TL;DR
.NET Core(2.2)上で倍精度浮動小数点を使った演算を行うと、同じ順序で計算させても環境によって計算結果がズレるから、比較するときとか注意すべきではないかと考える1。
実際やったこと
実行したテストの内容は以下の通り
-
[-90°,+90°]の区間を1°につき128分割してその弧度を計算した。 - 予め計算されている上記に対応した弧度を元にして、
sin,cos,tan及び、sin/cosを標準のSystem.Mathを使い計算した。
弧度の計算方法
弧度の計算は、以下の二種類を利用した。以下、対応するDegreesをdとする。
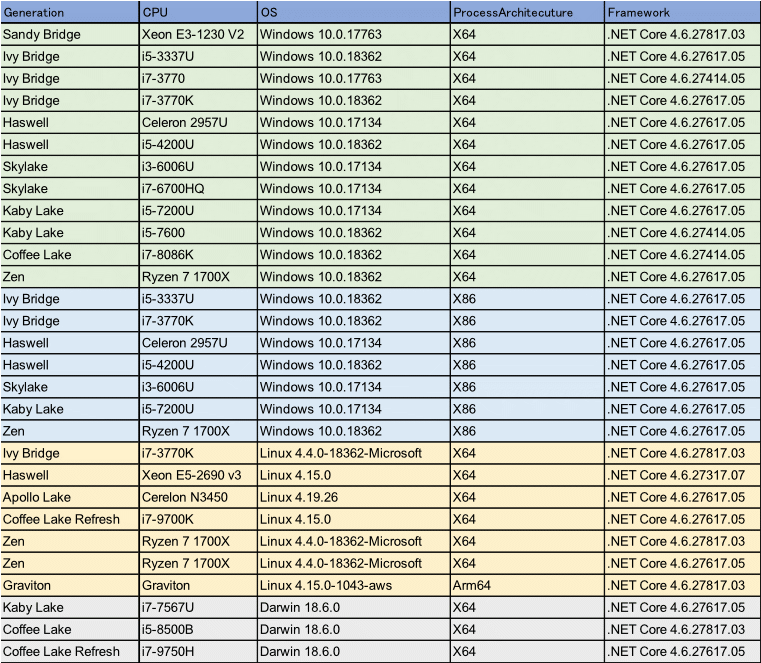
実行環境一覧
今回も多数のご協力を得る事が出来た。
また、この検証を進めるに当たり、多くの方から資料の提示や、アドバイスを頂くことが出来た。
この場を借りてお礼申し上げます。
テストした実行環境は以下の通りとなる。
計算させた結果に関する考察
さて、実際計算させた結果、割と面白い結果になった。
この先示す図表で、○は差異が出なかったことを示し、×は差異が存在したことを示している。
Windowsの場合
Windowsは唯一.NET Coreの32bit環境が存在する。そこで、32bit環境と、64bit環境を各々で比較してみたところ、以下のようになった。
32bit Process windows
実行結果は以下の通り。
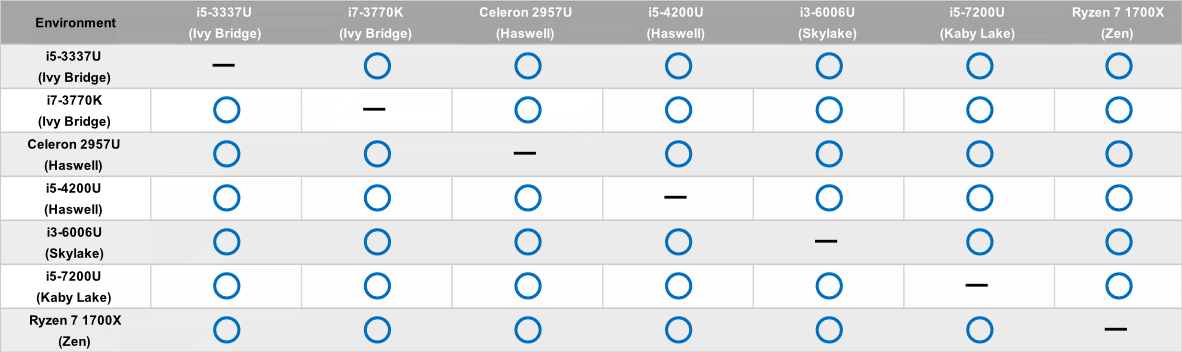
上記結果のように32bit版Windowsでは環境によって今回差異が出なかった。
これは恐らく、浮動小数点演算をx87 FPUで行っており、三角関数は各々、fsin、fcosを使って演算していたので、差異が出なかった者と考えられる。
但し、主にAMDとIntelで歴史的な経緯により実装に差異があるとのことだったので3、他の計算を行った場合、差異が出てくる可能性があるかも知れない。
64bit Process Windowsの場合
実行結果は以下の通り
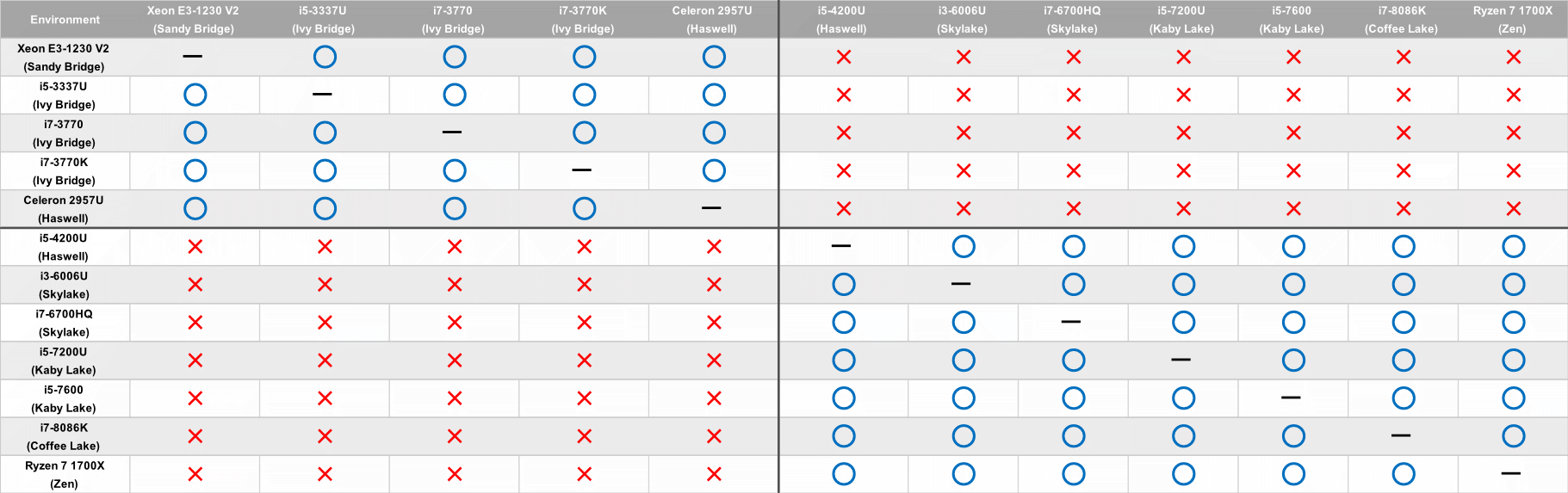
64bit ProcessのWindowsの場合、
FMA3命令を持っているか否かで計算結果に差異が出てくる結果となる。
FMA3の有無で差異が出るのは、[FMA (Fused Multiply-Add) について色んな観点でまとめてみた]によれば、丸めの回数が減るので、結果計算結果に差異が出たのではないかと予想される。
macOSの場合
macOSの場合は以下のようになった。
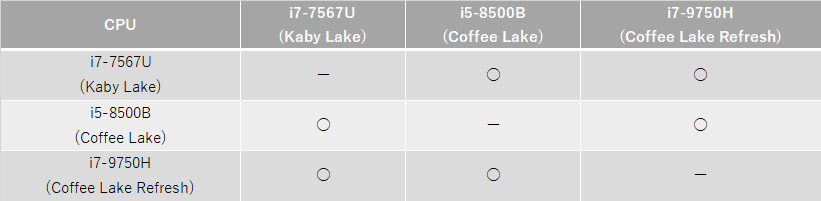
上記結果のように、CPUの差異で計算結果に差異が出るようなことはなかった。
但し、CPUが全てFMA3を持っているモデルなので、FMA3を持っていない場合でも、当該環境内における再現性が担保されるか否かは不明である。
Linuxの場合
Linuxの場合以下のような結果になった。
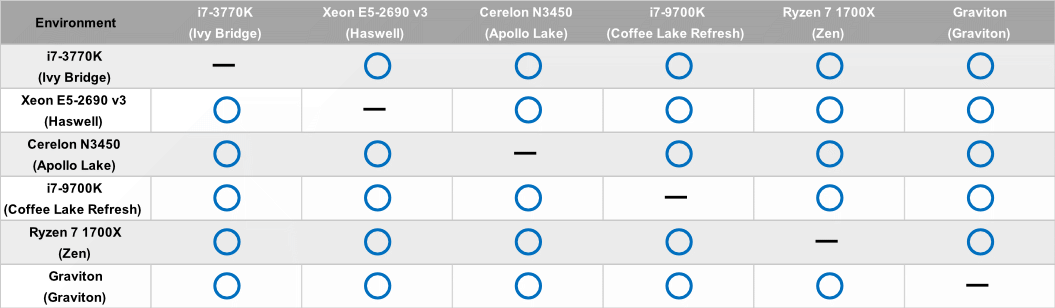
上記の、i7-3770kと、Ryzen 7 1700xは、WSLのLinux(Ubuntu 18.4)であり、GravitonはAWS上のUbuntu on ARMインスタンスとなっている。
このように、Linuxで有ればアーキテクチャ、CPUの世代、実行環境によって計算結果に差異が出なかった。
又、Linux上のclang及びgccを使用して同一の計算を行った場合の結果を以下に示す。
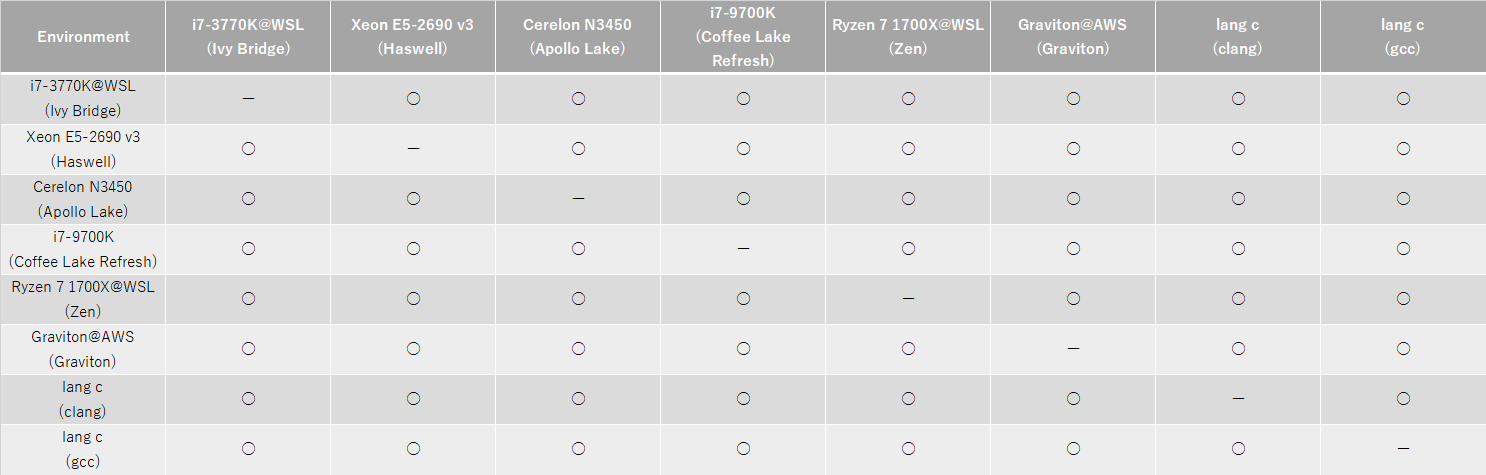
このように、clangと、gccを使った場合でも計算結果に差異が出なかったので、恐らく全てのパターンで標準のlibcを使っているのではないかと予想される。
各プラットフォーム間の検証
各プラットフォーム間の検証結果は以下の通りとなった。
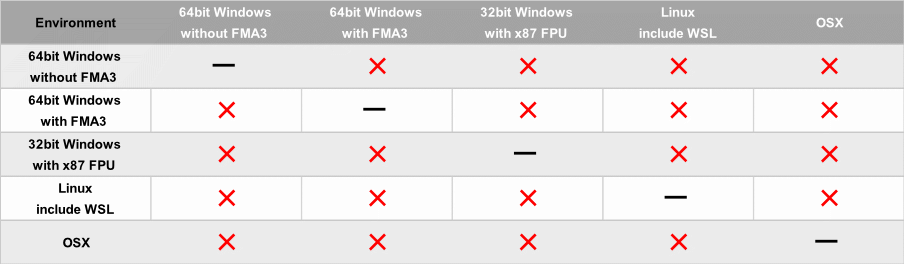
このように、各環境間では全ての環境間で差異が出た。
まとめ
以前の検証でILがASMに変換された結果を調査していたとき、X86とX64で実数計算をx86はFPU、x64はSIMDで行っていたので、差異が出たらちょっと面白そうだな程度で調べてみたのだが,中々どうして興味深い結果となった。
計算順序が同一であったとしても今回の検証により、実行環境の差異によって計算結果に差異を生じることがあり得ることがわかったので、異なる環境間で計算を行いその比較を行う際は、注意が必要では無いかと思う。
-
とは言え、実用上問題となるほどズレるわけではなく、下何桁かに差異が出てくる形となる。 ↩
-
今回のケースでのみ使うことを想定していたので、NaNとInfのチェックはしてたけど、非正規化数か否かのチェックは省いている。(実用性を考えるなら当然行うべきだと思う) ↩
-
[Cross Platform Floating Point Consistency](https://stackoverflow.com/questions/20963419/cross-platform-floating-point-consistency)に、**Again, in case of the x87 instruction set, Intel and AMD have historically implemented things a little differently.**とあった。 ↩