原文
適合MCMCを用いたDBMの学習 (Learning Deep Boltzmann Machines using Adaptive MCMC)
Ruslan Salakhutdinov (2010)
1. 要約/背景
- DBMのような高次元構造の学習装置では、学習そのものが不安定で困難を伴う。ギブスサンプリングにしても、局所解に嵌ったり、次のstateへの遷移が不安定になるのもしばしばである。
- Coupled Adaptive Simulated Temperingアルゴリズムは、上記の不安定性の改善に寄与する。ギブスサンプリングに比べて、計算スピードは遅くなるが、アウトプットは安定する。
2. 骨子の理論
(1) データの混合(mixing)と、学習速度の関係
Markov連鎖によるデータサンプリングを続けると、サンプリングデータにいち早く適合するように、重みの更新と変化が激しくなる。これは、実質的な学習係数の増加につながり、学習の精度が悪くなる。
継続的CD(PCD)アルゴリズムでは、重みの更新にfast weights(高速ウェイト)を用いる。
これは、サンプリングデータの停滞=データの悪い混合を防止し、学習精度の担保に貢献する。
(2) Wang-Landau(WL)アルゴリズム
適合MCMCの一種である。
マルコフ連鎖による重みの更新において、分配関数の扱いが困難になる。
このアルゴリズムは、重みに更新に対応する遷移確率の不変分布が次のような比例関係にあることに、注目する。
p({\bf x}; \theta, {\bf g}^t) \varpropto \sum_{k=1}^{K}\frac{p^*({\bf x}; \theta)}{g_k^t} I({\bf x} \in \chi_k)
この時、有向関数$I$と、重み適合因子$\gamma$を使って、次のような更新式を導ける。
g_k^{t+1} = g_k^{t}(1+\gamma_t I ({\bf x}^{t+1}\in\chi_k))
WLアルゴリズムによる重み更新の挙動は、Fast PCDの重み更新と呼応するものがある。
(3) Simulated Tempering
サンプリングの確率分布の考え方の一つで、サンプルベクトルに、「逆温度(inverse temperatures)」という概念を付加する。エネルギー関数$E(x)$に対して、ターゲット分布は次のように表現される。
p({\bf x},k) \varpropto w_k \exp(-\beta_k E({\bf x})) \\
p({\bf x}|k) = \frac{1}{Z_k} \exp(-\beta_k E({\bf x}))
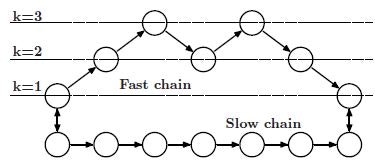
(1) ~ (3)を総合して、Coupled Adaptive Simulated Temperingアルゴリズムは形成される。サンプリングの模式図を下に示す。
計算コストはかかるが、アウトプットの精度向上が期待できる。
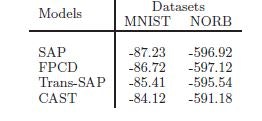
3. モデル適用例
例によって、MNISTとNORBによる画像認識のテスト結果を示す。表は、対数尤度を分解した時の下界という値を示す。
数値は、ゼロに近いほど良好であるが、CASTがContrastive DivergenceやStochastic Approximation Procedureといった手法よりよい結果を出した。