前口上
どうも時計屋です。
時計売りながらなぜかC#で遊んでます。
さて今日は技術系雑談DiscordサーバのGeek-Spaceで企画されたアドベントカレンダーの19日目ということで、参照と値に関して一席ぶちたいかなと。ということで、おつきあい頂ければこれ幸い。
さて、参照と値と一口には言いましても所変われば意味変わるなどというのはよくある話なので、今回は『C#における参照と値』ということにしましょう。また、ボクシングに関しては今回触れません、また文字列に関しては厳密に後述する参照型ではあるけど、ここにぶっ込んでしまうとよけい混乱することが目に見えているので今回は意識的に割愛して進めていくのでなにとぞご理解のほど1。
また今回は概念というか考え方を大掴みで取って貰うことに主眼をおいているので、厳密な解釈やら、実際メモリにどのように配置されるのかという点の考察をそこまで行ってません2。そんなこともあって最適化に関する考察は一部を除いてほぼ今回その議論をしていないのでその辺をお察しいただければ重畳。
ついでにいうなら、縛りを2つばかり入れてこのエントリを書いてみることにしました。
C#における参照と値
C#において、参照と値という言葉は『型』と『引数の渡し方』の主に2つの文脈で語られることがわりかし多い気がしてる(弊社調べ)。
また最近だと、『refローカル変数』『ref構造体』『ref戻り値』の文脈でも使われているけど、ここらはそれなりに作ってみて速さが足りないときに使うものなので、今回の議論の範囲を超えそうだし、何より議論がとっちらかりすぎて収束できる自信も皆無なのでばっさり切り捨ててみた。
ここでは、最初に値型、参照型の考察を行った上で、続けて引数における値渡しと参照渡しを考察していくことにしてみようかと。
値型とは何なのか?
んじゃ、まず最初に値型とはどんなものなのか、以下のコードを元に考察していこうかなって
int i=42;//-①
int j=i;//-②
Console.WriteLine($"i:{i}");
Console.WriteLine($"j:{j}");
j=100;//-③
Console.WriteLine($"i:{i}");
Console.WriteLine($"j:{j}");
まず最初に、②の後のConsoleへの出力ではi,j共に42が出力されること。
また、③の後のコンソール出力がiは42、jが100となることを実際実行して試してみてほしい。
さて、①ではiへ42を代入している。これをもう少し詳しく言えば、iで表現される記憶域へ、整数の値42を書き込んだと表すことができる。
さて、②では①と異なり、jへiを代入している。これを詳しく言えば、jで表現されている記憶域へ、iで表現されている記憶域に保持している内容を書き込む。と同様に表すことができるだろう。
ここで重要なのは上図の通り、i、j共に42を保持している。但し各々が表現している記憶域は完全に独立していることにある。以上のことから、値型への代入はすべて内容をコピーすることで実行されることがわかる。これをまとめると、①,③は各々変数へ数値リテラルの値をコピーしていることになるし、②はjへiの値をコピーしていることにほかならない。
これを図示すると以下の通りとなる

このように、変数がその方を表現する値と直接結びついていることを、"value semantics"又は、『値セマンティクス』と呼ぶ。
C#では、値のセマンティクスを持つ方のことを値型と呼び、これは構造体と列挙子が値型となっている。
参照型とは何なのか
それでは続けて参照型とは何なのか以下のコードを元にして考えていきたい。
int[] a=new int[]{42};//-①
int[] b=a;//-②
Console.WriteLine($"a[0]={a[0]}");
Console.WriteLine($"b[0]={b[0]}");
b[0]=100;//-③
Console.WriteLine($"a[0]={a[0]}");
Console.WriteLine($"b[0]={b[0]}");
さて、上記のコードは値型を考察したときのコードとほぼ同一だが、変数の型が整数型から整数型の配列へ変化している。
②の後のコンソールへの出力はa,b共に42となっている。しかし③実行後のコンソールへの出力は値型とは異なり、a,b共に100へ変化している。
値型を検証したときのコードとほぼ同じ操作をしているにもかかわらず、値型とは異なった結果になった。
それでは、値型に対する考察と同様に参照型の挙動を確認していくことにしよう。
それじゃ①では実際どのようなことが起きたのか考えてみよう。
変数へ代入するという意味だと先の値型と行っていることに差異はない。けど、代入する方法が実は違う。
右辺でnew int[]{42}としているけど、これは整数配列の要素0を42で初期化してこさえるという意味になる。
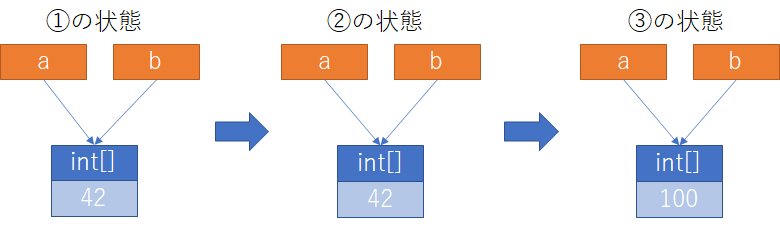
で、こさえたものをaへ代入しているのだけど、このような場合値型のようにaは値型のように右辺で生成された整数配列の記憶域そのものを表現してはいない。ではいったいなにを表現しているのかというと、記憶域のどこかにある整数配列への参照情報を表現している。
このように、参照型の変数は記憶域そのものを表現するのではなく、文字通り記憶域のどこかにある実体を指し示す情報を保持しているといえる。
ここを押さえた上で、②では実際どのようなことが起きているのか考えてみると、aが保持している参照情報を変数bへ代入しているといえる。これは同じ配列の実体を変数aもbも参照していることにほかならずその結果、③で変数bを経由して0番目の用を100に書き換えれば、aとbが参照しているint配列の実体は同一なので、aを経由した要素0の値は100となっていることになる。
これらの流れを図で表すと以下のようになる。
それでは参照型のまとめとして以下のようなプログラムを考察してみよう。
int[] a=new int[]{42};
int[] b=a;//-①
Console.WriteLine($"a[0]={a[0]}");
Console.WriteLine($"b[0]={b[0]}");
a=new int[]{42};//-②
b[0]=100;//-③
Console.WriteLine($"a[0]={a[0]}");
Console.WriteLine($"b[0]={b[0]}");
①の状態は既にに説明したので割愛するとして、③を実行後にどうなるかというと、a[0]は42、b[0]は100となる。
これは、②でaに新たな整数配列の実体を参照させなおしているので、状態として、下図のような形となっている。結果、aとbは別々の整数配列を参照しているため、最初と異なり別個の数値が出力されることになる。
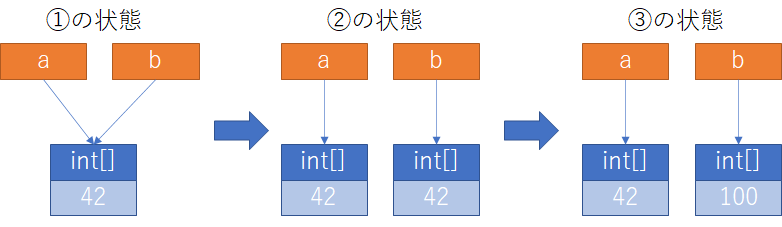
先と同じようにこのように、変数が参照情報のみを持ち、実態は記憶域のどこかにある形態を"Reference semantics"又は『参照セマンティクス』と呼ぶ。
尚C#では参照セマンティクスを持つ型を参照型とよび、クラス、インターフェース、デリゲートがそれにあたる。
値型と参照型のまとめ
以上、値型を最初に考察して、続けて参照型の考察をしてみた。
簡単にまとめれば、値型の変数などの識別子はその型を表現する記憶域そのものを表しているといえる。
他方、参照型は参照型の実体は記憶域のどこかに存在しており、変数などの識別子はその実体が記憶域のどこにあるのかというまさしく参照するための情報を表していることになる。
これらのことから、値型への代入は常にその記憶域のコピーを伴って実行される。その結果代入先と代入元は代入時点で同じ値を持つが、その実別個の存在として表されている。
また、各セクションの最後で触れた"Value semantics"と、"Reference semantics"はC#に限らず極めて一般的な概念となっている。C#においてはこの概念が型の属性として存在していることから、"Value semantics"を持つ型を値型、"Reference semantics"を持つ型を参照型と呼称している2。
C#における引数の値渡しと参照渡し
ある関数から別の関数を呼び出して利用するということはプログラミングを行っていく中で極めてよくある操作の一つといえる。関数を呼び出す際に、関数の呼び出し元から呼び出し先へ情報を転送して結果を得ようとしたとき、典型例として引数を使うことが多いだろう。以下のような簡単なサンプルを元にこれからの考察に必要な話題を整理していこう。
//インデントが見にくくなる関係で、クラスを含めていない。
static void Main()
{
int a=10;
int b=20;
int result=Add(a,b);
Console.WriteLine(result);
}
static int Add(int x,int y)=>x+y;
このサンプルがやっていることはとても単純で、Main関数から、Add関数を呼び出しその結果をコンソールに出力して終了するという体裁をとっている。
このときAdd関数は2つの整数値を受け取って、その加算した結果を返却する。そして呼び出し元から加算に使う整数値を引数、xとyという形で受け取り、それをAdd関数内部で実際利用して処理を行っている。この、関数定義時に現れる、xとyのことを仮引数(Parameter)と呼ぶことにする。
一方、Main関数内では、整数変数aおよびbが定義され、10と20が割り当てられている。その後Add関数をaおよびbを渡す形で呼び出している。このときの(a,b)を実引数(Argument)と呼ぶことにする。実引数は何かほかの変数である必要はなく、このAdd関数の場合、Add(10,20)のように、整数リテラルを渡したとしてもここで現れる(10,20)は実引数となる。
ここで、Main関数に注目してみよう。その内部で使われている変数aおよびbはローカル変数なので、Main関数の外部からこれらの変数を読み取ることはできない。一方Add関数の仮引数xおよびyはAdd関数内で、すでに割り当てがすんでいるローカル変数のように扱える。これらをまとめると、呼び出し先と呼び出し元の関数でほかから不可視な情報を引数という仕組みを通して関数間でやりとりしているといえる。
これから考察していく、値渡しと参照渡しはこの仮引数と実引数特に実引数に変数を入れた場合の関係性に関して深くみていく必要があるためその前段として引数の持つ意味と、呼び出し先および呼び出し元におけるやりとりにおいて引数がどのような機能を持っているのか少し説明した。
値型の値渡し
それでは最初に値型の値渡しに関して考察していく。先ほどのサンプルを少し手直ししてみよう。
//インデントが見にくくなる関係で、クラスを含めていない。
static void Main()
{
int a=10;
int b=20;
Console.WriteLine($"a:{a} b:{b}");//-①
int r=Add(a,b);
Console.WriteLine($"a:{a} b:{b}");//-④
}
static int Add(int x,int y)
{
Console.WriteLine($"x:{x} y:{y}");//-②
x=x+y;
Console.WriteLine($"x:{x} y:{y}");//-③
return x;
}
ここでは左記の例とは異なりAdd関数内で仮引数xへ、xとyを加算した結果を代入して、その結果を仮引数xを返却する形に変化している。また、仮引数の状態を確認するためコンソールへの出力を複数回行っている
このサンプルプログラムを実際に実行してみると、以下のような出力を得ることができる
a:10 b:20
x:10 y:20
x:30 y:20
a:10 b:20
30
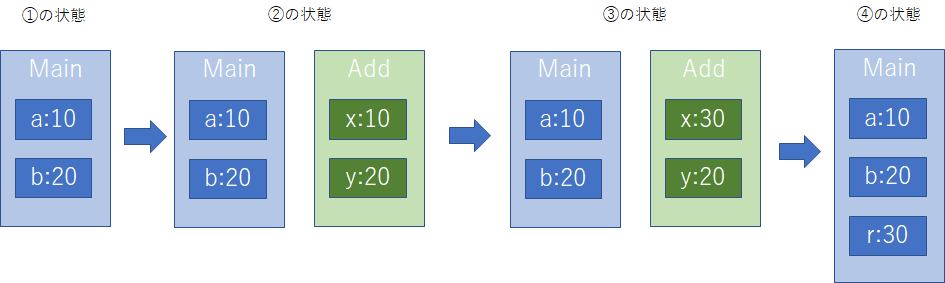
サンプルコードの付番と、出力結果の付番は一致している。ここで、①と②に関しては特筆すべきことはなく、①では、aとbに割り当てられた10と20が出力されている。②では、仮引数xとyに実引数(a,b)で渡された10と20が割り当てられ、その結果を出力している。
続けてそれ以降の処理をみていこう。xへyの値を足し込み、その結果を③で表示することになるので、ここではxは30、yは20の出力を得ている。ここでxを返却値としてAdd関数を抜けて呼び出し元のMain関数に戻ってきた後、再び実引数で利用していた、変数a及びbが変化したか否かを確認するためコンソールに出力しているが、ここではなんの変化もなく①と同様に10と20が出力されていることがわかる。
以上のことから、実引数として渡したMain関数の変数a、bと、Add関数の仮引数xとyの関係性は、操作と結果という点にのみ着目すれば、仮引数x及びyを右辺値とし実引数として渡した変数a及びbを右辺値とした代入操作と同じ結果を得ているといえる。
この状態を流れに沿って図示していくと以下のようになる。
このように、仮引数に何の修飾もせず値型の変数を用いることを**『値型の値渡し』**と呼ぶ。
参照型の値渡し
続けて参照型の値渡しとはどのようなものなのかこれまでと同様にサンプルコードを元にして考察していくことにしよう。
static void Report(string message,int[] array)
{
Console.Write($"{message} ");
Console.WriteLine(string.Join(" , ",array));
}
static void Main()
{
int[] array=new []{1,42,100,200};
Report("Main①",array);
Add(array);
Report("Main⑤", array);
}
// You can define other methods, fields, classes and namespaces here
static void Add(int[] values)
{
Report("Add ②",values);
int accum=0;
foreach(int item in values)
{
accum=accum+item;
}
values[0] = accum;
Report("Add ③", values);
values = new []{42};
Report("Add ④", values);
}
それでは早速考察していこう。
このサンプルでは最初に、整数配列を作成してそれをAdd関数に渡している。
Add関数内では受け取った整数配列をすべて加算してその結果を受け取った配列の最初の要素へ代入し、その後仮引数valuesへ新しく要素1の整数配列を割り当てている。
これを元にして、実引数として渡したMain関数内のarray変数と、Add関数の仮引数valuesの関係性がどのようなものであるかみてみる。
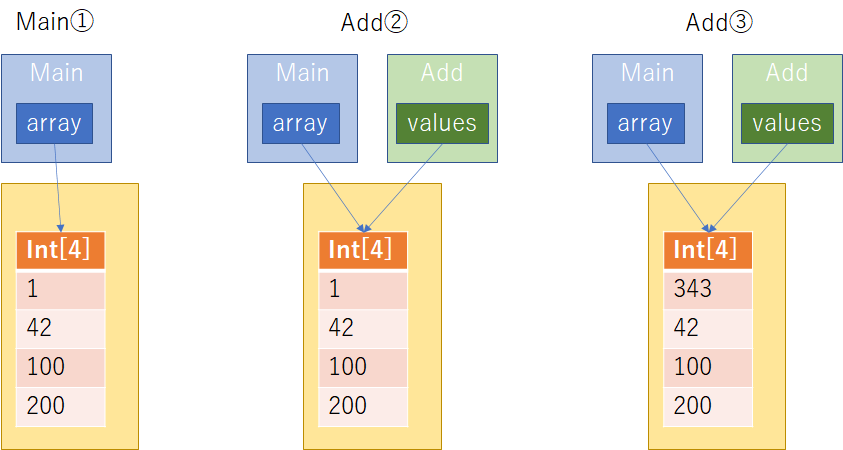
①及び②の出力結果は初期化済みのarray変数の出力と、values仮引数の初期状態を示すものであり特に難しいことはない。
さて、続けてvalues[0]へ加算した結果を代入した後の出力では当然values[0]の値が計算結果343となっている以外変化はない。
Add関数の最後にvaluesへ要素1の配列を差異割り当てしてその結果を④として出力している。
続けてAdd関数から制御が戻ってきたMain関数で変数arrayの内容を⑤として再び出力して終了している。
ここで、⑤の結果に注目してみると、Add関数で最初の要素に加算した結果を代入していたことがそのまま反映され、③と⑤は同じ結果を得ている。
先に検証していた参照型で説明した、左辺値に仮引数values、右辺値に実引数として渡したMain関数のarrayに対する代入操作と、その後の挙動の結果と一致している。
この流れを図すると以下のようになる。

先に説明した値型の値渡しと同様に、何の修飾もせず参照型を引数に利用することを**『参照型の値渡し』**と言う。
値渡しのまとめと参照渡しへのとっかかり
さてこれまで、値型と参照型に関する値渡しの考察をしてきた。基本的な考えは、値型と参照型で説明した任意の変数を別の変数へ代入した時、その代入先の変数に対する操作が、元の変数の表現する内容にどのような変化を与えるのかまたは与えないのかという振る舞いとほぼ同じということがわかったと思う。
関数の入力インターフェースは引数を使い、出力インターフェスには関数の戻り値を使うことが一般的である。しかし、例えば Interlocked.Increment メソッドなどのように、入力した引数に直接作用させる必要がある関数が存在する。
また、Dictionary.TryGetValue(TKey, TValue)メソッドなどのように戻り値にboolで取得の可否を通知することでif文に直接利用できるメソッドを考えた場合、出力される値は戻り値とほかの方法で取得する必要が出てくるであろう。
このような振る舞いを望むなら、先に挙げたような参照型に対する値渡しを使い、参照型のメンバ変数やプロパティを操作することで呼び出し先の関数で処理した結果を呼び出し元の関数へ反映させることが可能なのは先に見てきたとおりである。
しかし、値型に対して実引数の内容を仮引数の操作にともなって変化させることや、参照型の参照先を変化することは値渡しによって実現することはできない。
参照するということ
参照渡しの考察に入る前に、参照するとはどういうことなのか少し考えてみたい。
先に考察してきた参照型で説明してきたとおり、参照するとは記憶域のどこかにある実態を参照するための情報を保持しているだけで、変数そのものが実態を表現しているわけではなかった。もう少し詳しくいうと、参照型の変数は記憶域のどこかにある実態への参照情報という値を表現していることになる。
このように考えた場合、値型にせよ、参照型にせよ、呼び出し先の関数が定義した仮引数へ実引数を渡しても、実引数そのものにたいして、呼び出し先関数の結果を反映させることはできなかった。
しかしながら、先述の通り、仮引数に対する操作の結果が実引数に反映させたいことがあるので、仮引数に渡された実引数そのものを参照させるということが参照渡しの考え方の基本となってくる。
値型の参照渡し
それでは最初に値型の参照渡しを考察していこう。値型の値渡しの考察を行った際のサンプルコードを少し改変して、以下のようなサンプルを作った。
static void Main()
{
int a = 10;
int b = 20;
Console.WriteLine($"a:{a} b:{b}");//-①
Add(ref a, b);//-②
Console.WriteLine($"a:{a} b:{b}");//-④
}
static void Add(ref int x,int y)
{
x+=y;//-③
}
このコードの出力結果は以下のようになる。
a:10 b:20
a:30 b:20
さて、ここで先の値型の値渡しを大きく様相が異なる点が一つある、それは変数aがAdd関数の呼び出し前と呼び出し後で変化していることである。また、関数定義と呼び出し時にrefという今までになかった修飾子を伴って引数を渡していることも特徴の一つである。
それでは、最初に実行した結果を検証していこう。注目すべき点は、Add関数内でxへyを加算代入した結果が実引数aに反映されていることにある。この結果は今までになかった振る舞いになっている。値型の説明ですでに述べたとおり、値型の変数をほかの値型へ代入したり、値型の値渡しで実引数を借り引数へ渡した場合は、代入先の変数や、仮引数の値を変化させても元の代入元の変数や実引数に反映することはなかった。これは値型に対する代入や値渡しというものが原則としてコピーを伴って行われるものであり、各々の実態は代入後、または渡した後に互いに独立した存在となっているため、内容の変化が元々の変数に影響を与えることはがなかったからである。
しかし参照渡しの場合、結果から明らかなように、変数aはAdd関数の実行前と実行後で仮引数xへの操作結果を反映している。これは仮引数xが変数aの値をコピーして渡されたのではなく、変数aそのものへの参照として渡されたことにほかならない。
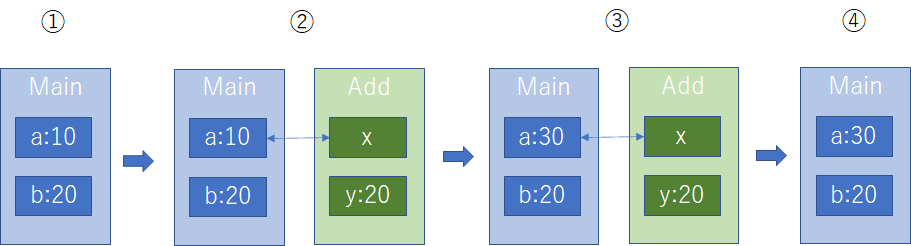
このように、値型の引数が参照を伴って渡されることから、これを**『値型の参照渡し』**と呼ぶ。
仮引数にも、実引数にもなんの修飾もしなければ値渡しとなっていた。一方、参照渡しの場合、この例の通り、仮引数にも実引数にもrefという修飾がついてる。このようにrefという修飾をつけることでC#ではその引数が参照渡しとして取り扱われることを示している。
一方、仮引数にref修飾がついていれば実際問題、実引数にrefをつけるのは少々冗長ではあるが、C#では仮引数、実引数のいずれにも修飾を伴うことを強制している。これは値渡しと異なり、関数を呼び出した結果が、実引数を書き換えてしまう可能性があるため、修飾を強制することでより明確に引数が参照で渡されることがわかるようにするためである。
参照型の参照渡し
それでは次に、参照型への参照渡しを考えてみよう。『参照を参照する』というのは中々複雑そうに見えるが、先の値型の参照渡しとほぼ同じ意味を持つ。それではサンプルとして、整数の配列を2つとって、その位置を変更するSwap関数を作ってみよう。
static void Report(string message,int[] array)
{
Console.Write($"{message} ");
Console.WriteLine(string.Join(" , ", array));
}
static void Main()
{
int[] a = new[] { 1, 2, 3 };
int[] b = new[] { 4, 5, 6 };
Report("a",a);
Report("b",b);\\-①
Swap(ref a, ref b);
Console.WriteLine("Swap method was called.");
Report("a", a);\\-④
Report("b", b);
}
static void Swap(ref int[] x,ref int[] y)
{
int[] tmp=y;\\-②
y=x;\\-③
x=tmp;\\-③
}
そして、このサンプルコードの実行結果は以下のようになる
a 1 , 2 , 3
b 4 , 5 , 6
Swap method was called.
a 4 , 5 , 6
b 1 , 2 , 3
配列の内容ではなく、配列そのものに注目したとき、Swap関数の前後で変数aと変数bの参照している配列の実態が交換されているということがわかると思う。そしてこれが、参照型の参照渡しの本質となっている。
これを図示すると以下のようになる。
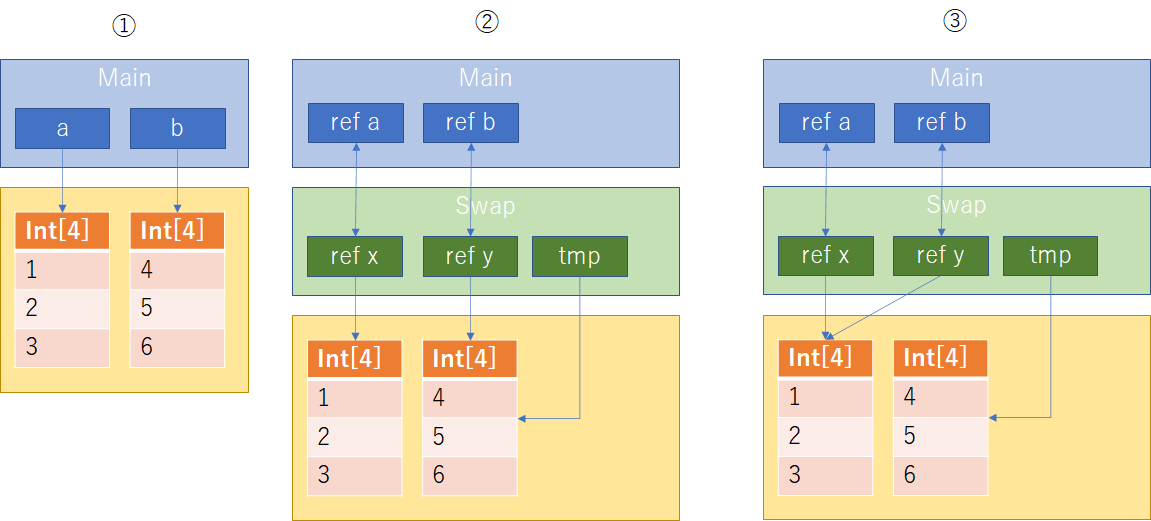
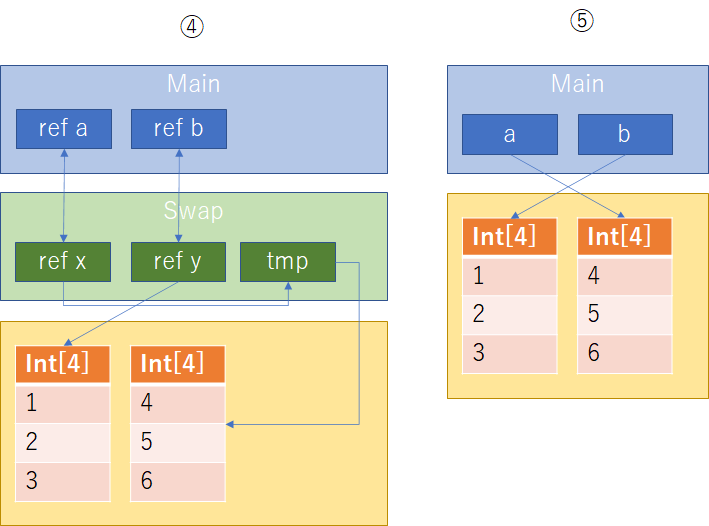
順を追ってみていこう。①に関しては普通に変数aに1,2,3、変数bに4,5,6の配列を参照している。②はSwap関数を呼び出し、int[] tmp=y;を実行した直後を示している。ローカル変数tmpに仮引数yを代入しており、これの意味するところは、仮引数y(つまり実引数b)が参照している配列への参照を持つ変数tmpを割り当てたということになる。③では仮引数yの参照先を仮引数xの参照先へ変更している。このとき、仮引数yは参照渡しされているので、仮引数yは実引数bの参照情報を**"参照"していることになり、仮引数yの参照先を変更することは元の実引数bの参照先を変更することになる。続いて④では、②で作成したローカル変数tmpの参照先(つまり初期状態で仮引数yが参照していた先)を仮引数xへ代入している。これも先の③と同様に仮引数xは実引数aの参照情報を"参照"**しているので、仮引数xへローカル変数tmpを代入することによって結果的に、実引数aは元々の実引数bが参照していた配列を参照し直していることになる。最後にSwap関数を抜けた状態では、先の③と④の操作が実引数aとbに反映される結果となり、元の参照とSwapされた状態になっていることを⑤は示している。
参照渡しとは何なのか
以上、値型と参照型に分ける形で引数の参照渡しを考察してきた。
意味ではなく、挙動として参照渡しを表現すならば、参照渡しで渡された場合、仮引数に対する操作はすなわち実引数に対する操作と等価となるといえる。そして、参照渡しの対象となる型が値型になっても参照型になってもこの意味が変わることはない。しかしながら、先に考察した参照の値渡しも呼び出し先関数によって変更した内容が呼び出し元に反映されるので、挙動としての類似性はある。ただし、この反映された結果というのはあくまでも参照されている先の実態を変更した結果によるものであり、仮引数と実引数でやりとりしている参照情報そのものを変更しているわけではない。このことから、参照型の値渡しと、値型または参照型の参照渡しは明確に異なるセマンティクスを持っているといえる。
参照の渡し方
値渡しの場合、未割り当ての変数を実引数として渡そうとした場合、コンパイルエラーが発生する。同様にこれまで使ってきたref修飾された参照渡しも割り当てのなされていない変数を実引数とした場合、コンパイルエラーになる。
しかしこれまで考察してきたとおり、参照渡しを行った場合、仮引数を通して実引数に対する割り当てを行うことができることがわかった。そしてこれを積極的に使おうと思った場合、呼び出し先で値が読み取られることがなく、出力専用として使われる引数の存在を容認することになる。しかし、この挙動をref修飾された参照渡しに許容してしまった場合、呼び出し先に実引数が渡されたとき、すでに実引数が割り当てがすんでいる状態であることを担保することができなくなってしまう。同様に出力専用とした場合、呼び出し先で確実に割り当てが行われる担保もできない。
これらの問題を解決するために、C#では参照渡しを行うとき、割り当ての責任が呼び出し先にあるのかそれとも呼び出し元にあるのかを分けて記述することが可能になっており、その修飾キーワードがrefとoutとなっている。
また、これまでの考察と完全に矛盾することになるが、参照で引数を渡す反面、呼び出し先における変更を許容しないin修飾も最近追加された。最後に、これらの参照渡しの方法を個別にみていくことにしよう。
ref引数
最初に一番の基本となるref修飾がどのようなものであるか考察してみる。refは文字通りreferenceの略形であり、最も基本となるものだ。先のサンプルのようにすでに割り当て済みの変数を参照渡しすることができ、呼び出し先ではref修飾のついた仮引数に対する代入は任意となる。
しかし下記のように未割り当ての変数をrefを伴って渡そうとした場合コンパイルエラーとなる。
static void Main()
{
int a;
//Foo(ref a);NG,CS0165が発生。
a=100;
Foo(ref a);//OK,割り当て済み
Foo(ref a);//OK,割り当て済み
}
//OK,値を変更してもいい
static void Foo(ref int x) => x = 42;
//OK,値を読み取るだけでもいい。
static void Bar(ref int x)=>Console.WriteLine(x);
out引数
次にout修飾がどのようなものかみてみよう。outはoutputの略計であり、一般的には出力引数といわれている。そして、利用条件としては、未割り当ての実引数をとることができるが、呼び出し先でout修飾のついた仮引数には必ず割り当ての操作が必要になり、割り当てがなければコンパイルエラーとなる。このことから、ちょうど先に説明したref修飾と対になっているといえる。これもコンパイルエラーとなるサンプルを下記に示す。
static void Main()
{
int a;
Foo(out a);//OK,呼び出し先が割り当てる責任を持つので未割り当ての変数を渡せる。
a=100;//OK,割り当て済みの変数ももちろん使える。
Foo(out a);//OK,割り当て済み
Bar(out a);//NG,割り当て済みだろうと、Bar関数はout引数の条件を満たしていない。
}
//OK,割り当てがなされている。
static void Foo(out int x) => x = 42;
//NG,必ず割り当てなければならない。
static void Bar(out int x)
{
}
in引数
それでは最後に、In引数について考察していきたい。
これまで考察してきた、ref引数は参照先の再割り当てや内容の変更を許容し、out引数はむしろ割り当てを強制していた。このように、この2つの参照渡しの方法は仮引数を経由した実引数への再割り当て又は内容の変更を許容していたことになる。
しかしin引数に関しては参照として引数を取り扱う反面、呼び出し先関数で仮引数を経由した実引数への再割り当てまたは内容の変更を許容しない。その意味するところは後ほど考察していくとして、実際試してみよう。
static void Main()
{
var a=10;
//Ok,Inを明示してもいい。
Hoge(in a);
//OK,変更を伴わないのでinを省略することもできる。
Hoge(a);
//NG,リテラルは参照する先が存在しないので引数として使えない。
Hoge(in 10);//CS8156
}
static void Hoge(in int x)
{
//OK,内容を読み取っているだけ
Console.WriteLine(x);
//NG,内容を変更できない。
x=100;//CS8331
}
このように、in引数ができることは大体、値渡しができることと一致している。ただし、リテラルに関しては参照する先が存在しないので、コンパイルエラーとなる。同様に呼び出し先で仮引数の内容を変更しようとしてもコンパイルエラーになる。
また、ほかの参照渡しとは異なり、基本的に参照元となる実引数の内容が変化することはないので、in修飾は呼び出す際に省略可能となっている。
ただし、変更ができないという点はどこまでの範囲が変更不可であるのかを明確にしておく必要がある。逆に言えばin引数の不変を保証する範囲が存在し、その範囲から外れれば変更ができてしまうのだ。以下のそのサンプルを示す。
class ClassEnvelope
{
public ClassEnvelope()=>Builder=new StringBuilder();
public StringBuilder Builder {get;set;}
public void SetNewStringBuiler(StringBuilder builder)=>Builder=builder;
}
struct StructEnvelope
{
public StringBuilder Builder{get;set;}
}
static void ForClass(in ClassEnvelope x)
{
//NG,xの参照している先を変更することはできない。
x=new ClassEnvelope();
//OK,xの内容ではなく、xのが参照している先を操作している。
x.SetNewStringBuiler(new StringBuilder());
}
static void ForStruct(in StructEnvelope x)
{
//NG,xの参照先は値型なのでxの内容を変更することはできない。
x.Builder=new StringBuilder();
//OK,xが保持しているStringBuilderへの参照を元にして参照先を操作している。
x.Builder.Append("hello world");
}
最初のForClass関数は先に定義しているClassEnvelopeをin引数としてとっている。この場合、xの意味するところは記憶域のどこかにあるClassEnvelopeの実体への参照情報なので、inによって、不変となるのはxへの再割り当てのみであり、xの参照先となる実体への操作は許容される。
一方ForStruct関数の場合、StructEnvelopeをin引数としてとっている。この場合、xの意味するところは呼び出し先から指定されたStructEnvelope型そのものである。従ってinによって不変となるのは、Builderプロパティそのものなので、ここの変更は不可となる(当然xそのものへの再割り当ても不可能である)。一方、このStructEnvelopeが保持しているStringBuilderの参照の先にあるものは、変更が可能となる。
このようにin引数は引数そのものが不変となることを保証してるだけで、仮にin引数が参照型のプロパティやフィールドを保持していた場合、その先の実体への変更は別段保護されないので、注意が必要となる。
また、in引数はリテラルを実引数として受け付けないことや、変更を許容しないという違いはあるにせよ、基本的に値渡しと同じような結果を生む。
in引数が必要となる理由
先に値渡しとほぼ同様の結果を生むと述べた。それならばなぜin引数は必要なのか最後に考察していこう。
値型に関する考察を行ってきたとき、代入にせよ、値渡しにせよコピーすることで転送していた。整数型やbool型のようにサイズが小さいものであれば基本的にこのコピーという操作はそれほどオーバーヘッドコストにはならない。しかし例えば極端な例として、intのフィールドを100個持つ値型があったとして、これを高頻度に値渡しとして関数呼び出ししようとした場合、このコピーにかかるコストは無視できないものとなる。逆にintのフィールドを100個持つ参照型だった場合、引数で取り扱うのは参照情報のみであり、実体のコピーがなされているわけではない。同様に値型の参照渡しも呼び出し元に指定された先の記憶域に存在している実体を参照として渡しているので、先の例のように大きなサイズの値型を参照渡しで取り扱えば参照情報のみのやりとりとなり、コピーを伴わずに実引数と仮引数の間でやりとりが行われる。
このように最適化という側面でコピーがコストになるため、呼び出し先で変更を伴わない、より強く言えば変更してはならない場合でも、値型を参照で渡そうとした場合、従来はref引数でこれを行っていた。しかしrefはこれまでみてきたとおり、呼び出し先で渡した引数に変更が加えれば実引数にそれが反映されてしまうことになる。そこで必要になったのがin引数なのだ。
in引数であれば、呼び出し先で内容の変更が伴わないことを保証しつつ参照情報のやりとりだけで引数の取り回しが可能なため、大きなサイズの値型を取り扱う場合特に有効な最適化の手段となり得る。
逆に、参照型の引数にinをつけることは無意味となる。これは参照型そのものが値渡しにおいて、値型のin参照渡しとほぼ同じ意味を持つ挙動をとり、in引数をつけてしまえば、参照の参照を読み取り専用で渡す意味となるので、参照を引き剥がすコストもかかり、何の意味もない。
一方値型に関しては、in引数が有効か否か考えた場合、思慮するべき項目はでデリファレンスコストとコピーコストのどちらが重いかという見地に収束する。この意味するところは、値渡しとしてコピーすることで引数を渡せば、コピーするコストを支払う代わりに、実体そのものが渡されることから、呼び出し先関数内における内容の読み取りは、すなわちその実体を直接相手にすることができ、これは高速に行うことが可能となる。一方最適化という側面において参照渡しを選択した際は、一般的に参照情報のサイズはそのOSが32Bitなら32BIt、64Bitなら64Bitなので定数的かつ高速に行うことができる。ただし呼び出し先で内容を読み出そうとした場合、値型であったとしても、実際に渡ってきたのは参照情報なので、参照型と同様のデリファレンスコストを支払わなければならない。従って、intやdoubleなどのPrimitiveな数値型をinを伴って渡してしまった場合、基本的に一般的な値渡しより劣るパフォーマンスとなる可能性が高い。
以上のことから、in引数の使用の可否は参照型の場合は無条件で否定できる。一方値型の場合は、どちらのコストがより重いのかという問題になるので、Primitive型程度のサイズであればin引数は使うべきではないし、サイズとして十分大きければin引数を使うべきとなる。しかしより正確には、実際に使われるようなシナリオをモデル化した上でベンチマークテストを行う必要がある。
切口上 ~まとめに変えて~
僕がC#を好きな理由の中に、今回考察してきた値型を自分の手で作成可能であるという点と、参照渡しが存在することを挙げることが出来る。
この2つは参照型や値渡しほど一般的に使われるものではないけど、うまく使いこなすことで可読性を損なうことなく安全な範囲で最適化できる側面がある。一方、うまく使わなければ、構造がいびつになってしまったり、想定通り動いたとしてもパフォーマンスに劣る原因にもなりえてしまう。
今回、そのとっかかりとしてこれらの考察を行ってきた。前口上でちょっと触れた縛り項目としてポインタを文中に出さない、C/C++を引き合いに出さないということがあった。この2つを使うことでかなり説明は僕自身が楽はできる。けどC#の事象をC#で閉じた中で解説できるものなのか試すという意味も込めて今回このような縛りを入れてみた。
書き上げた直後の感想としては、そこそこうまく書けたかもと思う反面、特に記憶域とか、参照情報といった記述がそこかしこにみられたので若干いびつになってしまった点は否めなかったし、そこは僕の力不足を痛感している。
さて、最後のin引数の考察の中で、全く触れなかった最適化に関して触れている。個人的にC#で何か型を作るなら基本的には参照型と値渡しが第一選択じゃないかと思ってる。値型や参照渡しは参照型と値渡しでうまく表現できないこと、又は表現できたとしても効率よく動かない場合の強力な武器となる反面、よくわからないままに使ってしまえば不用意に複雑で使いにくいものにもなってしまう。これらのことを深く思慮しようとすれば、もっと多くの知識が必要になるとは思うけど、そのとっかかりの一つとしてこのエントリが一助となれば望外の僥倖とするところだったりする。
それでは残り少ない2020年と、来る2021年も皆様が素敵なプログラミングライフを送れることを願いつつ、Merry Christmas and a Happy New Year.