原文
(ほぼ)イチからの自然言語処理(Natural Language Processing (almost) from Scratch)
Ronan Collobert (2011)
1. 要約
- 自然言語処理の分野に、DNNを適用した論文である。
2. 背景
従来の自然言語処理の代表例に、POS(Part-Of-Speech tagging;品詞タグ付け), CHUNK(chunking), NER(Named Entity Recognition), SRL(Semantic Role Labeling;単語意味解析)がある。
アルゴリズムの複雑さは違えど、根本的なプロセスは4つともに同じである。
すなわち、単語をタグ付けし、入力データに変形する。
従来は、データ化した単語に対して、人の手によって特徴量を設定して、SVMなどの手法で、語順を学習させてきた。
そのため、ここでも、特徴量を自ずから抽出できるかという文脈が発生し、DNNの適用が考案された。
3. 骨子の理論
使っているNNの理論に、新しいものはない。
ポイントは、NNに適用するにあたっての、言語のデータ整形である。
一つの単語を入力ベクトルと捉える。単語の性質の数をdとし、各単語について、それぞれの性質に応じた数値に変換し、d次元ベクトルを作る。
文章であれば、単語分だけベクトルをつくり、これを入力ベクトルとする。
ベクトルの次元に応じて、重みを用意する。これは一般的なNNと同じ。
畳み込みをして特徴抽出をするので、CNNに近いプロセスになる。(paddingはワードで行う。)
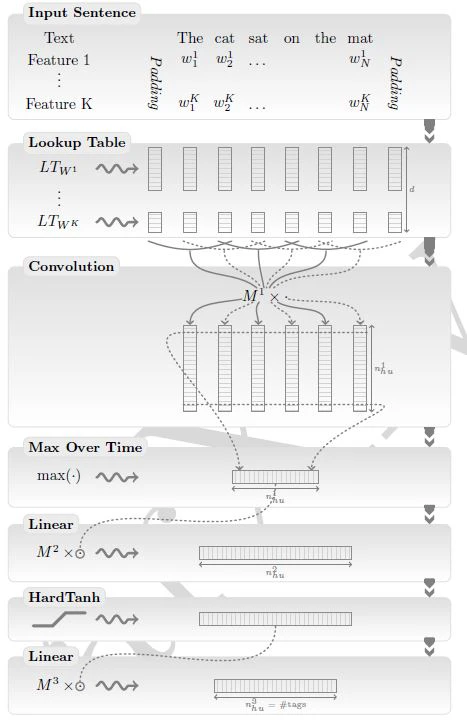
活性化関数は、HardTanhという関数を用いる(tanhがあるが、双曲線関数の形式ではない)
\begin{eqnarray}
HardTanh(x)=\left\{ \begin{array}{ll}
-1 & (x \lt -1) \\
x & (-1 \leqq x \leqq 1) \\
1 & (x > 1) \\
\end{array} \right.
\end{eqnarray}
パターン認識は、ソフトマックス法からの対数尤度を使った推定になる。アウトプットの創出が、グラフ転送ネットワークの概念に対応している。
\log p([y]_1^T|[x]_1^T, \tilde{\theta}) = s([x]_1^T, [y]_1^T ,\tilde{\theta}) - logadd_{\forall[j]_1^T}s([x]_1^T, [j]_1^T ,\tilde{\theta})
単語の数値化は、場合によっては正規化できない場合がある。このとき、データの分布が条件付き確率場(Conditional Random Fields)に従う点に注意する。
4. モデル適用例
SENNA(Semantic/syntactic Extraction using a Neural Network Architecture)という手法は、上記のNNの理論を組み込んで形成したアルゴリズムである。
SENNAと従来の方法(Benchmark)の性能比較した結果を下の表に示す。
両者とも、精度的には拮抗しており、特徴量を自ら抽出できるSENNAの方が有能である。
