Metal Best Practicesは、iOS/MacOS/tvOSのAPIであるMetalを用いた設計のベストプラクティスガイドです。
本稿では、何回かに分けてこのガイドを読み解き、コード上での実験を交えて解説していきます。
読んでそのまま理解できそうなところは飛ばしますので、原文を読みながら原文のガイドとしてご利用下さい。
他の記事の一覧は、初回記事より参照下さい。
Persistent Objects (永続オブジェクト)
永続オブジェクトを早期に作成して再利用します。すべてのレンダリングや計算のループでこれらのオブジェクトを作成するのは非効率です。次に、オブジェクトとそれぞれの作成タイミングを示します。
Metalに関するオブジェクトと作成のタイミング一覧
| オブジェクト名 | 作成タイミング |
|---|---|
| MTLDevice | アプリ開始時にGPUごとに1つ作成する。 |
| MTLCommandQueue | アプリ開始時にGPUごとに最低1つ作成。各キューが異なる作業をする場合は、それぞれ作成する。 |
| MTLLibrary | なるべくビルド時に構築する。Xcodeはアプリのビルド時に自動的に.metalをコンパイルして、デフォルトライブラリにビルドする。newDefaultLibraryで取得できる。 |
| MTLFunction | 作成はライブラリのビルド時と同じ。複数のパイプラインで使用する場合も同じものを再利用する。 |
| MTLRenderPipelineState, MTLComputePipelineState | アプリ開始時に必要なパイプライン毎に作成する。 |
| MTLBuffer, MTLTexture | 静的データの場合は、最初に作ったものをなるべく再利用する。動的データの場合も、最初に領域を確保しておき、データを更新するようにする。トリプルバフッファリングを用いると、フレーム毎に新しいバッファを作成せずにプロセッサのアイドル時間を最小限に抑えることができる。 |
コードで試してみる
こちらのリポジトリにサンプルコードがあります。
サンプルコードの中に、Particleというサンプルがあるのでこれを改変しながら計測していきます。
(実行イメージ)
毎フレームごとにオブジェクトを生成する場合
効率が悪いとされるオブジェクト作成処理を毎フレームごとに入れています。
MTLDevice、MTLCommandQueue、MTLRenderPipelineState, MTLTexture, MTLBufferなどベストプラクティスで再利用せよと書かれているものをほとんど再作成してみます。実際のコードは処理時間を計測するために、前後でos_signpost関数を実行しています。
func draw(in view: MTKView) {
guard let drawable = view.currentDrawable else {return}
// wasteful processing start
let metalDevice = MTLCreateSystemDefaultDevice()!
let metalCommandQueue = metalDevice.makeCommandQueue()!
buildPipeline()
initTexture()
makeBuffers()
// wasteful processing end
計測してみます、
os_signpost関数で取得したパフォーマンスデータは、InstrumentsのMetal System Traceで確認できます。(Time Profilerでも確認できますが、Metal System Traceを使うとGPUの処理と並べて比較できます)
Metal System Traceの使い方はこちらの記事をご覧ください。
計測結果は次のようになりました。
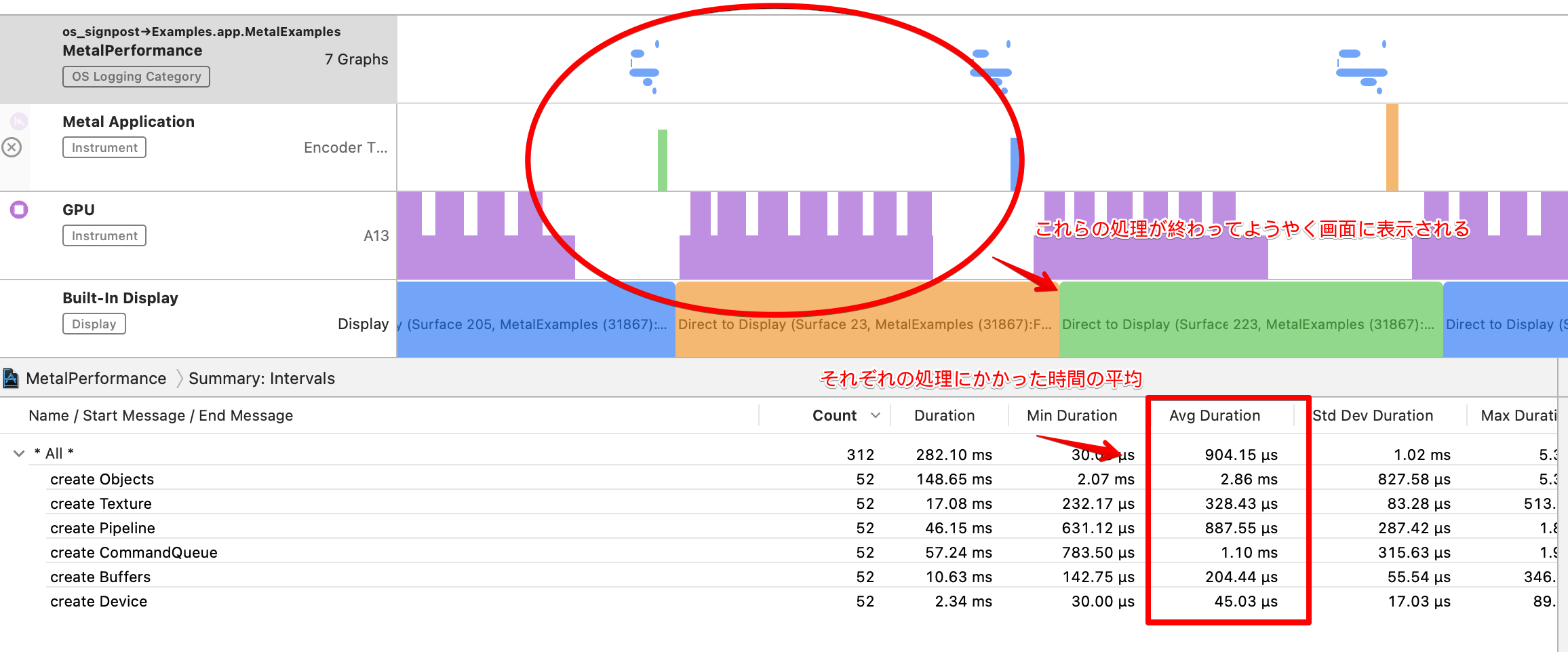
フレームごとの処理は次の順番になっています。
MetalPerformance(2.44ms) ・・・ 今回計測した処理
=> Metal Application(452μs) ・・・ コマンドバッファの作成処理
=> GPU(11.21ms) ・・・ GPU側の処理(VertexシェーダーやFragmentシェーダーの処理など)
=> Built-in Display(33.33ms) ・・・ 描画
60FPSを実現するためには、16.67ms間隔で描画する必要がありますが、今回は33msかかっていました。これは、描画のためのCPU+GPUの処理が16.67msに間に合わなかったためです。このうち、今回計測した処理が2.44ms占めているのでかなりコストが大きい処理です。
内訳をみていくと次のようにっていました。所要時間の大きい順に並べています。
作成コストの内訳
| オブジェクト | 所要時間 |
|---|---|
| MTLCommandQueue | 1,100μs |
| MTLRenderPipelineState | 887μs |
| MTLTexture | 328μs |
| MTLBuffer | 204μs |
| MTLDevice | 45μs |
| 合計 | 2.86ms |
1つ1つは短い処理ですが、『塵が積もれば山となる』ですね。
フレームレートはだいたい30FPSぐらいになっていました。
オブジェクトを再利用した場合を試してみる
今度はオブジェクトを最初に作成したら再利用しつづけるパターンで計測してみます。
ソースコードは、Pattern2_Reuseです。
計測結果は次のようになりました。
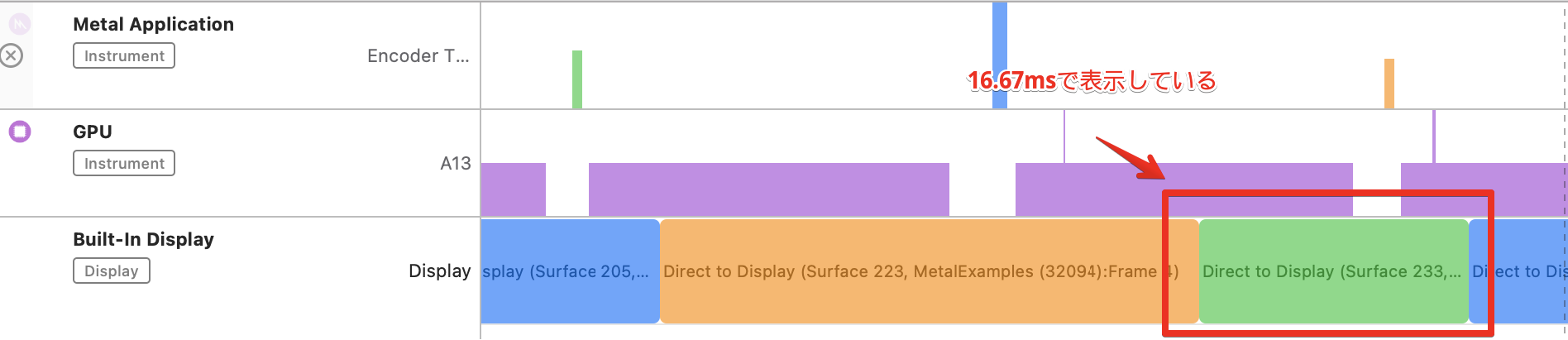
こちらは毎フレームにオブジェクトを作成しないので、その分早くなります。ところどころ16.67msで表示できていることがわかります。フレームレートはだいたい40FPSぐらいでした。
(実はGPUの処理もだいぶ時間がかかるので、60FPSは出せない作りになっています。)
結論
ベストプラクティスにあるとおり、永続オブジェクトを早期に作成して、再利用したほうが効率的ということがわかりました。
最後に
iOSを使ったARやML、音声処理などの作品やサンプル、技術情報を発信しています。
作品ができたらTwitterで発信していきますのでフォローをお願いします🙏
Twitterは作品や記事のリンクを貼っています。
https://twitter.com/jugemjugemjugem
Qiitaは、iOS開発、とくにARや機械学習、グラフィックス処理、音声処理について発信しています。
https://qiita.com/TokyoYoshida
Noteでは、連載記事を書いています。
https://note.com/tokyoyoshida
Zennは機械学習が多めです。
https://zenn.dev/tokyoyoshida