はじめに
ちょうど1年半前に実装トライしたテーマにトピックモデルがありました。知見が誰かの役に立つかなと思ったので、共有させていただきます。
かつて、社内に美容キュレーションメディアの事業が有りました。私は、業務推進 (Business Development) の立場として、集客戦略をお手伝いしました。キュレーションメディアの集客戦略の大動脈は、良記事を活かした自然検索からの流入です。
良記事の量産のために、分析の立場からどのような貢献ができるでしょうか。一つ挙げるならば、使える記事のネタを提供することではないかと考えました。これをもう少し要素分解すると、以下の2点に分けられます;
1. 世に出ている美容の話題の現状把握
2. 記事作成に役立つキーワードの提供
1点目については、技術的なアプローチがいくつか考えられます。アイディアのひとつが、本記事で上げるトピックモデルです。トピックモデルとは何か。一言で言うと、**「機械学習で記事の内容分類をしてくれるプログラム」**です。「記事の内容、話題=トピック」と解釈してください。
このモデルのすごい点は、記事単位だけでなく、記事を構成している単語単位についても、どのトピックに属するか判定してくれることです。結果として、記事レベル、単語レベルいずれにおいても話題の抽出・分類をすることができ、1点目の目的を達成することができます。
ちなみに、2点目は1点目と独立しているのではなく、密接な関係にあります。1点目で引っ張ってきたキーワード群に対して、SEO的観点から分析の手を入れると、2点目に到達できます。結果として、どの話題の記事から手を付ければいいのかということを戦略的に考えることができるようになります。
ということで、次章以降でトピックモデルについて理解を深めていきましょう。
トピックモデルの仕組み
繰り返しますが、トピックモデルとは「機械学習で記事の内容分類をしてくれるプログラム」のことです。具体的に説明するために、概略図を用意しました。
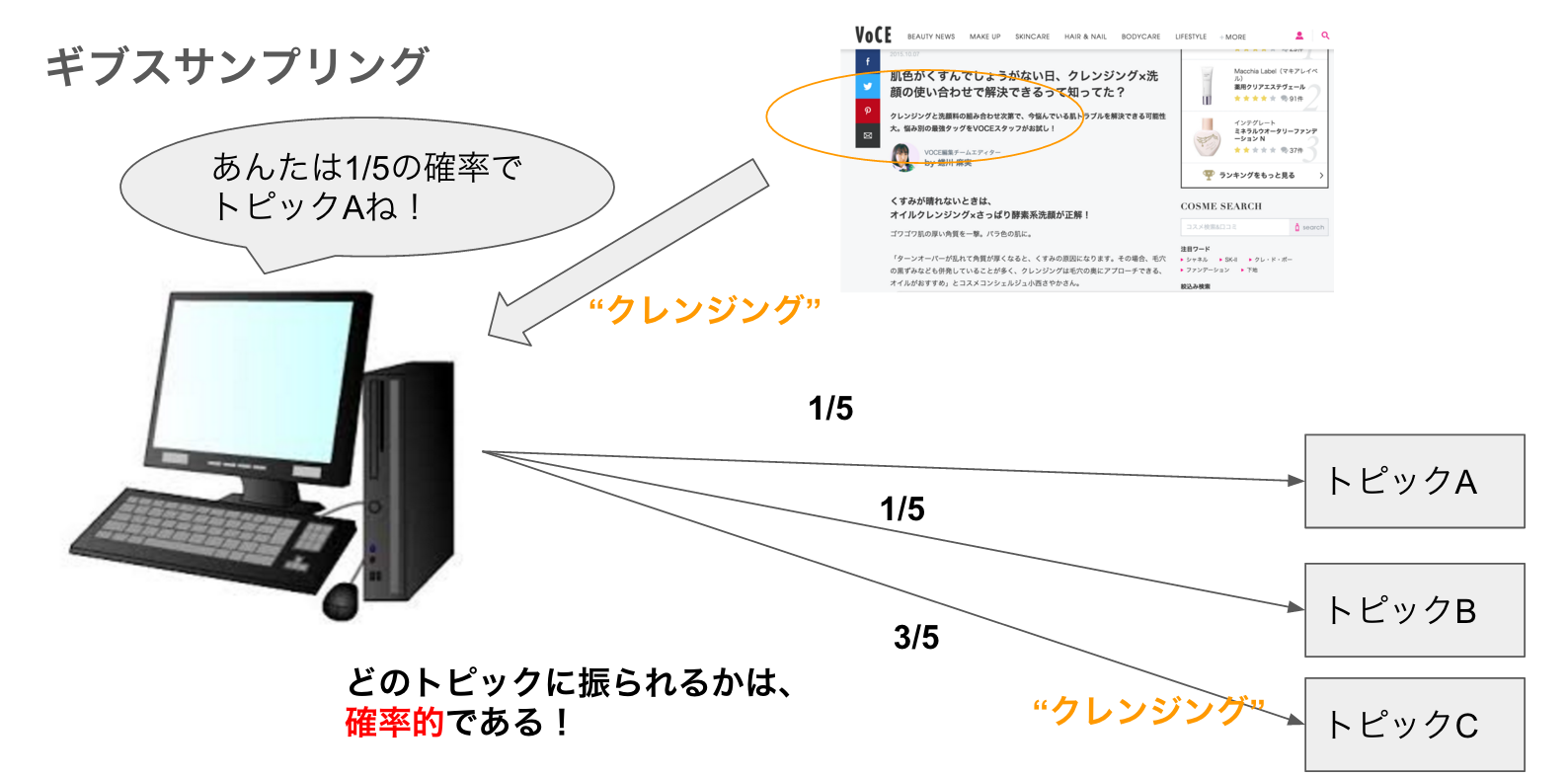
図の例では、美容記事の本文から、「クレンジング」という単語をピックアップしました。コンピュータは記事内、および記事間の単語「クレンジング」の出現割合を勘案し、単語「クレンジング」がトピックA、B、Cに割り振られる確率をそれぞれ計算します(図では計算の結果として1/5でAまたはB、3/5でCに振られると計算しました)。計算した確率をもとに、コンピュータは「クレンジング」をA~Cどのトピックに振るか決めます。当然、確率の高いCに振られやすくなります。ただし、確率なので必ずしもCになるとは限りません。とはいえ、例ではトピックC(例えば、「スキンケア」トピック)に振られましたが。
ちなみに、トピック名(ラベル)まではコンピュータも出してくれません。集まった単語の傾向から人がラベリングします。 (今後そんなライブラリも出たら面白そう)
以上から、トピックを振るという行為は**「確率的」であることがわかります。じつは、この「確率的」**というのがトピックモデルにおける大きな特徴です。確率的であるおかげで、文書・単語間に潜む潜在的な意味合いを炙りだし、トピックの代表的な意味に落としこむことができるのです。
次の章では、どのような計算規則でコンピュータがトピック分類をしているのか、説明します。
計算規則とモデル
前章でトピックを振る行為が「確率的」であると述べましたが、なぜ確率的に振ることができるのでしょうか?それは、単語、および話題(トピック)の散らばり方が、ある確率分布にしたがっているという前提(仮定)を置いているからです。その確率分布を、ディリクレ分布といいます。
ディリクレ分布とは、以下の等式を満たす確率分布のことです。
$$Dirichlet({\bf\phi} | \beta) = \frac{\Gamma(\sum_{v=1}^{V}\beta_v)}{\prod_{v=1}^{V}\Gamma(\beta_v)} = \prod_{v=1}^{V}\phi_{v}^{\beta_v -1}$$
$${\bf\phi}=(\phi_1,...\phi_V), \quad\phi_v \geqq 0,\quad \sum_{v=1}^{V}\phi_v = 1, \quad {\bf \beta } = (\beta_1,...,\beta_V),\quad\beta_v > 0$$
式の意味するところは、ベルヌーイ分布や二項分布の系と基本的に同じです(拡張したようなものです)。二項分布では、コインの表裏の出現回数の分布が典型例です。表裏の出る確率が$\phi$、表裏の出る回数が$\beta$に当たります。「面の数が V あるサイコロを$\sum_{v}\beta_v$回投げるときの出現確率の分布」みたいな感じです。$\phi$は固定、$\beta$は変動します。
単語「クレンジング」が記事に出現することと、サイコロで1の目(他の数字でも良い)が出ることを対応させてください。それがディリクレ分布を適用したことと同じ意味になります。トピックについても同様です。
ところで、「確率的」というと、次のような疑問を持つ方もいらっしゃるかもしれません。一つ一つの記事はライターが意図的に書いているため、単語やトピックの散らばりはランダムとするのはおかしい。すなわち、単語とサイコロの目を対応させるのは無理があるのではないか。この疑問を解消する鍵は、記事の集まりにあります。トピックモデルをかけるとき、対象となるデータは、複数(多量)の記事です。一つ一つの記事の単語の集まり方には一定の傾向があるかもしれませんが、それらが複数集まった全体の集合では、それぞれの傾向がぶつかり合い、ランダムに見えるのです。したがって、記事集合全体の視点から見ると、単語やトピックの出方は、サイコロの目が出る事象と同じように考えることができるのです (やや頻度論的な説明の仕方なので、違和感がございましたら恐縮です)。とはいえ、数学的には1記事だけでもトピックモデルの計算をすることはできます。ですが、計算結果にあまり価値や意味を持たないのは明らかです。
ここまでで、単語とトピックがディリクレ分布にしたがうことの有効性は分かりました。とはいえ、ディリクレ分布がトピックモデルのゴールではありません。単語が各トピックに属する確率を出すのが目的です。
<トピック振り分け手順>
1. トピック数 K を指定する
2. トピックk(= 1,...,K)ごとに単語のディリクレ分布を生成する。
3. 文書d(= 1,...,D)ごとにトピックのディリクレ分布を生成する。
4. 文書d中の各単語がトピックkに振られる確率(分布)を計算する。
5. 2. ~ 4. を"当てはまりがよくなる"まで繰り返す。
「当てはまりがよくなる」と書きましたが、当てはまりをよくする数学的手法は3種類あります。
(1) 最尤推定
文書dにおけるトピックの確率分布$\theta_{d}$、単語の確率分布$\phi_{w_{d}}$をもとに(対数)尤度関数を作ります。対数尤度関数が最大(極大)になる組み合わせを「当てはまりが良い」と判定します。最大を求める計算アルゴリズムはEMアルゴリズムを使います。
対数尤度関数 L :
$$L = \sum_{d=1}^{D}\sum_{n=1}^{N_d}\log\sum_{k=1}^{K}\theta_{dk}\phi_{kw_{dn}}$$
ここから負担率というトピックと単語の分配比率が計算されます。
$$q_{dnk} = \frac{\theta_{dk}\phi_{kw_{dn}}}{\sum_{k'=1}^{K}\theta_{dk'}\phi_{k'w_{dn}}}$$
これを変形して、トピック k で単語(語彙) v が出る確率は、
$$\phi_{kv} = \frac{\sum_{d=1}^{D}\sum_{n:w_{dn=v}}q_{dnk}}{\sum_{v'=1}^{V}\sum_{d=1}^{D}\sum_{n:w_{dn=v'}}q_{dnk}}$$
最尤推定による計算方法を別名**確率的潜在意味解析 (PLSA)**といいます。
(2) 変分ベイズ推定
ベイズ推定により当てはまりの良さを求める手法です。推定は尤度の最適化のために用います。尤度はPLSAと異なる形式で、周辺尤度といいます。
$$\log L({\bf W}|\alpha, \beta) = \log \int \int \sum_{{\bf Z}}p({\bf W}, {\bf Z}, {\bf \Theta}, {\bf \Phi}|\alpha, \beta)d{\bf \Theta}d{\bf \Phi}$$
ここで、${\bf W}$は文書集合、$\alpha$はトピックに関するメタパラメータ、$\beta$は単語分布に関するメタパラメータです。
この式にイェンゼンの不等式という関係を用いると、下限の式が出てきます。この下限を最大化することで当てはまりのよい状態を算出します。なぜ、「変分」という言葉がつくのかというと、下限の最大化の導出過程で変分法という数学手法を使うからです。以上から下限の式は変分下限 (variational lower bound)とよばれます。
変分下限の最大化はラグランジュの未定乗数法から導かれます。結果として、「最大値」ではなく、「最大になる確率分布の式」が導かれます(変分法なので)。この確率分布を変分事後分布といい、単語、トピックそれぞれの分布について導出されます。
(3) ギブスサンプリング
ギブスサンプリングでは、名称の通り単語1つ1つをサンプリングし、単語$w_{dn}$に相応しいトピック$z_{dn}$を推定します。サンプリング事例数が増えると経験分布よばれる確率分布に近似でき、単語$w_{dn}$にトピック$z_{dn}$が振られる確率を計算できます。
天下り的ですが、文書集合$W$、トピック集合$Z$の系において、単語$w_{dn}$にトピック$z_{dn} = k$が振られる確率は次の式で表されます。
$$p(z_{dn}=k|{\bf W} , {\bf Z_{-dn}}, \alpha, \beta) = Const.(N_{dk-dn} + \alpha)\frac{N_{kw_{dn}-dn} + \beta}{N_{k-dn} + \beta V}$$
ここで、
Const.:確率の和を1にする規格化定数
$-dn$: d番目の文書のn番目の単語を除くという意味
N: 各集合における単語数
V: 総語彙数(語彙とは、単語の種類(数)を表す。重複の出現を除くという意味。)
ポイントは、分子が「文書ごとのトピック所属数と単語ごとのトピック所属数」という要因積で表される点です。計算過程は複雑なのですが、最終的な計算結果はシンプルになるのです。
その他計算規則として**「最適なトピック数を推定するモデル」、「最適なメタパラメータを計算するモデル」が存在します。これらは、トピックモデルを実装する今回の目的において優先度が下がるので、ここでは触れないでおきます。興味のある方は、「中華料理店過程(CRF)」、「ポリヤ分布」**というKWを調べてみてください。
ちなみに、変分ベイズ推定、およびギブスサンプリングの手法を**潜在ディリクレ配分モデル(LDA)**と呼びます。
モデルを構築する
では、実際にトピックモデルを取り込み、美容記事からトピック抽出することにチャレンジしてみましょう!
今回構築した分析モデリングの体系は次の3ステップから構成されます。
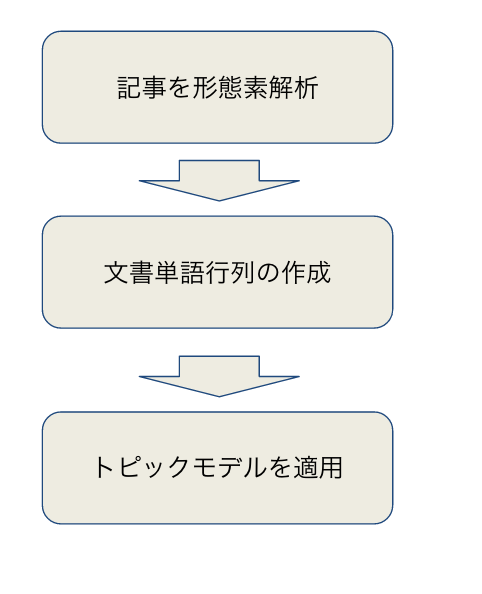
(1) 記事を形態素解析する
形態素解析とは、ざっくり言うと、文章を単語の区切りに切り分ける分析です。MeCab(めかぶ)というフリーの形態素解析器があります。形態素解析のイメージは次のような感じです;

文が単語に区切られ、品詞のラベルが付随しています。MeCabに登録される辞書にもとづいて品詞の区切りが決まります。
ここから分析に使う単語のフィルタリングをします。フィルタリングは2段階からなります;
①品詞の限定→名詞と形容詞を取り出す
②いらないワード(STOPワード)の削除→一文字ワード("あ"、"と")やサイト名("mery"など)など。分析や記事対策KWに使わなそうな単語をSTOPワードとして登録して省きました。
例えば、ある記事を形態素解析にかけてフィルタリングした単語集の一部を以下に挙げます。(全部で136単語抽出されました。)
※申し訳ありません。
2016年のキュレーションメディアの騒動でリンク切れになっている記事がございます。
ご了承くださいませ。

(2) 文書単語行列 (Document-Term Matrix; DTM)の作成
トピックモデルの入力データは、文書単語行列です。文書単語行列とは、行に文書、列に単語を設定した行列のことです。行列の要素には、記事の中の単語の出現頻度が入ります。(要素は頻度に限らずTFIDFといった別の数値を使うこともできます。今回は最も基本的な数値である頻度で実装しました。)実装する言語とパッケージによっては、入力データをコーパスとして整形する関数があったりしますが、なければ自前で作らなければなりません。
自前で実装する際の注意点は、処理時間と重さです。記事数が増えると、処理コストは線形ではなくべき乗的(約1.6乗)に増加します。ロジック上で、計算コストを節約するコツとして、**スパース性(疎性)**の利用があります。スパース性とは、圧倒的にゼロが多く、ゼロ以外の値がポツポツあるような状態です。スパース性のもつ行列をそのままスパース行列というのですが、スパース行列を作る関数は多くの言語にあります(少なくともRとPythonには存在する)。
スパース行列を作るコードの例(R言語)を記事末に載せました。よろしければ、参照ください。
(3) トピックモデルの適用
入力データの整形が終わったら、いよいよモデルの適用です。私はRのパッケージ"lda"で実装しました。パッケージldaの利点は入力データ整形の簡易さです。パッケージ付随の関数を使えば、コード一行で分析用コーパス(文書単語行列と同等のもの)を作ることができます。デメリットは、並列処理ができないことです。パッケージには"lda"にはギブスサンプリング関数が付属しているのですが、全ての計算過程が単一スレッドで進行します。ギブスサンプリングは、文書単位でタスクを分割して並列処理をすることができます。文書数(記事数)が膨大な分析では並列処理をかけたほうが効率がいいのですが、それができません。ちなみに、並列処理用のパッケージも存在します。Pythonではplda2.0というパッケージっで実装することができます。
モデルの適用方法にもひとつ捻りを入れました。それは、階層構造での適用です。
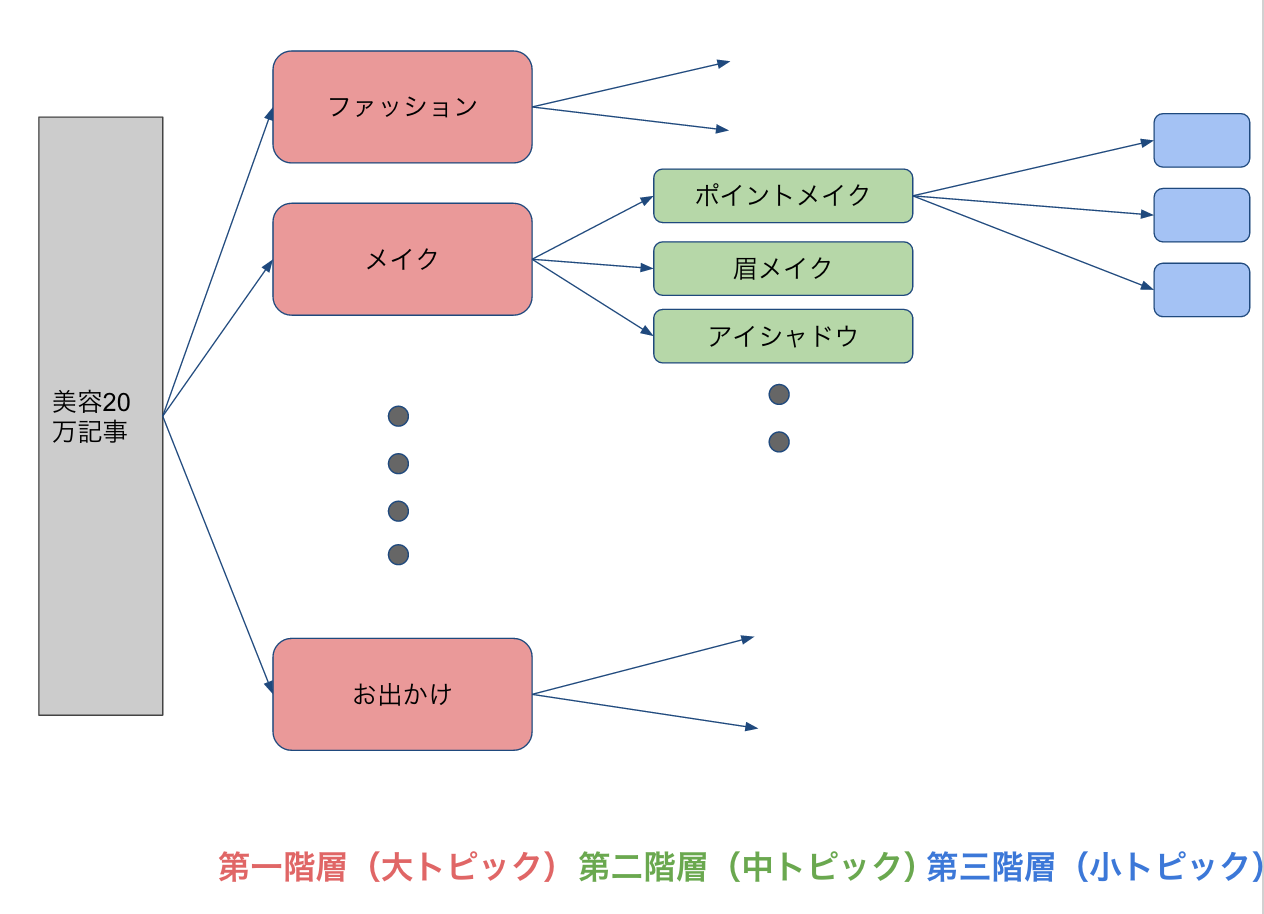
これは階層構造の模式図です。美容20万記事を一気に分類するのではなく、まず大トピックという形で大きく括ります。ついで、各大トピックそれぞれにトピックモデルを適用します。結果として、中トピックと称せる細分類したカテゴリに分類します。中トピックでは、分類記事のタイトルを取ってきて、タイトル中の単語にもとづいて、細分化します。細分化された小テーマは第三階層として分類されます。
これまでの話をまとめると、トピックモデルはギブスサンプリングで実装し、第二階層の分類まで手がけたことになります。なぜ、このような階層構造にしたかと思う方もいるでしょう。理由は、最適なトピック数に関係します。最適なトピック数から乖離すると、トピック分類の質が悪くなるのです。具体的には、同じような内容の単語集合が抽出されたり、トピックとして内容が取れないようなゴミトピックが抽出されたりします。ゴミというのは、確率モデルにおけるランダム性が強くにじみ出た集合と考えていただいて構いません。
分析結果
分析例として、第一階層の結果を挙げます。第一階層は探索的に15トピックの分類が最適であると行き着いたので、15トピックの分類を試みました。
下の表は、トピックに分類され代表単語リストです。それぞれのトピックに関連している単語が取れてきていることが分かります。

続いて、大トピックにおいて関連度の高い記事の例を見てみます。
【ヘア】
1. 「ねじるだけでOK!簡単なのにゴージャスに見えるヘアアレンジ」 <http://www.biranger.jp/archives/82655>
2. 「浴衣にぴったりなヘアアレンジ♪髪の長さ別のアレンジレシピ」 <http://w.grapps.me/beauty/20150813/>
3. 「自分に合う髪型知ってますか?顔の形で似合う髪型を教えちゃいます♡」<http://mery.jp/99736>
4. 「【デートにおすすめ♪】簡単かわいいボブアレンジ☆☆やり方解説つき」<http://mery.jp/75717>
5. 「今の季節はハーフアップが正解!カンタン可愛いほめられヘアアレンジ4選♡」<https://4meee.com/articles/view/32979>
【メイク】
1. 「老けないのはどっち?スキンケア「コットン派vs.素手派」 <http://www.biranger.jp/archives/72850>
2. 「肌が“おしゃれ”な印象に! 『M・A・C』のうるおいパウダリー」 <http://more.hpplus.jp/beauty/itbeauty/3120>
3. 「CCクリームってどれがいいの?コスパと効果で比べよう」<http://mery.jp/67595>
4. 「マジョリカマジョルカで作る、優しいピンクアイメイクレシピ」<http://favor.life/1856>
5. 「ランコムの新スキンケアシリーズ「アプソリュ」がリッチすぎる♪」<https://4meee.com/articles/view/157757>
【ダイエット】
1. 「ポッコリお腹、簡単に凹ませたいなら?」 <http://beauty-matome.net/qa/pokkori.html>
2. 「なかなか痩せれない人は代謝が原因? 必要なのは「有酸素運動」!」 <http://googirl.jp/daieltuto/1507yuusanso067/>
3. 「背中もウエストもほっそり!お尻歩きのダイエット効果がすごい」<http://josei-bigaku.jp/beauty/osiriaruki64759>
4. 「「半身浴vs.全身浴」ダイエット効果が高いのはズバリッ…徹底比較!」<http://www.biranger.jp/archives/157826>
5. 「美Bodyになろう❤︎」<http://mery.jp/78689>
このように、トピックに関連度の高い記事が分類されていることが分かります。
私は、この階層構造にもとづいて記事を分類したものを"プレーンマップ"として整理し、美容記事のKW戦略と全体の現状把握のベース資料として提供しました。
(プレーンマップの一部)
トピックモデルおよびプレーンマップ作成は更新性あるタスクです。時代は流れ、廃れるKW、新しいKWが出てくるからです。とはいえ、更新頻度はせいぜい数ヶ月に一度くらいの感覚で問題ないと思います。美容に関するトピックが頻繁に変わるわけではないからです。
さいごに
本分析の大元の目的は「世に出ている美容の話題を抽出できるのか」でした。この課題に対して、トピックモデルの実装はソリューションとして有効であると結論付けられるでしょう。
もちろん、モデルの適用をめぐって課題もあります。たとえば、形態素解析における単語の精度です。分析の最小単位である単語の認識がずれれば、モデルおよびKWそのものの有効性が落ちてしまうからです。この問題を踏まえ、現在、MeCabの辞書の強化・充実に向けた施策を打っております。例えば、辞書未登録語(=未知語)の収集ロジックなど。
モデル適用方法にも工夫できる余地が残っています。今回実装スコープに入れなかったCRF、ポリヤ分布を導入することによる分類性能の向上については、検討する価値があると考えています。
参考情報
「LDAでは何故ディリクレ分布を仮定するのか」 http://goo.gl/PqMJOr
「日本の新聞は全部書いていることが同じなのか?トピック分析で見る新聞社説」 https://goo.gl/KsRB83
(書籍)「トピックモデル―機械学習プロフェッショナルシリーズ」(岩田具治著)
コードサンプル
※きれいに整形していないので、あくまでも参考程度に御覧ください
(1) 文書単語行列の作成
# library(topicmodels)
library(foreach)
library(doParallel)
library(pbapply)
library(Matrix)
# ※※注意:keitaiso_listのデータ型※※
# リストの1成分が1記事に対応する。中身は、単語ごとに区切られたベクトルになっている。
# keitaiso_list <- tm_articles[1:3000]
registerDoParallel(detectCores())
keitaiso_list <- tmp.vec.merge[1:300]
# block <- 100
time.exec <- NULL
# sep <- ceiling(length(keitaiso_list)/block) #分割後のグループ数を計算する。
sep <- detectCores()
split_keitaiso <- split(keitaiso_list, 1:sep) #グループ分割されたリストを格納する。
# 横軸(単語軸)の単語リスト作成(ベクトルで返す)
execution.time <- system.time(
word.list <- foreach( i = 1:sep,.combine = "c",
.verbose = FALSE, .packages = "pbapply",
.export = NULL
) %dopar% {
# sink("data/log/log_word_list.txt", append=T)
# cat("i =", i, "\n")
# sink()
tmp <- unique(unlist(pblapply(split_keitaiso[[i]],function(x){
strsplit(x ,split = " ")
})))
return(tmp)
})
time.exec <- write.proctime(time.exec, "トピック単語列作成", execution.time)
word.list <- unique(word.list)
# 頻度マトリックス作成: foreachバージョン
execution.time <- system.time(
article.freq <- foreach( i = 1:sep,.combine = "c",
.verbose = FALSE, .packages = "pbapply",
.export = NULL
) %dopar% {
# sink("data/log/log_article_freq.txt", append=T)
# cat("i =", i, "\n")
# sink()
t <- pblapply(split_keitaiso[[i]], function(x){
tmp <- table(strsplit(x ,split = " "))
return(tmp)
})
return(t)
})
time.exec <- write.proctime(time.exec, "頻度マトリックス作成", execution.time)
# #0以外の要素配置のマップをつくる
# #names(article.freq) <- c(1:length(article.freq))
# # split_article <- split(article.freq, 1:sep) #グループ分割されたリストを格納する。
# execution.time <- system.time(
# sparse_index <- foreach(i = 1:length(article.freq), .combine = "rbind",
# .verbose = FALSE, .packages = "pbapply",
# .export = NULL
# ) %dopar% {
# # sink("data/log/log_article_freq.txt", append=T)
# # cat("i =", i, "\n")
# # sink()
# row <- NULL
# col <- NULL
# val <- NULL
# row <- c(row, sapply(article.freq[[i]], function(x){
# i
# }))
# for (k in 1:length(article.freq[[i]])){
# col <- c(col, which(word.list==names(article.freq[[i]][k])))
# }
# val <- c(val, sapply(article.freq[[i]], function(x){
# unname(x)
# }))
# output <- data.frame(row = row, col = col, val = val)
# return(output)
# })
# time.exec <- write.proctime(time.exec,"sparse_index作成", execution.time)
# 0以外の要素配置のマップをつくる
# 記事URLのインデックスをつくる
url_index <- names(article.freq)
names(article.freq) <- c(1:length(article.freq))
url_index <- data.frame(index=c(1:length(article.freq)), url = url_index)
url_index$url <- as.character(url_index$url)
split_article <- split(article.freq, 1:sep) #グループ分割されたリストを格納する。
execution.time <- system.time(
sparse_index <- foreach(i = 1:sep, .combine = "rbind",
.verbose = FALSE, .packages = "pbapply",
.export = NULL
) %dopar% {
# sink("data/log/log_article_freq.txt", append=T)
# cat("i =", i, "\n")
# sink()
row <- NULL
col <- NULL
val <- NULL
for (j in 1:length(split_article[[i]])){
row <- c(row, sapply(split_article[[i]][[j]], function(x){
as.numeric(names(split_article[[i]][j]))
}))
for (k in 1:length(split_article[[i]][[j]])){
col <- c(col, which(word.list==names(split_article[[i]][[j]][k])))
}
val <- c(val, sapply(split_article[[i]][[j]], function(x){
unname(x)
}))
}
output <- data.frame(row = row, col = col, val = val)
return(output)
})
time.exec <- write.proctime(time.exec,"sparse_index作成", execution.time)
startT <- proc.time()
sparse_row <- NULL
sparse_col <- NULL
sparse_val <- NULL
sparse_row <- sparse_index$row
sparse_col <- sparse_index$col
sparse_val <- sparse_index$val
endT <- proc.time()
time.exec <- write.proctime(time.exec,"sparse_index整理",endT-startT)
execution.time <- system.time(
sm <- sparseMatrix(sparse_row, sparse_col, x=sparse_val, dims = c(length(keitaiso_list),length(word.list)))
)
time.exec <- write.proctime(time.exec,"Sparse_DTM作成", execution.time)
write.table(time.exec, file = "time.exec.txt", sep = "\t", quote = FALSE, row.names = FALSE, col.names = TRUE)
write.table(word.list, file = "word.txt", sep = ",", quote = FALSE, row.names = FALSE, col.names = FALSE, fileEncoding = "utf-8")
writeMM(sm, file = "sparseMt.mtx")
write.table(url.list, file = "url.txt", sep = ",", quote = FALSE, row.names = FALSE, col.names = FALSE, fileEncoding = "utf-8")
(2) LDA実装
# ' -----------------------------------------------------------------------------
# '
# ' 美容サイトをスクレイピングし、美容分野におけるトピックモデルを構築する
# '
# ' @input 美容関連サイト記事データ(最終形は差分スクレイピングを想定)
# ' @export 美容Topicモデルオブジェクト
# '
# ' 参考:
# ' トピックモデルによる統計的潜在意味解析 2章後半:http://goo.gl/6Sq3pd
# ' RでLDAの一例:http://goo.gl/FsYGZd
# ' ggplot2エラー対処法:http://goo.gl/RJJ7gG
# '
# ' -----------------------------------------------------------------------------
# ' -----------------------------------------------------------------------------
# ' パッケージ準備
# ' -----------------------------------------------------------------------------
# パッケージインストール
# install.packages ("RMeCab", repos = "http://rmecab.jp/R")
# install.packages("lda")
# install.packages("reshape2")
# install.packages("ggplot2")
# install.packages("topicmodels")
# Rのテキストマイニングパッケージ
# install.packages("tm")
# DocumentTermMatrixをつくる前処理で使う→"slam"パッケージ
# install.packages("slam")
# library読み込み
library(lda)
library(reshape2)
library(ggplot2)
library(foreach)
library(doParallel)
library(tcltk)
library(LDAvis)
library(pbapply)
library(servr)
# ' -----------------------------------------------------------------------------
# ' 定数定義
# ' -----------------------------------------------------------------------------
# Topic分析
lda.param.rep = 25 #繰り返し数
lda.param.alpha = 0.1 #ディリクレ過程のパイパーパラメーターα
lda.param.eta = 0.1 # ディリクレ過程のハイパーパラメータη
k <- 5 # トピック数
# その他初期化
time.exec <- NULL # 実行時間格納DF
# ' -----------------------------------------------------------------------------
# ' 関数定義
# ' -----------------------------------------------------------------------------
# 実行時間記録関数
write.proctime <- function(time.exec,name.task,proctime){
tmp = data.frame(タスク = name.task
, ユーザ = format(proctime[1], digits = 3)
, システム = format(proctime[2], digits = 3)
, 経過 = format(proctime[3], digits = 3)
, 完了時刻 = Sys.time()
)
if(is.null(time.exec)){
result <- tmp
} else {
result <- rbind(time.exec, tmp)
}
rownames(result) <- NULL
return(result)
}
# ' -----------------------------------------------------------------------------
# ' 分析データ準備
# ' -----------------------------------------------------------------------------
# -------------------------------
# パース→フィルタ→形態素解析
# -------------------------------
# フィルタ
filter.vec <- c("RT\\s@[0-9a-zA-Z]*:\\s") # リツイート
filter.vec <- c(filter.vec, "@[0-9a-zA-Z]*\\s") # ユーザネーム
filter.vec <- c(filter.vec, "#[0-9a-zA-Z]*") # ハッシュタグ
filter.vec <- c(filter.vec, "(https?|ftp)(://[-_.!~*\'()a-zA-Z0-9;/?:@&=+$,%#]+)") # URL
filter.vec <- c(filter.vec, "([A-Za-z0-9][A-Za-z0-9\\-]{1,61}[A-Za-z0-9]\\.)+[A-Za-z]+") # ドメイン
filter.vec <- c(filter.vec, "\\s{2,}")
filter.vec <- c(filter.vec, "BEAUTY NEWS|美容雑誌『VOCE』|4meee|Beautyまとめ|biche|byS|CIEL|FAVOR|Googirl|Grapps|綺麗のトリセツ|Lily|Locari|M3Q|Mery|TRILL|VOCE|アンジー|キナリノ|きれいのニュース|キレイコラム|モア|女性の美学|美エージェント|美レンジャー|美肌マガジン|フォーミー|ビーチェ|キレイコラム|トリル|ANGIE|MORE|グラップス|SHERYL|シェリル|フェイバー|ロカリ|ヴォーチェ|キュレーションメディア|DAILY|レンジャー")
filter <- paste(filter.vec, collapse = "|")
filter.sym <- "[0-90-9\u007B-\u3040\u30FD-\u33FF\u0021-\u002F\u003A-\u0040\u005B-\u0060\uFE10-\uFF0F\uFF1A-\uFF20\uFF3B-\uFF40\uFF5B-\uFF65\uFFA0-\uFFFF]*" # 記号/数
# ToDo:絵文字
# その他
partOfSpeech <- c("名詞","形容詞")
# フィルタ(gsubはリストも引数に取れる。リスト内の文字列ベクトルに置換を実行する)
parse.text.desym <- gsub(filter, "", parse)
parse.text.desym <- gsub(filter.sym, "", parse.text.desym)
# データフレーム化
parse.text.df <- data.frame(text = as.factor(parse.text.desym))
row.names(parse.text.df) <- names(parse)
save(parse.text.df, file = "data/parsedf_160304.dat")
# 形態素解析_分散処理
registerDoParallel(detectCores())
parse.text.df.split <- split(parse.text.df, 1:detectCores())
tm_result <- foreach(i = parse.text.df.split
, .export = ls(envir=parent.frame())
, .packages = "RMeCab"
, .combine = c
) %dopar% {
tmp <- RMeCabDF(i, 1, 1)
result <- lapply(tmp
,function(x){
y <- x[names(x) %in% partOfSpeech]
names(y) <- NULL
return(y)
}
)
names(result) <- row.names(i)
return(result)
}
filter.wordclass <- iconv("名詞|形容詞", to = "UTF-8")
filter.stopword <- iconv("^(いろいろ|出典|おおまか|の|ん|ごっちゃ|さまざま|それぞれ|それなり|たくさん|みなさん|あのかた|あります|おります|あそこ|あたり|あちら|あっち|あなた|いくつ|おまえ|かたち|かやの|こっち|こちら|これら|さらい|しかた|しよう|すべて|ぜんぶ|そちら|そっち|ちゃん|とおり|どこか|ところ|どちら|どっか|どっち|なかば|はじめ|はるか|ひとつ|まとも|みたい|みんな|わたし|その後|向こう|貴方方|あの人|います|それで|しかし|あと|あな|あれ|いつ|いま|いや|うち|おれ|がい|かく|から|がら|きた|くせ|ここ|こと|ごと|これ|ごろ|さん|すか|ずつ|すね|そう|そこ|そで|それ|たち|たび|ため|だめ|ちゃ|てん|とき|どこ|どれ|なか|なに|など|なん|はず|ひと|ふく|ぶり|べつ|へん|ぺん|ほう|ほか|まさ|まし|まま|みつ|もと|もの|もん|やつ|よう|よそ|わけ|ハイ|彼女|下記|上記|時間|今回|前回|場合|一つ|年生|自分|ヶ所|ヵ所|カ所|箇所|ヶ月|ヵ月|カ月|箇月|名前|本当|確か|時点|全部|関係|近く|方法|我々|違い|多く|扱い|新た|半ば|結局|様々|以前|以後|以降|未満|以上|以下|幾つ|毎日|自体|何人|手段|同じ|感じ|この|その|あの|だれ|貴方|私達|です|まで|より|どの|4meee|Beautyまとめ|biche|byS|CIEL|FAVOR|Googirl|Grapps|綺麗のトリセツ|Lily|Locari|M3Q|Mery|TRILL|VOCE|アンジー|キナリノ|きれいのニュース|キレイコラム|モア|女性の美学|美エージェント|美レンジャー|美肌マガジン|フォーミー|ビーチェ|キレイコラム|トリル|ANGIE|MORE|グラップス|SHERYL|シェリル|フェイバー|ロカリ|ヴォーチェ|ロ|カリ|Q|BY|キュレーションメディア|DAILY|レンジャー|の|こと|さ|よう|ん|ない|そう|もの|これ|一|方|こちら|さん|ため|みたい|ところ|っぽい|それ|ここ|どこ|g|ml|cc|あと|これから|どれ)$|^[上中下字年月日時分秒週火水木金土国都道府県市区町村各第方何的度文者性体人他今部課係外類達気室誰用界会首男女別話私屋店家場等見際観段略例系論形間地員線点書品力法感作元手数彼子内楽喜怒哀輪頃化境俺奴高校婦伸紀誌レ行列事士台集様所歴器名情連毎式簿回匹個席束歳通面円玉枚前後左右次先一二三四五六七八九十百千万億兆はがのにをでえもとし]$"
, to = "UTF-8")
stopw <- read.csv("STOP.csv",header = F, sep = "")
stopw$V1 <- as.character(stopw$V1)
filter.read <- read.table(file = "filter1.csv", header = F, sep = ",", quote = "", fileEncoding = "utf-8")
filter.read$V1 <- as.character(filter.read$V1)
filter.read$V3 <- as.character(filter.read$V3)
stopw <- c(stopw$V1, filter.read[filter.read$V3 == "x", c(1)])
filter.read <- read.table(file = "filter2.csv", header = F, sep = ",", quote = "", fileEncoding = "utf-8")
filter.read$V1 <- as.character(filter.read$V1)
stopw <- c(stopw, filter.read$V1)
filter.stopword2 <- paste("^(",paste(stopw, sep = "", collapse = "|"),")$",sep = "")
tm.filtered <- pblapply(tm_result
,function(x
,filter.wc = filter.wordclass
,filter.stw = filter.stopword
,filter.stw2 = filter.stopword2
)
{
z <- x[!(grepl(filter.stw, x))] # [15/12/21]filter.stopwordでフィルタ
z <- z[!(grepl(filter.stw2, z))]
z <- z[grep("[^[:punct:]]+", z)] # [15/12/21]半角記号を排除
z <- z[!(grepl("^.*[0-90-9\u007B-\u3040\u30FD-\u33FF\u0021-\u002F\u003A-\u0040\u005B-\u0060\uFE10-\uFF0F\uFF1A-\uFF20\uFF3B-\uFF40\uFF5B-\uFF65\uFFA0-\uFFFF]+.*$", z))] # [15/12/21]特殊文字を排除
#z <- z[grep("[^0-9]", z)] # 数字を排除
result <- paste(z
, sep = ""
, collapse = " "
) # ベクトルから文字列へ変換
return(result)
}
)
# ' -----------------------------------------------------------------------------
# ' コーパス作成処理
# ' -----------------------------------------------------------------------------
#処理準備
startT <- proc.time()
# コーパス作成
sentence.lex <- lexicalize(tm.filtered, lower = TRUE)
# save(sentence.lex, file = "tmp/lex.dat")
# 後処理
endT <- proc.time()
time.exec <- write.proctime(time.exec,"ldaデータ前処理",endT-startT) # <実行時間記録>
# ' -----------------------------------------------------------------------------
# ' Topic分析
# ' -----------------------------------------------------------------------------
# 複数のトピック数
sequ <- seq(5, 15, 5)
startT <- proc.time()
# Topic分析実行
# result <- lda.collapsed.gibbs.sampler(sentence.lex$documents
# , K = 15
# , sentence.lex$vocab
# , lda.param.rep
# , lda.param.alpha
# , lda.param.eta
# , compute.log.likelihood = TRUE
# )
# save(result, file = "data/topic_first.dat")
# endT <- proc.time()
# time.exec <- write.proctime(time.exec,"lda分析",endT-startT) # <実行時間記録>
# save(time.exec, file = "result/execTime.dat")
result.many <- foreach(i=k
, .export = ls(envir=parent.frame())
, .packages = "lda"
) %dopar% {
tmp <- lda.collapsed.gibbs.sampler(sentence.lex$documents
, K = i
, sentence.lex$vocab
, lda.param.rep
, lda.param.alpha
, lda.param.eta
, compute.log.likelihood = TRUE
)
save(tmp, file = paste("data/topic",i,".dat", sep=""))
return(tmp)
}
endT <- proc.time()
time.exec <- write.proctime(time.exec,"lda分析",endT-startT) # <実行時間記録>
print(time.exec)