watsonx.data Milvusを払い出してみる
IBM Cloudのログイン後、カタログから「watsonx.data」のインスタンスを立ち上げます。
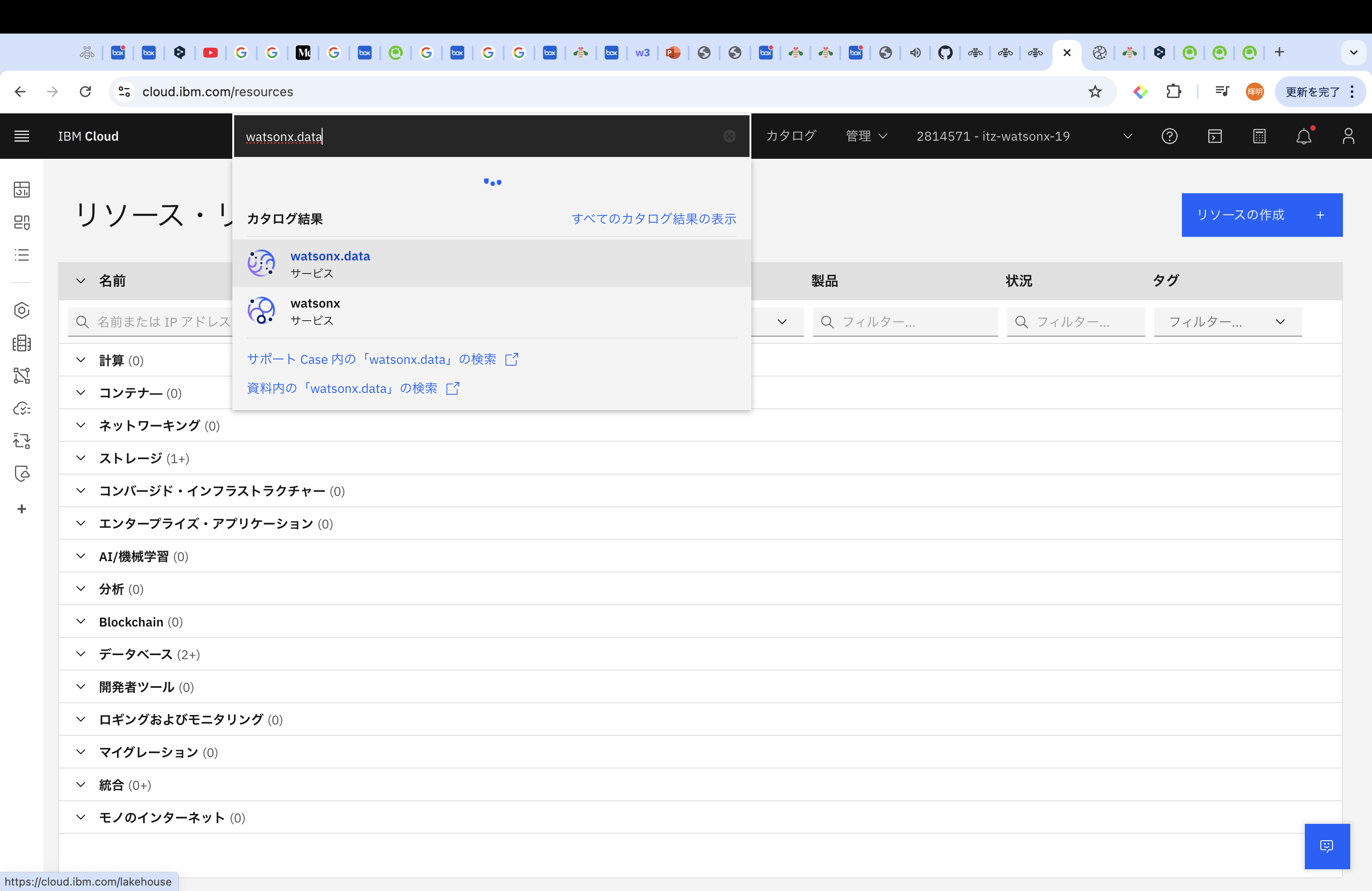
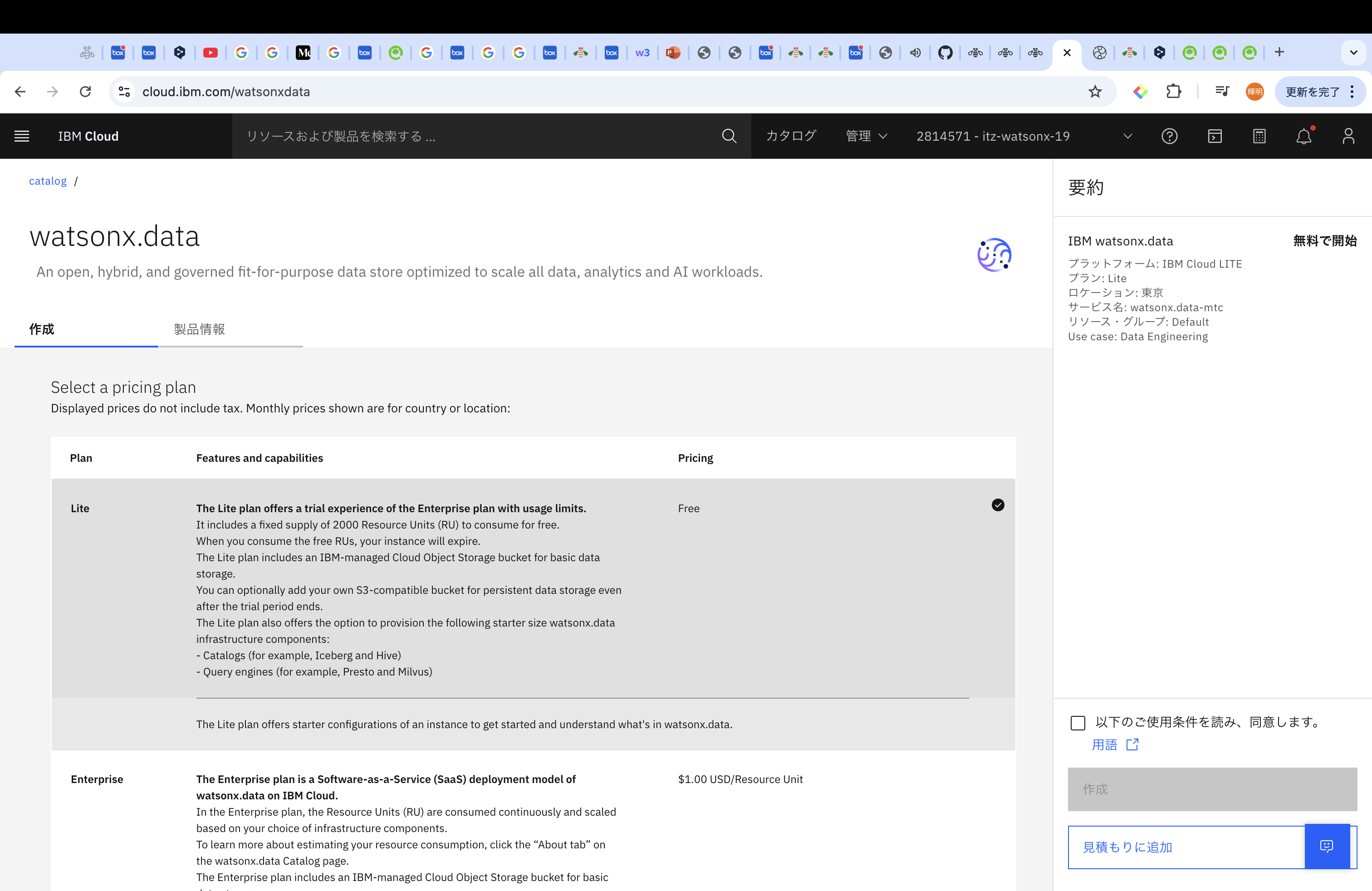
諸々の情報をいれて作成をしてください。
作成が完了すると、左側のハンバーガー・メニューの「リソース・リスト」を選択し、その後「データベース」から作成したwatsonx.dataがアクティブになっていることが確認できます。
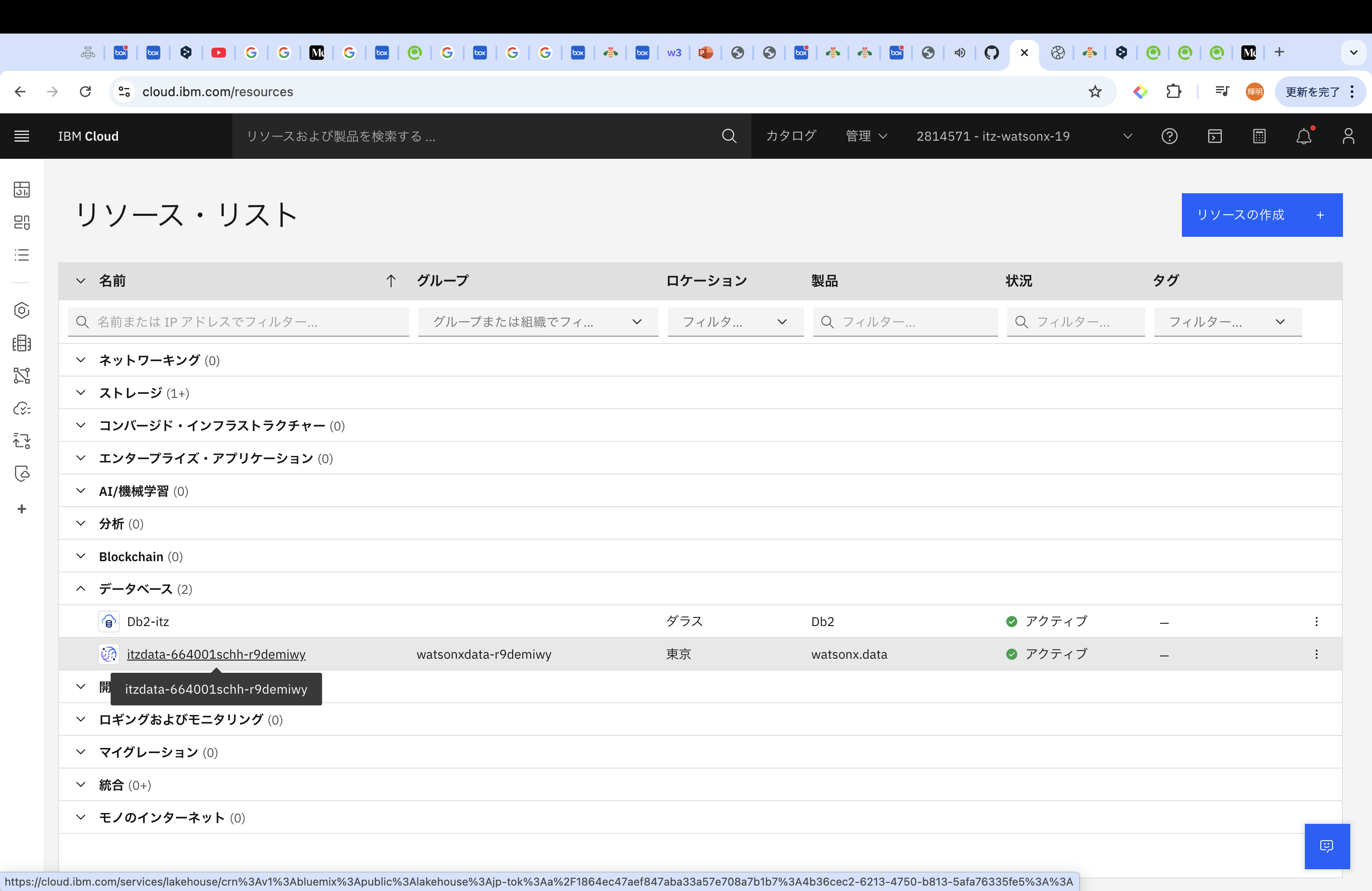
Webコンソールを開いて、watsonx.dataの初期設定をしていきます。
さて、諸々の設定をしていきます。
watsonx.data(レイクハウス)は、エンジンとストレージが疎結合をしているのが特徴です。そこで、まずはストレージを設定していきます。ストレージは新しいINSIGHT管理バケットでも、既存で持っているストレージ、どちらでも設定ができます。
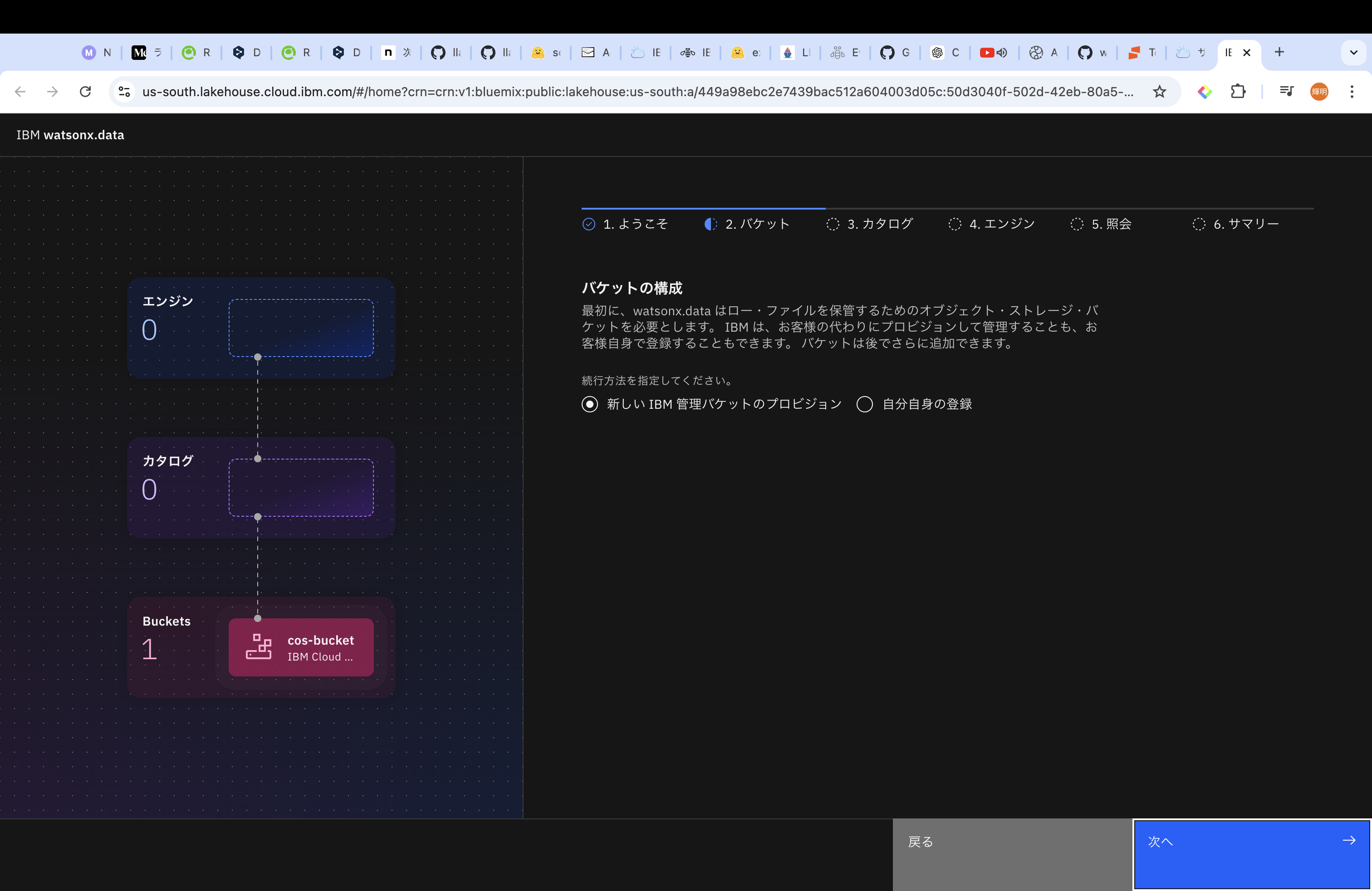
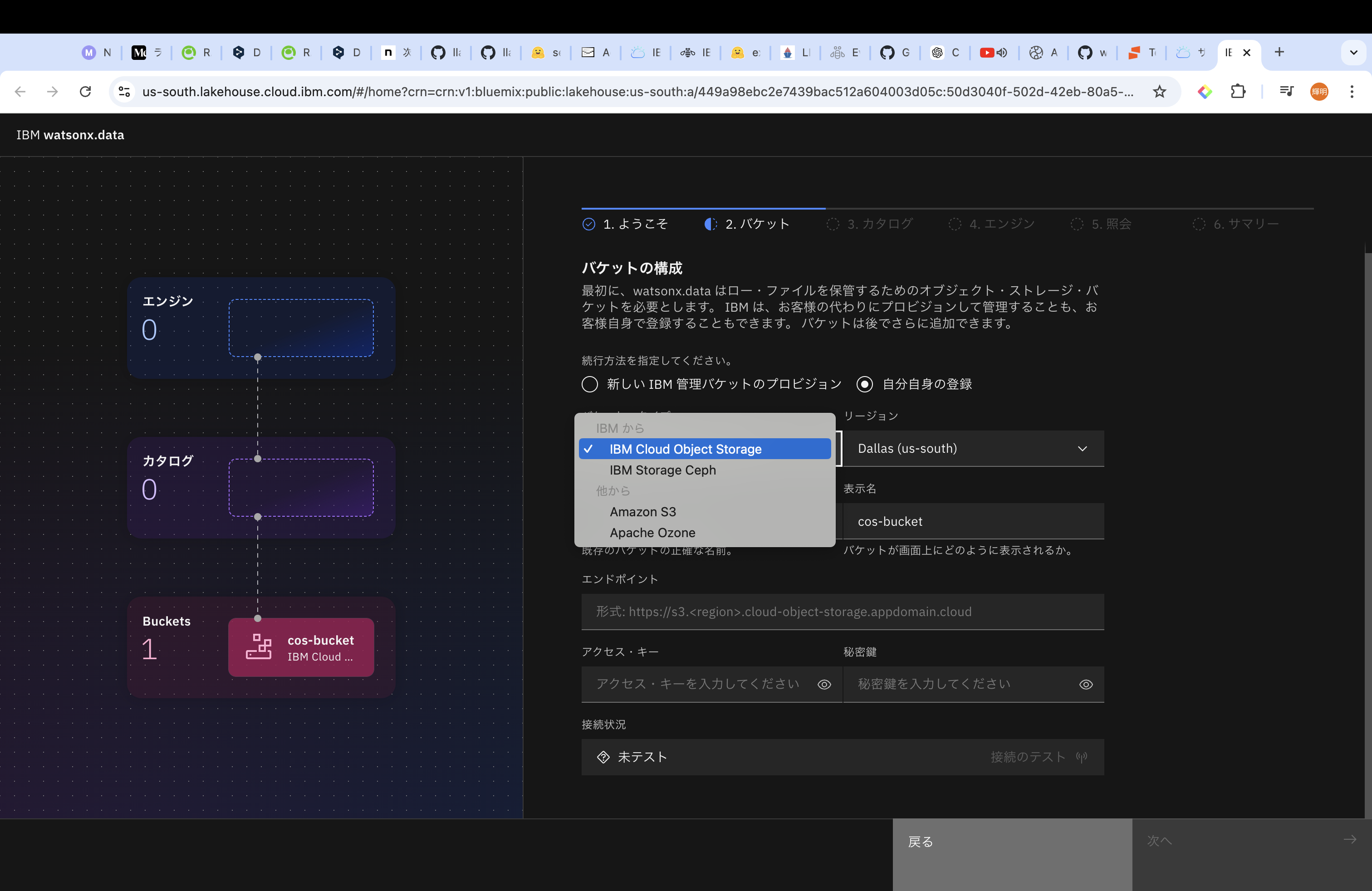
既存の場合、IBM Cloud Object Storage、IBM Storage Ceph、Amazon S3、Apache Ozoneなどから選択することができます。
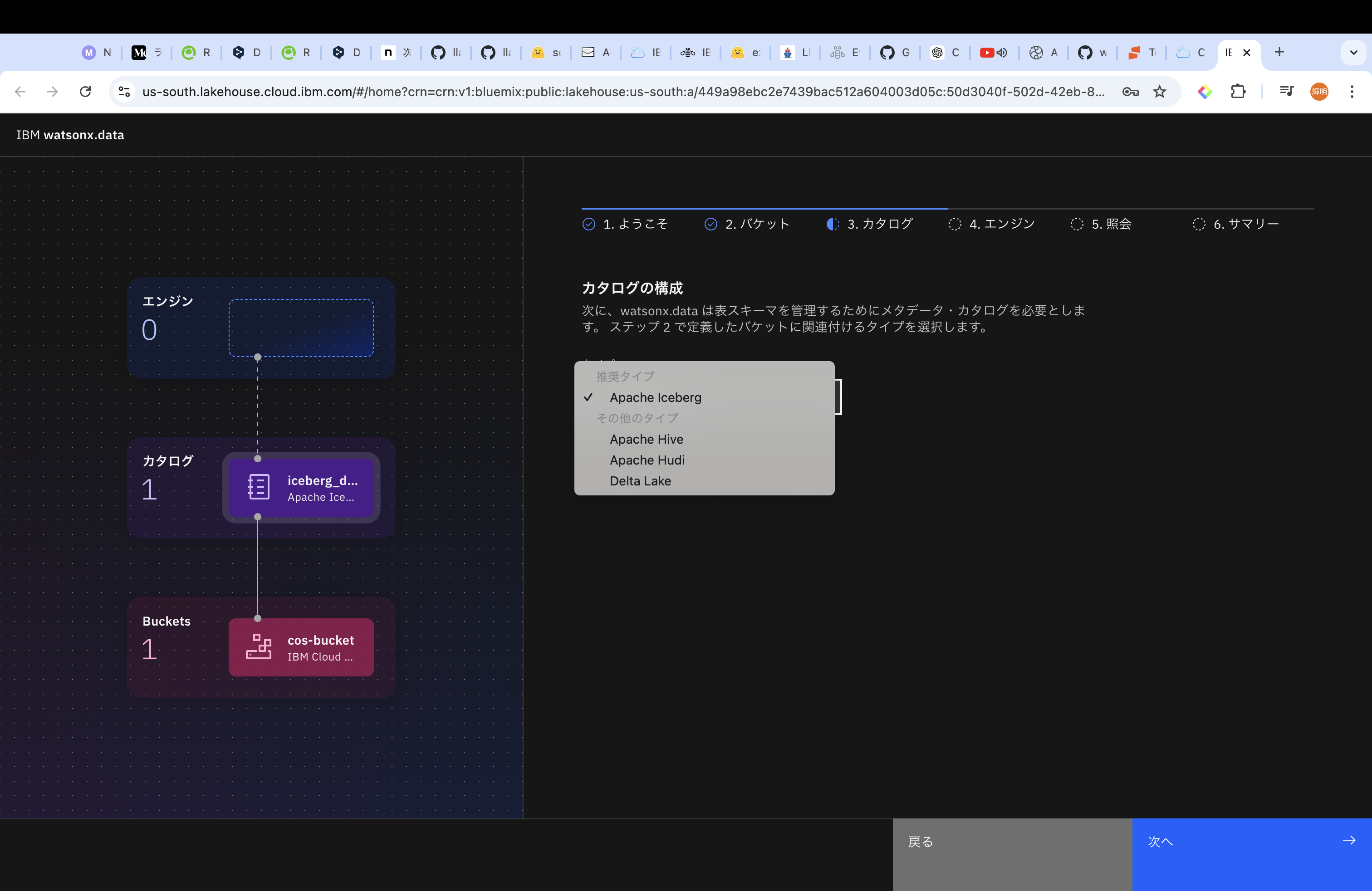
その後、テーブルフォーマットを設定します。ストレージとエンジンが疎結合するためには、どこにどんなデータがあるのか、テクニカルメタを管理するためのメタストアが必要です。そのメタストアに保存するためのテーブルフォーマットを指定します。Icebergは過去時点のスナップショットをとっておいて、当時のテーブルの状況でクエリを実行できるなどの特徴を持っています。細かい説明は省略します。
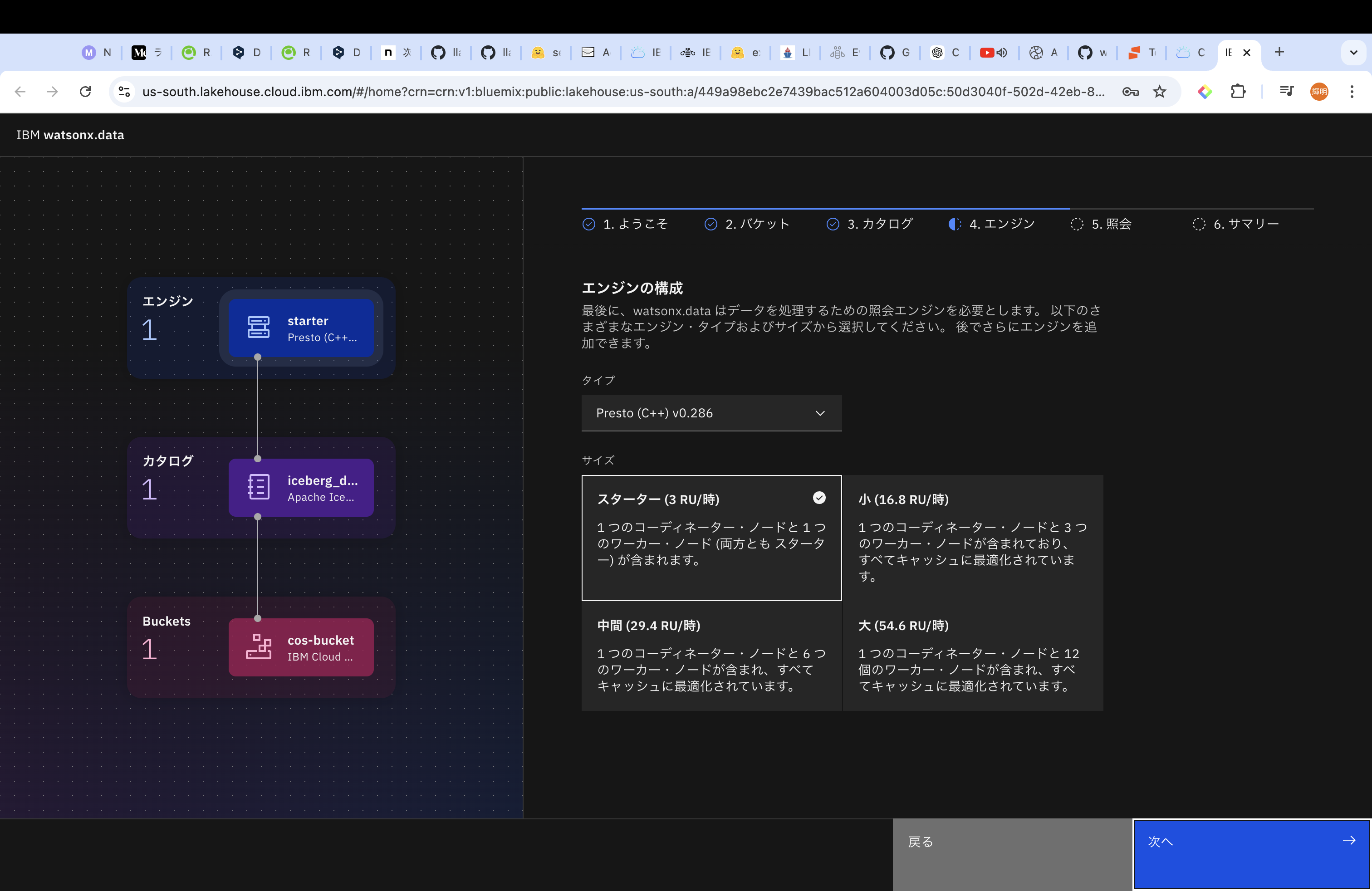
エンジンを選択します。2024年12月時点では、JavaベースのPrestoとC++ベースのPrestoを選択することができます。そして、最後に作成をします。
作成後無事ログインできたことが確認できます。
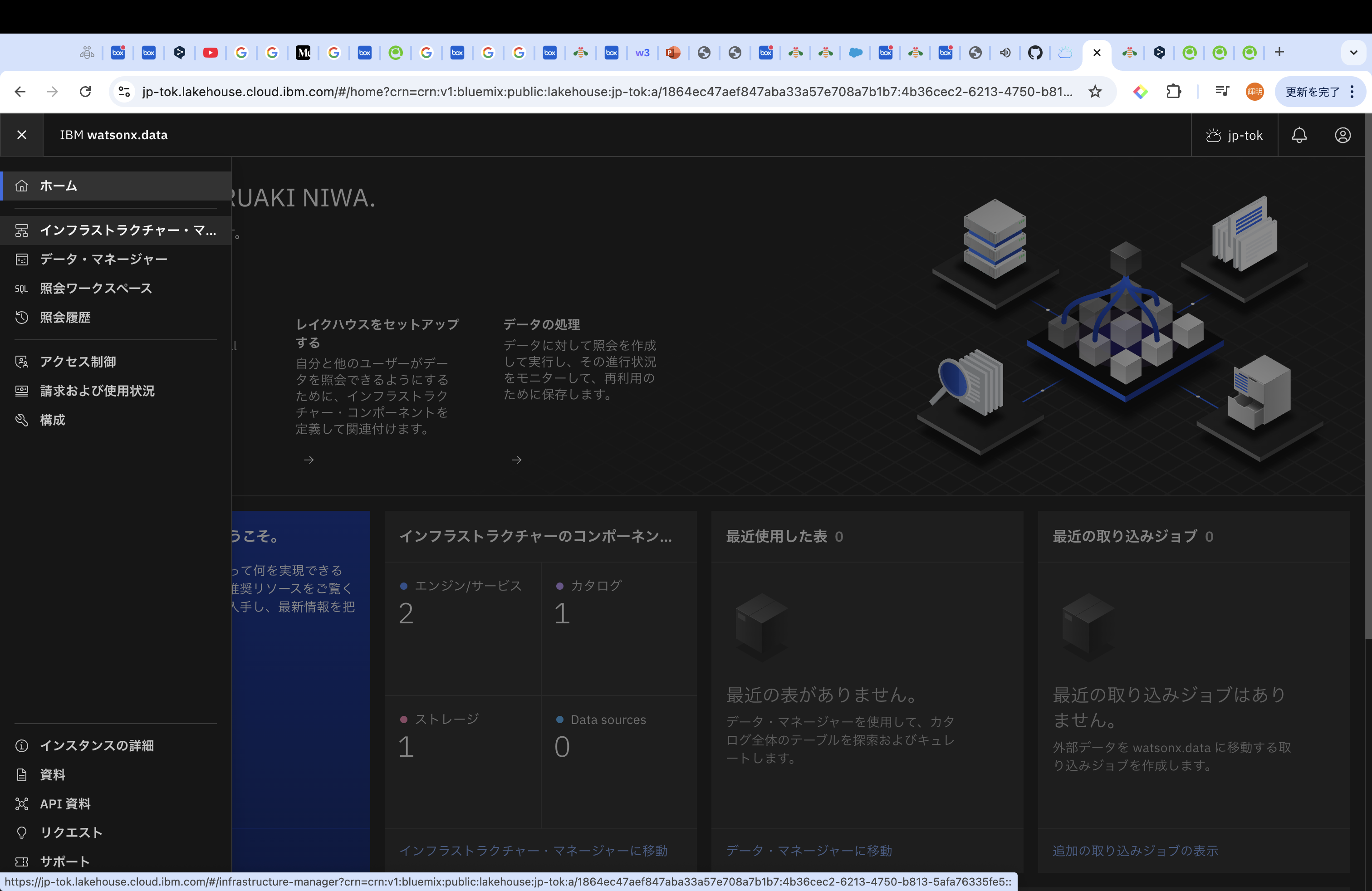
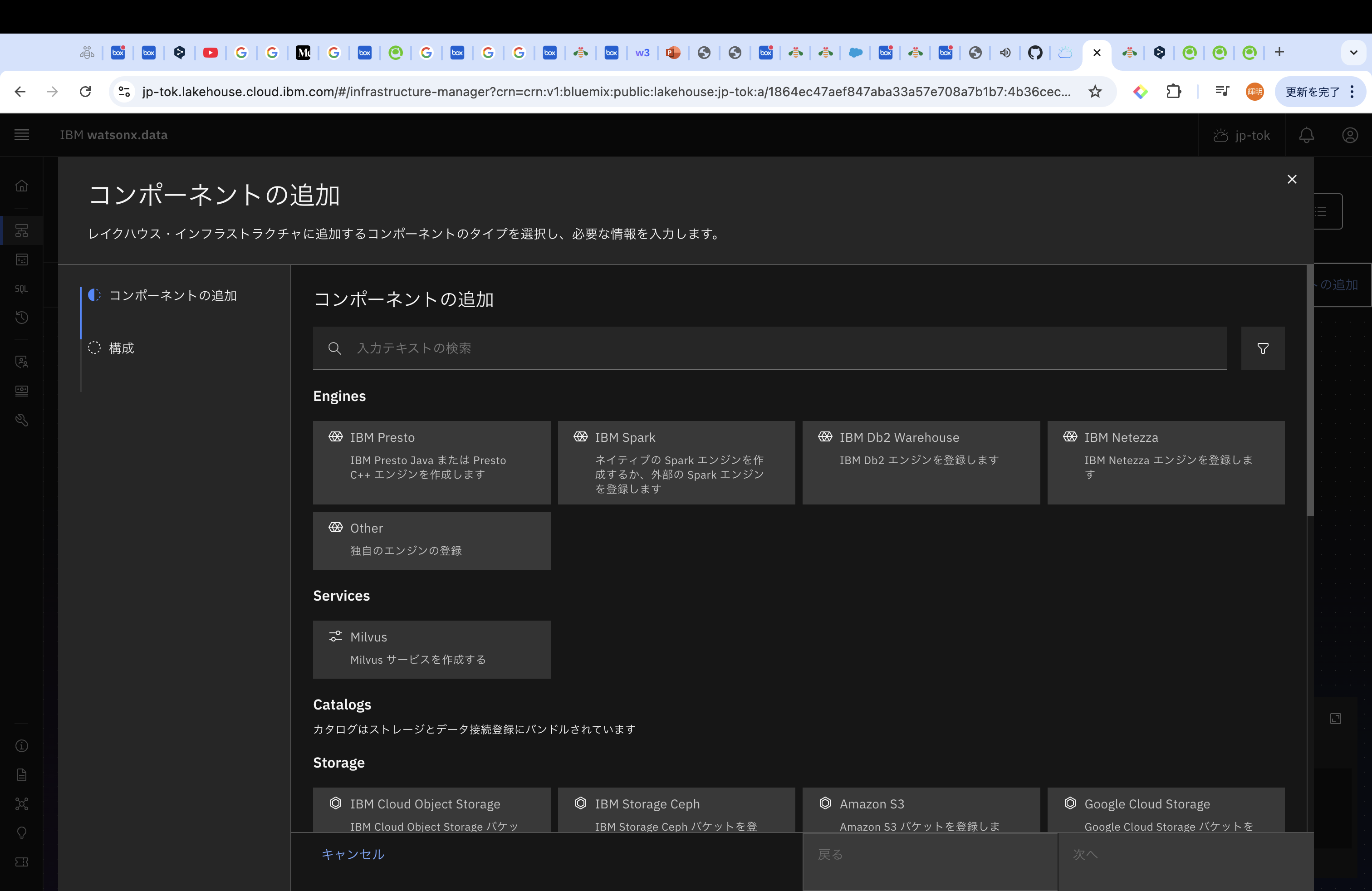
Milvusをデプロイするためには、ハンバーガーメニューから、「インフラストラクチャー・マネージャー」を選択後、「コンポーネントの追加」を選択してください。そうすると、「Service」の箇所に「Milvus」があるので、選択ください。
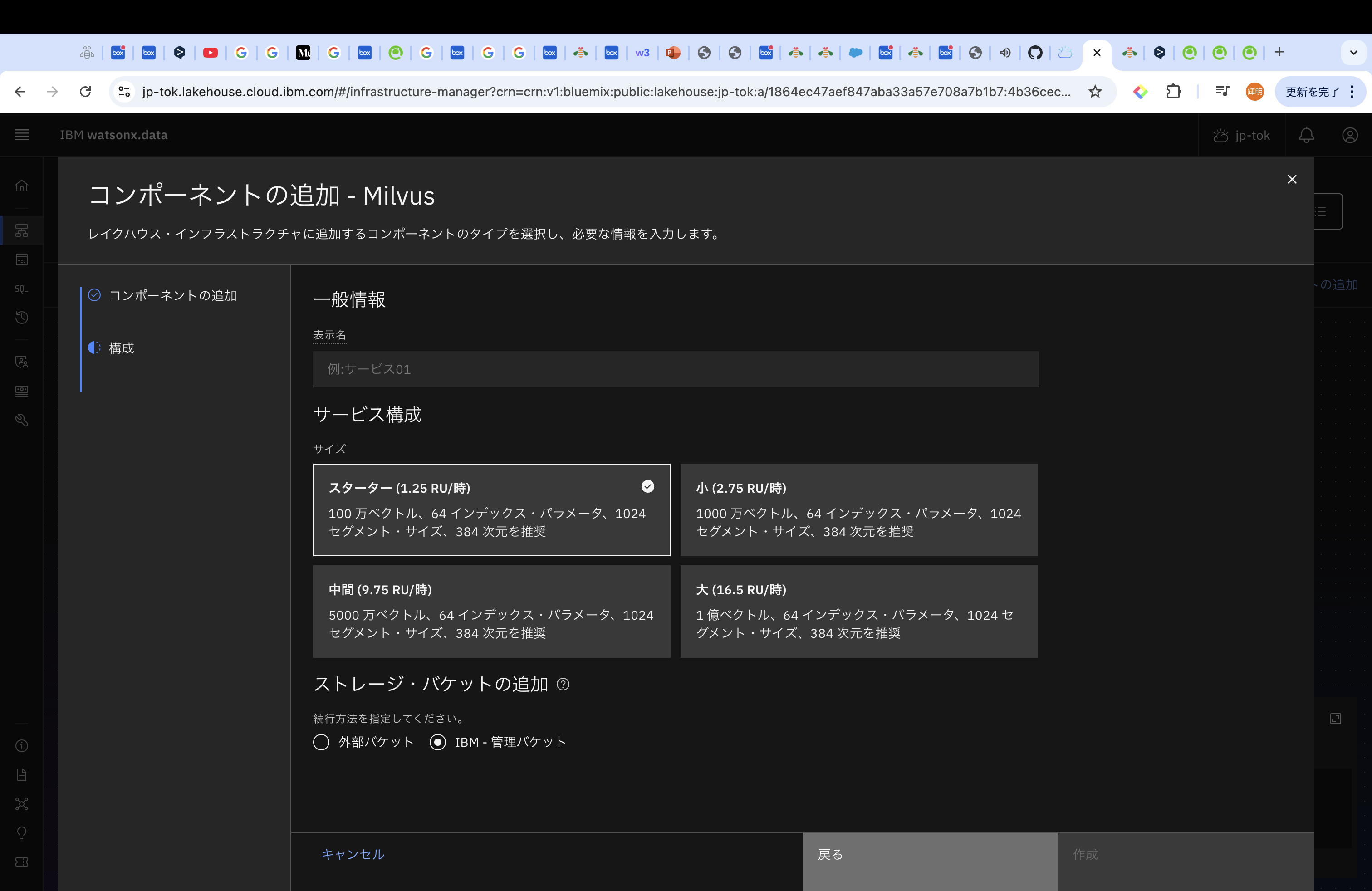
Milvusの構成は、「スターター」「小」「中間」「大」の6つです。スターターでも、100万ベクトルもメモリ上で処理できるので、結構ありますね。Prestoのエンジンと同様にMilvusもエンジンとストレージが分離しているため、ストレージをIBM管理バケットか外部バケットかを選択して作成することができます。その後作成をしてください。
無事Milvusのデプロイが完了すると、インフラストラクチャー・マネージャーで、Milvusのアイコンが出てきます。
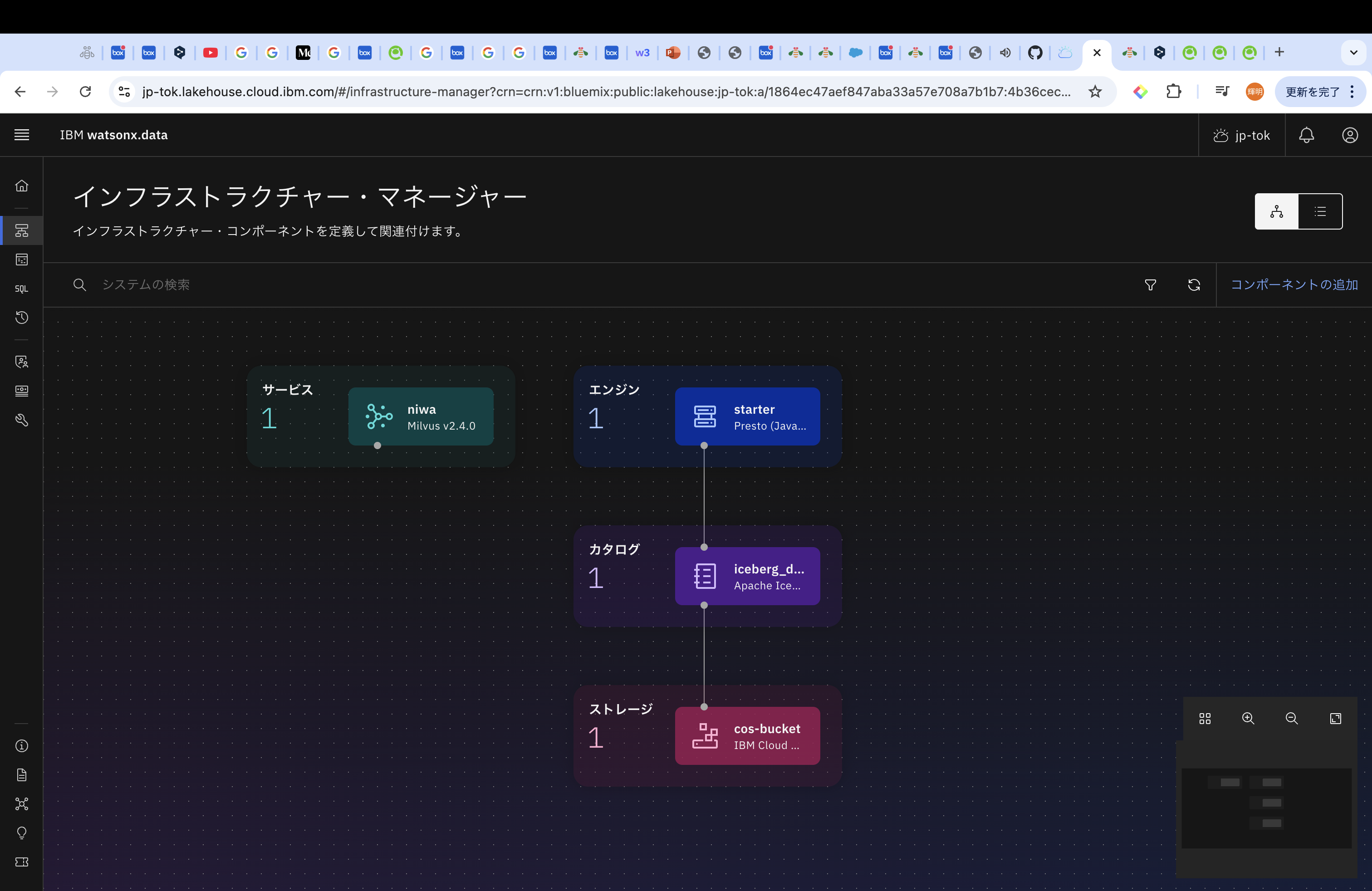
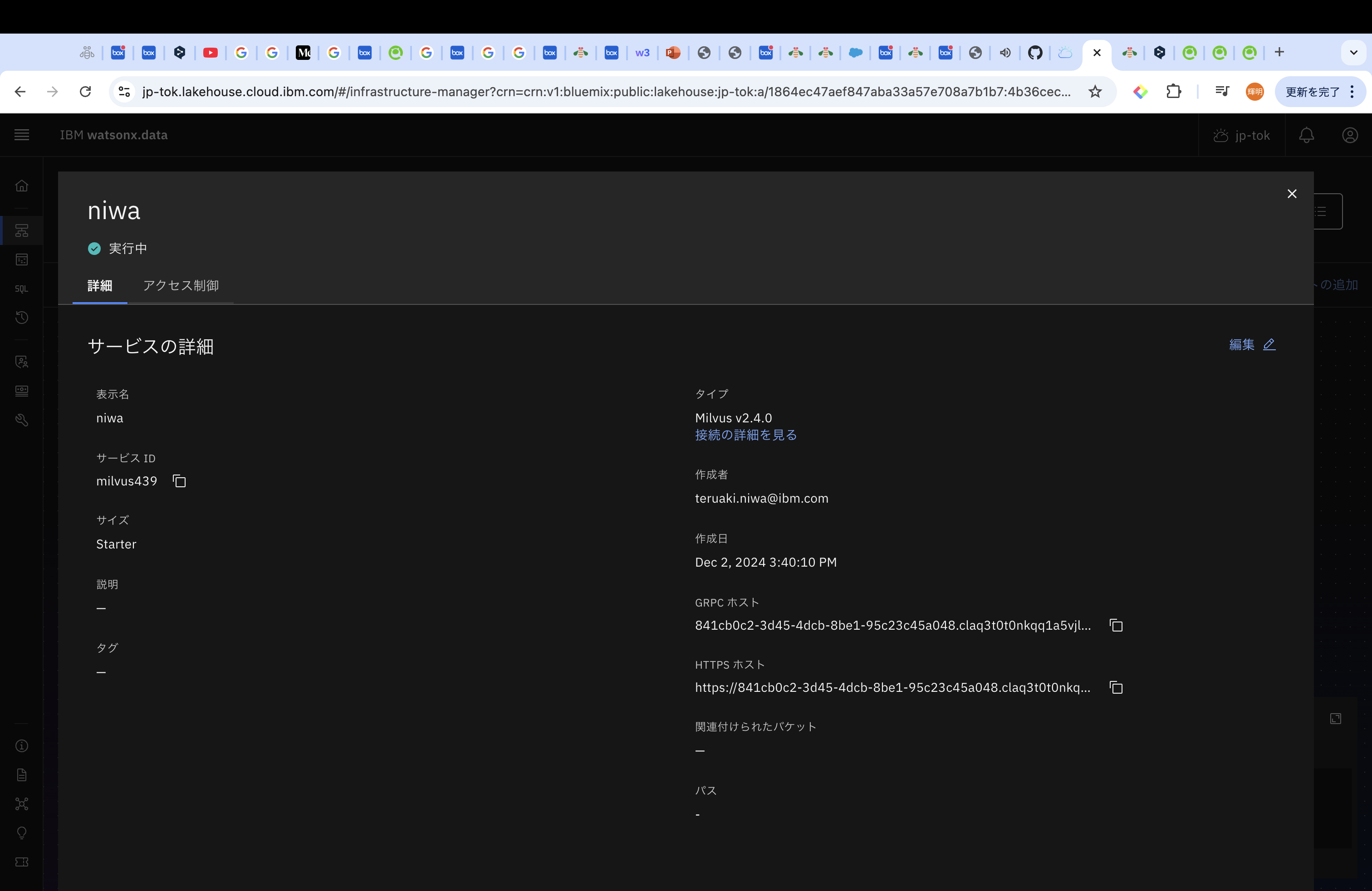
なお、接続情報などは、Milvusのアイコンを選択すると確認することができます。
感想
簡単にデプロイメントできました。これから色々触ってみようと思います。