前回までのあらすじ
前回の記事では、スクレイピングを使って取得したいユーザーの投稿情報を取得するところまでをまとめました。
今回は、その投稿情報をもとにして投稿の詳細情報を描画するところまでまとめます。
前回の記事はこちら
描画したデータ
以下の25個の項目をグラフで表現しました。
- 各時間ごとの投稿数、いいねの平均/中央値、リツイートの平均/中央値
- 各曜日ごとの投稿数、いいねの平均/中央値、リツイートの平均/中央値
- 文字数ごとの投稿数、いいねの平均/中央値、リツイートの平均/中央値
- 改行数ごとの投稿数、 いいねの平均/中央値、リツイートの平均/中央値
- メディア数ごとの投稿数、 いいねの平均/中央値、リツイートの平均/中央値
環境は、Jupyter notebook上で行いました。
スクリプトについて
簡単な統計情報
まずは小手調べに簡単な統計情報を出してみました。
平均値と中央値のいずれもを出している理由は、私のツイート数が少なすぎて何度かバズった外れ値の影響を考慮したからです。
pandasで取得するデータは前回の記事で紹介した方法で取得済みの設定です。
easy.py
import pandas as pd
import matplotlib.pyplot as plot
df = pd.read_csv('otnk23.csv',encoding='utf-8')
# いいねの平均
print(df['likes'].mean())
# いいねの中央値
print(df['likes'].median())
# リツイートの平均
print(df['retweets'].mean())
# リツイートの中央値
print(df['retweets'].median())
時間帯ごとの分析
time.py
# 時間帯ごとの投稿数
df['hour'] = df['date'].dt.hour
hour_size =df.groupby(pd.Grouper(key='hour' )).size().sort_index()
hour_size.plot.bar()
plot.title('hour_posts_size')
plot
# 時間ごとのいいねの中央値
likes_hour_groupby_median = df.groupby('hour')[['likes']].median()
likes_hour_groupby_median.plot.bar()
plot.title('hour_likes_median')
plot
# 時間ごとのいいねの平均
likes_hour_groupby_mean = df.groupby('hour')[['likes']].mean()
likes_hour_groupby_mean.plot.bar()
plot.title('hour_likes_mean')
plot
# 時間ごとのリツイートの中央値
retweets_hour_groupby_median = df.groupby('hour')[['retweets']].median()
retweets_hour_groupby_median.plot.bar()
plot.title('hour_retweets_median')
plot
# 時間ごとのリツイートの平均
retweets_hour_groupby_mean = df.groupby('hour')[['retweets']].mean()
retweets_hour_groupby_mean.plot.bar()
plot.title('hour_retweets_mean')
plot
曜日ごとの分析
day.py
# 曜日ごとの投稿数
df['day_of_week'] = df['date'].dt.day_name()
cats = [ 'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
day_size =df.groupby(pd.Grouper(key='day_of_week' )).size().reindex(cats)
day_size.plot.bar()
plot.title('day_posts_size')
plot
# 曜日ごとのいいねの中央値
likes_day_groupby_median = df.groupby('day_of_week')[['likes']].median().reindex(cats)
likes_day_groupby_median.plot.bar()
plot.title('day_likes_median')
plot
# 曜日ごとのいいねの平均
likes_day_groupby_mean = df.groupby('day_of_week')[['likes']].mean().reindex(cats)
likes_day_groupby_mean.plot.bar()
plot.title('day_lkes_mean')
plot
# 曜日ごとのリツイートの中央値
retweets_day_groupby_median = df.groupby('day_of_week')[['retweets']].median().reindex(cats)
retweets_day_groupby_median.plot.bar()
plot.title('day_retweets_median')
plot
# 曜日ごとのリツイートの平均
retweets_day_groupby_mean = df.groupby('day_of_week')[['retweets']].mean().reindex(cats)
retweets_day_groupby_mean.plot.bar()
plot.title('day_retweets_mean')
plot
メディア数ごとの分析
media.py
# メディア数ごとのサイズ
size_media_groupby_median = df.groupby('media').size()
size_media_groupby_median.plot.bar()
plot.title('media_num_size')
plot
# メディア数ごとのいいねの中央値
likes_media_groupby_median = df.groupby('media')[['likes']].median()
likes_media_groupby_median.plot.bar()
plot.title('media_likes_median')
plot
# メディア数ごとのいいねの平均値
likes_media_groupby_mean = df.groupby('media')[['likes']].mean()
likes_media_groupby_mean.plot.bar()
plot.title('media_likes_mean')
plot
# メディア数ごとのリツイートの中央値
retweets_media_groupby_median = df.groupby('media')[['retweets']].median()
retweets_media_groupby_median.plot.bar()
plot.title('media_retweets_median')
plot
# メディア数ごとのリツイートの平均値
retweets_media_groupby_mean = df.groupby('media')[['retweets']].mean()
retweets_media_groupby_mean.plot.bar()
plot.title('media_retweets_mean')
plot
改行数ごとの分析
block.py
df_text = df['text']
kaigyo = []
for text in df_text:
count = text.count('\n\n')
kaigyo += [count]
df['kaigyo'] = kaigyo
# 改行(スペースの数)ごとのサイズ
likes_kaigyo_groupby_size = df.groupby('kaigyo').size()
likes_kaigyo_groupby_size.plot.bar()
plot.title('block_size')
plot
# 改行ごとのいいね数の中央値
likes_kaigyo_groupby_median = df.groupby('kaigyo')[['likes']].median()
likes_kaigyo_groupby_median.plot.bar()
plot.title('block_likes_median')
plot
# 改行ごとのいいね数の平均
likes_kaigyo_groupby_mean = df.groupby('kaigyo')[['likes']].mean()
likes_kaigyo_groupby_mean.plot.bar()
plot.title('block_likes_mean')
plot
# 改行ごとのリツイート数の中央値
retweets_kaigyo_groupby_median = df.groupby('kaigyo')[['retweets']].median()
retweets_kaigyo_groupby_median.plot.bar()
plot.title('block_retweets_median')
plot
# 改行ごとのリツイート数の平均
retweets_kaigyo_groupby_mean = df.groupby('kaigyo')[['retweets']].mean()
retweets_kaigyo_groupby_mean.plot.bar()
plot.title('block_retweets_mean')
plot
文字数ごとの分析
text_num.py
df_text_num_about = []
df_text_num = df['text_num']
for text in df_text_num:
df_text_num_about.append(text//10*10)
df['about_num'] = df_text_num_about
# 文字数ごとのサイズ
about_num_groupby_size = df.groupby('about_num').size()
about_num_groupby_size.plot.bar()
plot.title('text_size')
plot
# 文字数ごとのいいね数の中央値
likes_about_num_groupby_median = df.groupby('about_num')[['likes']].median()
likes_about_num_groupby_median.plot.bar()
plot.title('text_size_likes_median')
plot
# 文字数ごとのいいね数の平均値
likes_about_num_groupby_mean = df.groupby('about_num')[['likes']].mean()
likes_about_num_groupby_mean.plot.bar()
plot.title('text_size_likes_mean')
plot
# 文字数ごとのリツイート数の中央値
retweets_about_num_groupby_median = df.groupby('about_num')[['retweets']].mean()
retweets_about_num_groupby_median.plot.bar()
plot.title('text_size_retweets_median')
plot
# 文字数ごとのリツイート数の平均値
retweets_about_num_groupby_mean = df.groupby('about_num')[['retweets']].mean()
retweets_about_num_groupby_mean.plot.bar()
plot.title('text_size_retweets_mean')
plot
感想と結果
せっかくなので、私の投稿の分析結果も載せておきます。
これは、文字数ごとの分析、改行数ごとの分析、メディア数ごとの分析の結果です。
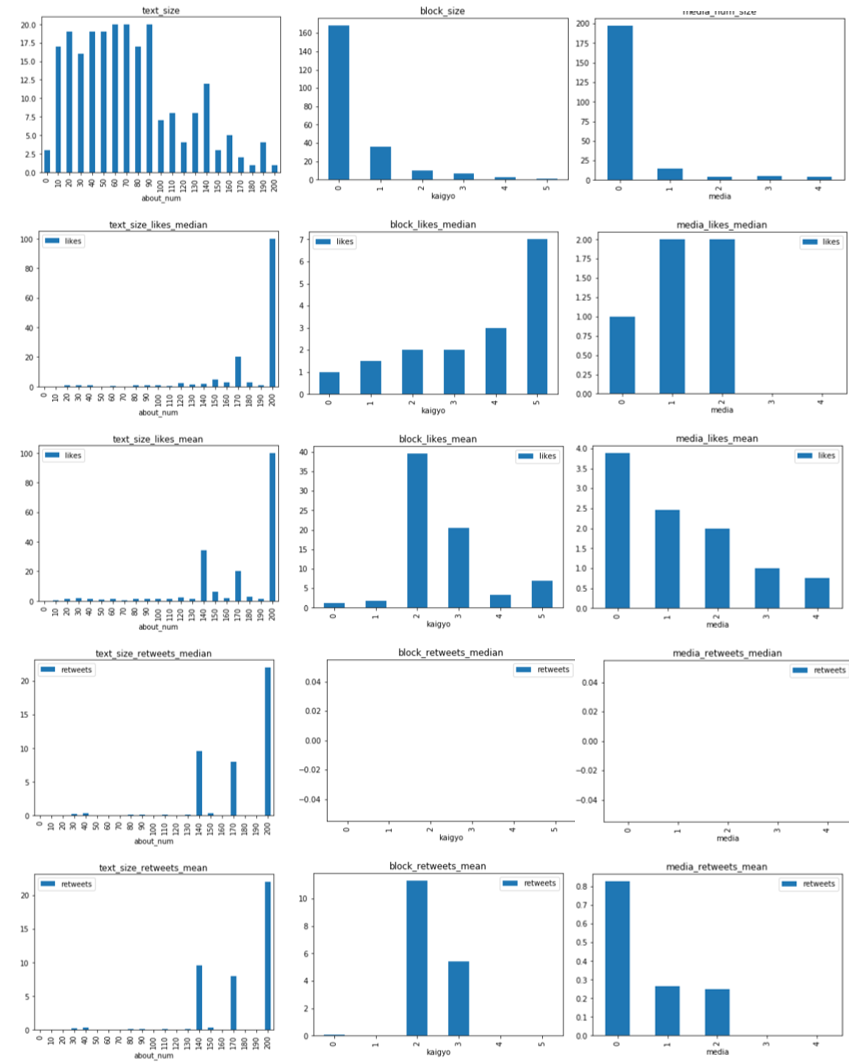
テキスト数に見るからに文字数が多いほうがバズりやそうですね。とはいえ、母数が少ないので何とも言えませんが。。。
それから、改行も0の場合はあまり伸びていませんね。これは中央値、平均値共にその傾向があるので、一定の有意性があるのかもしれません。
これは、曜日ごとの分析と時間ごとの分析です。
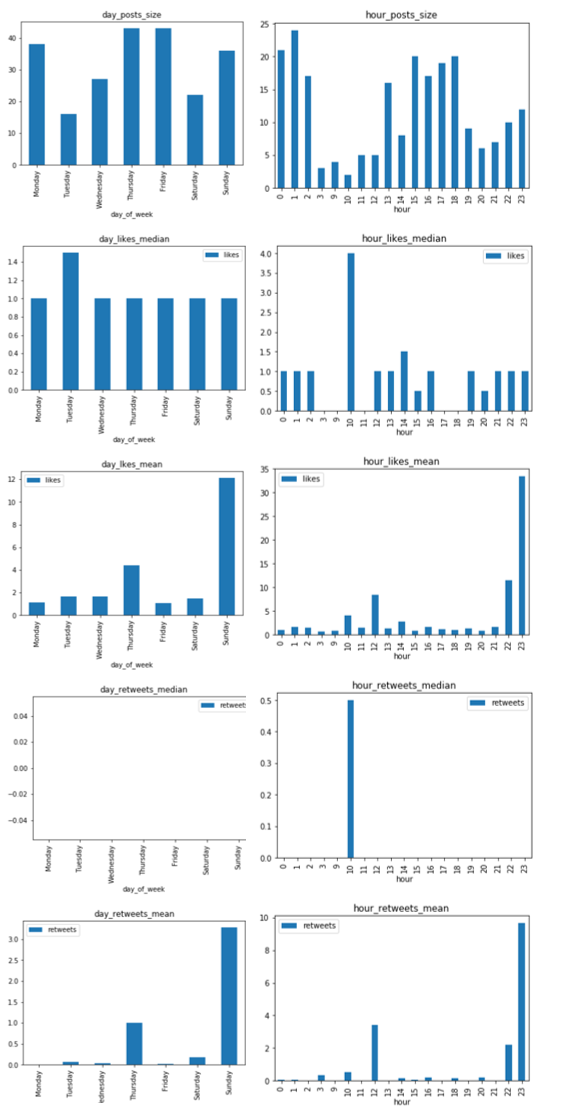
曜日に関しては、日曜日の平均が高いのでバズった投稿が集中しているのかもしれません。また時間に関しても、夜になるにつれエンゲージメントが伸びています。
私の投稿数とフォロワーが少ないので伸びにくい傾向が出てしまいましたが、時々気になるデータが出てきているようです。
皆さんも自分のアカウントや気になるアカウントで試してみてください。