YOLO v3をCoreMLに変換してみたので手順を書きます。
YOLO v3は、物体を検出するアルゴリズムです。
YOLOをiOSで動作させるのに一番簡単な方法は、Apple公式のCore MLモデルをダウンロードして使用することですが、今回は手動で変換してみました。
オリジナルのYOLOv3はDarknet構築されていますが、今回はこちらにあるKerasに変換したものを使用します。
qqwweee/keras-yolo3
https://github.com/qqwweee/keras-yolo3
手順
Google Colaboratoryでの手順を示します。
1.必要なライブラリをインストール & インポートする
!pip install tensorflow-gpu==1.14.0
!pip install -U coremltools
!pip install keras==2.2.4
2.keras-yolo3をcloneする
まずは、リポジトリから落としてきます。
!git clone https://github.com/qqwweee/keras-yolo3
3.keras-yolo3を動かしてみる
まずは、Pythonでそのままkeras-yolo3を動かしてみます。
このあたりはgithubのREADME.mdに書いてある手順そのままです。
最初に重み情報のファイルをダウンロードします。
%cd keras-yolo3
#!wget https://pjreddie.com/media/files/yolov3.weights
keras版のyoloモデルに変換します。
!python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5
適当な画像をアップロードして推論させてみます。
今回はneco.jpgというファイルをアップロードしました。
! python yolo_video.py --image --input neco.jpg
# 出力結果
# (416, 416, 3)
# Found 2 boxes for img
# bed 0.66 (11, 481) (656, 660)
# cat 1.00 (98, 17) (624, 637)
# 6.3229040969999915
ちゃんと猫を検出できているようです。
4.CoreMLに変換する
Core ML Toolsを使って変換します。
入力画像は416(width)x416(height)x3(RGB)としています。
また、image_scaleに1/255.0を設定して正規化をします。
from keras.models import load_model
from coremltools.converters import keras as converter
mlmodel = converter.convert(keras_model,
output_names=['grid1','grid2','grid3'],
input_name_shape_dict = {'input1' : [None, 416, 416, 3]},
image_input_names='input1',
image_scale=1/255.0,
)
# 出力
# 0 : input_1, <keras.engine.input_layer.InputLayer object at 0x7f7e4058fa58>
# 1 : conv2d_1, <keras.layers.convolutional.Conv2D object at 0x7f7e41cffb38>
# 2 : batch_normalization_1, <keras.layers.normalization.BatchNormalization object at 0x7f7e41cc6438>
# 〜略〜
# For large sized arrays, multiarrays of type float32 are more efficient.
# In future, float input/output multiarrays will be produced by default by the converter.
# Please use, either the flag 'use_float_arraytype' during the call to convert or
# the utility 'coremltools.utils.convert_double_to_float_multiarray_type(spec)', post-conversion.
変換したCore MLのモデルを保存します。
coreml_model_path = 'yolo.mlmodel'
mlmodel.save(coreml_model_path)
5.推論結果の表示を調べる
CoreMLへの変換はうまくいきましたが、これをXcodeのプロジェクトにコピーして、Vision Frameworkで推論させようとすると失敗します。
というのは、YOLOv3の出力は3つあり、1x1x255x13x13, 1x1x255x26x26, 1x1x255x52x52というshapeをしていますが、このままではVision Frameworkでは解釈できないためです。出力結果をデコードする必要があります。
YOLOv3の出力についてはこちらのブログがわかりやすかったです。
一般物体認識YOLOv3のモデル構造
デコードは自分で作ると大変そうなので、今回はこちらのプロジェクトを使います。
Ma-Dan/YOLOv3-CoreML
https://github.com/Ma-Dan/YOLOv3-CoreML
このプロジェクトでは、CoreMLの出力が255x13x13、255x26x26、255x52x52となることを想定しています。
この形になるように出力をReshapeする必要があります。
6.出力をreshapeする
モデルの出力を次のようにreshapeします。
1x1x255x13x13 → 255x13x13
1x1x255x26x26 → 255x13x26
1x1x255x52x52 → 255x13x52
そのためには、Core ML Toolsでreshapeするためのレイヤーを追加する必要があります。
なお、Core ML ToolsでCore MLモデルのレイヤーを編集する方法はこちらに詳しく書いてあります。
Core ML Toolsでレイヤーを編集する方法
https://qiita.com/TokyoYoshida/items/7aa67dcea059a767b4f2
reshapeするレイヤーですが、最初は次元を削減するadd_squeezeというのがあるのでを試しましたが、なぜかうまくいきませんでした。
また、add_reshapeというのもありましたが、これだと先頭の1x1の部分の次元が削減されないままでした。
いろいろ調べた結果、add_reshape_staticというのがあり、これを使うとうまくreshapeできました。
次のようにして追加します。
from coremltools.models.neural_network import datatypes
builder.add_reshape_static(name='Reshape1', input_name='grid1', output_name='output1', output_shape=(255,13,13))
builder.add_reshape_static(name='Reshape2', input_name='grid2', output_name='output2', output_shape=(255,26,26))
builder.add_reshape_static(name='Reshape3', input_name='grid3', output_name='output3', output_shape=(255,52,52))
次に、モデル全体の出力のshapeを指定します。
builder.spec.description.output[0].name = "output1"
builder.spec.description.output[0].type.multiArrayType.shape[0] = 255
builder.spec.description.output[0].type.multiArrayType.shape.append(13)
builder.spec.description.output[0].type.multiArrayType.shape.append(13)
builder.spec.description.output[1].name = "output2"
builder.spec.description.output[1].type.multiArrayType.shape[0] = 255
builder.spec.description.output[1].type.multiArrayType.shape.append(26)
builder.spec.description.output[1].type.multiArrayType.shape.append(26)
builder.spec.description.output[2].name = "output3"
builder.spec.description.output[2].type.multiArrayType.shape[0] = 255
builder.spec.description.output[2].type.multiArrayType.shape.append(52)
builder.spec.description.output[2].type.multiArrayType.shape.append(52)
最後にモデルを保存します。
mlmodel_modified = coremltools.models.MLModel(spec)
mlmodel_modified.save('Yolov3.mlmodel')
7.アプリで表示させる
あとは、Core MLのモデルをYOLOv3-CoreMLのプロジェクトにDrag & Dropして実行するだけです。
試しにXcode上からモデルを表示すると、正しく認識できていることがわかります。
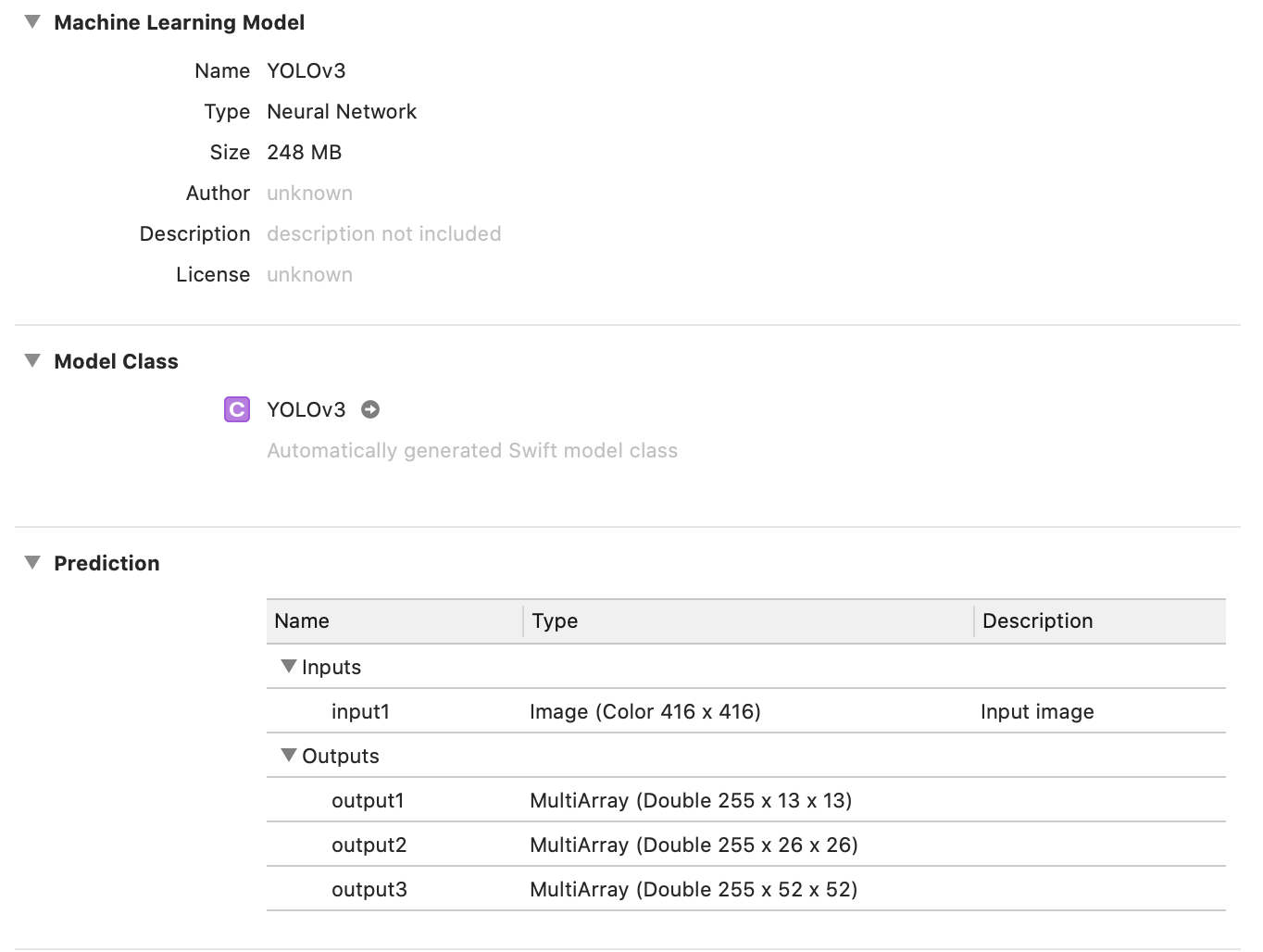
実行結果です。

ちゃんと認識できていますね。
最後に
NoteではiOS開発について定期的に発信していますので、フォローしていただけますと幸いです。
https://note.com/tokyoyoshida
Twitterでも発信しています。
https://twitter.com/jugemjugemjugem