講演: 里洋平氏(DATUM STUDIO)
※DATUM STAUIOの取り組み
- インターネット情報を活用し、人工知能を実装
- Azureなどプラットフォーム活用
- PowerBI
- Tableau
Part I センサーデータを用いた異常検知
異常検知とは
いつもと違う(異常な振る舞い)データを見つけ出すこと
セキュリティでの例
- ログ → 署名ベース → 既知ウィルスの発見
- データマイニング→ インシデント知識の発見
システム分野での例
- 高い異常スコア→異常なログを見出す(障害の原因対策に用いる)
マーケティング分野での例
- 口コミや消費行動からいつもと違ったキーワードや商品を検知する
- プロモーションや新規商品の開発に活用する
通常の統計分析との差分
- 通常の統計分析 → データの真ん中を捉える(ある程度サンプリングされたデータでも可能)
- 異常検知 → 真ん中から外れたデータを捉える(全件データを用いる必要がある)
通常の統計分析の概観
要約する(記述統計学)
| 使途 | 統計用語 |
|---|---|
| 真ん中を知る | 平均、中央値 |
| 構成を知る | 比率 |
| ばらつきを知る | 分散、標準偏差 |
1部分のデータから全体を断言する(推測統計学)
| 使途 | 統計用語 |
|---|---|
| 断言が間違える確率を知る | 検定 |
| データ同士の関係の強さを知る | 回帰分析 |
異常検知概観
- 「与えられたデータを用いて、他のデータから離れたデータを見つける」
- 基本は教師なし学習
| 機能 | 入力対象 | モデル | 検出対象 | 応用 |
|---|---|---|---|---|
| 外れ値検出 | 多次元ベクトル | 独立モデル | 外れ値 | 不正検出・故障検知 |
| 変化点検出 | 時系列ベクトル | 時系列モデル | 急激な変化 | 攻撃検出・ワーム検出 |
| 異常状態検出 | セッション時系列 | 状態モデル | 異常セッション | なりすまし検出・障害予兆検出 |
外れ値検出
- あるデータ点が全体の分布からどれくらい離れているか
- 例:正規分布における3σなど
※ 正規分布に従わない、複数変数の場合
- One-class SVM: 割合$1-p$のサンプルを最小の体積に押し込める境界面を探す。(カーネル使えるので、複雑な境界面も分けられる)
- Local Outlier Factor: データ点から$k$番目に近い点までの距離を求め、スコアとする(外れている点は近傍に点がないため、スコアが大きくなる)
- LOFの長所:小クラスタリング(コミュニティ)が複数あっても適用しやすい
- 予測モデルを用いた外れ値検出:予測モデルの残差の分布から異常度スコアを算出
変化点検出
- ノイズやピークでなく、急激に変化した点に注目する
- プロセス: 時系列推移に関するモデリング→スコアリング→スコアの平滑化→スコアに対するモデリング→スコアリング
異常状態検出
- 上と違い、複数の時系列に目を向ける
- 複数の時系列データの相関関係をモデリングし、関係性が通常と異なるセッションを見つける
- プロセス: 正常データ→時系列データ同士の相関関係のモデル化→未知データとの突き合わせ→異常判定
- GGM(グラフィカル・ガウジアン・モデル):別称グラフィカルLasso。データから疎なグラフ構造を抽出する(ノイズによる見せかけの相関を除去した本質的な相関関係)。Lassoの名前の由来はLasso回帰から来ている。最適な疎構造を導出するための目的関数がLasso回帰の解法と同じになるため。
異常検知の活用事例
課題感
- 人手で異常のルールを作成して検知しているが、全てのセンサーをカバーすることができない
- 全てのセンサーデータに対して、異常検知のアルゴリズムを適用して、自動で検知できる仕組みを作りたい
モデリング戦略
- 各センサーごとに変化点検出モデルで検知
- 全てのセンサーに対して、異常状態検出
変化点検出モデルの問題
- 周期性のないものに対して無力(時系列モデルが構築できない)
- センサー間の依存関係を考慮した異常を捉えられない
GGMによる検知
- センサー同士の依存関係(相関関係)をモデル化した
- 依存関係のグラフモデル化(正常時と異常時にセンサー間の依存関係に変化が出ている)
- 「異常さ」のスコアリング
- 異常スコアの計算だけでは、どのレコードが異常かは判定できない
- そこで、One-class SVMとLOFを併用
- 異常度スコアの平均値の推移をみる
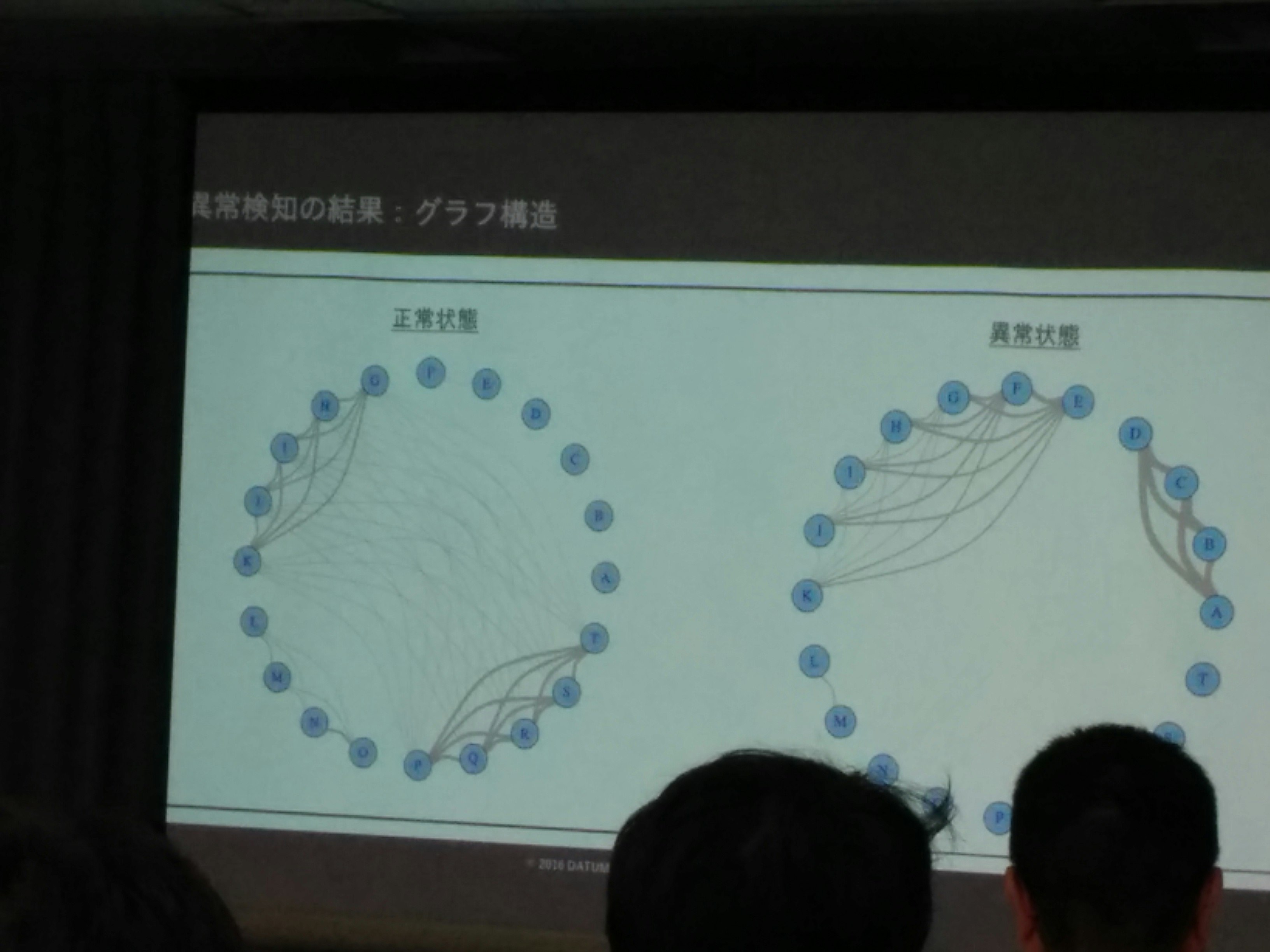
(写真: GGMにおける正常状態と異常状態でのグラフ構造の変化。※著作権等問題があれば、削除します。)
その他知見
- データ整形:相関の探索に時間がかかる(ライブラリは存在している)
- ロジックの一部はオリジナルで書いた(Rで書いた)
- その他モデル化において、閾値などの設定は一律に決めることはできず、クライアントの事例を深く考察して決める必要がある!
Part II 機械学習を用いた価格予測モデル
予測モデルとは
- 時系列モデルを用いる(過去のデータから未来の値を予測する)
- 機械学習を用いた予測(いくつかの説明変数から被説明変数を予測する)
時系列
- 時系列データ分解 = トレンド + 周期変動 +ノイズ → 合成 → 予測
- ARモデル(Auto Regression)
- MAモデル (Moving Average): 過去の予測誤差の線形結合を予測するモデル
- ARIMA(自己回帰和分移動平均モデル) : データの差を取ってからARMAモデルを適用する
- SARIMA: ARIMAに季節変動などの周期変動を加味したモデル
機械学習
- 回帰モデルによる予測がスタートライン
- 単回帰→重回帰
- 予測/実測散布図→予測結果の確認
- 過学習の問題(訓練データとテストデータに分ける)
- ハイパーパラメータの探索が最適モデリングの基本戦略
事例
課題
- 人の感覚でやっている、原材料の1年間の価格予測を過去のデータを元に予測したい
- 所持データ:過去30年間の価格、特徴量を考慮したデータ群(5年)
モデリング戦略
- 時系列使う→過去30年データ全て使えるが、時系列的要因以外を組み込めない
- 機械学習使う→因果関係があるであろう大量の説明変数を使うことができるが、5年分のデータしか使えない
…両方試してみた!
時系列
過去30年データ→SARIMAモデル→図示
下がる傾向は捉えられるが、予測精度はよくない→使えない
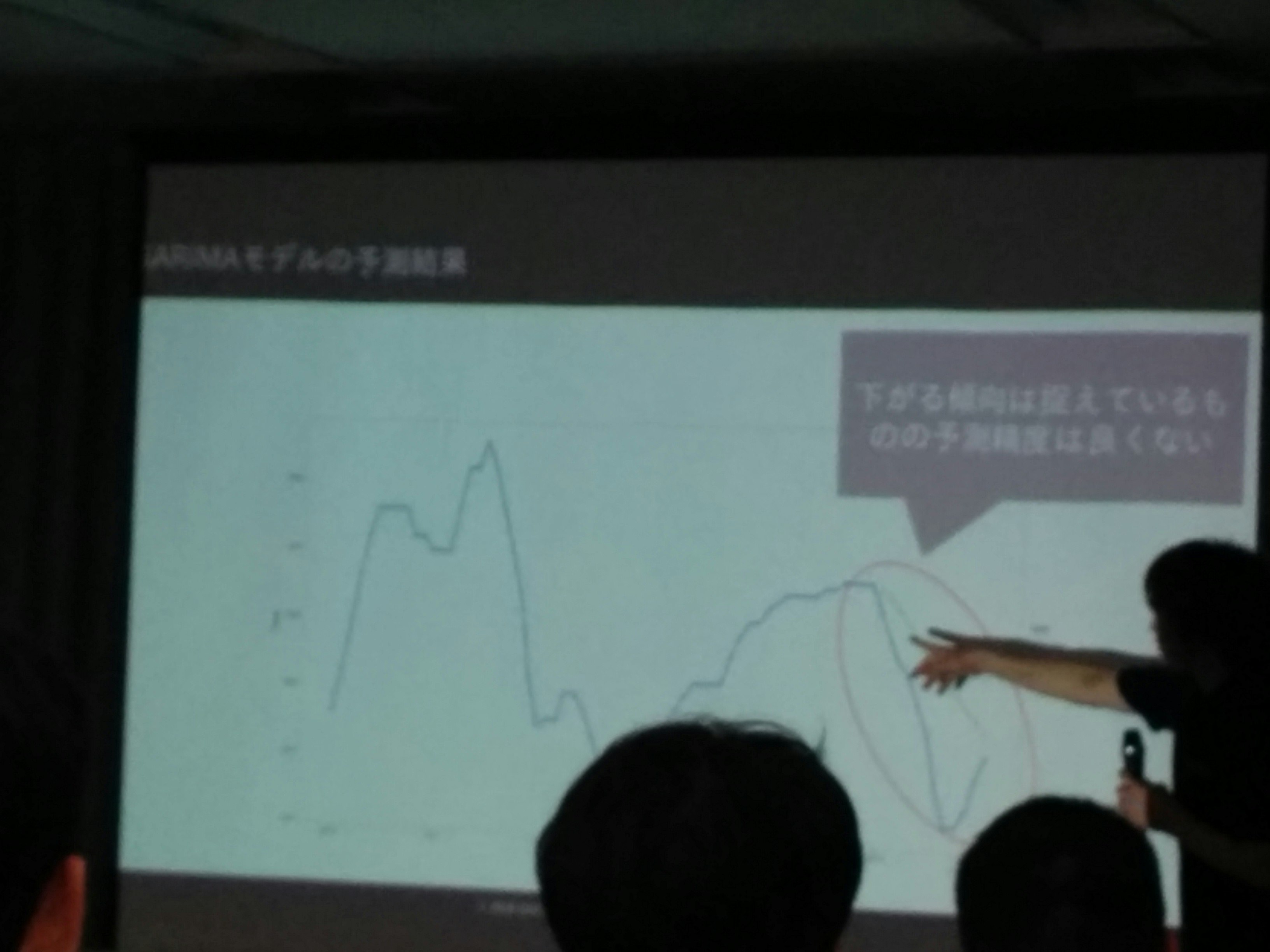
(注:青実線が実データ、点線が予測データ)
機械学習
- 直近6ヶ月の説明変数→Nヶ月後価格を予測するモデル
- 合成変数作成→変数選択→予測モデル構築→1ヶ月後価格
- この流れを12個、12ヶ月分まで作った
- 統合モデルを使った
- 複数の予測モデルで一時的な予測→その予測値を用いて、総合的な予測をする
- Netflixの事例での成功
- Rでは約300の予測モデルある(lm, gllm, knn, XgbTree)→各モデルから一時的な予測値。それらを統合して、予測させる
- 統合には「ランダムフォレスト」を用いる
- 決定木モデルの比率配分がこの例におけるハイパーパラメータになる
- 集団学習:異なる重み、異なるモデルを組み合わせて行う(※組み合わせ方法→回帰:平均値、分類:多数決)
結果: 6ヶ月先までは高精度で予測できた
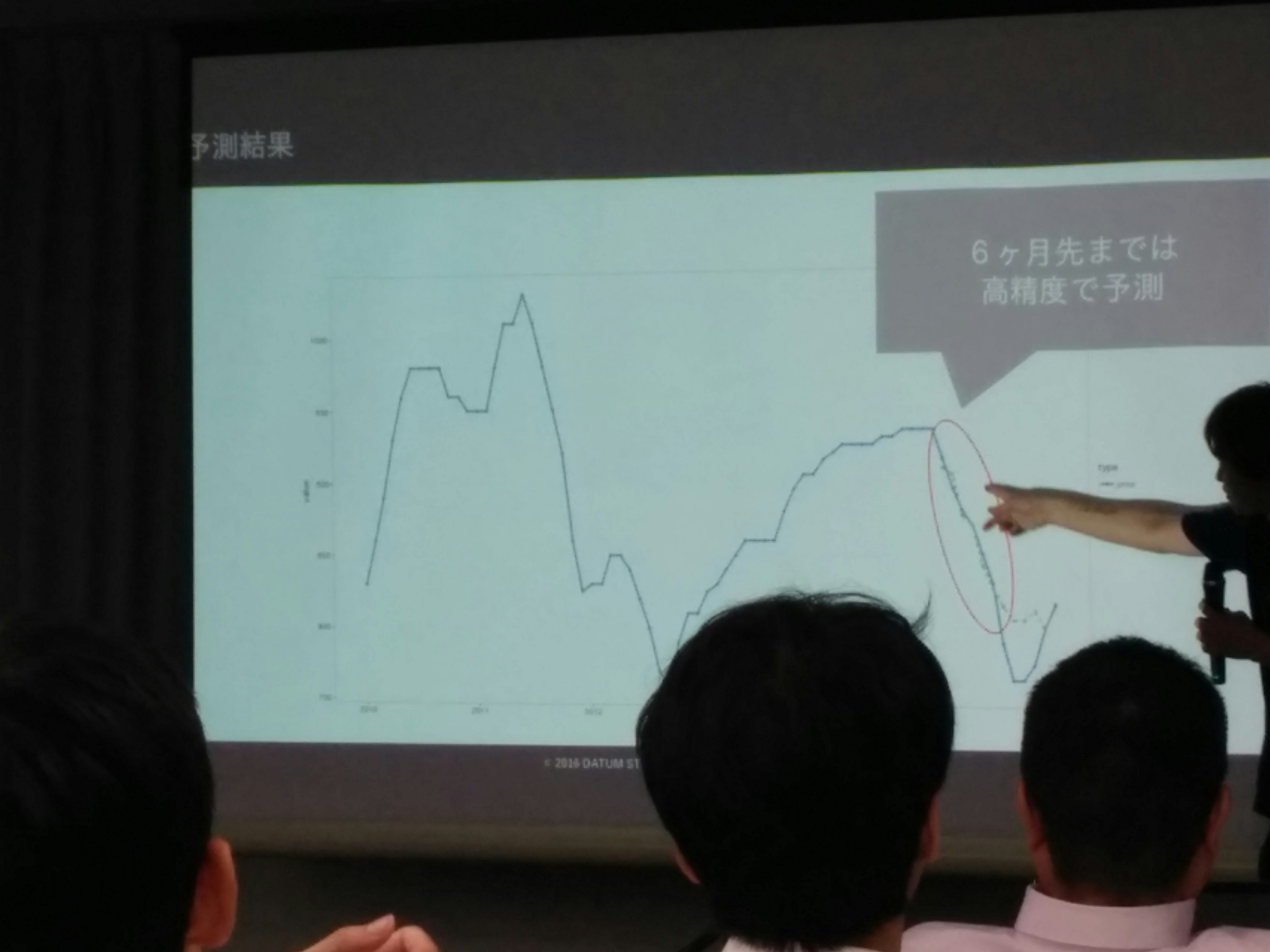
今後の方針
- 説明変数の拡充:5年前よりも前のデータ、因果関係のありそうな変数もってくる
- 説明変数を絞って、データの期間を伸ばす(長期間ある説明変数のみ使ってモデル化させる)
- 顧客への説得:精度の良し悪しで説得、たまに顧客からモデルの指定をされることがある。その際は、顧客の意向を優先的に汲むことがある。