Metal Best Practicesは、iOS/MacOS/tvOSのAPIであるMetalを用いた設計のベストプラクティスガイドです。
本稿では、何回かに分けてこのガイドを読み解き、コード上での実験を交えて解説していきます。
読んでそのまま理解できそうなところは飛ばしますので、原文を読みながら原文のガイドとしてご利用下さい。
また、iOSの記事なので他のOS(MacOS, tvOS)についての記載は割愛します。
他の記事の一覧は、初回記事よりご覧下さい。
Command Buffers (コマンドバッファ)
ベストプラクティス:GPUを十分に使い切らずに、フレームごとに可能な限り少ないコマンドバッファを送信します。
コマンドバッファはGPUで実行されるので、送信数を増やせばGPUの負荷になる。一歩でコマンドバッファを作成する処理はCPUが行う。そこで、CPUとGPUの処理のバランスを取るためにはコマンドバッファの数を調節しましょう、という話。
トリプルバッファリングを実装している場合、CPUはGPUよりも1〜2フレーム先の処理をしているため、1つか2つのコマンドバッファを送信すればGPUをビジー状態に保つことができます。トリプルバッファリングについてはこちらの記事をご覧ください。
コードで検証してみる
コードで検証してみます。
GPUとCPUのバランスを取る、という例を作るのが難しかったので、コマンドバファの送信数を増やしたらGPUの負荷がどのように変化するのかを観測します。
次のサンプルを改変して検証します。
このサンプルでは100万のパーティクルが上から下に流れます。
実行イメージ

パーティクルを作るコマンドバッファを複数送信してみて、GPUの負荷がどのように変化するのかを観測します。
その1:コマンドバッファを1回送信版・ウェイトあり
コマンドバッファを1送信した場合です。つまり、サンプルをそのまま実行した場合です。
ウェイトありとしているのは、CPU側の処理は最後にGPUの処理が終わるのを待つようにしているためです。
コードは次のようになっています。draw関数の中にdoDraw関数がありますが、これは後でコマンドバッファを2回送信するためのものです。今回は1回だけ送信したいのでdoDrawの呼び出しは1回だけです。また、コマンドバッファにラベル名をつけてあとで解析しやすくしています。
func draw(in view: MTKView) {
func doDraw(label: String) {
guard let drawable = view.currentDrawable else {return}
let commandBuffer = metalCommandQueue.makeCommandBuffer()!
commandBuffer.label = label
renderPassDescriptor.colorAttachments[0].texture = drawable.texture
renderPassDescriptor.colorAttachments[0].loadAction = .clear
renderPassDescriptor.colorAttachments[0].clearColor = MTLClearColorMake(0.8, 0.7, 0.1, 1.0)
let renderEncoder = commandBuffer.makeRenderCommandEncoder(descriptor: renderPassDescriptor)!
guard let renderPipeline = renderPipeline else {fatalError()}
renderEncoder.setRenderPipelineState(renderPipeline)
renderEncoder.setVertexBuffer(vertextBuffer, offset: 0, index: 0)
uniforms.time += preferredFramesTime
for vertextBuffer in vertextBuffers {
renderEncoder.setVertexBuffer(vertextBuffer, offset: 0, index: 0)
renderEncoder.setVertexBuffer(texCoordBuffer, offset: 0, index: 1)
renderEncoder.setFragmentTexture(texture, index: 0)
renderEncoder.setVertexBytes(&uniforms, length: MemoryLayout<Uniforms>.stride, index: 2)
renderEncoder.drawPrimitives(type: .triangleStrip, vertexStart: 0, vertexCount: 4, instanceCount: 1000000)
}
renderEncoder.endEncoding()
commandBuffer.present(drawable)
commandBuffer.commit()
commandBuffer.waitUntilCompleted()
}
doDraw(label: "label1")
// doDraw(label: "label2")
}
実行してみると、52FPS出ていました。
Metal System Traceを使って処理の状況を確認してみましょう。
このツールの使い方はこちらをご覧下さい。
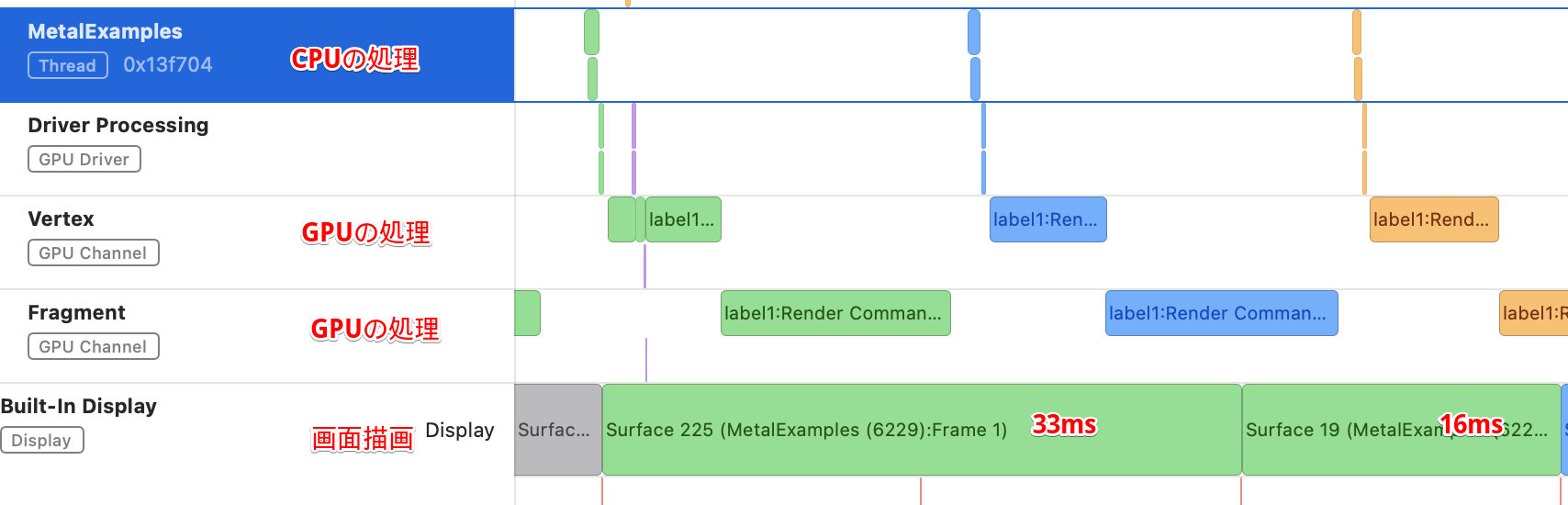
CPUの処理のあとにGPUの処理が続いています。コマンドバッファのwaitUntilCompleted()を使用している(=ウェイトしている)ので、その次のCPUの処理は、GPUの処理が終わるのを待ってから始まります。
【Metal System Traceの画面】
その2:コマンドバッファを2回送信版・ウェイトあり
コマンドバッファを2回送信してみましょう。
先程のコードの、 doDraw(label: "label2") のところについていたコメントを外します。
doDraw(label: "label1")
doDraw(label: "label2") // コメントを外す
実行してみると、27FPSに落ちます。
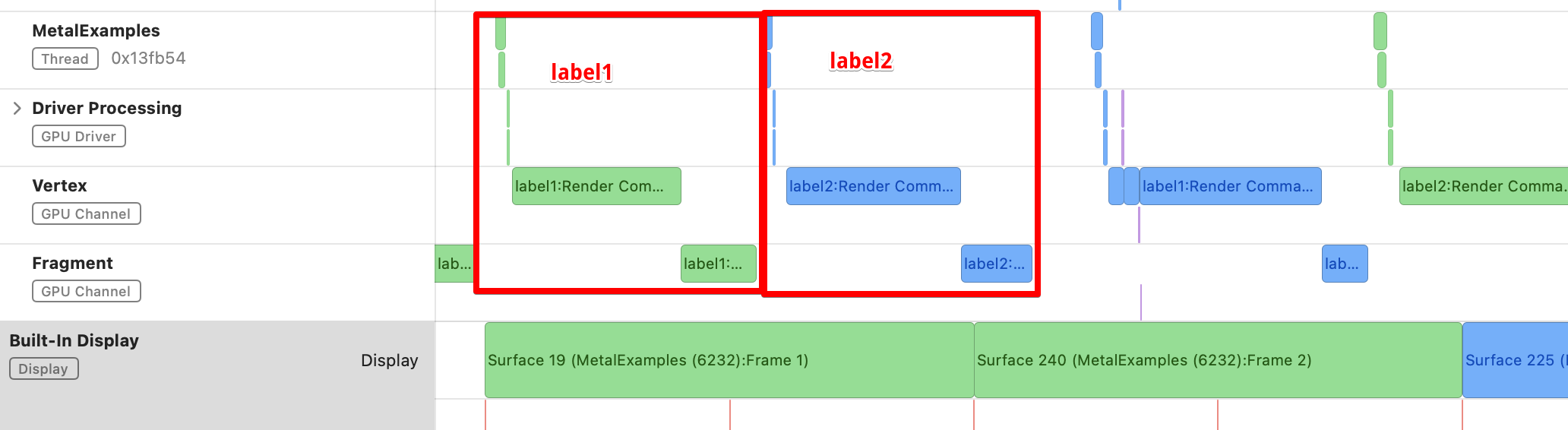
Metal System Traceでみると、コマンドバッファにつけたlabel1とlabel2が順番に処理されているのがわかります。
CPUの処理に対してGPUの処理が重くなりすぎている状態になりました。
【Metal System Traceの画面】
その3:コマンドバッファを2回送信版・ウェイトなし
ここで、コマンドバッファのwaitUntilCompletedをコメントアウトして実行してみます。
コメントアウトすると、CPU側の処理はGPUの処理を待たずにどんどんコマンドバッファを送信します。
// commandBuffer.waitUntilCompleted()
実行してみるとなんと60FPS出ています。
パーティクルも明らかに早く流れています。

何が起きているのか、Metal System Traceで見てみましょう。
【Metal System Traceの画面】
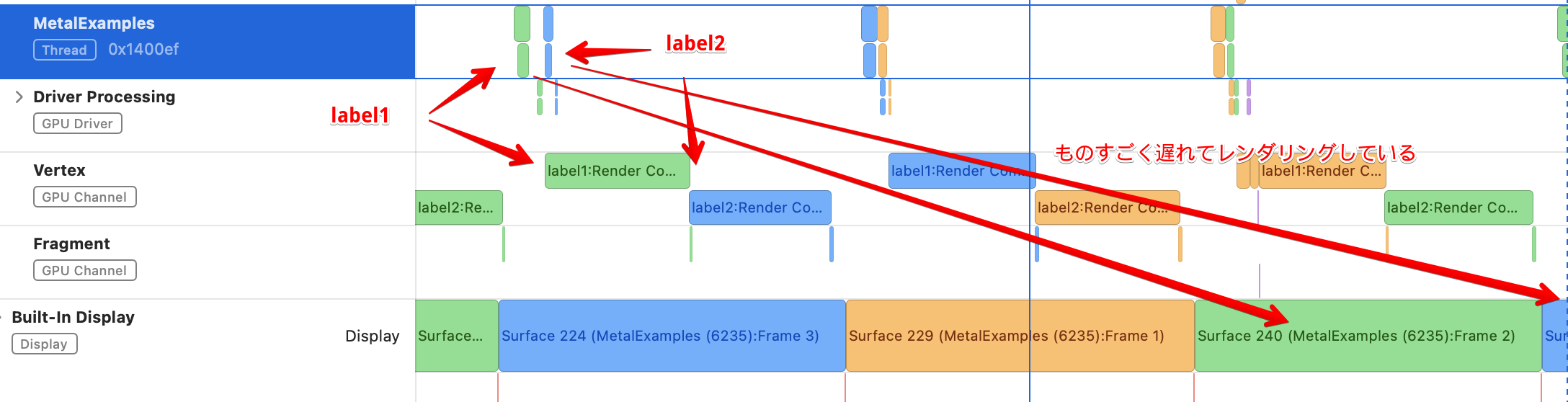
まず、CPU側では、label1のコマンドバッファとlabel2のコマンドバッファは間隔を空けずに実行されています。これは、waitUntilCompletedを外したためです。
ただし、送信したコマンドバッファが実際に画面に表示されるのは、2フレームほど遅れたあとになっています。
つまり、waitUntilCompletedを外したことで、GPU側の処理を待たずに常に次のフレームのデータが準備できている状態ができています。トリプルバッファリングに似てていますが、今回のサンプルではパーティクルの座標など表示に必要なデータはすべてGPU側で用意していたので、トリプルバッファリングを使わずにこのような処理を実現できました。
おまけ:120Hzで実行してみる
そういえば、iPhone 13 Proは120Hzのリフレッシュレートだななどと考えていたら、家にもiPad Proという120Hzのデバイスがあったことを思い出しました。
MTKViewnoのpreferredFramesPerSecondに120を入れてみて実行してみます。
コマンドバッファは1回だけ送信します。
実行してみると120FPSは出ていなくて、だいたい90FPSになっていました。
ものすごい勢いでパーティクルが流れていきます。
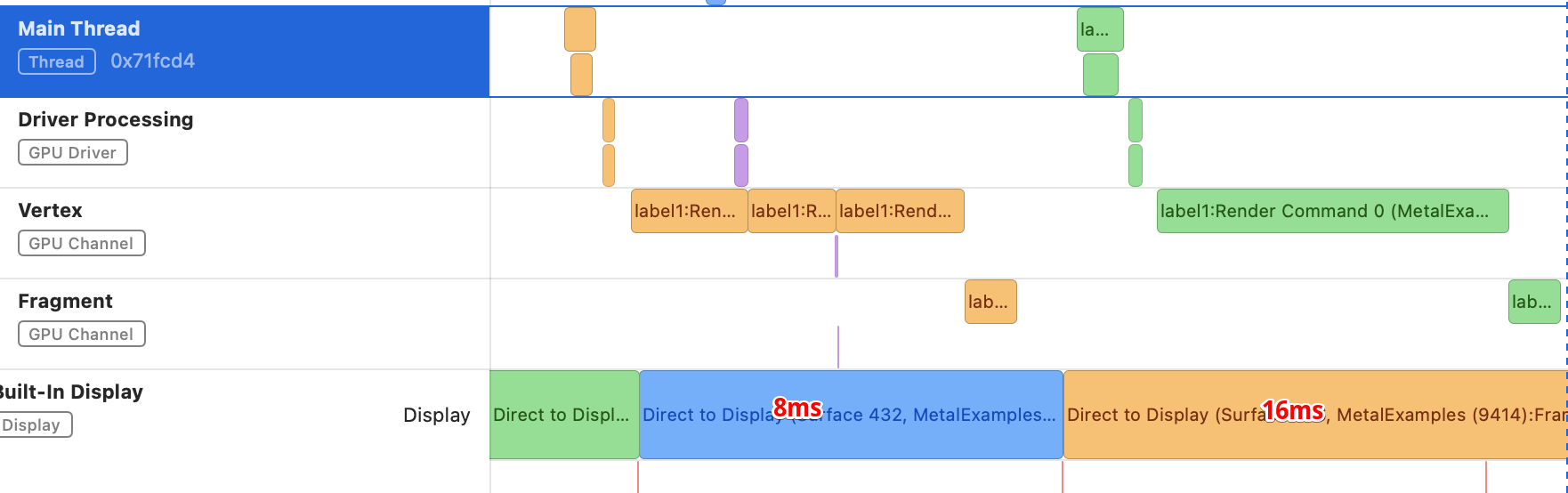
描画は、概ね8.34ms間隔ですが、ところどころ16.67msになっていました。(今回のテーマには何も関係ありません🙃)
【Metal System Traceの画面】
結論
当たり前といえば当たり前ですが、コマンドバッファを多く送信すると、GPUの負荷が大きくなることが確認できました。
最後に
iOSを使った3D処理やAR、ML、音声処理などの作品やサンプル、技術情報を発信しています。
作品ができたらTwitterで発信していきますのでフォローをお願いします🙏
Twitterは作品や記事のリンクを貼っています。
https://twitter.com/jugemjugemjugem
Qiitaは、iOS開発、とくにARや機械学習、グラフィックス処理、音声処理について発信しています。
https://qiita.com/TokyoYoshida
Noteでは、連載記事を書いています。
https://note.com/tokyoyoshida
Zennは機械学習が多めです。
https://zenn.dev/tokyoyoshida