ここでは、久保川達也先生著『現代数理統計学の基礎』の5.3,5.4の範囲について説明します。
5.3 確率変数と確率分布の収束
5.3.1 確率収束と大数の弱法則
確率収束については教科書の通り次の定義が成り立ちます
定義 5.8 確率収束
確率変数の列$\{U_n\}_{n=1,2,\dots}$が確率変数$U$に確率収束(convergence in probability)するとは、任意の$\varepsilon>0$に対して
$$
\lim_{n \to \infty}P(|U_n-U|\geq\varepsilon)=0$$
となることをいい、$U_n\rightarrow_pU$で表す
大雑把に言うと、$n$を十分大きくした時$U_n$と$U$の差が存在する確率が0になる、つまり$U_n$が$U$に収束することを意味しています
これを示すのにマルコフ(Markov)の不等式やチェビシェフ(Chebyshev)の不等式と呼ばれるものが使われます
補題 5.9 マルコフ(Markov)の不等式
$Y$を非負の確率変数で$E[Y]<\infty$とする。このとき、任意の$c>0$に対して次の不等式が成り立つ
$$
P(Y\geq c)\leq E[Y]/c \tag{5.10} $$
[具体例]
これだけ見てもよく分からないので、具体例を考えます。
ある国の平均世帯年収が400万だとします。
では、その国で年収が2000万を超える世帯は最大何%か?
こちらは、確率分布が与えられていないですが、マルコフの不等式を使うことで計算できます
先ほどのマルコフの不等式を変形すると
P(Y\geq cE[Y])\leq \frac{1}{c}
となり、それぞれ代入して
P(Y>5\times 400)\leq \frac{1}{5}
よって、$P(Y>2000)\leq 1/5$となり最大でも20%ということなります。
補題 5.10 チェビシェフ(Chebyshev)の不等式
確率変数Xについて平均と分散、$\mu=E[X]$、$\sigma^2=\text{Var}(X)$が存在すると仮定する。このとき次の不等式が成り立つ。
$$
P(|X-\mu|\geq k)\leq \frac{\sigma^2}{k^2} \tag{5.11}
$$
[証明]
マルコフの不等式に$Y=(X-\mu)^2,c=k^2$を代入する
[具体例]
こちらも具体例で見てみます
あるテストの平均点が55点で、標準偏差10点であった。
75点以上の人は最大で何%か。ただし得点の分布は左右対称とする。
こちらも式を変形すると
P(|X-\mu|\geq k\sigma)\leq \frac{1}{k^2}
$P(|X-55|\geq 2 \times 10)\leq \frac{1}{2^2}=25%$となり、絶対値なので最大12.5%となります。
定理 5.11 大数の弱法則
チェビシェフの不等式を用いることで、nが十分大きいときに標本平均が母平均に確率収束するという大数の弱法則が導かれます。また、弱法則というくらいなので強法則もあります。
$X_1, X_2, \dots , i.i.d. \sim (\mu, \sigma^2)$とし、$\sigma^2=\text{Var}(X_1)<\infty$とする。このとき、$\bar{X}$は$\mu$に確率収束する
[証明]
$\bar{X}$が$\mu$に確率収束するので、任意の$\varepsilon>0$に対して
$$
\lim_{n \to \infty}P(|\bar{X}-\mu|\geq\varepsilon)=0
$$を示せばよく、チェビシェフの不等式より
$$
0\leq P(|\bar{X}-\mu|\geq\varepsilon)\leq \frac{E[(\bar{X}-\mu)^2]}{\varepsilon^2}=\frac{\sigma^2}{n\varepsilon^2} \rightarrow 0;(n\rightarrow \infty)
$$より示せた。
5.3.2 分布収束と中心極限定理
定理 5.14 分布収束
確率変数の列$\{U_n\}_{n=1,2,\dots}$が確率変数$U$に分布収束もしくは法則収束(convergence in distibution)するとは、
$$
\lim _{n \to \infty}P(U_n \leq x)=P(U \leq x)=F_U(x)
$$
が$F_U(x)$の連続点で成り立つことをいい、$U_n \rightarrow_d U$で表す
また、$F_U(x)$のことを、$U_n$の極限分布といいます。この分布収束の代表的な例が中心極限定理(central limit theorem, CLT)です。これは、サンプルサイズが大きくなるにつれて標本平均の分布が正規分布に従うという定理であり、様々な場面で使われます。
定理 5.15 中心極限定理
$X_1, X_2, \dots , i.i.d. \sim (\mu, \sigma^2)$とする。このとき、次の分布収束が成り立つ
$$
\lim_{n \to \infty}P(\frac{\sqrt{n} (\bar{X}-\mu)}{\sigma}\leq x)=\int_{-\infty}^{x}{\frac{1}{\sqrt{2\pi}}e^{-y^2/2}dy}=\Phi(x)
$$
[証明]
方針としては、$\frac{\sqrt{n} (\bar{X}-\mu)}{\sigma}$の$n\rightarrow \infty$時の特性関数が標準正規分布の$e^{-t^2}$と一致することを目指します。
そこで、簡単のため、$Z_i=(X_i-\mu)/ \sigma$とおくと、$X_i\sim N(\mu, \sigma^2)$より、$E[Z_i]=0$、$\text{Var}(Z_i)=1$、$E[\bar{Z}]=0$、$\text{Var}(\bar{Z})=1/n$となります。よって示す式は
\lim P(\sqrt n\bar{Z}\leq z)=\Phi (z)
となります。$\sqrt n \bar{Z}$の特性関数は、
$$
\varphi _{\sqrt n \bar Z}(t)=E[e^{it(Z_1/\sqrt n+\dots+Z_n/\sqrt n)}]=\left(E[e^{(it/\sqrt
n)Z_1}]\right)^n \tag{5.12}
$$であり、$Z_i$は同じ分布のため特性関数も同じ形になり、$Z_1$のみで表すことが出来ます。$Z_1$の特性関数$E[e^{i\theta Z_1}]$を$\varphi (\theta)$でおくと、$E[e^{(it/\sqrt n)Z_1}]=\varphi(t/\sqrt n)$と表され、テーラー展開すると、
\begin{eqnarray}
\varphi \left(\frac{t}{\sqrt n}\right)
&=& \varphi(0)+\frac{t}{\sqrt n}\varphi'(0)+\frac{1}{2}\cdot \frac{t^2}{n}\varphi''(0)+\omicron(n^{-1})\\
&=& 1+\frac{t}{\sqrt n}iE[Z_1]+ \frac{1}{2}\cdot \frac{t^2}{n}(i^2E[Z_1^2]) +\omicron(n^{-1})\\
&=& 1-\frac{t^2}{2n}+\omicron(n^{-1})\\
\end{eqnarray}
と近似でき、
\varphi_{\sqrt n \bar{Z}}(t) = \left(1-\frac{t^2}{2n}+\omicron(n^{-1})\right)^n\rightarrow e^{-t^2/2}
に収束し、連続性定理2.17から$\sqrt n \bar{Z}$が$\mathcal{N}(0,1)$に収束することがわかります。
[具体例]
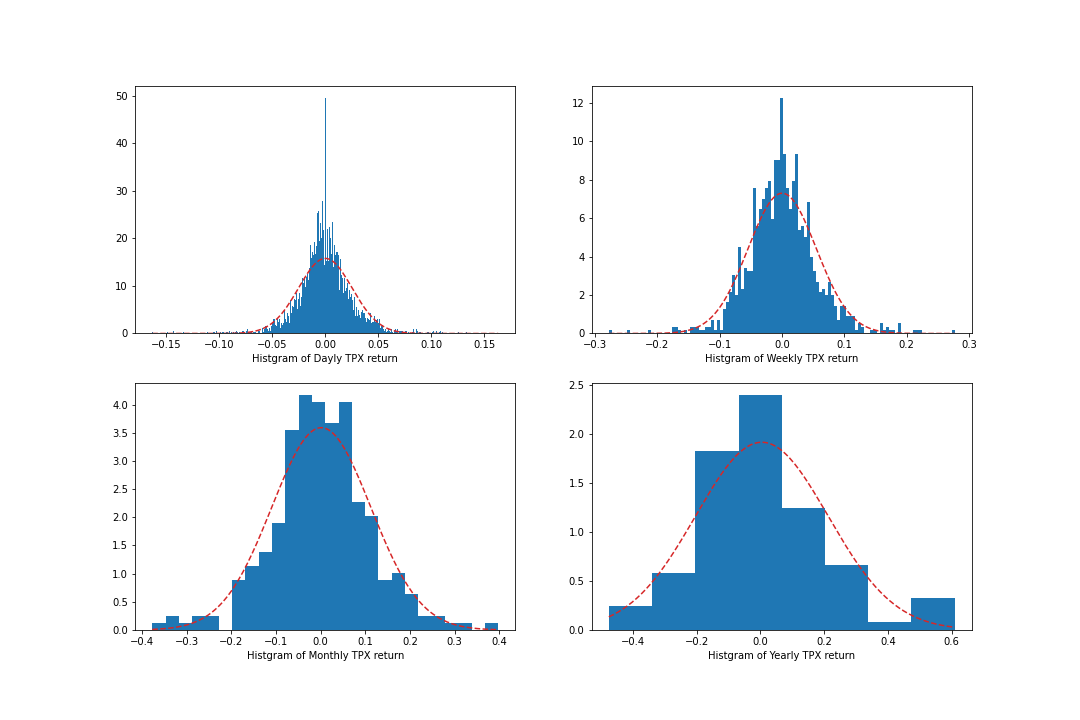
TOPIXのリターンは日次→週次→月次→年次になるにつれ正規分布に近づくそうで、これはサンプルサイズが大きくなることによる中心極限定理の影響になります。
5.3.3 収束に関する諸結果
収束の概念の関係や所結果を紹介します。
命題 5.16
確率変数の列$\{U_n \}_{n=1,2,\dots}$と確率変数$U$を考える。
\begin{align}
&(1)\; U_n\rightarrow_p UならばU_n\rightarrow_d U \\
&(2)\; aを定数とするとき、U_n\rightarrow_d a ならば U_n\rightarrow_p a
\end{align}
この命題は、分布収束と確率収束の関係性を表します。
命題 5.17
確率変数の列$\{U_n \}_{n=1,2,\dots}$と確率変数$U$を考える。
この時、$U_n \rightarrow_d U$となる必要十分条件は、あらゆる有界連続な関数$f(\cdot)$に対して$\lim_{n \to \infty}E[f(U_n)]=E[f(U)]$が成り立つことである。
この定理を用いると連続関数$h(\cdot)$に対して$h(U_n)→_dh(U)$が成り立ち、この性質を連続写像定理(continuous mapping theorem)といいます。この定理は、分布収束性が連続関数においても成り立つことを示し、確率収束についても同様の性質が成り立ちます。
命題 5.18 連続写像定理
確率変数の列$\{U_n \}_{n=1,2,\dots}$と確率変数$U$を考える。関数$h(\cdot)$が連続とする。
\begin{align}
&(1)\; U_n\rightarrow_p U ならば h(U_n) \rightarrow_p h(U) \\
&(2)\; U_n\rightarrow_d U ならば h(U_n) \rightarrow_d h(U)
\end{align}
命題 5.19 スラツキーの定理(Slutsky's theorem)
確率変数の列$\lbrace U_n \rbrace_{n=1,2,\dots}, \lbrace V_n\rbrace_{n=1,2,\dots},;$確率変数$U,;$定数$a$に対して$,U_n\rightarrow_d U, V_n \rightarrow_p a$とする。この時、次が成り立つ
\begin{align}
&(1)\; U_n+V_n\rightarrow_d U+a \\
&(2)\; U_nV_n\rightarrow_d aU
\end{align}
→証明:5.5
良く用いられるそうです。
命題 5.20 デルタ法(delta method)
確率変数の列$\lbrace U_n \rbrace_{n=1,2,\dots}$について、定数$\theta$と$a_n\uparrow \infty$となる数列に対して$a_n(U_n-\theta)\rightarrow_d U$であると仮定する。連続微分可能な関数$g(\cdot)$について、点$\theta$で$g'(\theta)$が存在し、$g'(\theta)\neq 0$とする。このとき、
a_n(g(U_n)-g(\theta))\rightarrow_d g'(\theta)U \tag{5.13}
が成り立つ。特に、$\sqrt{n}(U_n-\mu)\rightarrow_d \mathcal{N}(\mu,\sigma^2)$が成り立つときには、デルタ法から
\sqrt n\{ g(U_n)-g(\mu)\}\rightarrow_d \mathcal{N}(0,\sigma^2\{g'(\mu)\}^2) \tag{5.14}
となることが分かる。
具体例
$\sqrt n(U_n-\mu)→_d U$とし、$U$は正規分布$\mathcal{N}(0,\sigma^2)$に従うとします。ここで、$\mu\neq0$を仮定すると、
$$
\sqrt n \left(\frac{1}{U_n}-\frac{1}{\mu}\right)→_d -\frac{1}{\mu^2}U
$$となり、右辺は$\mathcal{N(0,\sigma^2/\mu^4)}$に従います。
また、$g'(\theta)= 0$のときは次に紹介する2次のデルタ法が用いられます。
命題 5.21 2次のデルタ法
確率変数の列$\lbrace U_n \rbrace_{n=1,2,\dots}$について、定数$\theta$と$a_n\uparrow \infty$となる数列に対して$a_n(U_n-\theta)\rightarrow_d U$であると仮定する。2回連続微分可能な関数$g(\cdot)$について、点$\theta$で$g'(\theta)=0,g''(\theta)\neq 0$とする。このとき、
a_n^2(g(U_n)-g(\theta))\rightarrow_d \frac{g''(\theta)}{2}U^2 \tag{5.15}
が成り立つ。特に、$\sqrt{n}(U_n-\mu)\rightarrow_d \mathcal{N}(\mu,\sigma^2)$が成り立つときには、2次のデルタ法から
\sqrt n\{ g(U_n)-g(\mu)\}\rightarrow_d \frac{g''(\mu)}{2}\sigma^2Y
となることが分かり、ここで$Y$は$\chi^2$に従う確率変数である。
(5.14)において、$\sigma^2$が$\mu$の関数、$\sigma^2=\text{Var}(X_i)=V(\mu)$の場合、つまり、分散が期待値の関数である分布の時(ベルヌーイ分布、ポアソン分布など)に、漸近分散が漸近的に定数になるような変換を分散安定化変換(variance stabilizing transformation)といい、
\begin{eqnarray}
\{g'(\mu)\}^2V(\mu)&=&c \\
g'(\mu)&=&\sqrt{\frac{c}{V(\mu)}}
\end{eqnarray}
となるような変換$g(\cdot)$となります。
具体例
相関係数のz変換も分散安定化変換の一種になります。
母集団相関係数$\rho$をもつ二変量正規母集団からの大きさ$N=n+1$個の無作為標本に基づく標本相関係数を$r$とする。
$$
\sqrt n (r-\rho )→_d \mathcal{N}(0,(1-\rho^2)^2)
$$であり、漸近分散は$(1-\rho^2)^2$となり、母集団相関係数に依存している。ここで、$f(\cdot )$を連続関数として、
$$
\sqrt n (f(r)-f(\rho))→_d \mathcal{N}(0, \{f'(\rho)\} ^2(1-\rho^2)^2)
$$
となる。極限分布が$\mathcal{N}(0,1)$となるためには
\begin{eqnarray}
(1-\rho^2)\frac{df}{d\rho}&=&1 \\
f(r)=\frac{1}{2}\log\frac{1+r}{1-r}&=&\text{arctanh}(r)
\end{eqnarray}
が導かれ、この変換はFisherのz変換として知られています。
5.4 順序統計量
順序統計量は確率変数を小さい順に並び替えたもので、重要な統計量になります。
定義5.24 順序統計量
$X_1, \dots X_n$を確立分布$P$からのランダムサンプル、すなわち$X_1, \dots X_n, i.i.d. \sim P$とする。小さい順に並び替えたものを$X_{(1)} \leq X_{(2)} \leq
\dots \leq X_{(n)}$で表し順序統計量(order statistics)という
具体的に最大統計量$X_{(n)}$、最小統計量$X_{(1)}$について考えて一般化してみます。
ある母集団からn個のサンプルを取る
$$X_1, X_2, \dots , X_n, i.i.d \sim P$$このn個のサンプルを小さい順に並び替える
$$X_{(1)}, X_{(2)}, \dots , X_{(n)}$$このとき、確率変数$X_i$の分布関数を$F(\cdot)$、確率密度関数を$f(\cdot)$とします。
最大統計量
最大統計量$X_{(n)}$の分布関数$F_{X_{(n)}}(x)$を考えると、
\begin{eqnarray}
F_{X_{(n)}}(x)
&=& P(X_{(n)}\leq x) \\
&=& P(X_{(1)}\leq x, X_{(2)}\leq x, \dots , X_{(n)}\leq x) \\
&=& P(X_{1}\leq x, X_{2}\leq x, \dots , X_{n}\leq x) \\
&=& P(X_{1}\leq x) \times P(X_{2}\leq x) \times \dots \times P(X_{n}\leq x) \\
&=& \{F(x)\}^n \\
f_{X_{(n)}}(x)
&=& nf(x)\{F(x)\}^{n-1} \tag{5.17}
\end{eqnarray}
となります。これは$X_{(n)}$が$x$より以下になる時、他の確率変数も$x$より小さくなるためです
最小統計量
一方最小統計量$X_{(1)}$に関しては
\begin{eqnarray}
F_{X_{(1)}}(x)
&=& P(X_{(1)}\leq x) \\
&=& P(X_{1}\leq x \;\text{or}\; X_2\leq x \;\text{or}\; \dots \;\text{or}\; X_n \leq x) \\
&=& 1-P(X_{1}>x, X_{2}>x, \dots , X_{n}>x) \\
&=& 1-P(X_{1}>x) \times P(X_{2}>x) \times \dots \times P(X_{n}>x) \\
&=& 1-\{1-F(x)\}^n \\
f_{X_{(1)}}(x)
&=& nf(x)\{1-F(x)\}^{n-1} \tag{5.17}
\end{eqnarray}
となります。最小統計量に関しては$X_{(1)}$が$x$以下になる時、$X_i$のどれかが$x$以下になれば十分なため、その排反を考えます。
一般化
次に一般的な$X_{(j)}$について考えます。
$$F_{X_{(j)}}(x) = P(X_{(j)}\leq x)$$となりますが、これは、$X_{(j)}$が$x$以下になることしか言っていないため、例えば$X_{(j+1)}$や$X_{(j+2)}$が$x$以下の場合も含むことになります。よって、元の$X_1\dots X_n$のうち、$j$個以上が$x$以下、残りが$x$より大きくなることと同値であり、その組み合わせは
F_{X_{(j)}}(x)=\sum_{k=j}^{n}{{}_n\mathrm{C}_k\{F(x)\}^{k}\{1-F(x)\}^{n-k}}
となり、これを微分することで$X_{(j)}$の確率密度関数$f_{X_{(j)}}(x)$が得られます。
命題5.26
\begin{eqnarray}
f_{X_{(j)}}(x)
&=& \frac{n!}{(j-1)!(n-j)!}f(x)\{F(x)\}^{j-1}\{1-F(x)\}^{n-j} \tag{5.16} \\
&=& \frac{1}{B(j,n-j+1)}f(x)\{F(x)\}^{j-1}\{1-F(x)\}^{n-j}
\end{eqnarray}
これは、$n$個のランダム・サンプルを$\{ X_k < x \\} ,\\{ X_k=x \\} , \\{ X_k>x \} $の3つの事象に分ける三項分布と捉えられます。
同様にして、$X_{(i)}$と$X_{(j)};(i<j)$の同時確率密度関数$f_{X_{(i)},X_{(j)}}(x,y)$は$\{ X_k < x \}, \{ X_k = x \}, \{ x < X_k < y \}, \{ X_k = y \}, \{ y < X_k \}$の5つの事象がそれぞれ$i-1,;1,;j-1,;1,;n-j$回起こる五項分布に対応し、
$$
f_{X_{(i)},X_{(j)}}(x,y)=\frac{n!}{(i-1)!(j-i-1)!(n-j)!}f(x)f(y)F(x)^{i-1}
$$と書け、$X_{(1)}, \dots, X_{(n)}$の同時確率密度関数は
$$
f_{X_{(1)},\dots,X_{(n)}}(X_1,\dots,x_n)=n!f(x_1)\dots f(x_n),;;-\infty<x_1<\dots<x_n<\infty
$$と書けます。
[具体例] 一様分布からのランダム・サンプル
$X_1,\dots,X_n\sim U(0,1)$の時、$F(x)=xI_{[0<x<1]}+I_{[x\geq1]}$より、$0<x<1$において
$$
f_{X_{(j)}}=\frac{n!}{(j-1)!(n-j)!} x^{j-1}(1-x)^{n-j}
$$となり、ベータ分布$Beta(j, n-j+1)$に従います。
実際、一様分布からのランダムサンプルの最小統計量、中央値、最大統計量などの順序統計量は以下のようにベータ分布に従うことが分かります。(中央値は、奇数個の場合は順序統計量とは言えないそうです)
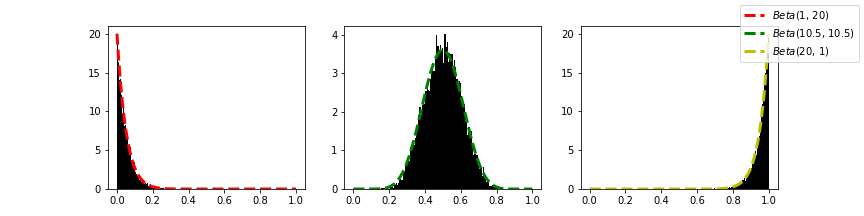
import numpy as np
import math
from math import gamma
from scipy.special import comb, beta
from matplotlib import pyplot as plt
# ベータ分布
def beta_dis(a, b, x):
return 1/beta(a,b)*x**(a-1)*(1-x)**(b-1)
# (10000, 20)の一様分布を作成
np.random.seed(0)
arr = np.random.rand(10000, 20)
min_arr = np.min(arr, axis=1)
med_arr = np.median(arr, axis=1)
max_arr = np.max(arr, axis=1)
fig = plt.figure(figsize=(12, 3))
X = np.linspace(0, 1, 100)
# 最小統計量
ax1 = fig.add_subplot(131)
ax1.hist(min_arr, bins=100, density=True, color="black")
a = 1
b = 20+1-a
y = [beta_dis(a, b, x) for x in X]
ax1.plot(X, y, label=f"$Beta$({a}, {b})", color="r", linewidth=3, linestyle='--')
# 中央値
ax2 = fig.add_subplot(132)
ax2.hist(med_arr, bins=100, density=True, color="black")
a = 10.5
b = 20+1-a
y = [beta_dis(a, b, x) for x in X]
ax2.plot(X, y, label=f"$Beta$({a}, {b})", color="g", linewidth=3, linestyle='--')
# 最大統計量
ax3 = fig.add_subplot(133)
ax3.hist(max_arr, bins=100, density=True, color="black")
a = 20
b = 20+1-a
y = [beta_dis(a, b, x) for x in X]
ax3.plot(X, y, label=f"$Beta$({a}, {b})", color="y", linewidth=3, linestyle='--')
fig.legend()
fig.savefig("plot.png")
最後に、$n(1-X_{(n)})$の極限分布を考えます。先程の式から、$X_{(n)}\sim Beta(n,1)$に従うことが分かり、確率密度関数は$nx^{n-1}$、分布関数は$x^n$となります。$0<\varepsilon<1$に対して$n \rightarrow \infty$とすると、
$$
P(|X_{(n)}-1|\geq \varepsilon)=P(X_{(n)}\leq1-\varepsilon)=(1-\varepsilon)^n\rightarrow0
$$となり、$X_{(n)}\rightarrow_p 1$となることが分かります。サンプル数が十分に大きい時、一様分布のサンプリングの最大統計量は1に確率収束するようです。(当たり前?)
極限分布は
$$
P(n(1-X_{(n)})\geq t)=P(X_{(n)}\leq1-\frac{t}{n})=(1-\frac{t}{n})^n\rightarrow e^{-t}
$$から、$P(n(1-X_{(n)})<t)\rightarrow 1-e^{-t}$となり、指数分布$Ex(\lambda)$の分布関数が$1-e^{-\lambda x}$で与えられることから、$n(1-X_{(n)})\rightarrow_{d}Ex(1)$が示されます。この時、$n$の代わりに$\sqrt{n}$を掛けると$\sqrt{n}(1-X_{(n)})\rightarrow_{p}0$となり1点になってしまいます。このような場合は極限分布は退化するといい、退化しないような極限分布を極値分布(extreme-value distribution)といいます。
参考
-
久保川達也 『現代数理統計学の基礎』 共立出版 pp.94-105
-
小西貞則 統計数理研究所彙報 第32巻 第2号 1984 p.160
https://ismrepo.ism.ac.jp/?action=repository_uri&item_id=32671&file_id=17&file_no=1&nc_session=8b9e4bvk5mv5arb3qdbu5rlkb0%20target= -
https://ja.wikipedia.org/wiki/%E9%A0%86%E5%BA%8F%E7%B5%B1%E8%A8%88%E9%87%8F
-
http://www.eeso.ges.kyoto-u.ac.jp/emm/materials/basic_stat/orderstat