Metal Best Practicesは、iOS/MacOS/tvOSのAPIであるMetalを用いた設計のベストプラクティスガイドです。
本稿では、何回かに分けてこのガイドを読み解き、コード上での実験を交えて解説していきます。
読んでそのまま理解できそうなところは飛ばしますので、原文を読みながら原文のガイドとしてご利用下さい。
また、iOSの記事なので他のOS(MacOS, tvOS)についての記載は割愛します。
他の記事の一覧は、初回記事よりご覧下さい。
Indirect Buffers (間接バッファ)
ベストプラクティス:描画またはディスパッチ呼び出し引数がGPUによって動的に生成される場合は、間接バッファーを使用します。
描画に必要となる頂点などのデータの計算にCompute Shaderを用いてGPUで処理する場合、その結果をCPUが受け取ってから、改めてGPUに描画を依頼するよりは、GPUが処理したデータをそのままGPUに描画させたほうがCPU⇔GPU間の無駄な転送がなくなるので処理が早くなるという話です。
そのための仕組みとして間接バッファ(Indirect Buffers)というものがあります。この間接バッファを使ってGPUで処理した描画用のデータは、そのままGPUから描画処理に渡すことが出来ます。
またMetal Best Praciticeでは直接触れられていませんが、間接バッファに似たもので間接コマンドバッファ(Indirect Command Buffers = よくICBと略します)というものがあります。これは、描画用のデータだけでなく、コマンドバッファそのものをGPUに渡してしまうものです。通常、描画処理の依頼は、CPU側からdrawPrimitivesなどを呼び出して行いますが、ICBを使用するとシェーダ関数の中でdraw_primitivesを呼び出して描画を依頼することが出来ます。
コードで確認してみる
今回はICBを試してみたいと思います。サンプルは次のリポジトリにあるものを使います。
実行イメージはこんな感じです。パーティクルが上から下へ流れていきます。
1.普通にCPUからdrawPrimitivesを実行する場合
サンプルコードそのままになりますが、簡単に紹介します。
drawメソッドでは、パーティクルの座標を上から下に流すための計算をGPUに依頼し、その結果を使って描画をしています。
なおこのサンプルではトリプルバッファリングという手法でCPUとGPUの処理の並列性を高めています。トリプルバッファリングについてはこちらの記事をご覧ください。
func draw(in view: MTKView) {
// パーティクルの座標の計算をCompute Shaderに依頼する
func calcParticlePostion() {
computeSemaphore.wait()
let commandBuffer = metalCommandQueue.makeCommandBuffer()!
let encoder = commandBuffer.makeComputeCommandEncoder()!
encoder.setComputePipelineState(computePipeline)
encoder.setBuffer(particleBuffers[beforeBufferIndex], offset: 0, index: 0)
encoder.setBuffer(particleBuffers[currentBufferIndex], offset: 0, index: 1)
encoder.setBytes(&Coordinator.numberOfParticles, length: MemoryLayout<Int>.stride, index: 2)
encoder.dispatchThreadgroups(threadgroupsPerGrid,
threadsPerThreadgroup: threadsPerThreadgroup)
encoder.endEncoding()
commandBuffer.addCompletedHandler {[weak self] _ in
self?.computeSemaphore.signal()
}
commandBuffer.commit()
}
guard let drawable = view.currentDrawable else {return}
renderSemaphore.wait()
let commandBuffer = metalCommandQueue.makeCommandBuffer()!
currentBufferIndex = (currentBufferIndex + 1) % Coordinator.maxBuffers
calcParticlePostion()
renderPassDescriptor.colorAttachments[0].texture = drawable.texture
renderPassDescriptor.colorAttachments[0].loadAction = .clear
renderPassDescriptor.colorAttachments[0].clearColor = MTLClearColorMake(0.8, 0.7, 0.1, 1.0)
let renderEncoder = commandBuffer.makeRenderCommandEncoder(descriptor: renderPassDescriptor)!
guard let renderPipeline = renderPipeline else {fatalError()}
renderEncoder.setRenderPipelineState(renderPipeline)
uniforms.time += preferredFramesTime
renderEncoder.setVertexBuffer(particleBuffers[currentBufferIndex], offset: 0, index: 0)
renderEncoder.setVertexBytes(&uniforms, length: MemoryLayout<Uniforms>.stride, index: 2)
// ここで実際に描画している
renderEncoder.drawPrimitives(type: .point, vertexStart: 0, vertexCount: Coordinator.numberOfParticles)
renderEncoder.endEncoding()
commandBuffer.present(drawable)
commandBuffer.addCompletedHandler {[weak self] _ in
self?.renderSemaphore.signal()
}
commandBuffer.commit()
}
また、負荷をかけるためにCoordinatorクラスのnumberOfParticlesというstatic変数に1_000_000を入れて実行してみます。この量になるとパーティクルが画面を埋め尽くし、単なる青い画面になります。

実行してみると60FPS出ていました。さすがトリプルバッファリング + GPUの処理ですね。
2.ICBを用いてGPUからdraw_primitivesを実行する場合
次に、ICBを用いてシェーダーからdraw_primitivesを実行してみます。
このコードはリポジトリにIndirectCommandBuffersというサンプルとして入っています。
まず、ICBを作成します。
// icb経由でシェーダーに渡すRenderPipelineState
struct Model {
var pipelineState: MTLRenderPipelineState
}
class Coordinator : NSObject, MTKViewDelegate {
var icbPipeline: MTLComputePipelineState!
var icb: MTLIndirectCommandBuffer!
var icbFunction: MTLFunction!
var icbBuffer: MTLBuffer!
lazy var models = [Model(pipelineState: renderPipeline)]
var modelsBuffer: MTLBuffer!
init(_ parent: IndirectCommandBuffersMetalView) {
// icbの作成
func buildICB() {
guard let library = self.metalDevice.makeDefaultLibrary() else {fatalError()}
let icbDescriptor = MTLIndirectCommandBufferDescriptor()
icbDescriptor.commandTypes = [.draw]
icbDescriptor.inheritBuffers = false
icbDescriptor.inheritPipelineState = false
icbDescriptor.maxVertexBufferBindCount = 25
icbDescriptor.maxFragmentBufferBindCount = 25
guard let icb = metalDevice.makeIndirectCommandBuffer(descriptor: icbDescriptor, maxCommandCount: 1, options: []) else {
fatalError()
}
self.icb = icb
icbFunction = library.makeFunction(name: "particleComputeICBShader")
icbPipeline = try! metalDevice.makeComputePipelineState(function: icbFunction)
let icbEncoder = icbFunction.makeArgumentEncoder(bufferIndex: 3)
icbBuffer = metalDevice.makeBuffer(length: icbEncoder.encodedLength, options: [])
icbEncoder.setArgumentBuffer(icbBuffer, offset: 0)
icbEncoder.setIndirectCommandBuffer(icb, index: 0)
var mBuffers: [MTLBuffer] = []
var mBuffersLength = 0
for _ in models {
let encoder = icbFunction.makeArgumentEncoder(bufferIndex: 4)
let mBuffer = metalDevice.makeBuffer(length: encoder.encodedLength, options: [])!
encoder.setArgumentBuffer(mBuffer, offset: 0)
encoder.setRenderPipelineState(renderPipeline, index: 0)
mBuffers.append(mBuffer)
mBuffersLength += mBuffer.length
}
modelsBuffer = metalDevice.makeBuffer(length: mBuffersLength, options: [])
var offset = 0
for mBuffer in mBuffers {
var pointer = modelsBuffer.contents()
pointer = pointer.advanced(by: offset)
pointer.copyMemory(from: mBuffer.contents(), byteCount: mBuffer.length)
offset += mBuffer.length
}
}
// 略(いろんな初期化)
buildICB()
}
次にdrawメソッドでICBの実行を依頼します。
func draw(in view: MTKView) {
func calcParticlePostion(_ commandBuffer: MTLCommandBuffer) {
let encoder = commandBuffer.makeComputeCommandEncoder()!
encoder.setComputePipelineState(icbPipeline)
encoder.setBuffer(particleBuffers[beforeBufferIndex], offset: 0, index: 0)
encoder.setBuffer(particleBuffers[currentBufferIndex], offset: 0, index: 1)
encoder.setBytes(&Coordinator.numberOfParticles, length: MemoryLayout<Int>.stride, index: 2)
// ICBをシェーダに渡す
encoder.setBuffer(icbBuffer, offset: 0, index: 3)
encoder.setBuffer(modelsBuffer, offset: 0, index: 4)
encoder.dispatchThreadgroups(threadgroupsPerGrid,
threadsPerThreadgroup: threadsPerThreadgroup)
encoder.useResource(icb, usage: .write)
encoder.useResource(particleBuffers[beforeBufferIndex], usage: .read)
encoder.useResource(particleBuffers[currentBufferIndex], usage: .write)
encoder.endEncoding()
}
guard let drawable = view.currentDrawable else {return}
semaphore.wait()
let commandBuffer = metalCommandQueue.makeCommandBuffer()!
currentBufferIndex = (currentBufferIndex + 1) % Coordinator.maxBuffers
calcParticlePostion(commandBuffer)
// ICBの最適化
let blitEncoder = commandBuffer.makeBlitCommandEncoder()!
blitEncoder.optimizeIndirectCommandBuffer(icb, range: 0..<1)
blitEncoder.endEncoding()
renderPassDescriptor.colorAttachments[0].texture = drawable.texture
renderPassDescriptor.colorAttachments[0].loadAction = .clear
renderPassDescriptor.colorAttachments[0].clearColor = MTLClearColorMake(0.8, 0.7, 0.1, 1.0)
let renderEncoder = commandBuffer.makeRenderCommandEncoder(descriptor: renderPassDescriptor)!
// ICBのコマンドを実行する
renderEncoder.executeCommandsInBuffer(icb, range: 0..<1)
renderEncoder.endEncoding()
commandBuffer.present(drawable)
commandBuffer.addCompletedHandler {[weak self] _ in
self?.semaphore.signal()
}
commandBuffer.commit()
}
シェーダーでは、ICBを受け取って描画のコマンドを発行します。
kernel void particleComputeICBShader(
device Particle *beforeParticles [[ buffer(0)]],
device Particle *particles [[ buffer(1)]],
const device int *numberOfParticles [[ buffer(2)]],
device ICBContainer *icbContainer [[buffer(3)]],
const device Model *modelsArray [[ buffer(4)]],
uint gid [[thread_position_in_grid]]
){
if (gid < uint(*numberOfParticles)) {
float2 newPosition = beforeParticles[gid].position;
if (newPosition.y > -1) {
newPosition.y -= 0.01;
} else {
newPosition.y += 2 - 0.01;
}
particles[gid].position = newPosition;
// コマンドを取り出す
render_command cmd(icbContainer->icb, 0);
// Pipeline Stateやバッファをコマンドに渡す
cmd.set_render_pipeline_state(modelsArray[0].pipelineState);
cmd.set_vertex_buffer(beforeParticles, 0);
// 描画の実行
cmd.draw_primitives(primitive_type::point, 0, *numberOfParticles, 1);
}
}
実行すると、先程と同じ青い画面が出ます。
しかしここで意外なことが起きました。59FPSしか出ていないのです。最初にした普通のトリプルバッファリングの実装のほうがパフォーマンスが出ています。
ということでなぜそうなったのかを分析してみます。
Metal System Traceを使って、処理の状況を確認します。このツールの使い方はこちらをご覧ください。
(今回iPhoneで検証していましたが、Metal System TraceがなぜかiPhoneで実行した場合トレースをしてくれなかったので、iPadに切り替えて検証しています。iPadの場合、普通のトリプルバッファリングの場合は50FPS、ICBの場合は49FPSと若干結果が違いますが、ICBのほうが遅いという傾向は同じでした)
まず、普通のトリプルバッファリングの場合のトレースです。

Compute Shader→Vertex Shader→Fragment Shader→描画という流れが続いていますが、Fragment Shaderの処理に並行して次のフレームのCompute Shaderの処理が始まっていることがわかります。これは、普通のトリプルバッファリングの場合は、Compute Shaderの処理とRenderの処理は関係がないため、コマンドバッファは別々のものを使用しているためです。
次に、ICBの場合のトレースです。
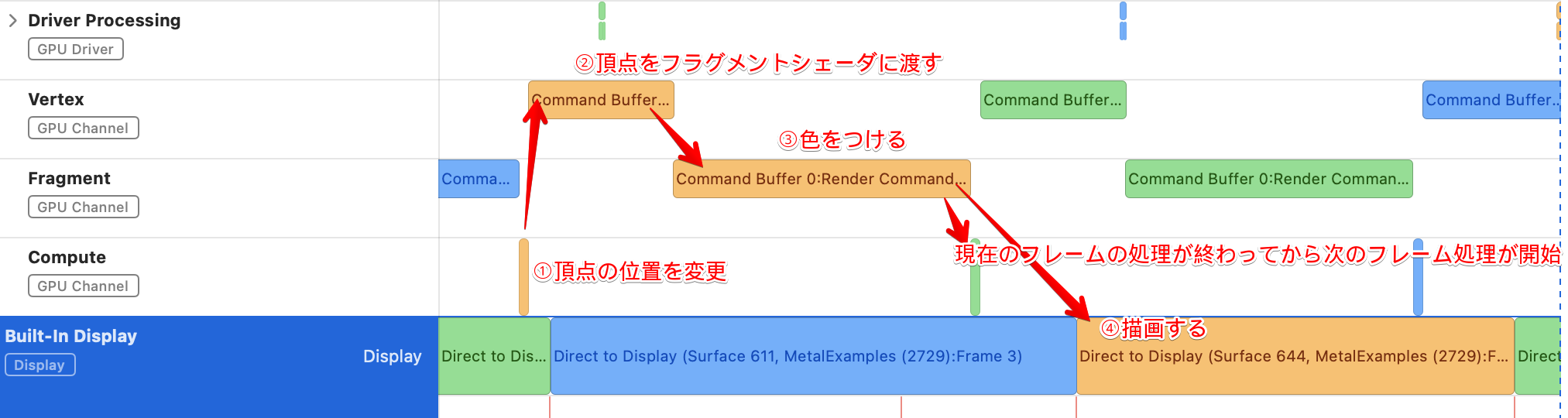
ICBの場合は、現在のフレームの処理がすべて終わってから次のフレームの処理が始まっています。ICBの場合は、Compute Shaderの処理の中でRenderの処理をするため、コマンドバッファは1つにしています。このため、処理の待ち時間が長くなってしまったようです。(コマンドバッファを別々にする方法はあるのかもしれませんが、今回調べた限りでは見つからず、実際に別々にして試してみてもうまく動作しませんでした)
さらにですが、普通のトリプルバッファリングで無駄な転送が発生しているかというとそんなことはありませんでした。
普通のトリプルバッファリングの場合のトレースの状況を再掲します。
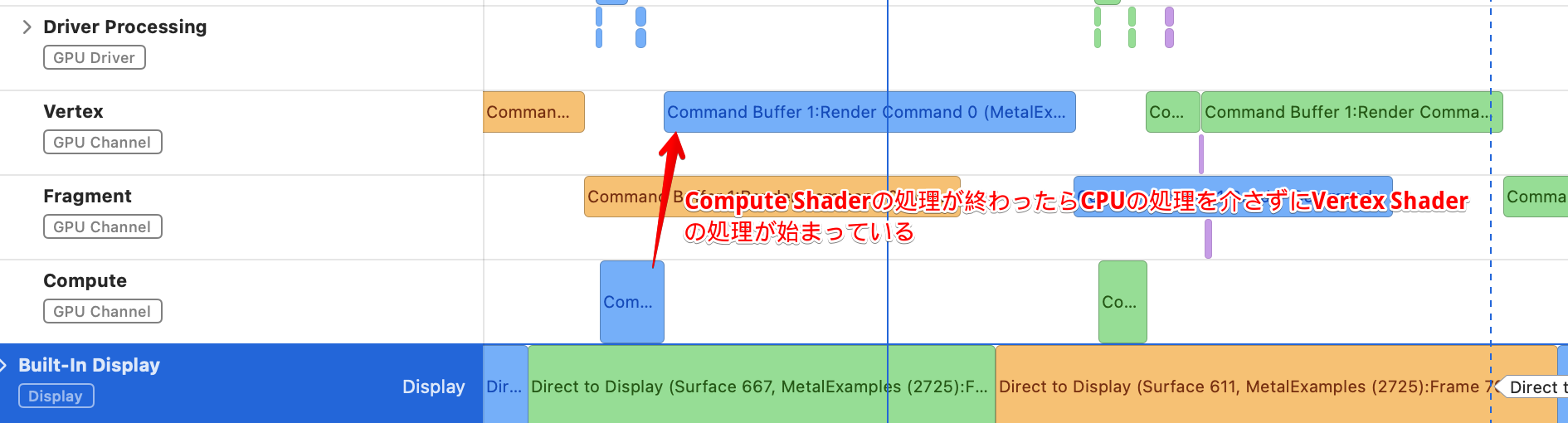
Compute Shaderの処理が終わったらCPUの処理を介さずにVertex Shaderの処理が始まっています。Metal Best Practiceでは、ここで一旦CPUがCompute Shaderの処理結果を受け取ることで無駄な転送が発生すると説明されていましたが、無駄な転送は発生していませんでした。
それもそのはずで、リソースストレージモードがSharedモードで実行しているので、GPUが処理した頂点のデータは、CPU側に転送などせずとも参照できるし、CPU側からGPU側に渡すときもデータの転送などせずにメモリ上のアドレスだけを渡せばよいのです。
リソースストレージモードについてはこちらをご覧ください。
結論
ということで今回の検証ではベストプラクティスの通りにはなりませんでした。
ただ、これは今回作ったサンプルが検証するのに適したものでなかっただけであり、ベストプラクティスが否定されるわけではありません。CPU⇔GPU間でのデータ転送が大きい場合は、ベストプラクティスを用いると大きな効果を発揮しそうです。
正直今回は、いい感じのサンプルを作るのが難しすぎて力尽きた感があります。。Metal Best Practiceで紹介されているのは、MTLDrawPrimitivesIndirectArgumentsなど、drawIndexedPrimitivesなどインデックスを用いた図形描画コマンドの引数に間接バッファを使用するというものでした。これを使ったサンプルで良いものが思いつかず、ICBのサンプルを作ったのが敗因でした😭
最後に
iOSを使った3D処理やAR、ML、音声処理などの作品やサンプル、技術情報を発信しています。
作品ができたらTwitterで発信していきますのでフォローをお願いします🙏
Twitterは作品や記事のリンクを貼っています。
https://twitter.com/jugemjugemjugem
Qiitaは、iOS開発、とくにARや機械学習、グラフィックス処理、音声処理について発信しています。
https://qiita.com/TokyoYoshida
Noteでは、連載記事を書いています。
https://note.com/tokyoyoshida
Zennは機械学習が多めです。
https://zenn.dev/tokyoyoshida