原文
ベクトル空間における言語特徴量の効率的推定(Efficient Estimation of Word Representations in Vector Space)
Tomas Mikolov (2013)
1. 要約
- 「単語ベクトル(word vectors)」の効率的な学習方法の提示。Word2Vecというモデルに接続する考え方。
- 規模にして10億語超、語彙では100万語超の処理を試みる。
- 比較対象: 過去の言語処理規模では、1000万語レベルの処理が限界だった。
学習テクニックとして広く使われてきた手法は、次の3つである。
①NNLM(Neural Network Language Model)
順伝播型NNを用いて、単語の特徴量を抽出する。教師データには、品詞タグ付けされたコーパスを用いる。
②LSA(Latent Semantic Analysis)
精度はNNに劣る。教師なし学習で分類する。単語文書行列を特異値分解して特徴量を抽出する。
③LDA(Latent Dirichlet Allocation)
②と同様教師なし学習モデル。LSAと異なり、単語の分布に確率分布を仮定する(ディリクレ分布およびカテゴリ分布)。文脈が類似している単語や記事を抽出できるが、計算コストが高い。
2. 骨子の理論
提案手法のコンセプトは、計算の複雑さの排除である。
NNLMのもつ精度を多少下げても、計算スピードの向上を狙った。
総称は、対数-線形識別器モデルという。
ポイントは、隠れ層の非線形ノードの扱いにある。
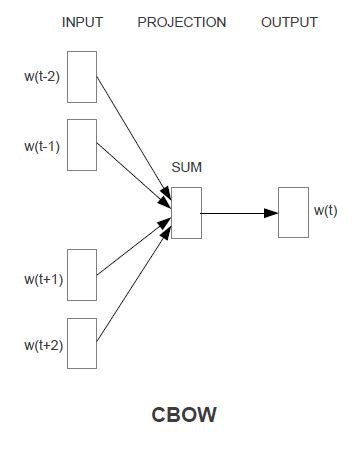
①Countinuous Bag-of-Wordsモデル(CBOW)
非線形の隠れ層を排除した。
投射(projection, 入力)層をすべてのデータ間で共有した。
言葉の由来は、投射層の共有により、語順の影響が無視され、言葉のまとまり(Bag)として、データ群を眺めることになるから。
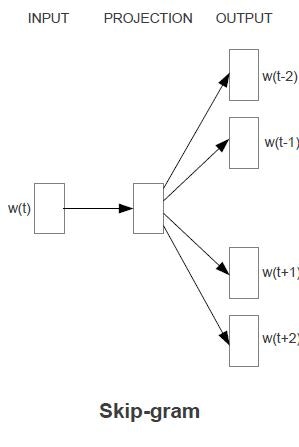
②Skip-gramモデル
現前の単語データを前後の文脈ではなく、前後から離れた文中の言葉の分類に用いる。
N-gramはN文字を指示するが、接頭辞skip-との組合せから、特徴抽出の言葉のポジションが飛び飛びになっていると想像できる。
CBOWやSkip-gramは深層学習の言語モデルの基礎にもなっている。
去年出版された深層学習の総論の教科書にも説明が載っているので、参照されたい;
http://goo.gl/JTMUIv
3. モデル適用例
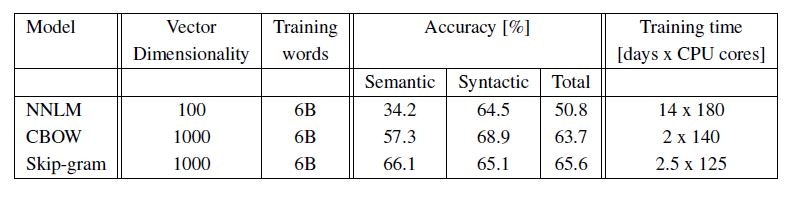
Google起因のDistBeliefというアルゴリズムを使って計算した。
NNLMに比べて、提案手法の計算時間が約1/7に減っているのが分かる。
NNの次元数は、1000を超える。
Skip-gramが高いパフォーマンスを示した。