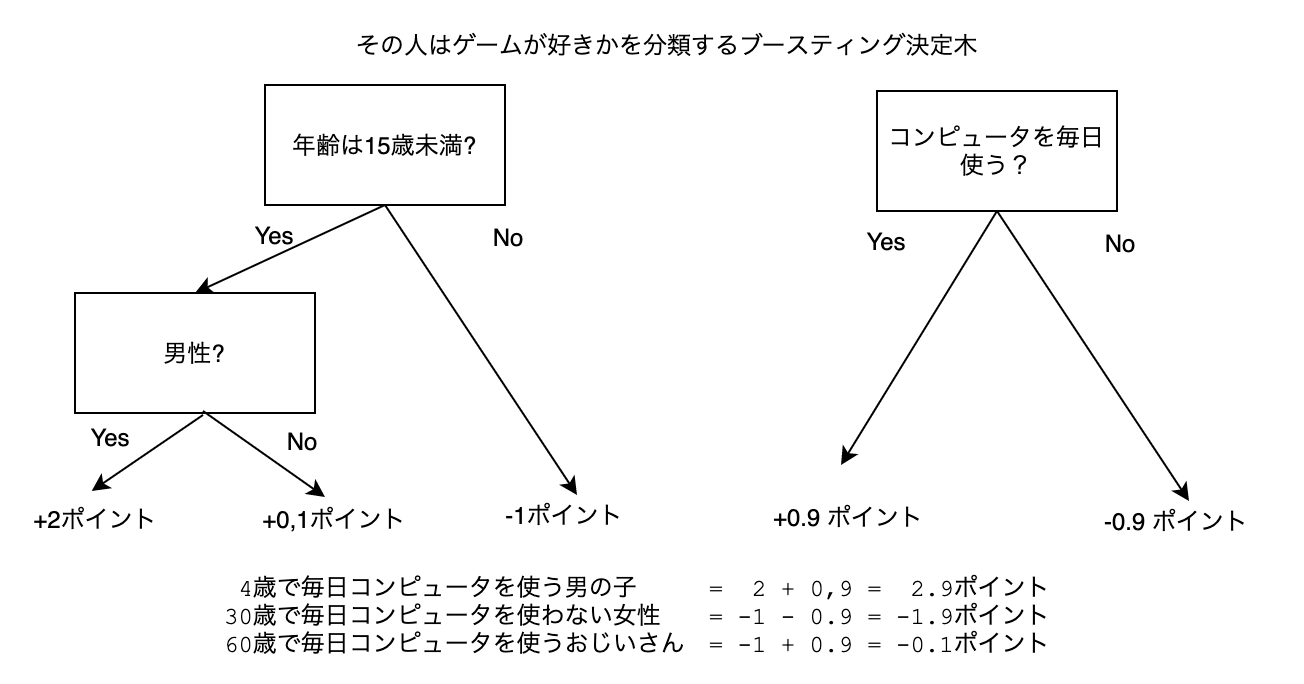
最初の木で出したポイントと、2番目の木で出したポイントを足して、最終的なポイントを出しています。ここではポイントまでしか出していませんが、最終的にはこれを確率に変換します。
なぜこのようにすると予想の精度が上がるのか?についてはこちらに解説がありました。
学習は最初の木を学習させたあと、その予想結果との差に対して新たな木を作って学習させます。このように順番に学習していくので、「直列に学習する」と表現してます。
また、予想結果の差に対して新たに学習していくので、勾配に従って学習していくことになります。これが勾配降下法に相当します。
学習についてはこちらのブログがわかりやすかったです。
XGBoostを使ってみる
Google Colabを使ってXGBoostを試してみます。ほぼこちらのブログの内容の写経になっています。
Python: XGBoost を使ってみる - 乳がんデータセットを分類してみる
乳がんデータセットを使って、特徴量から乳がんであるかを予想する二値分類問題です。
import xgboost as xgb
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from matplotlib import pyplot as plt
dataset = datasets.load_breast_cancer()
X, y = dataset.data, dataset.target
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.3,
shuffle=True,
random_state=42,
stratify=y)
clf = xgb.XGBClassifier(objective='binary:logistic',
n_estimators=1000)
evals_result = {}
clf.fit(X_train, y_train,
eval_metric='logloss',
eval_set=[
(X_train, y_train),
(X_test, y_test),
],
early_stopping_rounds=10,
callbacks=[
xgb.callback.record_evaluation(evals_result)
],
)
y_pred = clf.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print('Accuracy:', acc)
# 出力結果
# Accuracy: 0.9649122807017544
Core MLに変換する
モデルができたので、今度はCore MLに変換します。
Core ML ToolsはXGBoostの変換に対応しているので、簡単に変換することができます。
pip install -U coremltools==4.0
import coremltools as ct
coreml_model = ct.converters.xgboost.convert(clf , mode='classifier')
coreml_model.save('xgboost_test.mlmodel')
iOSアプリで動作させる
iOSアプリで動作させます。Core MLを簡単に試せるリポジトリを作ったのでこれを使います。
このリポジトリをCloneして、変換したモデルをドラッグ & ドロップします。
モデルの情報はこんな感じです。
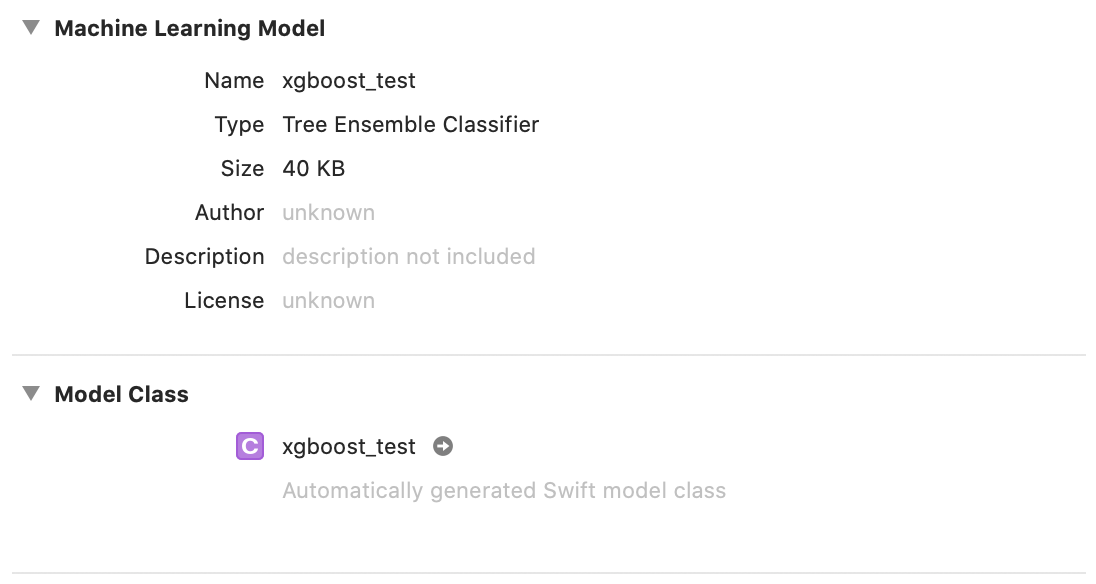

早速予想してみましょう。
モデルに入力する情報(特徴量)が30もあるのでちょっと大変ですが、Google Colabでダウンロードしたデータセットから取得して、xgboost_testInputの初期化パラメータに与えます。
@IBAction func buttonSimpleMLTapped(_ sender: Any) {
let model = xgboost_test()
let inputToModel: xgboost_testInput = xgboost_testInput(
f0: 1.300e+01,
f1: 2.078e+01,
f2: 8.351e+01,
f3: 5.194e+02,
f4: 1.135e-01,
f5: 7.589e-02,
f6: 3.136e-02,
f7: 2.645e-02,
f8: 2.540e-01,
f9: 6.087e-02,
f10: 4.202e-01,
f11: 1.322e+00,
f12: 2.873e+00,
f13: 3.478e+01,
f14: 7.017e-03,
f15: 1.142e-02,
f16: 1.949e-02,
f17: 1.153e-02,
f18: 2.951e-02,
f19: 1.533e-03,
f20: 1.416e+01,
f21: 2.411e+01,
f22: 9.082e+01,
f23: 6.167e+02,
f24: 1.297e-01,
f25: 1.105e-01,
f26: 8.112e-02,
f27: 6.296e-02,
f28: 3.196e-01,
f29: 6.435e-02
)
if let prediction = try? model.prediction(input: inputToModel) {
print(prediction.target)
print(prediction.classProbability)
}
}
アプリを実行するとボタンが複数出てくるので一番上のボタンを押します。
ボタンを押すと、Xcodeのコンソールに予想結果が出力されます。
1
[0: 0.019117622730040473, 1: 0.9808823772699595]
うまく分類できているようです。
最後に
2020年11月現在、XGBoostをiOSで動かしたい人はほとんどいないのか、ネット上にはほとんど情報がありません。
また、Core ML Toolsのドキュメントもあまり親切ではないので、もしXGBoostをiOSで動かしたいという方の参考になりましたら幸いです。
NoteではiOS開発、とくにCoreML、ARKit、Metalなどについて定期的に発信していますので、フォローしていただけますと幸いです。
https://note.com/tokyoyoshida
Twitterでも発信しています。
https://twitter.com/jugemjugemjugem
参考資料
勾配ブースティング決定木についてはこちらのブログの説明が詳しかったです。
ブースティングについては上のブログにはあまり説明がなく、こちらの資料がわかりやすかったです。
GBDTと勾配降下法の関係については、こちらのブログが参考になりました。